日前,由UC Berkeley打造的CyberGym,被业内称为AI安全“奥运会”。考题全部来自真实开源漏洞,规模达到传统测评基准的7.5倍,要求AI自主挖掘漏洞并输出可复现的攻击代码(PoC),全球大厂悉数参战。


图片来源:新智元

国产黑马凭空杀出
就在GPT-5.5、Claude等海外顶级模型同台比拼时,一个代号 MopMonk(扫地僧)的国产AI突然杀进榜单,以73.1%的成功率拿下全球第七、国内第一,成绩直逼OpenAI。
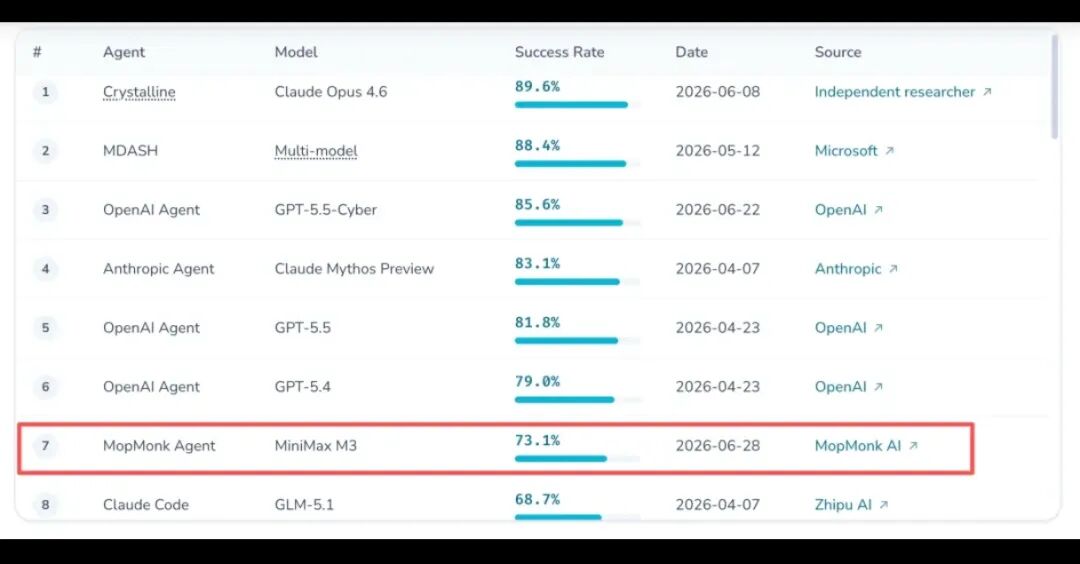
诡异的是这支团队全程保持静默:没有发布会、没有官方宣传,只放出开源技术文档,团队背景至今成谜。取名“扫地僧”,充满武侠韵味——不显山露水,一出手就能与全球巨头掰手腕。

