过去用 AI 写代码的节奏是:写提示词,等 Agent 改,读 diff,再补一句提示词。
但 Loop engineering 的出现,正让 AI 编程从“会不会写 Prompt”转向“会不会设计 Loop”。
所谓 Loop,并不是让 Agent 无人监管地乱跑。它更像一个小型工程系统:自动发现任务,把任务交给 Agent,检查结果,记录状态,再决定下一步。你设计一次系统,系统以后替你不断提示 Agent。

核心判断:别再只盯着提示词了,真正能放飞 Agent 的,是 Skill、状态文件、MCP、Sub‑agent 和客观验收门组成的可控循环。

它解决的不是怎么问,而是谁来持续问
过去两年,很多人把 AI 编程能力理解为 prompt 能力:怎么喂上下文,怎么拆任务,怎么让模型少犯错。
但 Loop engineering 的视角更进一步:如果某类任务会反复出现,为什么每次都要人坐在椅子上重新提示?
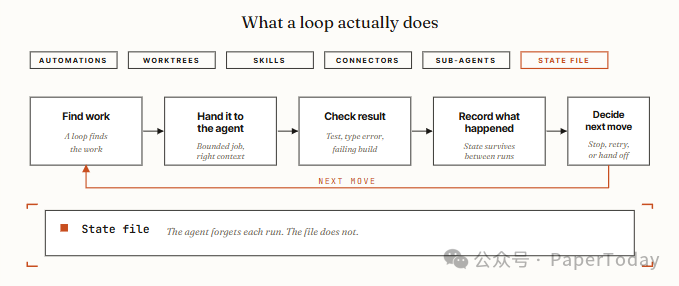
把 Loop engineering 定义成一个系统:它会 find the work、hand it to the agent、check the result、record what happened、decide the next move。译成人话就是:
- 自动知道该干什么;
- 把任务交给 Agent;
- 用测试、构建、lint 等机制验收;
- 把结果写进状态文件;
- 决定继续、重试、升级给人,还是停止。
这也是为什么文章强调,最小可用 Loop 不需要一上来搞 swarm,不需要十几个 Agent 互相协作。最小可用 Loop 只有四件套:一个 automation、一个 Skill、一个 state file、一个 gate。

这个判断很重要。因为很多人一听“Loop”,脑子里就变成“让 AI 自己干一切”。但文章的真实意思更克制:先把一个手动跑得通的任务稳定下来,再把它写成 Skill,再包进 Loop,最后才考虑 schedule。
顺序不能反。
Skill 是 Loop 的记忆,不是提示词装饰
这篇文章里,“Skill”不是一个锦上添花的 prompt 模板,而是 Loop 能不能持续工作的基础设施。
如果没有 Skill,每一次循环都要重新理解项目:怎么跑测试、哪些目录不能碰、历史上踩过什么坑、哪些失败属于 flake、哪些失败必须升级给人。
这就像让一个新人每天第一天入职。
有了 Skill,项目知识被写进 SKILL.md:分类规则、修复模式、禁止动作、状态更新方式,都可以被每一轮读取。Loop 的价值不是 Agent 单次更聪明,而是项目意图开始复利。
