今天是2026年6月29日,星期一,北京,天气阴。
继续做总结,回到Skill这块,从根本逻辑上看这个技术。讲2个点,一个是 Skill的本质价值认定及实现机制,看看其设计的思路和概念本质 ;一个是 Skill三级加载机制——缓解上下文Token,用一个实际的例子来拆解出来具体是怎么做的。
把握原理,深入了解,才能有判断力。
一、Skill的本质价值认定及实现机制
先说结论,Skill的独特价值在于它解决了一个工程上长期存在的矛盾:领域专家知识的转移问题。你无法把一个医生的诊断能力直接编码进Workflow(路径太多),也无法完整写进SOP(隐性知识太多),更无法存进本体(它描述世界,不描述判断)。
所以,Skill提供了第四条路:把专家的判断框架和注意力焦点,用自然语言约束的形式,注入到模型的推理上下文中。这就是为什么Skill是当前 Agent 范式里“知识载体”最实用的形态——它恰好处于“形式化程度足够让模型理解”和“灵活程度足够让模型推理”的交叉点上。
为了更深入地理解它,我们可以从多个角度来看其本质。
看本质,从三张图表来说明:
1、Agent Skill的三层理解
一个常见的误解是把Skill理解为“工具调用的包装器”——这是表面。更准确的理解是:Skill是上下文的注入单元,它改变的不是模型能调用什么,而是模型在当前情境下“是谁”、“知道什么”、“应该怎么思考”,其传达的是一种约束思想。

2、Skill的四层构成
以SKILL.md为例,Skill的结构分为声明层、触发层、指令层、资源层四部分。
一个完整的Skill构成如下:

这个文件的构成满足层级性,规约如下:
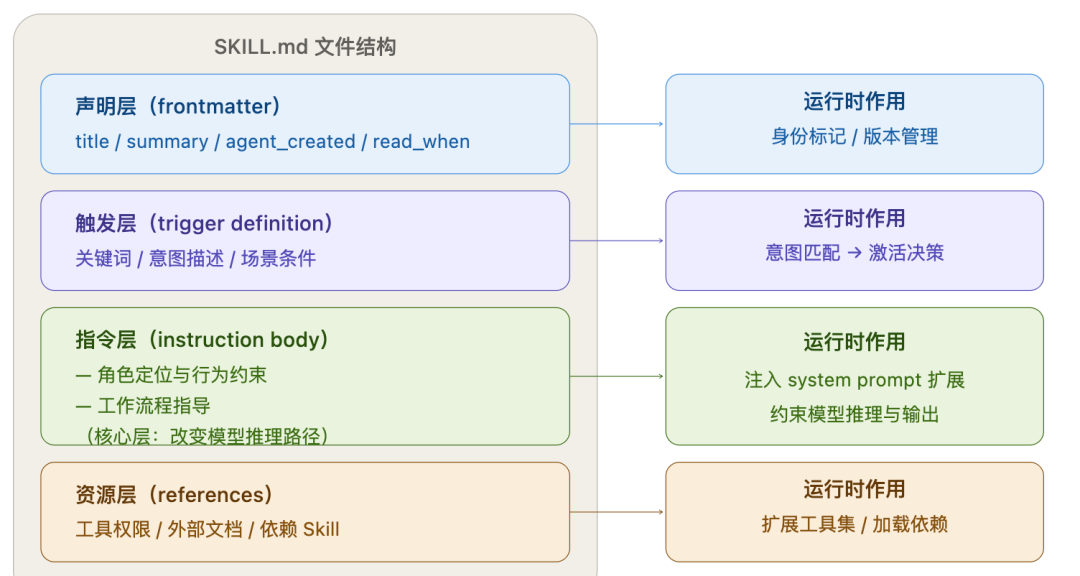
- 声明层 是元信息(frontmatter):描述这个Skill是什么、何时读取、是否由agent创建;
- 触发层 是语义触发词,决定模型何时“拿起”这个Skill;
- 指令层 是核心,它不是伪代码,而是自然语言约束,告诉模型在这个角色下应该怎么思考、拒绝什么、优先什么;
- 资源层 是引用:工具权限、外部文档、依赖的其他Skill。
3、Skill应用的6个阶段
模型支持Skill是工程侧最关键的问题,Skill应用本质上是 动态system prompt扩展,分六个阶段:
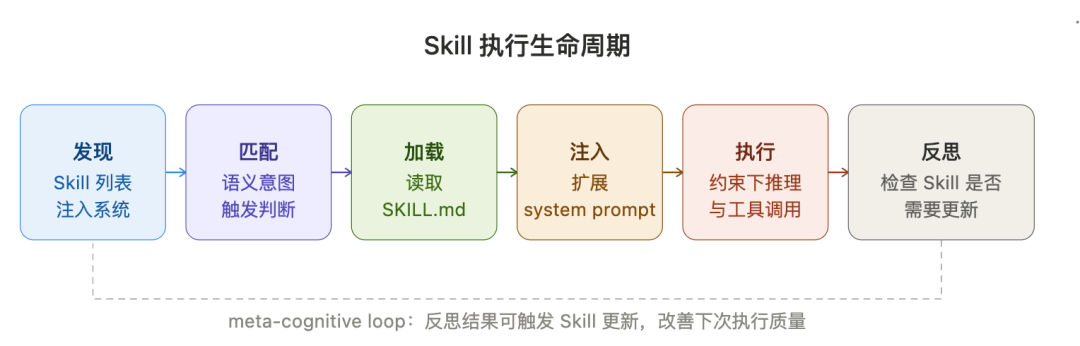
- stage1-发现:Skill列表被注入到system prompt中,模型知道“有哪些Skill可用”;
- stage2-匹配:模型根据用户意图(语义)判断是否需要调用某个Skill(本质是few-shot pattern matching in context);
- stage3-加载:系统读取SKILL.md内容;
- stage4-注入:Skill的指令层内容被追加到当前对话上下文(扩展system prompt或作为assistant turn注入);
- stage5-执行:模型在被扩展的上下文约束下生成回复和工具调用;
- stage6-反思:执行结束后,模型检查Skill是否需要更新(meta-cognitive loop),这其实已经很接近Skill的进化范畴了。
由此可见,Skill不扩展模型的参数知识,而是扩展模型的上下文约束,用自然语言重塑当前决策空间。
二、Skill三级加载机制——缓解上下文Token
与Skill相关的,还有一个十分关键的问题,即压缩上下文Token。这得益于Skill的三级加载机制,不是一次性加载全部,而是按需逐级展开,用于控制上下文开销。如下所示:

