💥 工业级 shared_ptr 实现为何稀缺?
在 GitHub 上搜索,确实能找到不少 shared_ptr 的实现。但坦率地说,其中能够达到工业级标准的寥寥无几。
大部分开源实现存在以下普遍问题:
- ❌ 功能缺失:仅实现基本引用计数,缺乏
weak_ptr、make_shared 等关键特性。
- ❌ 玩具级别:代码仅几百行,未考虑多线程安全性。
- ❌ 学习困难:直接抛出一整段代码,初学者难以理解实现脉络。
- ❌ 缺乏讲解:只有代码,没有深入的设计思路和细节考量说明。
更重要的是,即便看懂了别人的代码,你依然难以完成从 0 到 1 的独立实现。这正是我们决定深入探讨并动手实践的核心原因。
🎯 为何选择 shared_ptr 作为深度实践项目?
选择 shared_ptr 作为实战项目,经过了多方面的考量:
面试高频与实用价值
- 面试必考:智能指针几乎是所有中高级 C++ 面试的核心考点。
- 工业标准:
std::shared_ptr 是现代 C++ 资源管理的基石组件,掌握它意味着深入理解了现代 C++ 的核心思想。
- 知识密集:其实现涵盖了内存管理、多线程并发、模板编程、RAII(资源获取即初始化)等多个核心概念。
技术挑战性
- 设计复杂:控制块管理、类型擦除、弱引用机制,每一处都体现了精妙的设计。
- 性能敏感:作为基础库组件,任何细微的性能优化都至关重要。
- 标准对标:只有实现出能与
std::shared_ptr 性能相媲美的版本,才算真正成功。
🔥 工业级 CraftedPtr 实现的核心特性
本实现 100% 从零开始设计编码,包括架构设计、接口定义、每一行代码实现及测试,确保深度掌握。
核心特性(完全对标 std::shared_ptr)
✅ 完整的引用计数机制 ✅ 线程安全(原子操作)
✅ 自定义删除器支持 ✅ weak_ptr 完整实现
✅ make_shared 性能优化 ✅ 别名构造函数
✅ 类型转换函数族 ✅ 异常安全保证
✅ 标准兼容的接口 ✅ 完善的比较运算符
性能表现
性能测试表明,该实现与标准库实现差距极小,部分场景甚至更优。
[拷贝构造 - 1000万次]
std::shared_ptr: 84.53 ms
my::shared_ptr: 91.83 ms ← 差距仅 8.6%
[weak_ptr.lock() - 100万次]
std::weak_ptr: 20.62 ms
my::weak_ptr: 11.26 ms ← 性能提升 45%
[多线程并发 - 8线程]
std::shared_ptr: 232.25 ms
my::shared_ptr: 207.29 ms ← 性能提升 10.7%
项目架构:精心设计的分层结构
整个项目采用经典的分层设计,确保了代码的清晰度和可维护性。
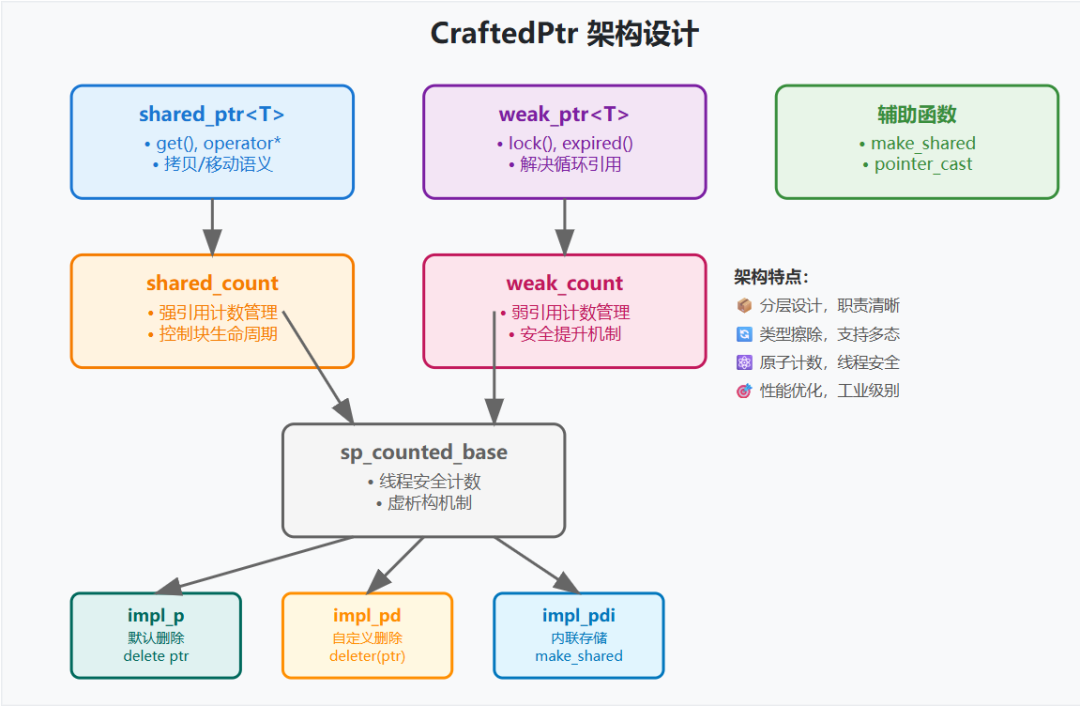
