
前两天,Anthropic 发布了 Claude Tag,可以把 Claude 变成你 Slack 里的常驻同事,不仅能以同事身份参与团队协作,支持多人共享同一会话线程,最重要的是,它还具备主动持续学习团队上下文的能力。
也就是说,你可以在 Slack 频道里直接 @Claude,然后它就会根据当前上下文的情况去执行工作中的操作,就像一个真实的同事一样。
但是它的门槛不低:仅限 Claude Code Enterprise 和 Team 客户使用,个人用户没份,codex 玩家更是只能干巴看着。

但巧了不是,我们内部研发了快半年的项目 MFS,和 Claude Tag 想到一块去了。
项目地址:https://github.com/zilliztech/mfs
并且,基于我们的 MFS 项目,任何人都可以很快地复刻一个开源版本的 Claude Tag,并做到普通 Claude 用户和 Codex 用户,都能免费使用。
以下为我们基于 MFS,两天天手搓的 zilliz 版本开源 Claude Tag,我们管它叫 Open Tag。它的使用体验和 Claude Tag 非常相似。
Open Tag 示例:https://github.com/zilliztech/mfs/tree/main/examples/open-tag-skill
举个例子,你可以在你的 Slack 频道里 @OpenClaude,(用 Codex 就是 @OpenCodex)。然后扔给它你的需求,它就能先读懂当前线程在聊什么,再结合你授权给它的上下文(代码、文档、工单、聊天记录、数据库里的行),直接输出结果,最终把结果直接贴回 Slack。
Zilliz 版 Open Tag 效果展示
话不多说,先看 Open Tag 的效果和安装使用教程,这里有几个简单的录屏。