底层底气:MiniMax M3 打造强大基座
扫地僧的底层模型是国产开源模型 MiniMax M3,这也是它突围的核心根基。该模型集成了三大王牌能力:百万 token 超长上下文、顶尖代码能力,以及原生多模态。
面对 CyberGym 动辄百万行的大型代码库,1M 上下文窗口能直接吃进整个项目文件;代码跑分对标海外闭源大模型,具备长周期自主迭代与自我纠错能力,为漏洞挖掘提供了充足的算力与推理支撑。
制胜关键:专属 Harness 框架,补齐 AI 行动力
很多大模型看得懂漏洞,却写不出有效的 PoC,问题就卡在协调层 Harness 上,而这正是扫地僧的独门内功。
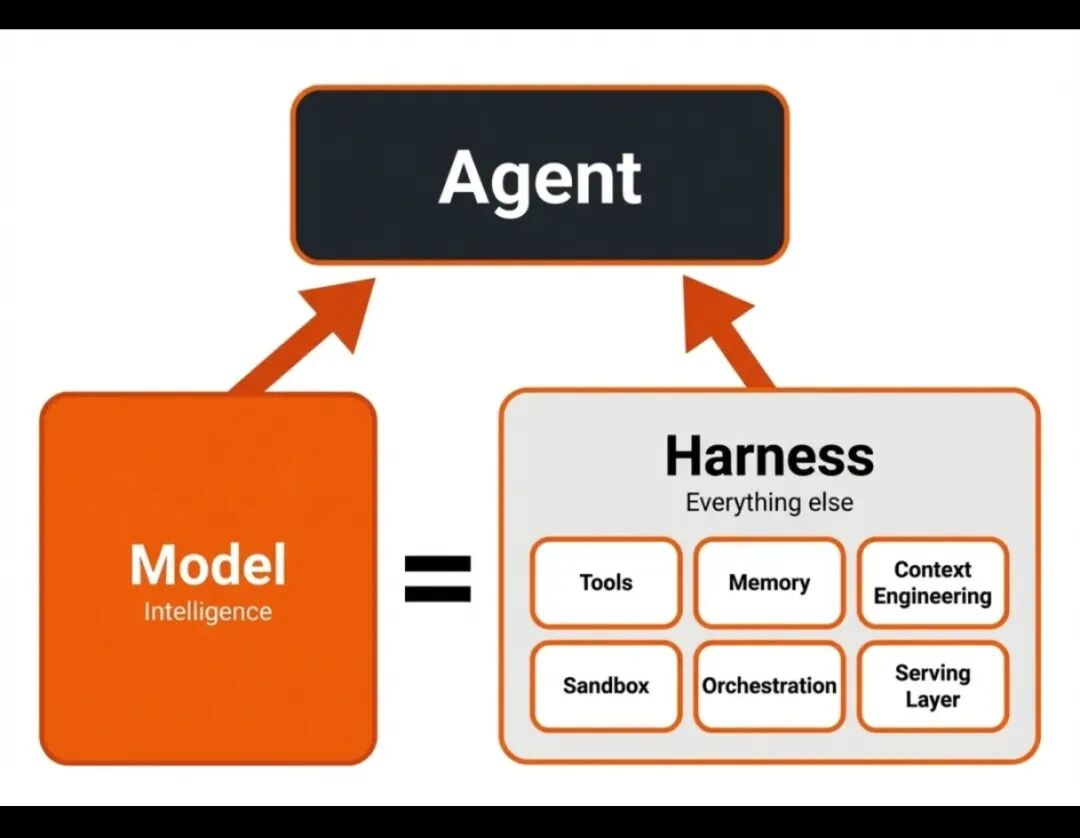
整套框架分三层核心设计:
- 结构化漏洞记忆:分类存储代码路径、失败案例、测试约束,无需每次重读全部代码,大幅降低计算消耗;
- 记忆驱动迭代挖掘:每轮测试结果自动留存,基于过往经验缩小搜索范围,减少无效试错;
- 多智能体并行探索:多个 Agent 共享记忆,从不同方向同步排查漏洞,互不重复、效率翻倍。
简单来说:M3 负责思考与判断,Harness 负责落地执行,两者深度绑定,把模型的智商转化为实打实的漏洞挖掘能力。
行业风向变了:堆参数已成过去式
此前行业普遍内卷模型参数规模,但 CyberGym 榜单给出了全新的结论:
Agent执行框架、调度工程的价值,远大于单纯扩充参数。
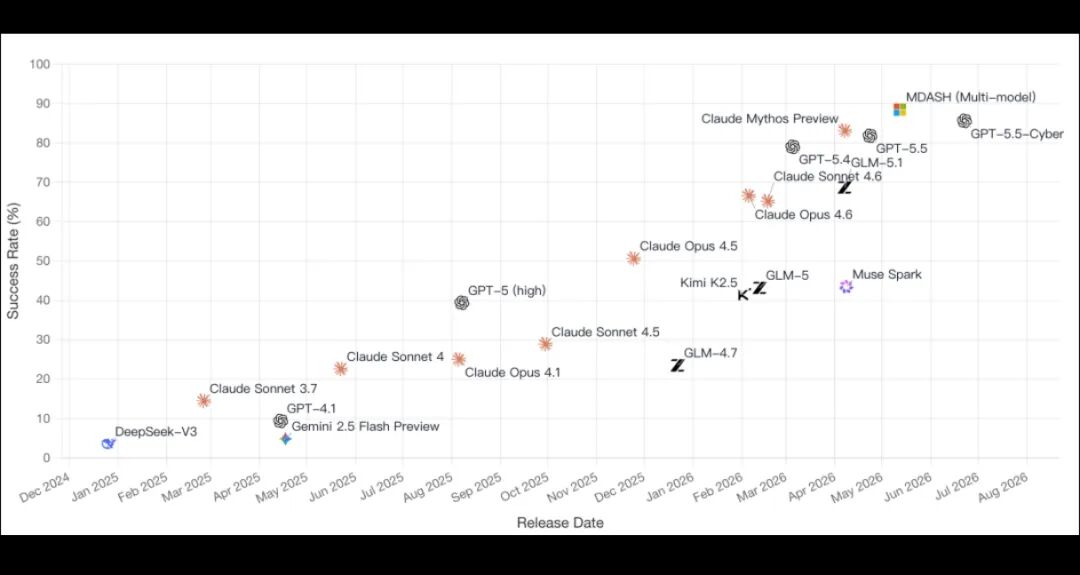
模型会持续迭代,但打磨成熟的 Harness 调度体系可以长期复用,具备显著的复利价值。扫地僧这套方案给国内 AI 安全团队指明了一条新路:用好优质开源基座,深耕智能体调度工程,完全有希望追上海外头部产品。
神秘扫地僧究竟来自哪里?
现有线索全部指向国内:东方武侠代号、上海 MiniMax 基座,以及深耕网络安全的技术路线。业内普遍猜测这是一支上海本土的 AI 安全团队。
“起这种名字大概率是阿里”
“我喜欢这个名字,充满了武侠的浪漫,只有中国人懂的浪漫。”
不过官方至今没有透露企业或团队信息,只开放 GitHub 开源仓库。这名低调的国产“扫地僧”,也留下一个悬念:到底是哪家团队打造了这匹黑马? |  发表于 15 小时前
|
查看: 36|
回复: 0
发表于 15 小时前
|
查看: 36|
回复: 0