其中:
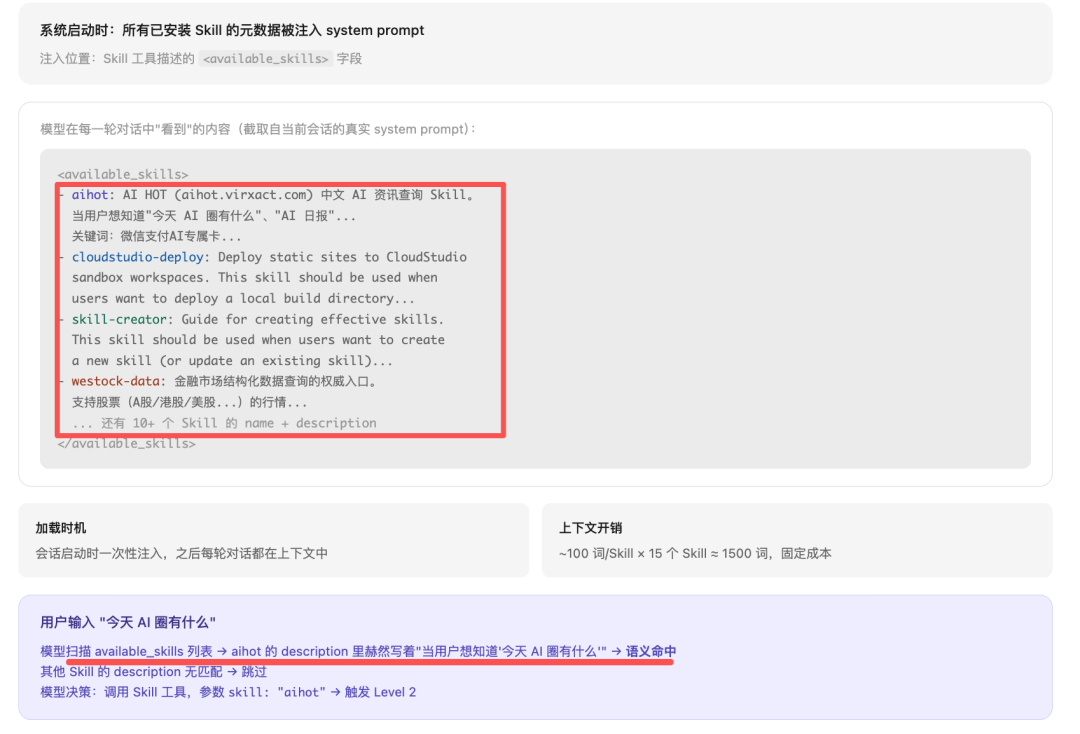
Level1 用~100token/Skill的固定成本建立“可发现性”索引:
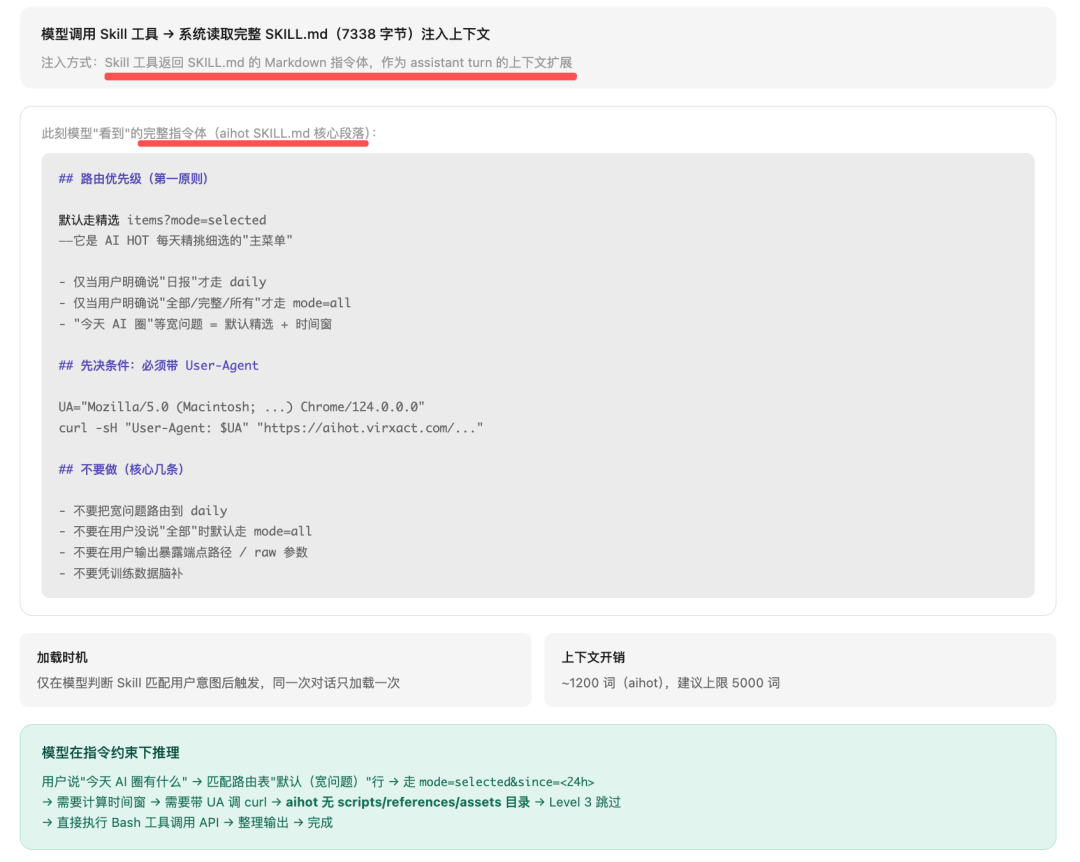
Level2在命中时付出~5000token的可变成本加载执行指令:
Level3按“执行/查阅/引用”三种模式按需读取资源:

三级对应信息检索的“索引→检索→使用”三段式,但检索由模型自身的in-context语义推理完成。
从本质上看,三级加载的本质是上下文窗口的经济学。上下文窗口是稀缺资源(如128K tokens),如果一次性加载所有Skill的完整内容,15个Skill × 5000 token = 75000 token,直接撑爆窗口。渐进式加载解决了这个矛盾:用约1500 token的固定成本(Level1)覆盖所有Skill的“可发现性”,只在命中时才付出约5000 token的可变成本(Level2),资源文件按需读取(Level3)。 这正是信息检索中“索引-加载-使用”三段式的映射。
下面来看一个Skill渐进式加载的完整例子。假设已经有了一个 kg-schema-generator Skill,如下:
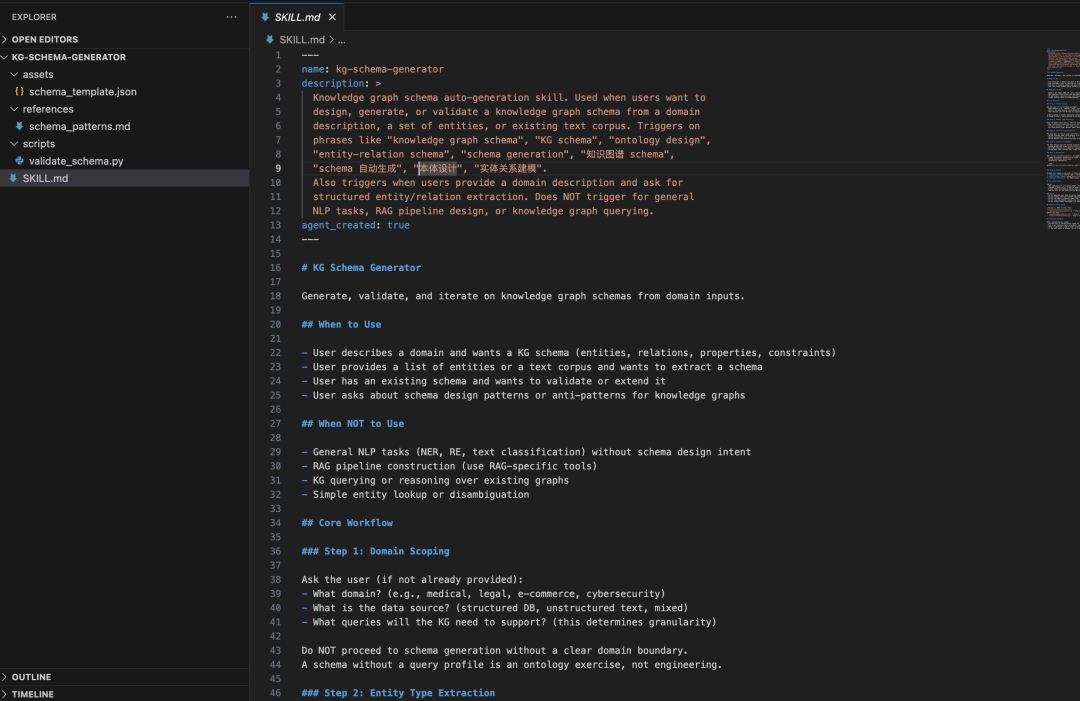
用户发起请求,提问“帮我设计一个医疗领域的知识图谱schema”,执行过程可以分成9个步骤:
Step0、系统启动:扫描Skill目录
系统启动时,扫描~/.workbuddy/skills/和builtin-skills/目录下所有SKILL.md文件。

只读取的 name + description:

然后,注入到system prompt的字段。

此刻模型知道有 kg-schema-generator这个Skill,但不知道它的具体工作流、约束、scripts在哪,只看到了约80 token的description。
此刻,上下文累积:Level1 ~1500 token (固定)。

Step1、用户输入到达:用户侧 ~1500 token (不变)
用户说:“帮我设计一个医疗领域的知识图谱schema”。这句话进入模型上下文,模型需要判断是否需要调用某个Skill。

模型此刻的推理任务:这句话是否匹配某个Skill的description?匹配哪个?这就是Skill的路由分类。
此刻,上下文累积:Level1 ~1500 token(固定) 不变。

Step2、Level1匹配:语义命中
模型扫描 available_skills列表。kg-schema-generator的description里写着“design, generate, or validate a knowledge graph schema”和“知识图谱 schema”,与用户输入语义命中。其他Skill的description无匹配。
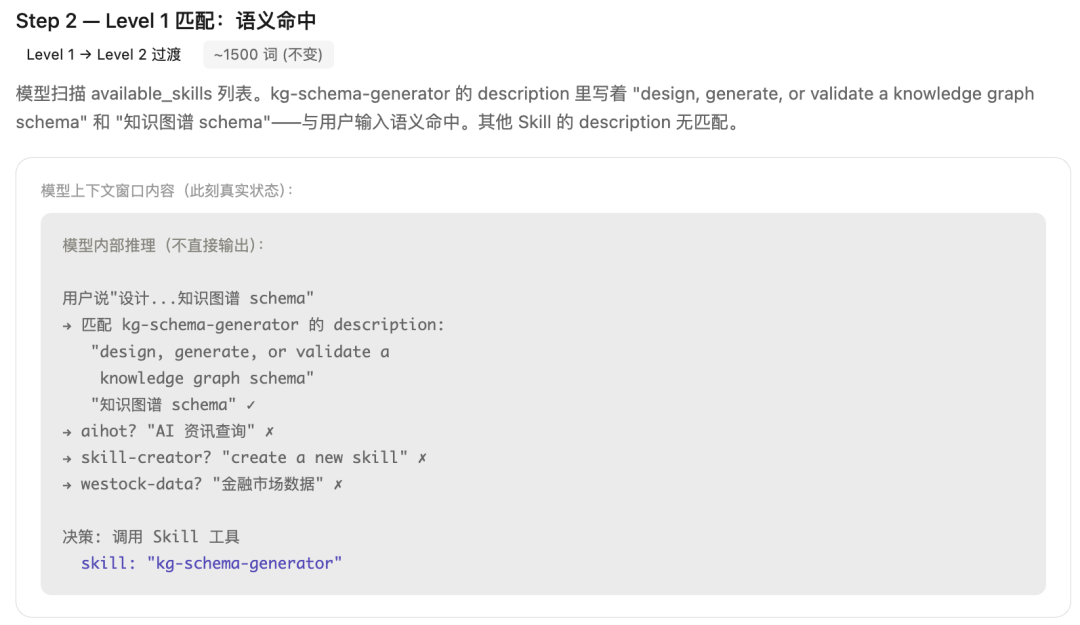
此刻,Level1→Level2过渡,约1500 token (不变)。
Step3、Level2加载:完整SKILL.md注入上下文
模型调用Skill工具 → 系统读取kg-schema-generator/SKILL.md的完整内容(frontmatter + 指令体)→ 作为工具返回值注入上下文。模型此刻“变成”了一个KG schema设计专家。
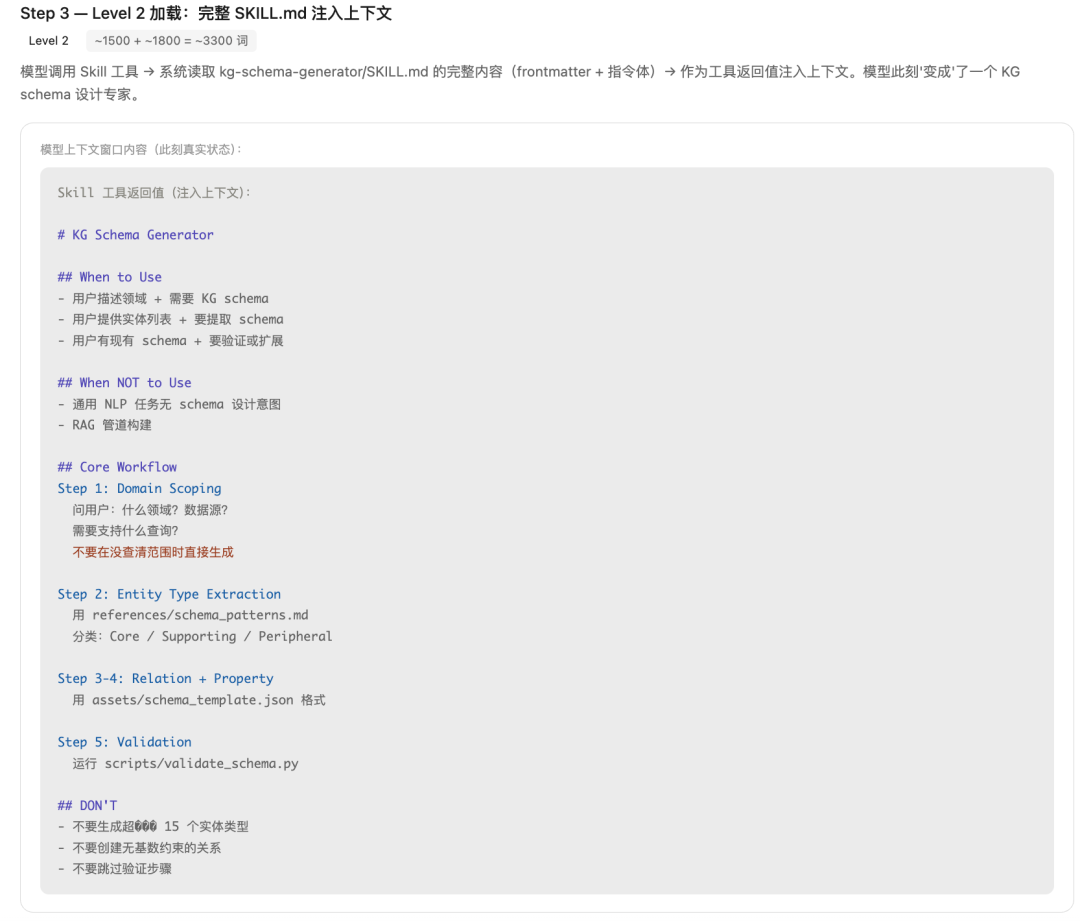
此刻,模型知道了 完整的工作流(6步)、约束(DO/DON’T)、三个资源文件的用法。但还没读取资源文件本身。Level2 ~1500 + ~1800 = ~3300 token。

