AquaCrop是由联合国粮食及农业组织(FAO)开发的一款先进作物-水分生产力模型,它在全球农业水资源管理与优化领域发挥着关键作用。该模型通过精确模拟作物生长过程中的水分需求与消耗,为制定科学的灌溉计划、应对水资源短缺提供了强大的决策支持工具。它不仅内置了全面的数据库,还拥有用户友好的界面,便于研究和实际应用。
AquaCrop模型的核心原理与数据需求
AquaCrop模型的核心优势在于其精细化的水分管理能力,能够模拟水分胁迫对作物生长和产量的影响。它基于一个相对简单的计算框架,将作物生长与水分利用联系起来,其核心方程可概括为:生物量由水分生产力(WP)和累积蒸腾量决定,而最终产量则通过收获指数(HI)从生物量中折算得出。
为了驱动模型运行,需要准备以下几类关键数据:
- 气象数据:包括每日最高/最低气温、降水量、参考作物蒸散量(ET0)和大气CO₂浓度。
- 土壤数据:涉及土壤类型、初始含水量、饱和含水量、田间持水量等水力特性参数。
- 作物数据:需要指定作物类型,模型内置了多种作物的关键参数,如冠层发育、蒸腾、产量形成等。
- 田间管理数据:包括灌溉时间与水量、施肥措施以及耕作方式等。
下面的示意图清晰地展示了AquaCrop模型中农业生态系统的关键组成部分及其相互关系:
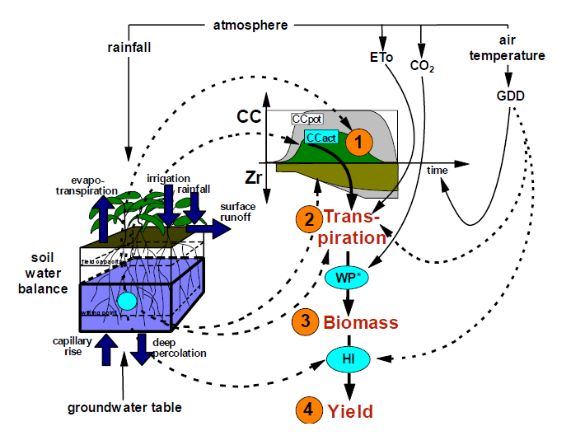
模型数据准备流程详解
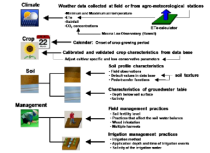
数据准备是模型成功应用的基础。通常,气象数据来源于本地气象站或区域气象数据库。在数据分析领域,使用Python进行数据清洗与预处理是常见且高效的方法。土壤和作物参数则多来自实地测量或查阅文献。
下图展示了从数据收集到模型运行的完整准备流程,以及ET0(参考作物蒸散量)的具体计算路径:
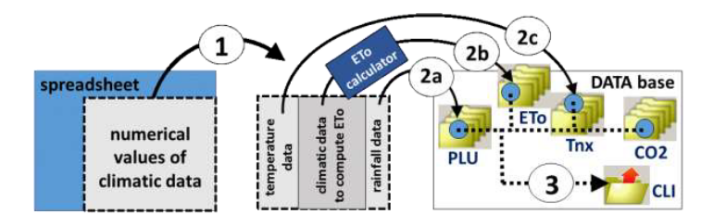
模型运行、输出与结果分析
在准备好所有输入文件后,即可运行AquaCrop模型。模型运行后,会生成详细的模拟结果文件,通常包括每日或生育期阶段的冠层覆盖度、土壤水分状况、蒸腾蒸发量、生物量累积及最终产量等关键变量。
用户可以通过模型自带的图表工具或导出数据到其他软件(如Excel)进行可视化分析,评估不同灌溉策略或气候情景下的作物表现与水分生产率。下图分别展示了模型设置中的种植周期定义和核心的作物生长模拟过程:
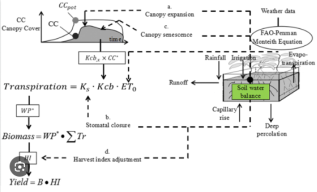
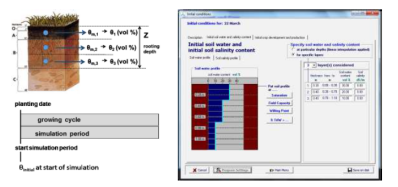
模型参数分析与优化
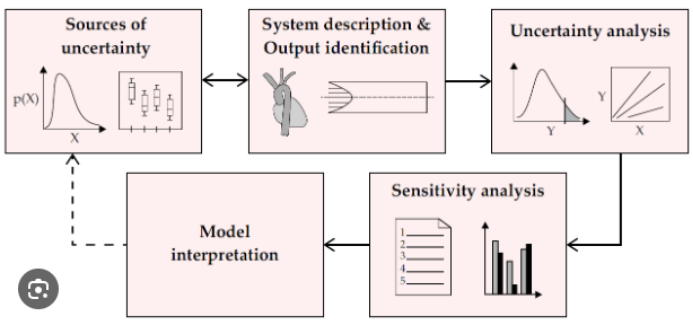
理解模型参数的敏感性和不确定性对于正确解读结果至关重要。
- 敏感性分析:用于识别对输出结果(如产量)影响最大的输入参数(如作物水分生产力WP、最大冠层覆盖度等)。
- 不确定性分析:评估输入参数的不确定性如何传递并导致模拟结果的不确定性。
- 参数调优:基于本地试验数据对模型关键参数进行率定,可以提高模型在特定区域的模拟精度。这个过程是数据科学与模型优化的典型应用。
下图可能展示了参数分析或模拟结果输出的相关界面:
AquaCrop模型Fortran源代码解析
对于希望深入了解模型机理或进行二次开发的研究者,AquaCrop提供了开源的Fortran源代码。
- 现代Fortran基础:AquaCrop代码主要采用Fortran 90/95标准编写,理解了模块、派生数据类型和动态内存分配等特性有助于阅读代码。
- 代码编译:通常可以使用GNU Fortran(gfortran)或Intel Fortran编译器进行编译,生成可执行文件。
- 代码结构:源代码按功能模块化组织,通常包含主程序、气候模块、土壤模块、作物生长模块、灌溉管理模块和输出模块等。
- 入口与核心逻辑:主程序是执行入口,负责读取输入文件、控制模拟时间步长、调用各个子模块进行计算,并最终写入输出结果。核心计算集中在每天的水分平衡、冠层发展、蒸腾胁迫以及生物量累积等过程中。
下图可能反映了模型的代码结构或某部分计算流程:
通过对源码的研读,用户能够更透彻地理解模型背后的科学假设和算法实现,从而增强模型应用的信心和能力。 |  发表于 2025-12-14 00:17:28
|
查看: 280|
回复: 0
发表于 2025-12-14 00:17:28
|
查看: 280|
回复: 0
