一条650万人看过的帖子
事情要从6月7号凌晨说起。Peter Steinberger 发了一条帖子,浏览量后来冲到了650万。
"你不应该再手动给 AI 写 prompt 了。你应该设计循环,让循环来替你 prompt。"
评论区瞬间沸腾。有人称其为今年最重要的观点,有人嗤之以鼻说不过是新瓶装旧酒。但有一条回复点中了关键——
"没人知道这到底是什么意思,除了他和 Boris。"
Boris Cherny 是 Anthropic 的 Claude Code 负责人,他的表述更加直白:
"我已经不写 prompt 了。我有循环在跑,循环会自动 prompt Claude、自动决定下一步。我的工作就是写循环。"
NVIDIA 的黄仁勋也表达过类似的判断:prompt 正在过时,未来的开发者写的是循环(loop)。
三个人,三个视角,都在讲同一件事。它叫 Loop Engineering。
这篇文章会把这件事掰开揉碎讲清楚:Loop Engineering 到底指什么,它和 Prompt Engineering 的差别在哪里,以及你现在就能上手的实践框架。
Prompt Engineering 到底哪里不够用了
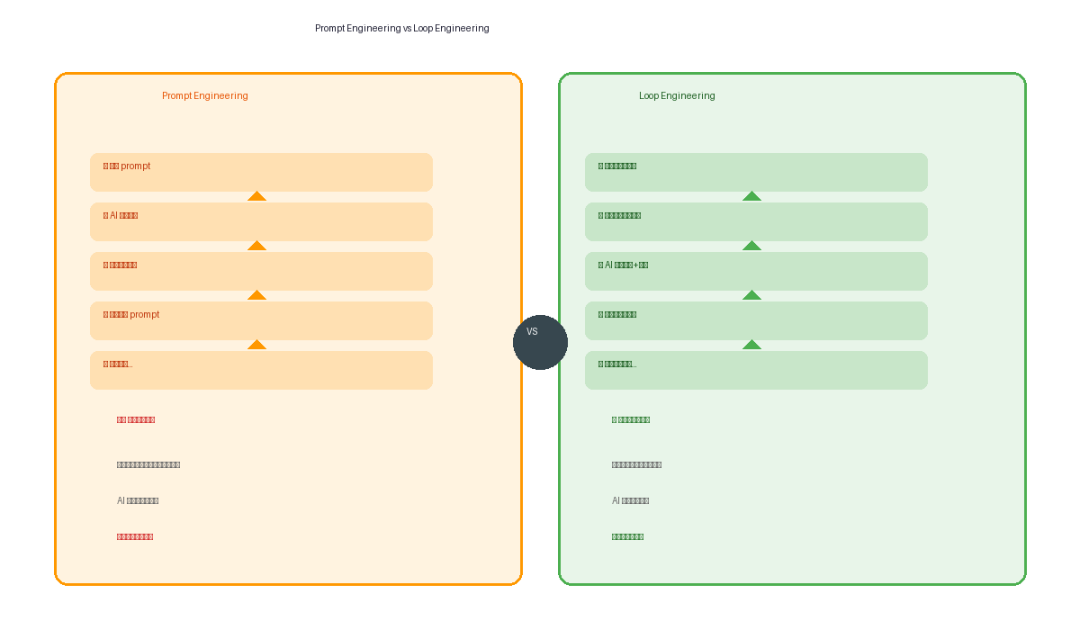
过去两年,我们跟 AI 编程助手的协作模式几乎没变过:
你写一段 prompt → AI 返回结果 → 你检查对不对 → 不对就改 prompt 再来一轮……如此反复。
这个模式最根本的问题在于:你就是循环本身。
每一轮都需要你介入、判断、调整。AI 更像一个单次执行器——喂它什么指令,它就干什么,做完就停。
2024 年之前这或许还行。但到了 2026 年,AI 编程助手已经能处理越来越复杂的任务。一个 agent 甚至可以连续运行 12 个小时。Anthropic 的内部数据很有意思:一年前 agent 平均运行时长才 1 小时,如今是 12 小时。
那么问题来了:一个能连续跑 12 小时的 agent,你总不能每隔 5 分钟就切回来瞅一眼、补一条新 prompt 吧?