给的 CI triage 例子就很典型:
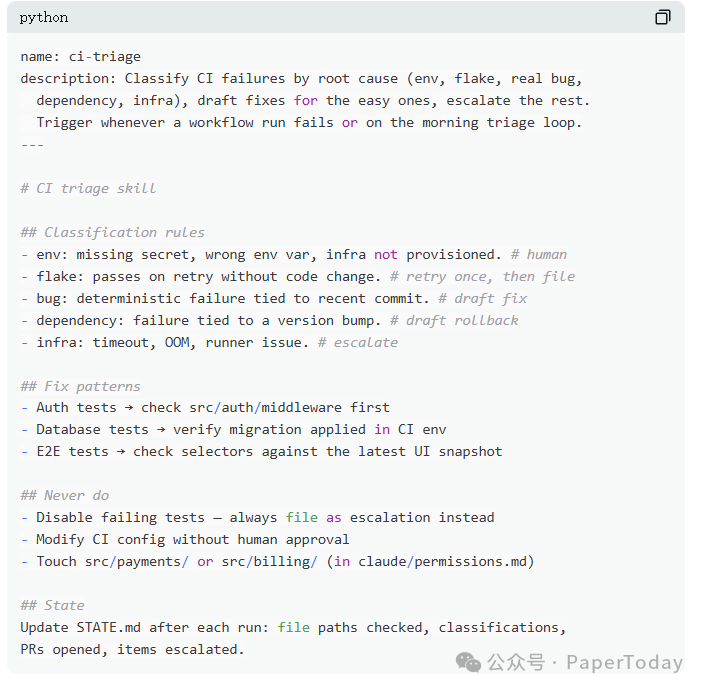
- missing secret / wrong env var 属于人类处理;
- retry 后通过的失败先归为 flake;
- deterministic failure 且关联近期 commit,才适合 draft fix;
- payments、billing、permissions 这类目录不要自动碰;
- 每次运行后更新
STATE.md。
这不是“提示词写得更长”。这是把团队规则写成 Agent 每轮都能读的操作手册。
MCP 和 Sub‑agent,让 Loop 从脚本变成系统
如果一个 Loop 只能读本地文件,它其实很小。真正有生产价值的 Loop,往往要碰真实工具:GitHub、Linear、Jira、Slack、Sentry、数据库、staging API。
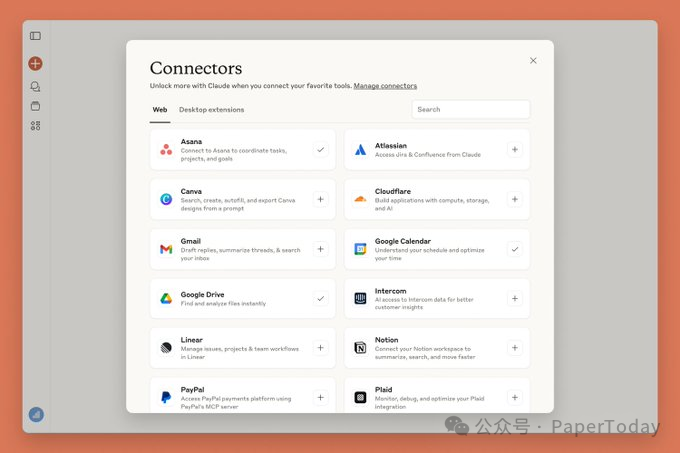
这就是 MCP / connectors 的意义。它让 Agent 不只是说“我建议这样修”,而是能在合适权限下:
- 开分支、开 PR;
- 把 PR 链回 Linear ticket;
- CI 绿了之后通知频道;
- 读取错误追踪系统,定位高频告警;
- 把无法自动判断的问题升级给人。
但工具一多,风险也上来了。所以文章又强调 Sub‑agent:写代码的 Agent,不应该也是唯一验收它的人。
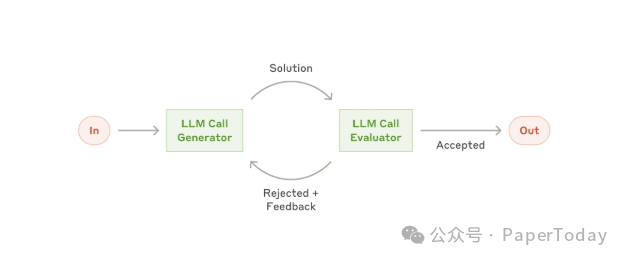
这其实是 Anthropic 很早就写过的 evaluator‑optimizer 思路:一个模型生成,另一个模型批评或验证,再迭代。放在 Loop 里,它变成更朴素的工程原则:maker 和 checker 要分开。
常见拆法是:
- explorer 负责读代码和找上下文;
- implementer 负责改;
- verifier 负责按 spec、测试和风险边界检查。
Sub‑agent 会烧更多 token,因为每个 Agent 都要自己读上下文、调用工具、形成判断。所以它不该被滥用。但在无人值守 Loop 里,一个可信 verifier 往往是你敢离开键盘的前提。
真正的分水岭:有没有客观 Gate
这篇文章最值得反复强调的一点是:Loop engineering 不是“自动化越多越好”。它有一个非常硬的边界:没有客观验收门的 Loop,只是 Agent 自嗨。
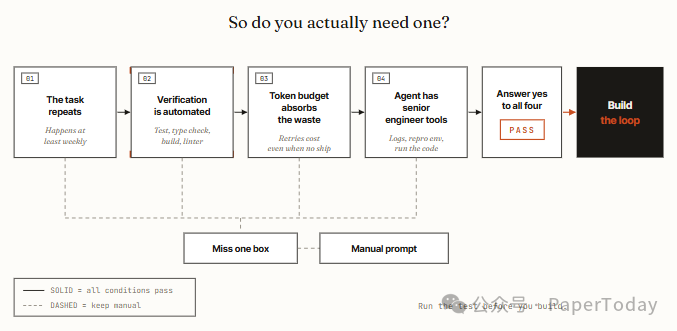
给了一个 4 条件测试:
- 任务会重复出现;