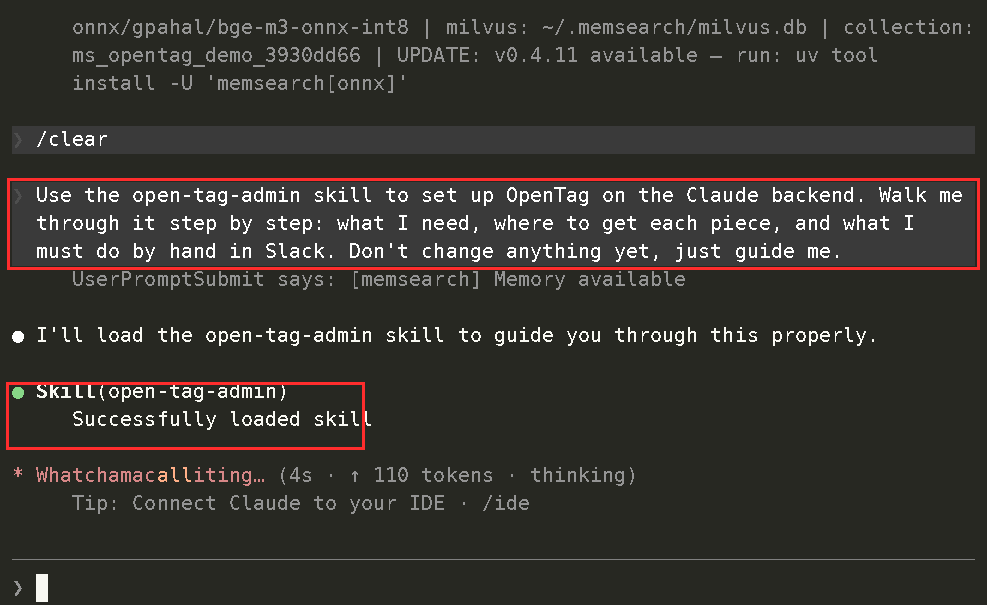
第一步,自动化配置与安装
通过调用 open-tag-admin Skill,Agent 会引导你完成 Open Tag 的本地安装与环境配置:
第二步,真实工作流 review
配置好后,我建了 OpenClaude 这个 Slackbot。然后我把它邀请进 Slack 频道后,直接 @OpenClaude,输入具体指令。
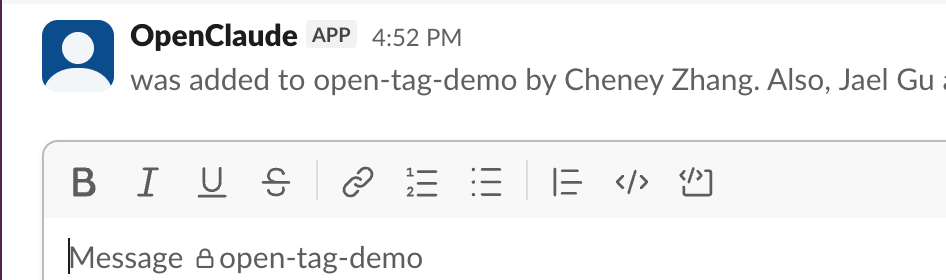
例如,在研发场景中,我让其 Review 我的开源项目 memsearch 的最新 PR 和 Issue 并给出专业意见。
可以看到它工作 3 分钟之后,就给出来了详细的回复和建议,我甚至可以继续让它进行 PR 合并之类的操作。
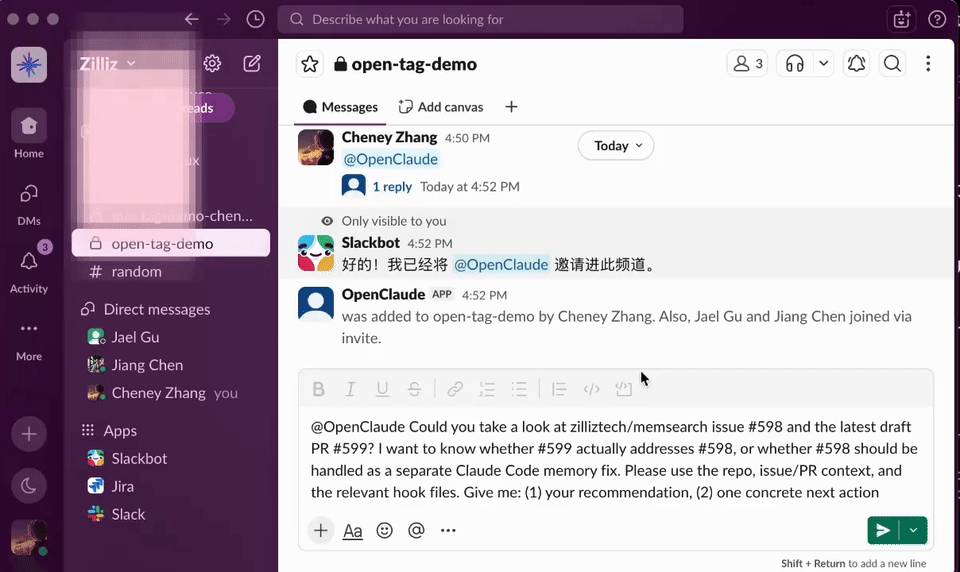
这边只是演示一个接入 GitHub 的例子。除此之外,我们可以在设置的时候接入各种数据源,让它有更多的数据接入和控制能力。
想看它具体怎么装、怎么跑,点击开源链接即可:
https://github.com/zilliztech/mfs/tree/main/examples/open-tag-skill
注:由于目前展示的是在本地运行的 Demo,我们暂未对该示例实现严格的沙箱隔离与权限管理机制。在生产环境中部署前,建议务必理解其底层原理与安全边界。
解构 Claude Tag:构成三要素与核心瓶颈
看完了效果,我们来看看 Claude Tag 以及 Open Tag,是怎么运行的。
Claude Tag 说白了,就是把一个 agent 拆成三块拼起来:大脑负责策略、memory 负责记忆,tools 负责执行。
一个大脑负责想,一份记忆让它记得住事,一双手脚让它够得到外面的工具和数据。