Prompt Engineering 的瓶颈,并不是 prompt 写得好不好,而是“人”变成了整条循环的瓶颈。
Loop Engineering:把“人”从循环里移出来
Google Cloud AI 总监 Addy Osmani 下过一个简洁的定义:
"Loop Engineering 就是把你从 prompt 的执行者变成 prompt 系统的设计者。你设计一个循环,让 AI 在循环里自己迭代,直到完成目标。"
用人话翻译一下:
以前你是那个一条条写 prompt 的人。现在你要成为设计“prompt 工厂”的人。
这座工厂能自动发现任务、自动分配给 AI、自动检查结果、自动决定下一步。你只需要在关键节点设置检查站。
这可不是停留在纸面上的概念。Claude Code 和 OpenAI 的 Codex 都已经内置了完整的 Loop Engineering 原语,现在就能用。
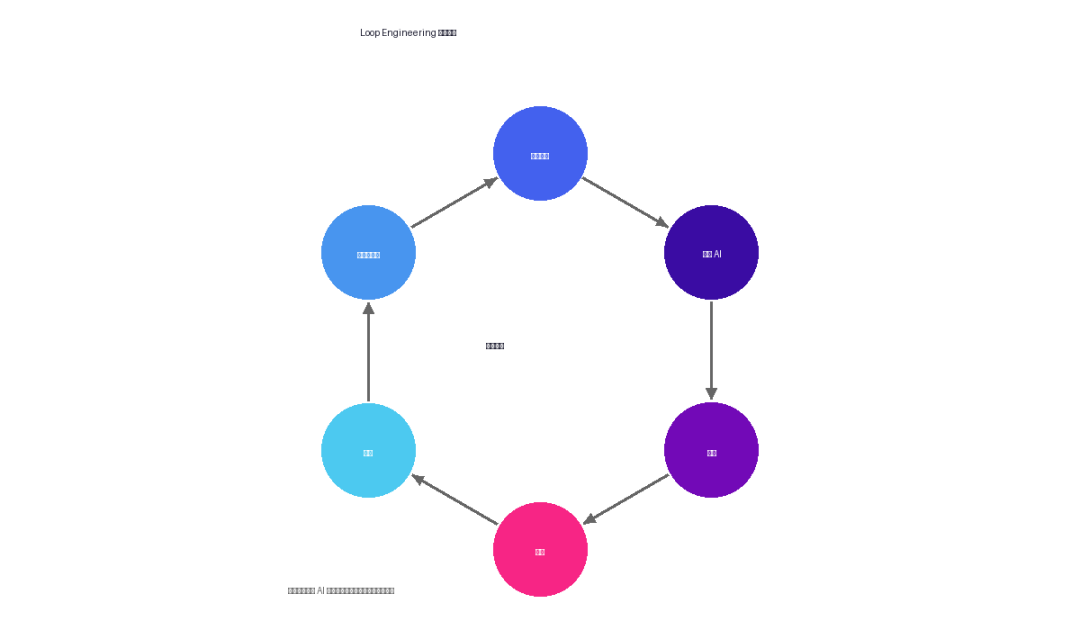
一个 Loop 长什么样:五个零件 + 一块记忆
Addy Osmani 把 Loop Engineering 的核心构件归纳为五点。不管在 Claude Code 还是 Codex 里,形状都一样——仅仅叫法不同。
1. 自动化(Automations)——循环的心跳
这是让 loop 成为真正“循环”而不仅仅是“跑一次就结束”的关键。
在 Codex 中,你可以在 Automations 标签页创建自动化任务:选定项目、编写 prompt、设定频率、选择运行环境。跑出来的结果会进入 Triage 收件箱,什么都没发现的任务则自动归档。
在 Claude Code 里,用 /loop 设定循环频率,用 /goal 设定终止条件——例如“所有测试通过且 lint 无报错”。条件达成即停,没达成就继续。
OpenAI 内部已经在用这类自动化做每日 issue 分拣、CI 失败总结、每周 commit 简报甚至 bug 猎捕。这些事上周还需要人盯着,现在循环自己跑着就干完了。
关键洞察:没有自动化,loop 无非就是“你手动跑了一次”。
2. 工作树(Worktrees)——防止 Agent 打架
两个 agent 同时修改同一个文件,就好比两个工程师往同一个分支猛推代码——十有八九要撞车。
Git worktree 的思路简单实用:给每个 agent 分配一个独立的工作目录和独立分支,但共享同一份仓库历史。一个 agent 的改动不会碰到另一个 agent 的 checkout。
Codex 内置了 worktree 支持。Claude Code 则通过 --worktree 标志或 isolation: worktree 配置子 agent,用完自动清理。
这解决了一个很少被摊开讨论却极其普通的问题:并行 agent 的文件冲突。
3. 技能(Skills)——把项目知识“写死”
AI 每次启动都是一张白纸。它不知道你的代码规范、测试惯例、部署流程。如果你不主动告诉它,它就靠猜。
Skills 就是把这些知识固化成文档——通常是 SKILL.md 或 AGENTS.md 文件——放在项目里。agent 启动时自动读取,你不用每次重复交代。
正因如此,同一款 AI 工具在不同人手里表现差距会如此悬殊——差别不在模型能力,而在 Skills 文档的质量。
4. 插件和连接器(Plugins & Connectors)——让 AI 接入你的工具链