Step4、工作流Step1:领域界定(模型主动提问)
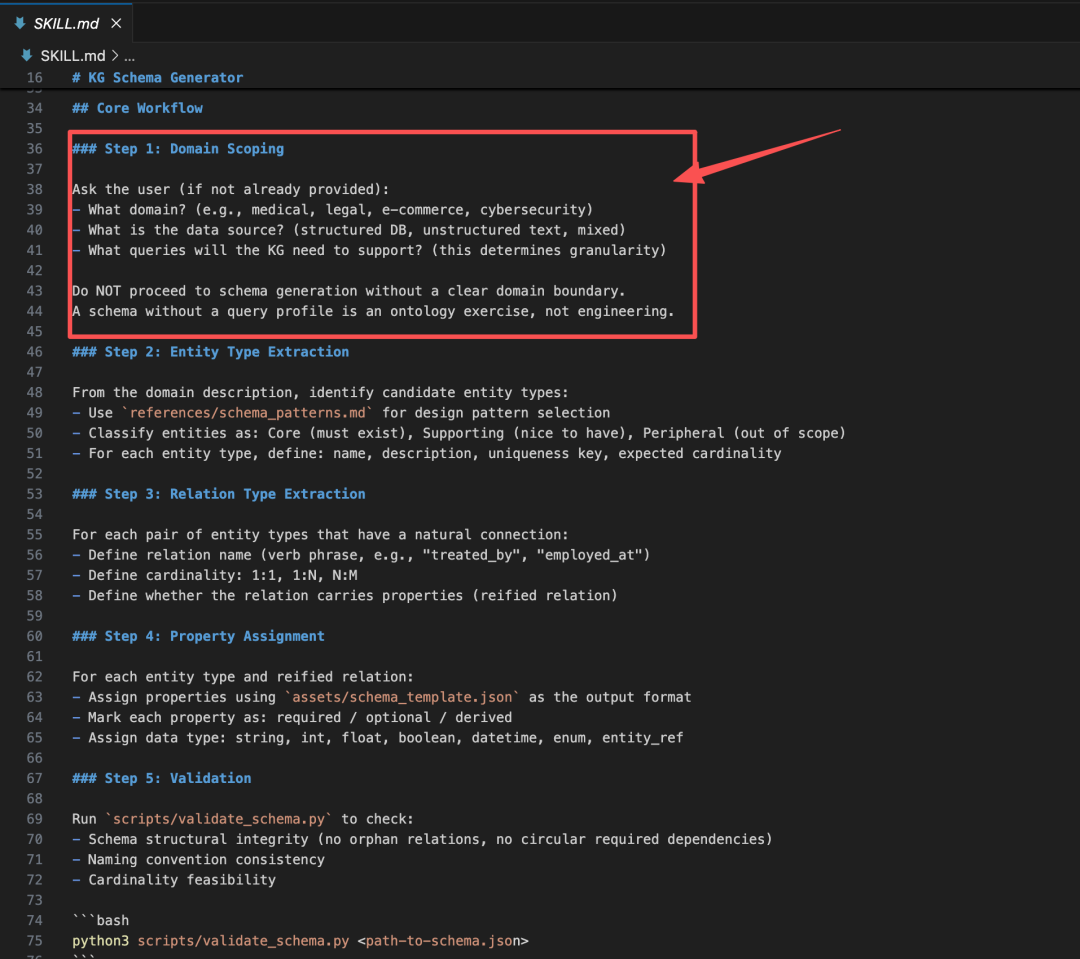
模型遵循SKILL.md的Step1指令:“Ask the user: 什么领域?数据源?需要支持什么查询?”。模型没有直接跳到schema生成,而是先问清楚边界,这正是SKILL.md约束的效果。
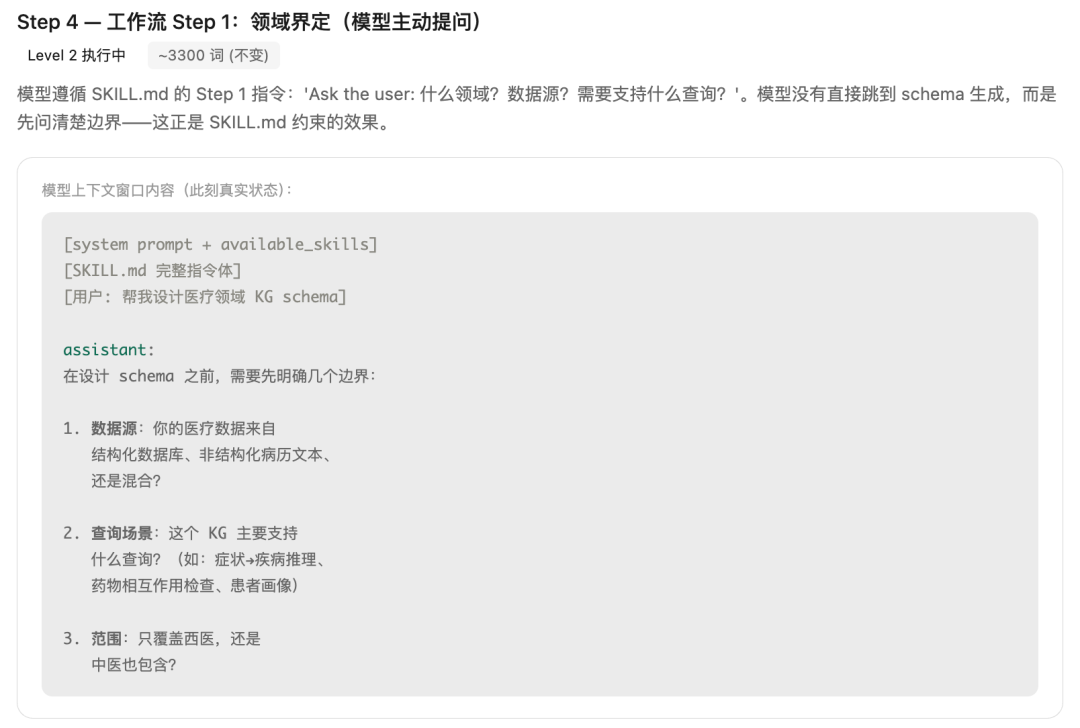
此刻,上下文累积,Level2 执行中 ~3300 token (不变)。