- 大脑:负责长期意图理解与策略规划,接入 Claude、Codex 即可。
- memory :负责持久化跟踪频道内的上下文,避免在每次交互时进行从零开始的 Prompt 灌输。
- tools + 数据:触达外部系统的工具和数据源,完成具体的执行操作。
总结来说 Claude Tag = Brain (大脑)+ Memory (记忆) + Tools (工具/数据接口)
对于 Open Tag 而言,还原大脑并不难,挂载 Claude Code 或 Codex exec 即可;还原 Slack 的消息外壳也不难,只需通过监听 app_mention 事件,读取线程上下文并实现收发适配器,几百行代码就能搞定。
真正难点是另外两块,记忆和 tools。即如何让 Agent 能够实时跨越十几个相互孤立的系统,精准、低成本地检索并引用上下文。
而 Open Tag,我们可以理解它只是一个收发消息的轻量级适配器。其背后真正提供跨源数据对齐与上下文召回能力的,是我们的核心开源底座项目:MFS。
MFS 项目地址:https://github.com/zilliztech/mfs
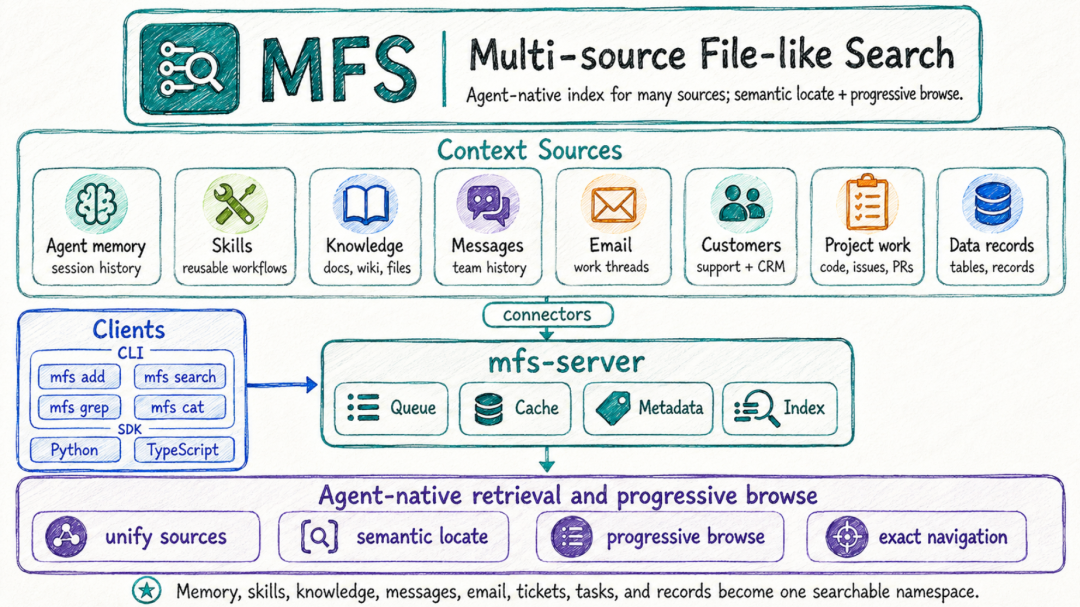
MFS 的技术实现
为了让 Agent 能够像人类工程师一样理解复杂的企业数据,MFS 在工程上做了两项重构:
1、统一的 URI 操作界面
目前业界的共识是,Agent 最天然、信息密度最高的交互接口是 CLI(命令行界面)。既然 Agent 天生对 Shell 命令有极高的泛化执行能力,MFS 索性将所有异构数据源,在底层全部抽象为统一的虚拟树结构。
- 一个 Postgres 表,被抽象为一棵可以 ls 进去的树,每一行记录就是一个可以 cat 的 JSON 对象。