AI agent 不能只活在沙箱里。它需要读你的 Linear 看板、查你的 GitHub issue、调你的 API。
MCP(Model Context Protocol)就是干这件事的——它充当 AI 与外部工具之间的标准接口。Codex 和 Claude Code 都已经支持 MCP 服务器和各类插件。
5. 子 Agent(Sub-agents)——一个出主意,一个挑毛病
Loop Engineering 里最反直觉的设计大概是:写代码的 agent 和检查代码的 agent 必须分离。
道理很简单,考试不能自己给自己打分。一个 agent 负责生成方案,另一个 agent 独立验证——跑测试、做 lint、检查类型。验证 agent 有权说“不行,重来”。
Peter Steinberger 说得十分到位:
"loop 只是一半。另一半是在 loop 里放一个能说‘不’的东西:一个测试、一个类型检查、一个真正的错误。一个没有反馈的 loop,只是 agent 在自言自语。"
6. 记忆(Memory)——最不起眼但最关键
一块磁盘上的 Markdown 文件,记录着“什么做完了、什么还没做”。
听起来朴素得不像关键技术,但 Addy Osmani 却认为这是每个长时运行 agent 的命脉:
"模型在两次运行之间会忘记一切。所以记忆必须在磁盘上,不能只存在上下文里。agent 会忘,但仓库不会。"
在 Claude Code 里,这体现为 AGENTS.md 和进度文件;在 Codex 里则是 Markdown 或 Linear 连接器。
Prompt、Context、Loop:三层楼的关系
许多人把这三个概念混为一谈,或者认为后者会“取代”前者。其实它们是叠加嵌套的关系:
| 层级 |
关注什么 |
一句话解释 |
| Prompt Engineering |
你发给 AI 的那条指令 |
怎么写一条好 prompt |
| Context Engineering |
这条指令周围的上下文 |
给 AI 什么信息它才能做好 |
| Loop Engineering |
执行 prompt 的整个系统 |
谁来 prompt、什么时候 prompt、结果怎么验证 |
它们不是互相取代,而是互相嵌套。 Loop Engineering 包裹着 Context Engineering,Context Engineering 包裹着 Prompt Engineering。
可以这样理解:
- Prompt Engineering 是“教 AI 说人话”
- Context Engineering 是“给 AI 足够的背景信息”
- Loop Engineering 是“设计一个不用你盯着就能跑的系统”
三层都精通的人,才是 2026 年真正稀缺的 AI 工程师。
我的判断:Loop Engineering 值得押,但有条件
话说到这儿,我得给一个明确的倾向——我认为 Loop Engineering 值得现在就开始投入学习。
理由有三:
第一,Claude Code 和 Codex 都已经内置了完整的 loop 原语。这不是停留在概念层,而是已经落地到产品里的东西。
第二,Anthropic 的数据很说明问题:agent 运行时长一年涨了 12 倍。跑得更久的 agent 天然需要用 loop 来治理,而不是用人来盯着。
第三,Peter Steinberger 那条 650 万浏览量的帖子本身就是一个信号——社区正在寻找 prompt 之后的下一个范式。
但是,这需要条件。
