这道题是一位学员在快手面试中遇到的真题:“SFT 训着训着成复读机了怎么办?”说实话,这题考的不仅是背几个解决方案,更是对 SFT 训练过程有没有真正的理解。下面我们就来把这道题拆透。
首先得搞清楚什么叫复读机问题。简单说,就是模型生成的时候开始重复——可能是重复某些短语、句子,甚至陷入无限循环出不来。你跑推理时发现模型在那儿“啊啊啊啊”或者把同一句话翻来覆去讲,这就是典型的复读机。

为什么会出现复读机问题?
那为什么 SFT 训练会出现这个问题?即使仅出现一条句子级的上下文重复,重复的概率在大多数情况下也会陡增。原因在于:LLM 对已有上下文过于“自信”——当先前的 token 共享同一个句子级上下文时,模型学会了一条捷径,直接复制该 token。举个例子,句子“我十分喜欢”中,第二个“喜欢”共享了同一个上下文,模型便直接拷贝,结果就生成“我十分喜欢喜欢”。
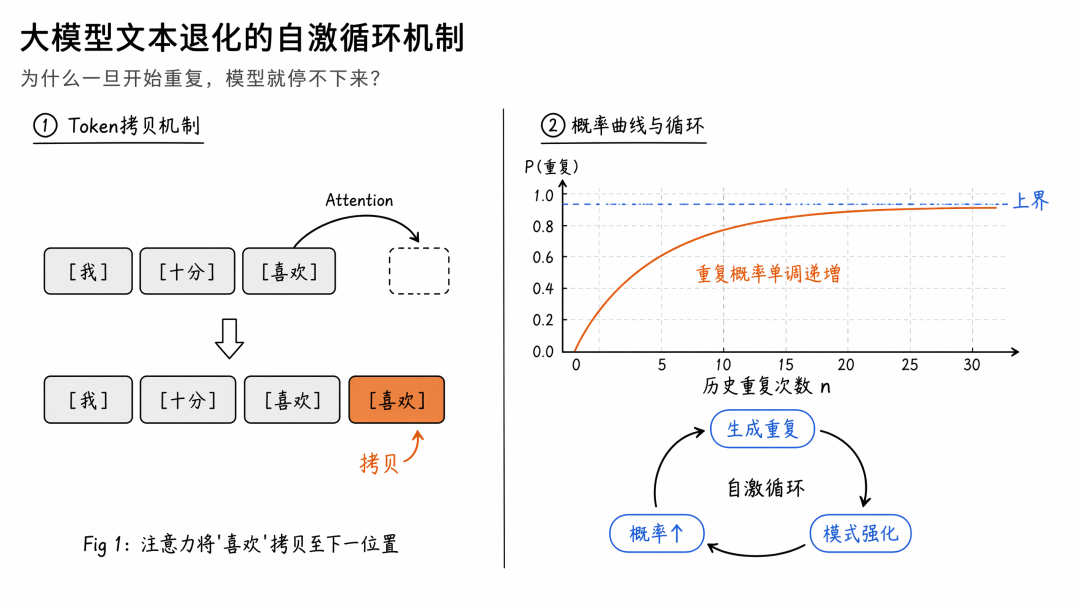
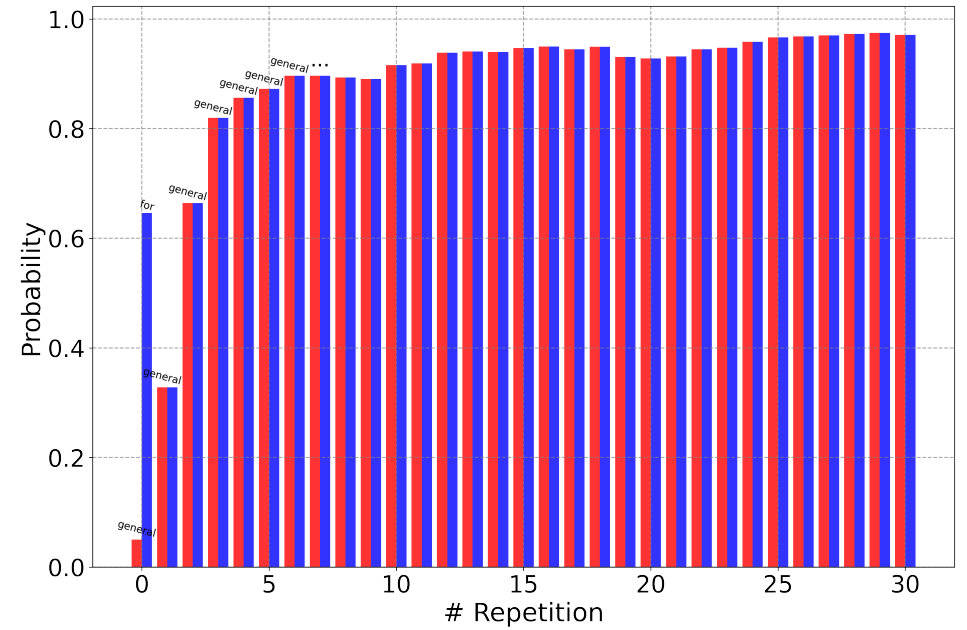
重复的概率几乎随着历史重复次数的增加而单调递增,最终稳定在某个上限附近。一旦生成的句子重复几次,模型就会困在自我强化效应引起的循环里。如下图,随着重复次数增加,“general”一词的概率几乎单调上升并趋于稳定(红柱表示生成相同 token 的概率,蓝柱表示最大概率)。
接下来看几个核心原因:
第一,训练数据本身的问题。 如果 SFT 数据里存在大量重复的 pattern,或者某些表达出现频率特别高,模型就会把这种分布学进去。它会觉得这么说“安全”,因为训练集里就是这么高频出现的,于是倾向于复读这些内容。
第二,解码策略的局限。 如果你用的是 greedy decoding(每一步都选概率最高的 token),模型一旦进入一个高概率的重复循环,就很难跳出来。有一篇 arXiv 的论文专门分析过这个现象——用马尔可夫模型的视角解释:greedy decoding 缺乏逃离重复循环的能力,加上自我强化效应(重复概率随历史重复次数单调递增),最终就卡在某个高概率状态上一直重复。
第三,SFT 本身的过拟合问题。 字节的大模型团队曾在技术报告中明确提到,长时间的 SFT 训练会导致模型快速过拟合,不仅引发复读机问题,还会损害 prompt following 能力和生成多样性。这其实是 SFT 的通病:你在追求某个方向的优化时,模型的泛化能力正在悄悄下降。