核心用户接口层
shared_ptr<T> 和 weak_ptr<T>:用户直接使用的智能指针接口,封装内部复杂性。
计数管理层
shared_count 和 weak_count:封装引用计数管理逻辑,负责控制块的生命周期。
线程安全控制块层
sp_counted_base:控制块的抽象基类,使用原子操作保证多线程环境下的安全,这是实现高性能并发编程的关键。
策略实现层
sp_counted_impl_p:默认删除器实现。sp_counted_impl_pd:支持自定义删除器。sp_counted_impl_pdi:内联存储优化实现(用于 make_shared)。
便利工厂层
make_shared:高性能对象创建工厂函数。static_pointer_cast 等类型转换函数族。
这种分层架构的优势在于:职责分离、易于扩展、类型安全,并为每层进行针对性的性能优化提供了可能。
核心实现代码解析:make_shared 的优化
以下是 make_shared 性能优化的核心实现,展示了如何通过单次内存分配来提升效率。
// sp_counted_impl_pdi: Inplace 存储实现
template<typename T>
class sp_counted_impl_pdi : public sp_counted_base {
private:
// 使用 aligned_storage 确保内存正确对齐
typename std::aligned_storage<sizeof(T), alignof(T)>::type storage_;
public:
// 完美转发参数,使用 placement new 构造对象
template<typename... Args>
explicit sp_counted_impl_pdi(Args&&... args) {
::new(static_cast<void*>(&storage_)) T(std::forward<Args>(args)...);
}
T* get_pointer() noexcept {
return reinterpret_cast<T*>(&storage_);
}
void dispose() noexcept override {
get_pointer()->~T(); // 仅调用析构函数,内存随控制块一同释放
}
};
// make_shared 工厂函数
template<typename T, typename... Args>
shared_ptr<T> make_shared(Args&&... args) {
detail::shared_count pn(
detail::sp_inplace_tag<T>{},
std::forward<Args>(args)...