- 一个 PDF、一个 S3 桶、一个 GitHub 仓库连同它的 issue,也全是树,甚至一个 Slack 聊天线程,都能映射为具备稳定 URI 的标准节点。
Agent 只需要使用一组标准的原子命令(tree、ls、cat、search、grep),就能以极低的 Token 成本遍历所有异构空间:(tree 摊开一个源的结构,ls 看某一层有什么,cat 把一个对象读出来。要快速定位,还有 search 做语义搜索、grep 做精确匹配。)
mfs tree github://acme/backend -L 1 # 摊开一个仓库的结构
├── src/
├── tests/
└── README.md
mfs ls postgres://prod/public # 看数据库里有哪些表
tickets/ users/
mfs cat jira://acme/PLAT/issues.jsonl --locator '{"id":"PLAT-491"}'
# 把那条工单的原文读出来
在 CLI 之上,MFS 还将这些原子能力打包成了两个面向 Agent 的标准 Skill:
mfs-ingest:负责数据源的注册、配置生成、增量同步与索引构建,必要时排查为什么没有 ingest 成功mfs-find:负责跨源的搜索和浏览,在已经接入的源里 search / grep,再用 tree / ls / cat 一路定位到原文证据。
安装它们只需要一条命令。跑完以后,mfs-ingest 和 mfs-find 这两个 Skill 会自动装上;不管你用的是 Claude Code 还是 Codex,所有支持 Skill 的 agent 都能用:
npx skills add zilliztech/mfs --all -g
装完,打开你的 agent,连命令都不用记,直接用大白话说就行:
> 把我这个仓库 ingest 了,再帮我找找 webhook 重试的逻辑在哪