怎么解决?
分训练侧和推理侧两个维度来答,面试官会很喜欢。
推理侧:见效快,治标
首先可以调解码策略。例如用 Beam Search 并开启 early_stopping=True,这是那篇论文中验证过的通用方案,对多种重复问题都有效。也可以把 temperature 调高一点增加随机性,或改用 top‑k、top‑p 采样 替代 greedy decoding。另一个实用 trick 是 presence_penalty 或 repetition_penalty,直接惩罚已经出现过的 token,让模型不再“念念不忘”。
训练侧:治本,从根本上解决
一种思路是构造负样本做对比学习。人为生成一些重复的伪数据(比如把短语或句子复制 N 遍),然后在 loss 里加入重复惩罚项。论文里提到,对于开放生成任务,惩罚因子 λ 取 0.5 效果不错;摘要类任务取 0.9 更好。
另一种更成熟的思路是上 RLHF。字节在 Seaweed 模型上就这么做的——SFT 之后再接 RLHF,专门用 DPO 来优化。他们发现单靠 SFT 能改善输出“美观度”,但运动和结构的退化还得靠 RLHF 补齐。DPO 的好处在于能从人类偏好中直接学习,对“什么是好输出、什么是不好输出”有更直接的反馈信号。
此外,工程细节同样不能忽视:SFT 时学习率不要太大,训练时间要控制好,一旦出现过拟合苗头就立即 early stopping;训练前做好数据清洗,去掉重复和冗余内容,保证数据多样性。
总结
面试时你可以这样结构化地回答:复读机问题的根源是训练数据分布偏差、解码策略局限以及 SFT 过拟合。解决方案分两层——推理侧用 Beam Search、调 temperature、加 repetition penalty;训练侧通过数据清洗、重复惩罚 loss、甚至引入 RLHF/DPO 做偏好对齐。 如果时间允许,再补一句“字节的 Seaweed 模型就是用 SFT+RLHF 两阶段来解决这个问题的”,这波回答就稳稳加分了。
如果你对这类面试问题还有疑问,欢迎到云栈社区和同行们深入探讨。 |  发表于 3 小时前
|
查看: 3|
回复: 0
发表于 3 小时前
|
查看: 3|
回复: 0