Step5、Level3加载:按需读取 references/
用户回答后,模型执行 Step2(实体类型提取) 。SKILL.md说“Use references/schema_patterns.md for design pattern selection”。

模型需要知道医疗领域该用什么schema模式 → Grep搜索references文件 → 读取相关段落(不是整个文件)。
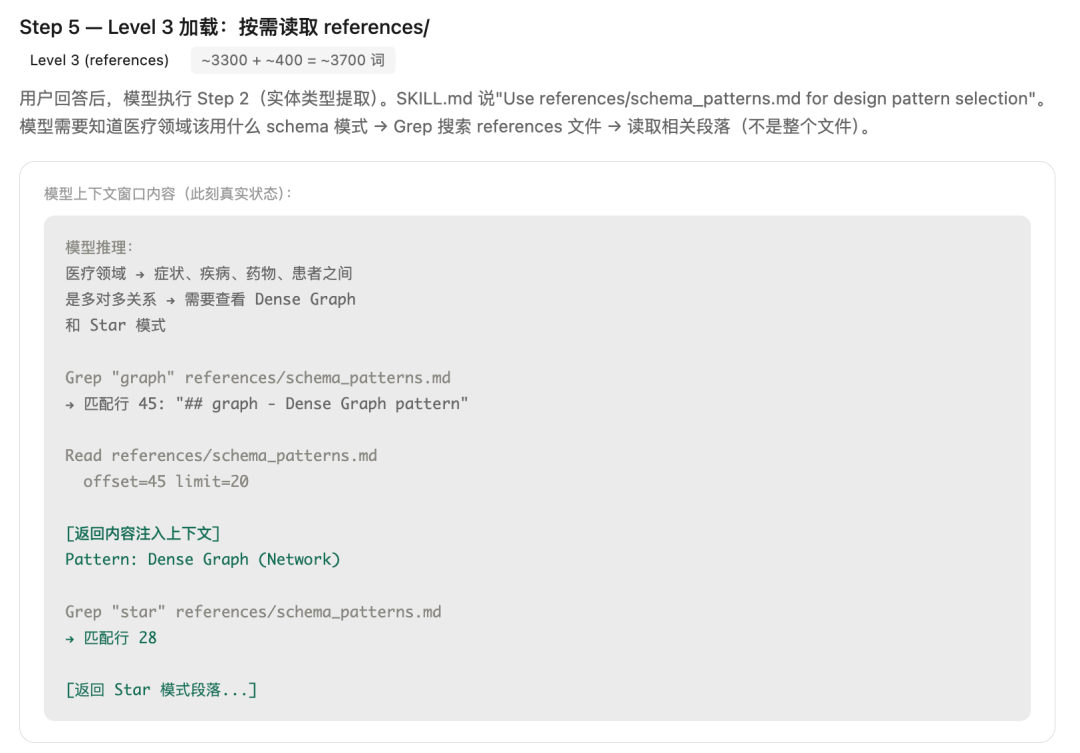
这一步,模 型用Grep定位到需要的段落,再用Read的offset/limit只读那20行。整个references文件有90行,但只有约30行进入上下文。这就是Level3的“按段读取”。
此刻上下文token累积:Level3 (references),~3300 + ~400 = ~3700 token。