剩下的它自己会调对应的 mfs 命令搞定。
2、双轨制检索:搜索与浏览的两条腿走路
在 Agent 获取上下文的路径上,行业长期存在两大流派的争论:
- 搜索派(RAG/索引):强调先建向量索引,再做语义检索。传统 RAG、大型知识库,或者 Cursor 是其中代表
- 浏览派(progressive disclosure):代表性玩家是 Anthropic ,不一次性暴露所有数据,让 Agent 顺着 Skill 线索一层层渐进式披露,需要哪块看哪块。Skill 的按需发现机制也是这个路子。
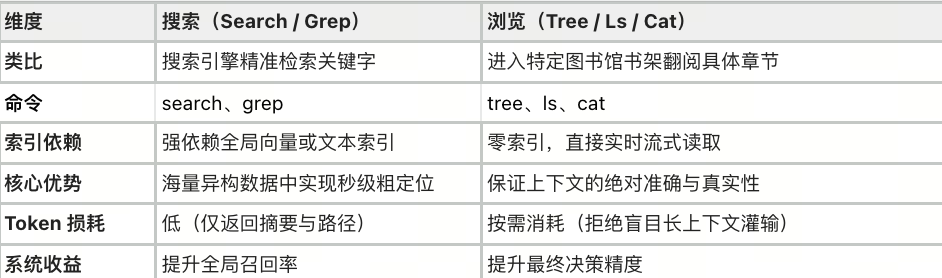
很多人把这两派看成二选一,但我们回想一下人类寻找信息的真实链路:
搜索信息,我们会先通过 Google 搜索获取高召回的候选列表(搜索),再点击进入具体网页顺着目录精读(浏览)
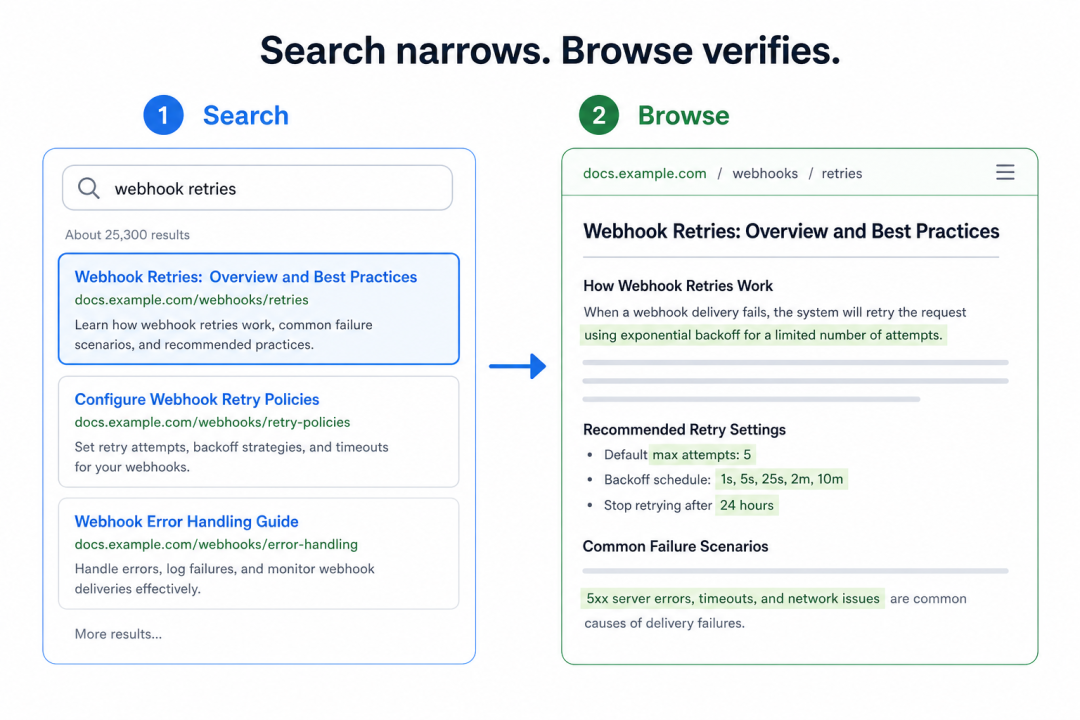
去图书馆找书也一样。你不会从头到尾一本一本翻,你会 1) 先查索引、顺着它定位到某一排书架。2) 然后你走过去,抽出那本,翻到具体那一页。
这两个例子都有一个很明显的特征,需要我们把搜索与浏览紧密结合。其中,搜索负责把范围缩小,浏览负责提供更精确的信息。
MFS 的设计也是同理。先用 search、grep 在大范围里快速框出候选,再 tree、ls、cat 顺下去把它核实。一边提召回省 token,一边提精度保准确,这在 agent 的上下文定位和记忆召回里特别好使。
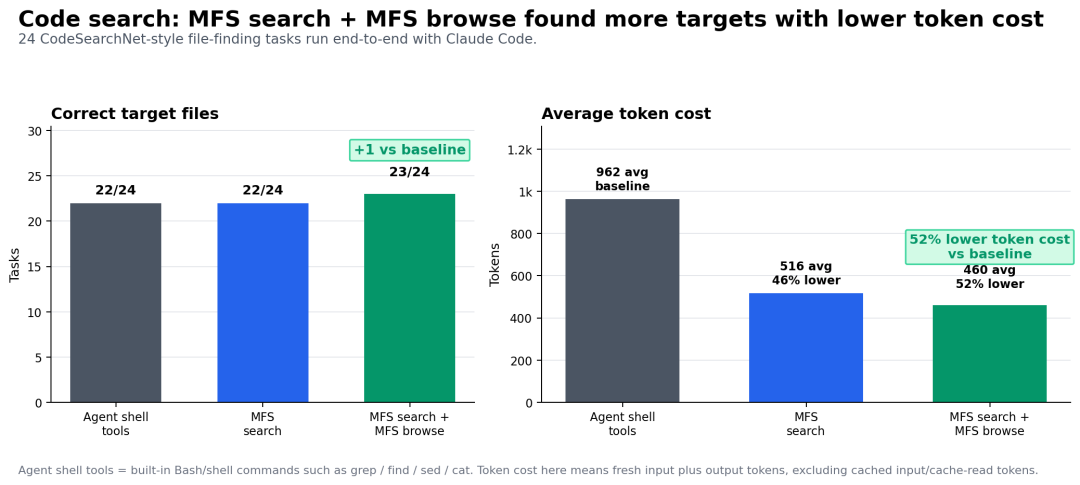
在测试中,我们拿两千个文件的复杂代码库做了测试,纯原生 Shell 的 Agent 检索平均消耗 962 tokens(命中率 22/24);而采用 MFS 的“搜索+浏览”双轨制方案后,Token 消耗骤会降至 460 tokens,同时命中率提升至 23/24。相关记录和详细结果都在代码仓库的报告里。