);
return shared_ptr<T>(detail::sp_inplace_tag<T>{}, pn);
}
这段简洁代码背后蕴含了深刻的设计思路:
- 单次内存分配:对象和控制块被分配在同一块连续内存中,显著减少内存碎片和分配开销。
- 完美转发:通过
std::forward 保持参数的原始值类别(左值/右值),实现最优构造。
- 内存对齐:使用
aligned_storage 保证对象满足其对齐要求,这对系统性能和某些硬件操作至关重要。
- RAII 管理:控制块销毁时自动析构管理的对象,杜绝资源泄漏。
使用示例:与标准库完全一致
该实现的目标之一就是提供与 std::shared_ptr 完全一致的使用体验。
#include "my_shared_ptr.hpp"
#include <iostream>
class Resource {
int data_;
public:
Resource(int x) : data_(x) {
std::cout << "Resource(" << data_ << ") 构造\n";
}
~Resource() {
std::cout << "Resource(" << data_ << ") 析构\n";
}
int get() const { return data_; }
};
int main() {
{
// 使用 make_shared 创建智能指针
auto ptr1 = my::make_shared<Resource>(42);
std::cout << "引用计数: " << ptr1.use_count() << std::endl; // 输出: 1
{
auto ptr2 = ptr1; // 拷贝构造,引用计数增加
std::cout << "引用计数: " << ptr1.use_count() << std::endl; // 输出: 2
// 通过指针访问对象
std::cout << "值: " << ptr2->get() << std::endl; // 输出: 42
} // ptr2 离开作用域被销毁,引用计数减1
std::cout << "引用计数: " << ptr1.use_count() << std::endl; // 输出: 1
} // ptr1 离开作用域,引用计数归零,Resource 对象自动析构
std::cout << "程序结束" << std::endl;
return 0;
}
/* 输出结果:
Resource(42) 构造
引用计数: 1
引用计数: 2
值: 42
引用计数: 1
Resource(42) 析构
程序结束
可以看到,其接口和使用方式与标准库实现完全相同。通过实现它,你将从底层深度掌握标准库组件的设计原理。
渐进式实现路径:7天掌握核心技术
整个实现过程被规划为7天的渐进式学习路径,每天聚焦一个核心主题,逐步构建完整的工业级智能指针。
Day 1: 基础引用计数实现
目标:实现最简版本的 shared_ptr,理解 RAII 与引用计数基本原理。
核心:设计类结构、实现基础控制块、完成构造/析构/拷贝语义。
Day 2: 控制块分离架构
目标:重构为类似 Boost 的设计,引入控制块基类,实现类型擦除。
核心:创建 sp_counted_base 抽象基类、shared_count 管理类,理解分层架构优势。
Day 3: 自定义删除器支持
目标:扩展架构以支持任意类型的资源释放器(Deleter)。
核心:实现带删除器的控制块模板,深入理解类型擦除如何管理异构资源。
Day 4: 线程安全改造
目标:引入原子操作,确保多线程环境下的正确性与高性能,这是实现云原生时代高并发服务的基础组件要求。
核心:将引用计数改为 std::atomic<long>,理解内存序(memory_order)的选择与 add_ref_lock 实现。
Day 5: weak_ptr 与循环引用解决
目标:实现完整的 weak_ptr,解决智能指针的经典难题——循环引用。
核心:实现 weak_count 和 weak_ptr,重点攻克 lock() 方法的线程安全实现。
Day 6: make_shared 性能优化
目标:实现 make_shared,通过单次内存分配优化性能。
核心:实现内联存储控制块 (sp_counted_impl_pdi),掌握 aligned_storage 与 placement new 技术。
Day 7: 完善功能与工程化
目标:补全生产级组件所需的所有标准接口,并进行工程化封装。
核心:实现别名构造函数、类型转换函数族 (static_pointer_cast等)、比较运算符,配置 CMake 构建与测试框架。
通过这七天的系统实践,你将不仅获得一个工业级的 shared_ptr 实现,更能透彻理解现代 C++ 在内存管理、并发编程和库设计方面的精髓。
 发表于 2025-12-13 14:59:04
|
查看: 289|
回复: 0
发表于 2025-12-13 14:59:04
|
查看: 289|
回复: 0