Step6、工作流Step2-4:生成Schema(引用 assets/)
模型基于领域知识和刚读到的设计模式,生成完整的schema。
输出格式引用 assets/schema_template.json,模型知道模板结构(SKILL.md里描述了),直接按格式输出,不需要把模板文件读入上下文。
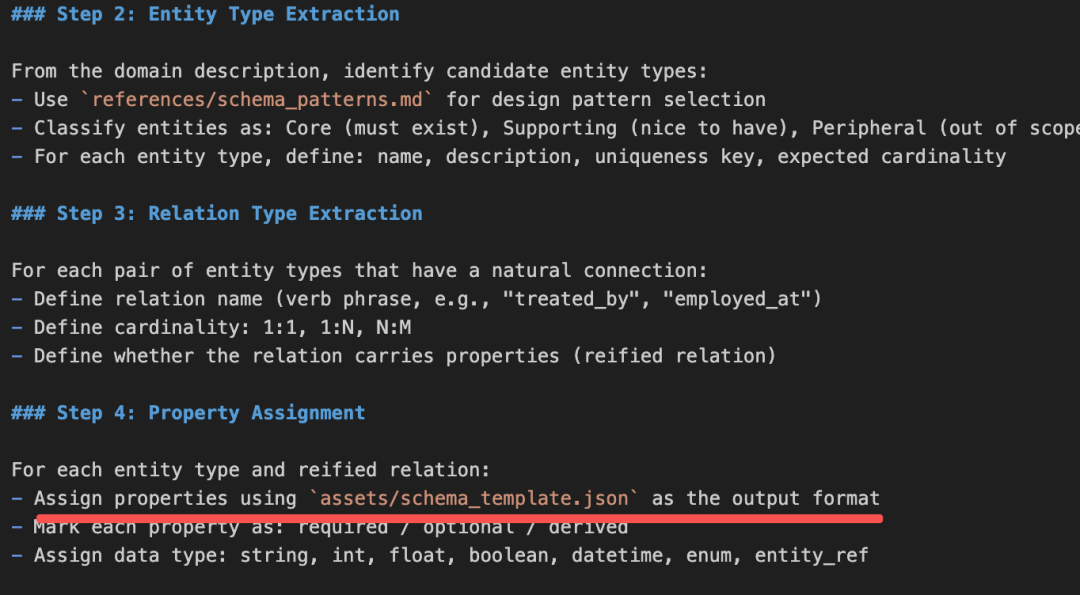
这一步,assets/schema_template.json的内容不进入上下文。模型从SKILL.md的Resource Usage Guide表格知道了模板的字段结构(entity_types, relation_types, design_rationale),直接按格式生成。如果模板结构复杂到SKILL.md描述不下,模型才会Read它。
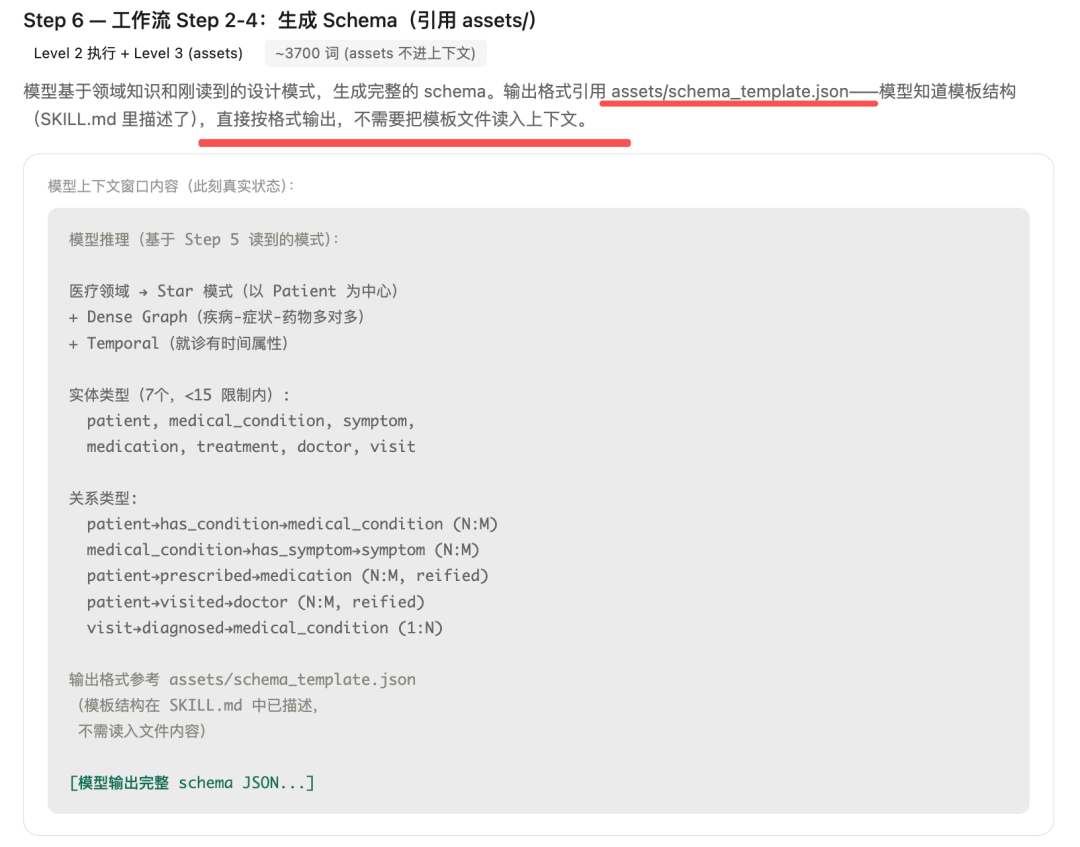
此刻的 上下文累积:Level2 执行 + Level3 (assets) ~3700 token (assets不进上下文)。