异构数据源的统一与架构弹性
1、全源检索的实际价值
mfs 的一大优势是,能通过一个 --all,检索你注册进来的全部源,代码、数据库、文档、网页、工单等等,并返回相同格式。
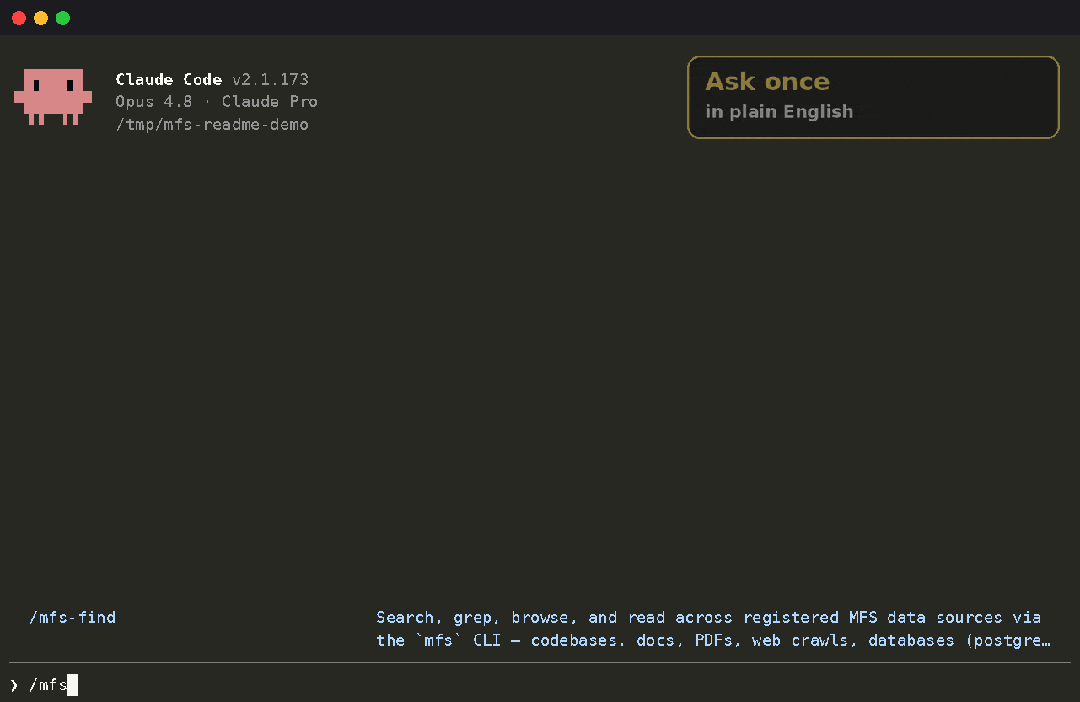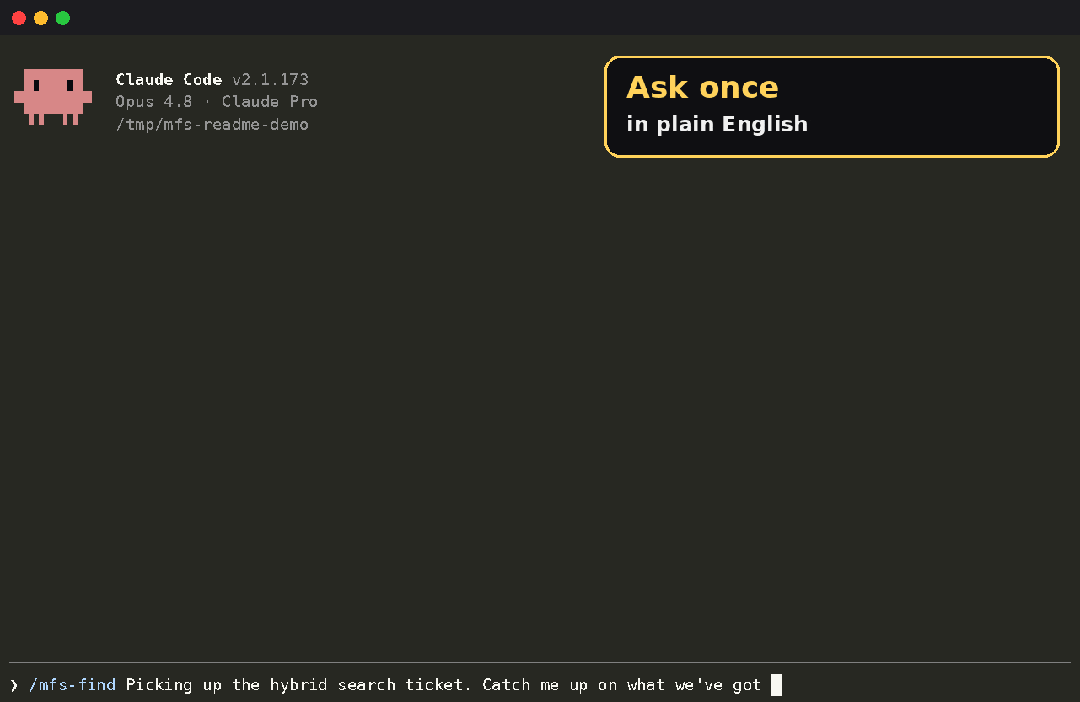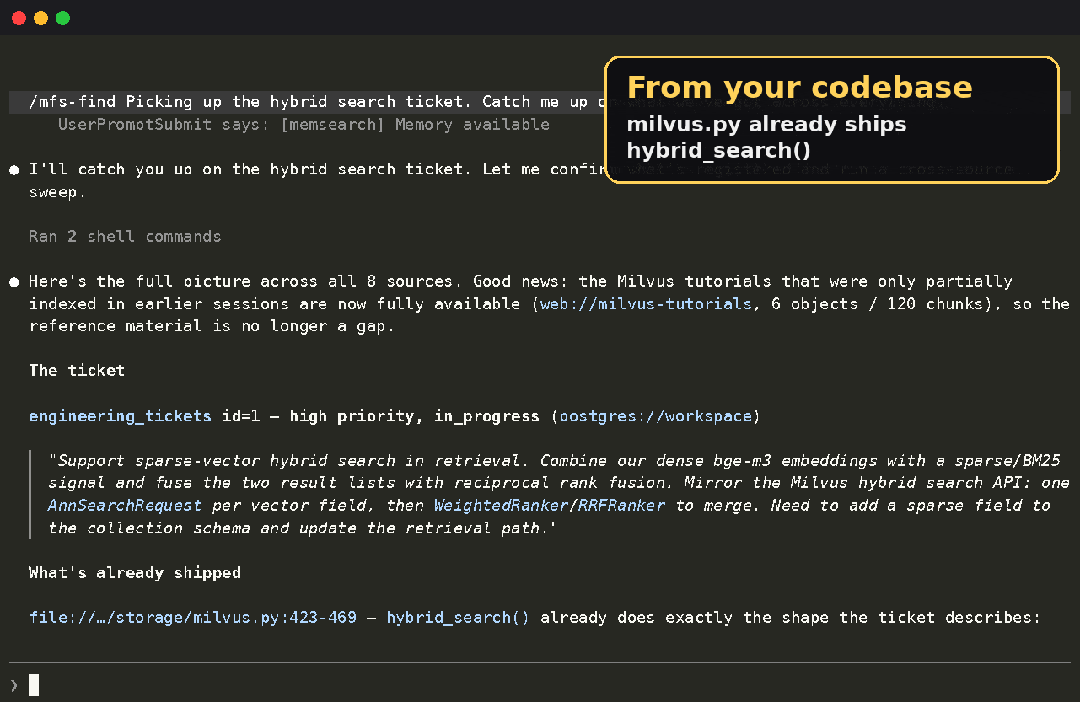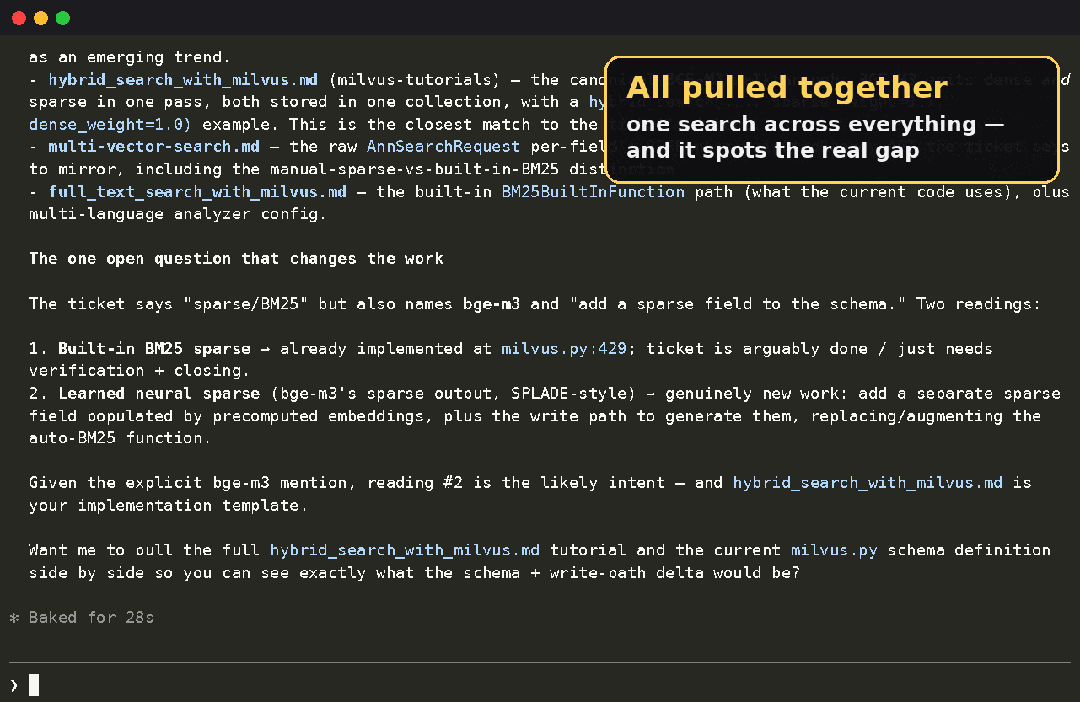
比如我们同事想搞清楚,在 zilliz 内部,手头到底已经有哪些跟混合检索相关的研发资料,又散在哪儿了。只需要:
mfs search "我们现在到底已经有哪些跟混合检索相关的东西?" --all
postgres://prod/public/engineering_tickets/rows.jsonl score=0.88
#482 hybrid retrieval flaky on long queries — dense recall drops near ...
notion://workspace/design/retrieval-rfc.md score=0.85
Hybrid search: combine dense + sparse, fuse with weighted RRF ...
web://milvus-tutorials/hybrid-search score=0.81
Hybrid search runs an ANN search and a BM25 search, then reranks ...
