以某个历史知识为例,如果你只是把Codex当成一个普通的ChatBot来用,通常我们只会像下面这样直接提问:
而Codex也只会回馈给你一段干巴巴的纯文字答案,就像下面这样:
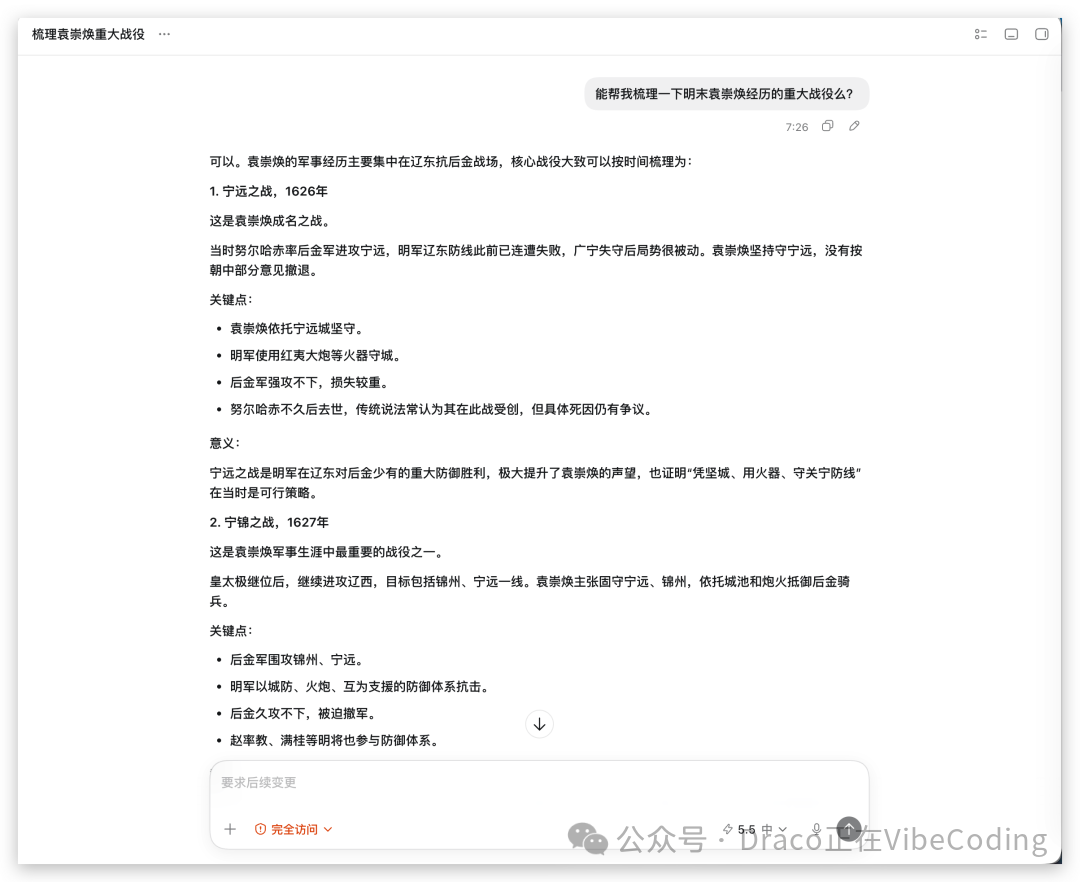
但人脑处理纯文本的效率其实非常低。逐字逐句地啃完一段历史背景,可能五分钟后就忘了一大半。这时候,你就应该跳出“对话”的思维定式,向Codex提出“可视化”的诉求:
请使用你自带的image_gen工具将以上知识绘制成一个infographics
Codex会调用 image-gen 工具(当然,这里需要你拥有GPT的Plus或者Pro订阅计划)来生成一张可视化的技术文档风格信息图:
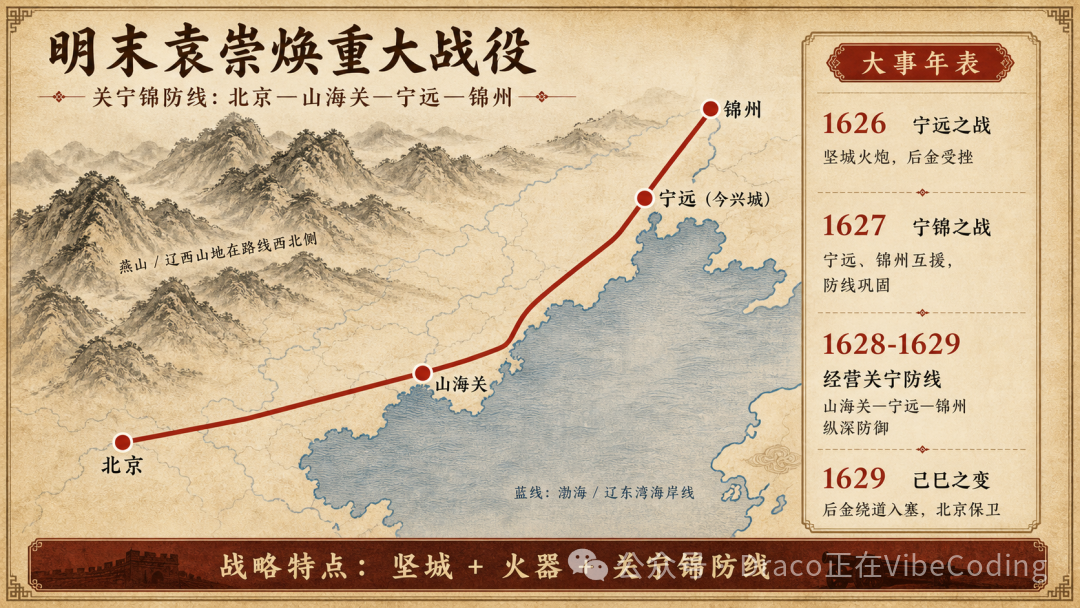