Step7、Level3加载:执行 scripts/(不读入上下文)
模型执行 Step5 (Validation)。
SKILL.md说“Run scripts/validate_schema.py”,模型用Bash工具执行脚本,传入生成的schema JSON文件路径。
这一步,脚本源代码从不进入上下文,只有执行结果进入。这是Level3的设计巧思:scripts/里的代码可以无限长,但上下文开销永远是0。模型只需要知道脚本路径和用法(SKILL.md里写了),执行后只拿回stdout结果。这一步累积上下文开销,Level3 (scripts) ~3700 token (脚本不进上下文)。

Step8、最终输出:三层呈现
模型按 SKILL.md Step6 的要求,

以三层格式呈现结果:摘要表格 + 完整Schema JSON + 设计理据。然后主动询问是否需要迭代。
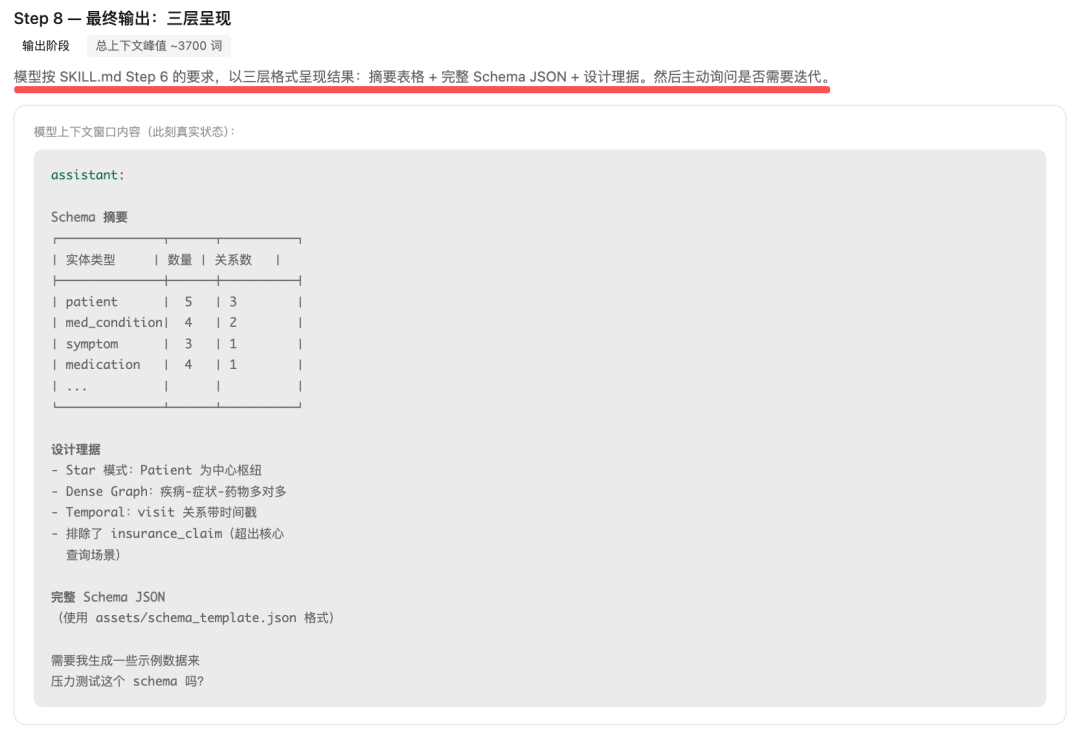
因此,整个流程走完,回顾上下文开销:L1 固定 ~1500 token + L2 ~1800 token + L3 references ~400 token + L3 scripts 0 token + L3 assets 0 token = 总计 ~3700 token。如果不用渐进式加载,一次性加载全部16个Skill的完整内容+所有资源 = ~80000+ token。
但这时候,会流露出一个问题:如此一来,对大模型能力的要求会比较高,它需要知道如何做拆解,如何去调用工具,如何去引用。并且,也对Skill的写法提出了要求,例如对scripts的正确引用、对description的正确表达、对step执行的正确描述等等。
总而言之,Skill是一个庞大的工程。而对其设计和加载机制的理解,正是我们构建高效Agent的起点。在 云栈社区,你还可以找到更多关于Agent、RAG等前沿技术的深度实践分享。
老刘,主页:https://liuhuanyong.github.io 。
 发表于 昨天 23:36
|
查看: 4|
回复: 0
发表于 昨天 23:36
|
查看: 4|
回复: 0