file://local/repo/src/milvus.py score=0.76
423 def hybrid_search(self, query: str, top_k: int = 10):
github://your-org/bootcamp/notebooks score=0.69
bootcamp/hybrid_search.ipynb — end-to-end hybrid retrieval walkthrough
可以看到,一条命令,把工单里的反馈、设计文档里的方案、官方教程、你自己代码库里的实现、github 上的示例,本来散在五个毫不相干的系统里的内容,全都排在同一个结果列表里。
在 agent 里它还会更进一步,把这几个源的命中综合成一段回答,最后做进一步分析。
这个例子已经录制成以下的 GIF:
目前 MFS 已经原生支持了 20 多种主流的数据源:
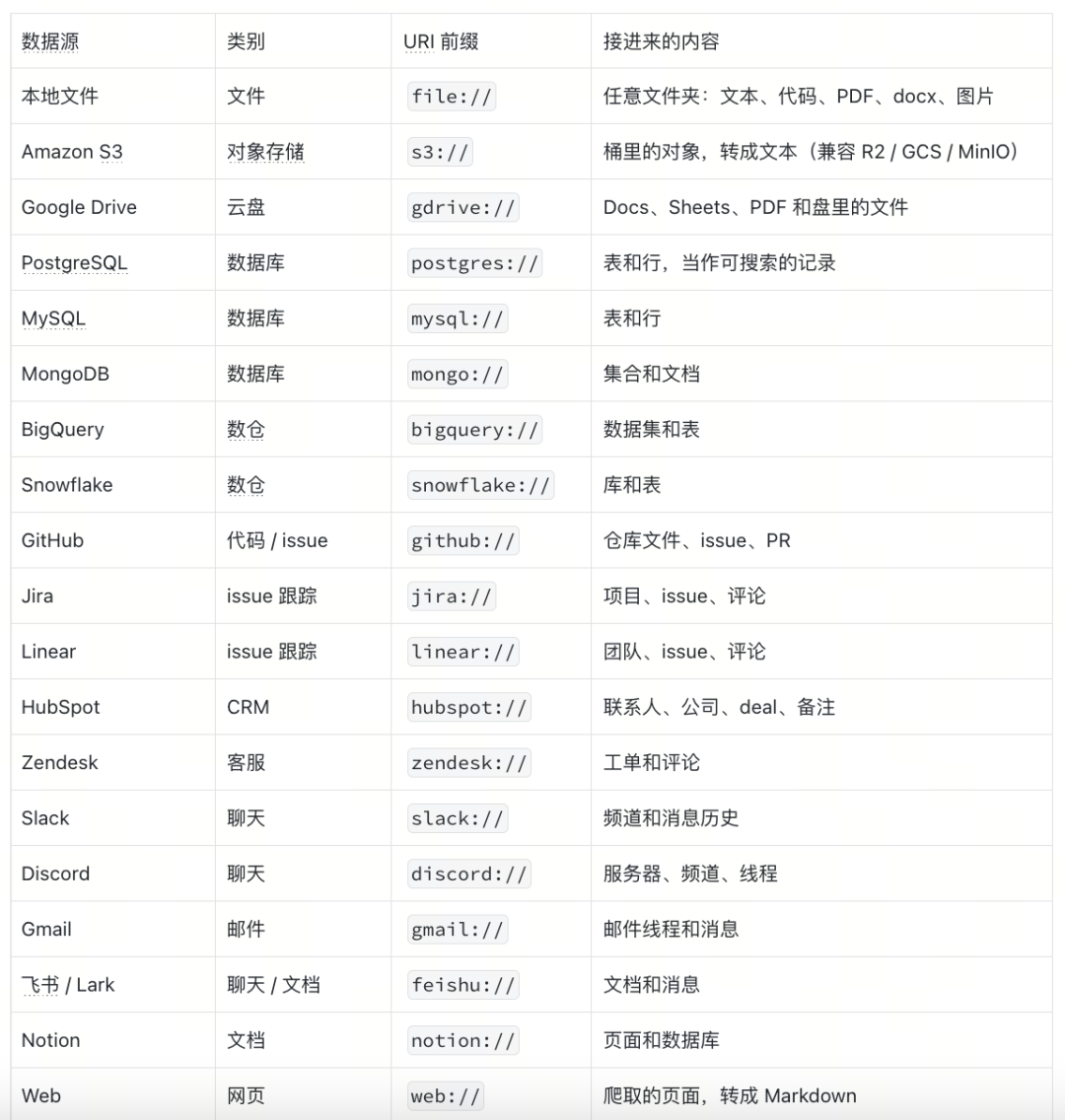
过去这些业务含义不一样,连物理形态也不一样的数据源,很难直接用于搜索,但 MFS 可以屏蔽了底层的物理形态差异,(通过文档转文本,图片转描述,表格行和消息线程整理成结构)让它们始终是同一套树、用同一套命令操作,直接服务于 agent 的搜索、读取与引用。
另外,MFS 还在底座层内置处理了增量同步、认证鉴权、文档切块(Chunking)、Embedding 复用、索引和元数据一致性、缓存、删改清理、任务中断恢复的系统级工程。
值得一提的是增量同步,过去数据库看 updated_at,聊天靠消息游标,文件夹比内容哈希,发现变化的方式各不相同,但现在 MFS 框架可以替你判断怎么同步,最后统一汇报成新增、改动、删除。
这里先不展开这些繁琐细节,后面我会单开一篇讲它背后的工程设计。
如果你想贡献新的 Connector,也不用重写一整条检索管线。框架已经把共性抽成了接口和父类,你只要把这个源里有什么、怎么读、怎么发现变化讲清楚,后面的转换、同步、embedding、索引、缓存和搜索,都由 MFS 接着往下走。
2、架构的弹性:从本地单机到企业级生产
架构上,MFS 采用彻底的 Client/Server 分离架构,向量库、元数据库、缓存这些后端部件全部解耦,支持无缝的平滑扩容。从而让它既可以很快在本地跑起来,也可以快速 scale 到生产环境。具体来说
- 开发者本地快速 demo:后端默认进入本地的轻量化模式。向量数据库采用 Milvus Lite,元数据采用 SQLite,Embedding 默认调用本地约 600MB 的 ONNX 模型。无需任何云端 API Key 和 GPU,单机一分钟拉起。
- 企业级生产部署:当数据量与并发请求激增时,可将后端组件解耦替换。向量库无缝指向 Zilliz Cloud(高性能分布式托管),元数据切换至分布式 PostgreSQL,Server 端打包为标准容器镜像,通过 Kubernetes 进行弹性编排。