然而,如果你只用了简单的Prompt就沾沾自喜,得到的信息图很可能会存在严重的幻觉和位置错误。比如下面这张初版图里,北京、山海关、宁远、锦州的相对地理位置关系可以说是毫无准确性可言:

要解决这个痛点,关键一步是让Codex去“查资料”。你需要指引它联网下载信息图中涉及的地名所对应的真实经纬坐标,以及相关的海岸线与河流矢量数据,然后重新绘制底图。请记住:我们身处的世界早已完成了“比特化”,那些你耳熟能详的东西,基本都能在开源数据库里找到对应的档案。
Codex获取到的真实地理数据源包括:
- 海岸线:Natural Earth
10m coastline
- 河流:OSM / Overpass 拉取的著名水系
- 投影:局部 Lambert Conformal Conic
- 河流筛选:保留了与辽西走廊强相关的
大凌河、小凌河、女儿河、兴城河、兴城西河、六股河
在这一步,Codex会先将获取到的真实坐标和矢量信息绘制为一个底层SVG,然后把这个精准的底图作为参考图喂给 image_gen 进行二次创作,最终输出兼具美观与准度的成品:
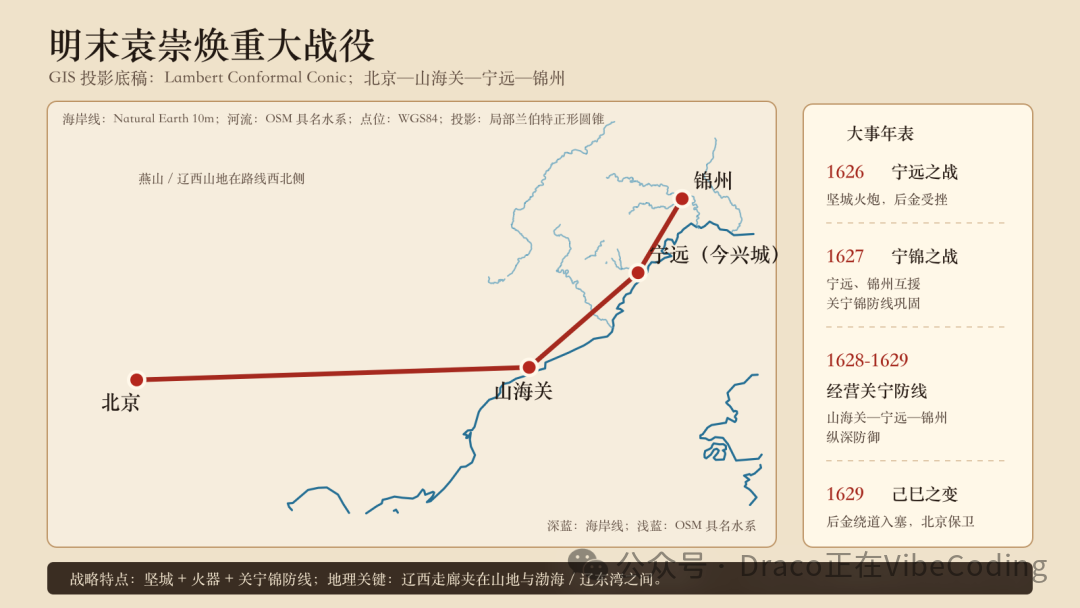
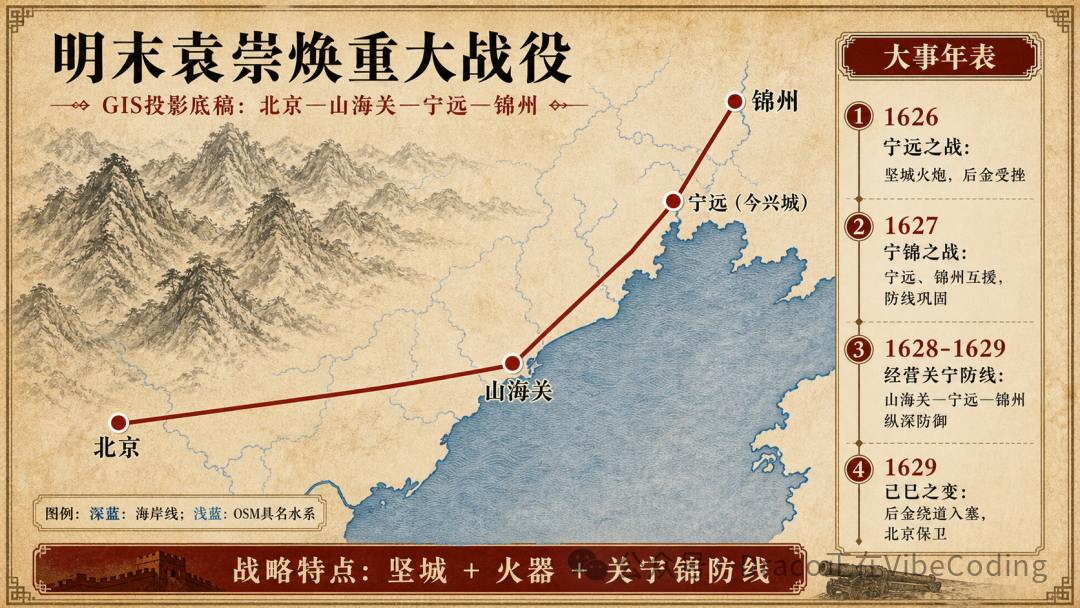
虽然最终生成图中的信息依然难以做到100%完全还原史实,但作为一种帮助你建立直观认知的 “rough understanding”,已经完全够用了。
一旦你在某个Codex session中搭建起了这套“数据校准+绘图指令”的工作流,就可以在同一个对话上下文里,稳定地量产各种历史事件相关的Infographics了!比如,我们趁热打铁,再来一个“官渡之战”:
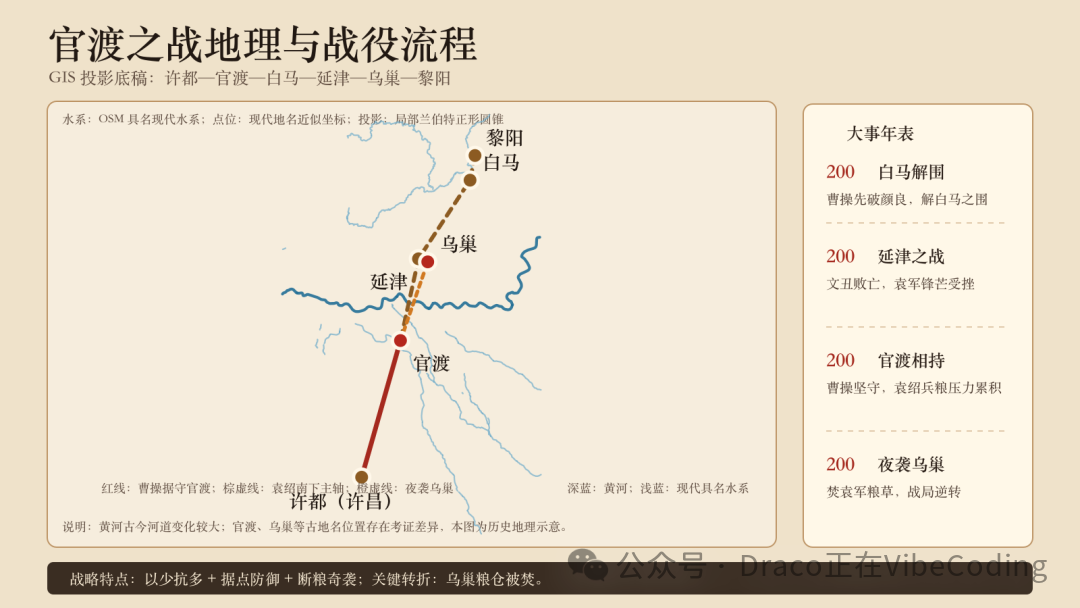
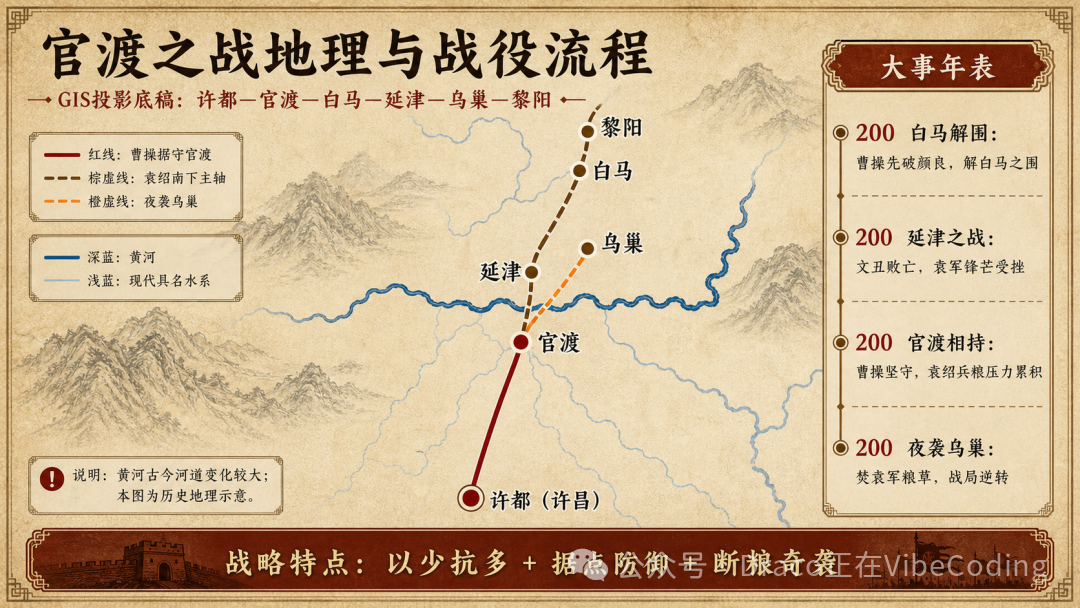
相比历史类知识,生物类的可视化产出会更直接轻松一些。例如,我们先来段最简单的对话:
帮我介绍一下人体细胞的构成

随后加上我们那条将知识图像化的指令:
请使用image_gen帮我生成一张16:9的infographics
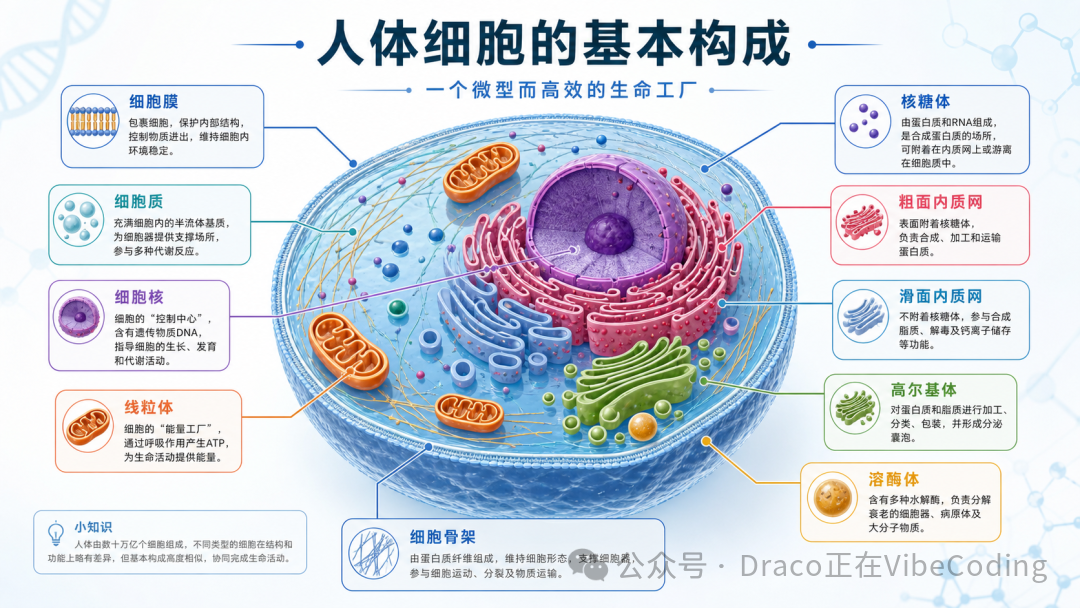
我们甚至还可以利用之前的Hyperframes生产线略作调整,将那些生成的静态图片全部替换为 image_gen 产出的高清Infographics,进而批量制作出一整套生动有趣的学习打卡式教学视频。
当然,如果你涉足的是更高阶的数理领域,也完全可以抛弃信息图,改用Manim这类工具来制作极致视觉表现的数学概念学习笔记视频。
以上思路纯粹是抛砖引玉,不知道是否能激发你脑海中更多有趣的创意火花?去试着把枯燥的知识变成视觉盛宴吧。 |  发表于 昨天 01:00
|
查看: 18|
回复: 0
发表于 昨天 01:00
|
查看: 18|
回复: 0