如果日常只用 AI 问一两个简单问题,prompt 工程完全够用,没必要折腾 loop。可如果你的场景是让 AI 处理复杂的、多步骤、需要反复验证的任务——比如代码重构、自动化测试、持续集成——那么 loop 就是你的效率杠杆。
我的建议很直白:如果你每天用 AI 写代码超过 1 小时,就从今天开始学 Loop Engineering。如果只是偶尔问问问题,先把 prompt 写好再说。
你现在就能开始的三步
不需要高阶框架,也不用等新工具。Loop Engineering 的核心思想今天就能落地。
第一步:从一个定时任务开始
找一件你每天必须手动处理、而且判断标准明确的事。比如:
- 每天检查 GitHub issue 里有没有新的 bug report
- 每天跑一遍测试,失败了就尝试修复
- 每天审一遍 PR,有冲突就发出提醒
用 Claude Code 的 /loop 或者 Codex 的 Automations,设置一个定时任务。prompt 要写清楚:做什么、检查标准是什么、什么情况下算完成。
第二步:加上验证 agent
不要让同一个 AI 既写代码又检查代码。利用 sub-agent 功能,一个 agent 负责产出,另一个 agent 负责运行测试并检查。验证 agent 的 prompt 要明确:只检查、不修改、有权打回。
第三步:加上磁盘记忆
在项目根目录创建一个 PROGRESS.md,记录每次 loop 的结果。agent 每次启动时读取,知道哪些做完了、哪些还没做、上次被打回的原因是什么。
这三步走下来,你就拥有了一个最小可用的 Loop。它可能还挺粗糙,但它能跑。能跑起来再慢慢打磨。
这件事真正的信号
Loop Engineering 并非什么革命性新发明。它的底层逻辑——OODA 循环——在军事和控制论领域已经存在了几十年。
但它忽然流行起来,揭示了一个更深的趋势:AI 开发的重心正在从“模型能力”转向“系统设计”。
一年前大家还在比谁的 prompt 写得好。现在比的,是谁的 loop 设计得巧妙。
模型是公共基础设施,但你围绕模型搭建的自动化体系——发现任务、分配任务、验证结果、记住教训——这才是你的护城河。
Addy Osmani 有句话很值得记住:
"Loop Engineering 坐在 Harness 的上一层。Harness 是单个 agent 跑的环境;Loop 是在 Harness 上面加了定时器、小助手和自我喂养机制。"
你不再是在“用”AI,你是在“设计”一个运用 AI 的系统。 这是从用户到架构师的跃迁。而这个跃迁,正在定义 2026 年 AI 工程师的核心竞争力。
你的下一步
不必一步到位。
从今天开始,找一件重复性高、判断标准明确的事,设一个自动化的 loop。让它跑上一周,看看效果。
当你的 loop 真正跑起来时,你会发现一件有趣的事:你花在“写 prompt”上的时间急剧减少,而花在“设计系统”上的时间急剧增加。 这并不是效率下降——而是你的工作性质变了。
Peter Steinberger 那条帖子下面,有一条不太起眼的回复我特别喜欢:
"一年前我们讨论的是 prompt。半年前是 context。现在是 loop。半年后会是什么?"
答案多半是:半年后,loop 也会变成默认配置,而你会开始设计更上层的东西。
但前提是——你得先从 loop 开始。
 发表于 昨天 23:58
|
查看: 5|
回复: 0
发表于 昨天 23:58
|
查看: 5|
回复: 0