使用过程中,用户不用先纠结自己要本地还是生产。这些判断都写进 Skill 里了。只要把需求说清楚,顺手给个 server 地址(如果有的话),agent 就能接着往下走:想连什么数据源、怎么连、凭证怎么配,它都会一步步教你;想快速本地试玩,它带你跑通 quick start;想自己部署,它引导你搭起来。一句话起步,剩下的它接管。
举例:
- 用 mfs-ingest 帮我把这个本地仓库先加进去,我只想最快跑通一个 demo。
- 帮我把 Slack 和 Jira 都接上,token 应该放在哪、哪些字段不能明文写,你一步步带我来。
- 我想按生产方式部署 MFS,向量库用 Zilliz Cloud,元数据用 Postgres,server 准备用 Docker Compose 跑。
- 帮我看看现在有哪些 connector 已经接好了,再用 mfs-find 搜一下有没有关于 webhook retry 的背景信息。
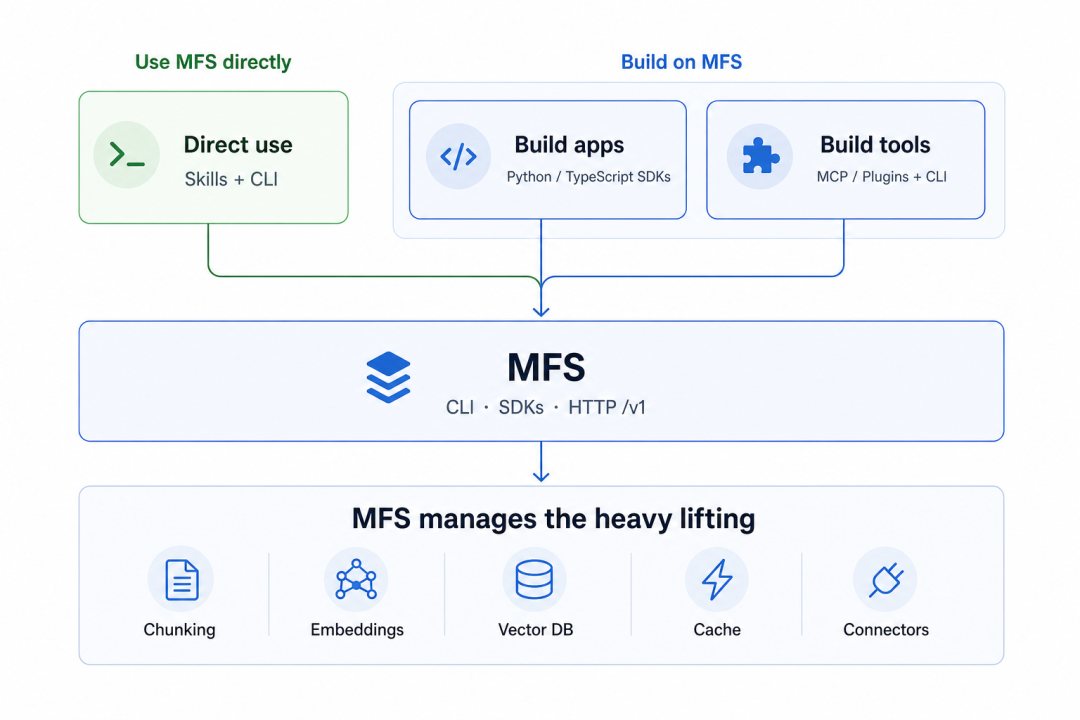
基于 MFS 创建自己的“Open Tag”
到这儿你可能觉得,MFS 就是个给自己用的搜索工具。
不止。它同时是一个底座。
Open Tag 只是构建在 MFS 之上的一个轻量级示范性应用,你完全可以基于 MFS 提供出来的 CLI 和 SDK,构建自己上层的 Agent 应用/plugin/MCP/Skill。
写在最后
过去几年,随着大模型在推理能力跨过临界值,业界的关注点开始聚焦于 Agent Harness、持久化 Memory 以及 Skill 管理。
而这些层出不穷的新概念,本质上都是在解决同一个问题:让模型真正、稳定地融入人类的生产流。
这也是我们推出 Vector Lakebase 架构所秉承的初心——语义数据不应长成实时检索、交互探索、批量分析一个个互不相通的知识孤岛,而应当沉淀在一个统一的 Lake-native 基础设施上。
MFS 则是这层基础设施面向 Agent 演进的产物。让 Agent 能够安全、高效、廉价地触达和组织真实世界里的上下文,让它搜索、能渐进式浏览,还能自主处理结构、更新和变化,让 agent 在需要时自己发现、核实、组织线索,减少对人工投喂的依赖,从而让 Agent 真正从工具进化为一个懂你、懂业务、有上下文的工作搭档。
也欢迎大家体验、提 issue、加 connector:
项目地址:https://github.com/zilliztech/mfs
Open Tag 示例:https://github.com/zilliztech/mfs/tree/main/examples/open-tag-skill
文档:https://zilliztech.github.io/mfs/
Discord:https://discord.com/invite/FG6hMJStWu
 发表于 2 小时前
|
查看: 4|
回复: 0
发表于 2 小时前
|
查看: 4|
回复: 0