- 验证可以自动化;
- token 预算能承受探索、重试和浪费;
- Agent 拥有高级工程师该有的工具,比如日志、复现环境、运行测试的能力。
少一个,都不该急着 Loop 化。
尤其是第二条。没有测试、类型检查、构建或 linter,所谓 verifier 很容易只是另一个乐观模型。两个 Agent 互相点头,不等于代码正确。
文章把这种失败叫 Ralph Wiggum loop:Agent 过早喊“完成”,循环因此退出,但任务其实半成品。它不是失败得轰轰烈烈,而是失败得很安静。
修法也很直白:用能返回 pass/fail 的东西做 Gate。测试通过没有?构建成功没有?Lint 是 0 还是非 0?类型检查有没有报错?这些比“另一个 Agent 觉得还行”更可靠。
最该警惕的,不是 token,而是理解债
最后一部分很清醒:Loop 越强,风险越大。
一个能自动开 PR、自动修 lint、自动追 CI 的系统,确实能提升吞吐。但如果人不读 diff,不抽查 gate,不控制权限,最后真正爆掉的可能不是 token 账单,而是理解债。
借 Addy Osmani 的说法提醒了两个风险:
- Comprehension debt:代码进库速度超过团队理解速度,未来 debug 的时候才还债;
- Cognitive surrender:你不再形成自己的判断,只是接受 Loop 给出的结果。
再叠加无人值守系统的安全税:
- 技能来源可能夹带 prompt injection;
- 调试日志可能泄露凭据;
- MCP / GitHub / Slack 权限可能越加越大;
- 自动 PR 可能超过人类 review 能力;
- auth、payments、billing 这类高风险代码不该轻易交给 Loop。
最后
我的判断是:Loop engineering 不是每个人今天都要上的新潮流,但它确实指出了 AI 编程下一阶段的方向。
把一个重复任务跑通手动流程 → 写成一个 Skill → 加一个状态文件 → 接一个客观 Gate → 再用 Loop 定期跑。
不是 Agent 更自由,而是工程师把自由关进了一个可验证、可追踪、可停止的系统里。
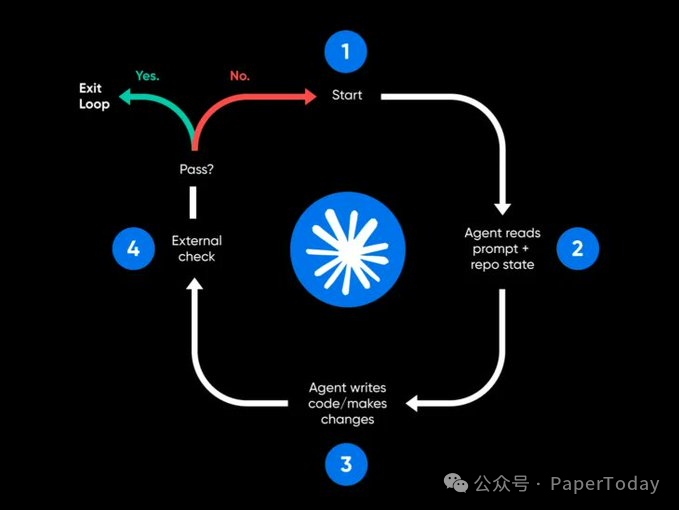
Loop engineering: the 14-step roadmap from prompter to loop designer.
https://x.com/0xcodez/article/2064374643729773029
 发表于 昨天 22:36
|
查看: 4|
回复: 0
发表于 昨天 22:36
|
查看: 4|
回复: 0
