一、整体架构与核心流程
Langchain-Chatchat 的知识库管理是其实现检索增强生成(RAG)功能的核心模块。通过其 Web 界面,用户可以直观地进行知识库的创建、文件上传与管理。
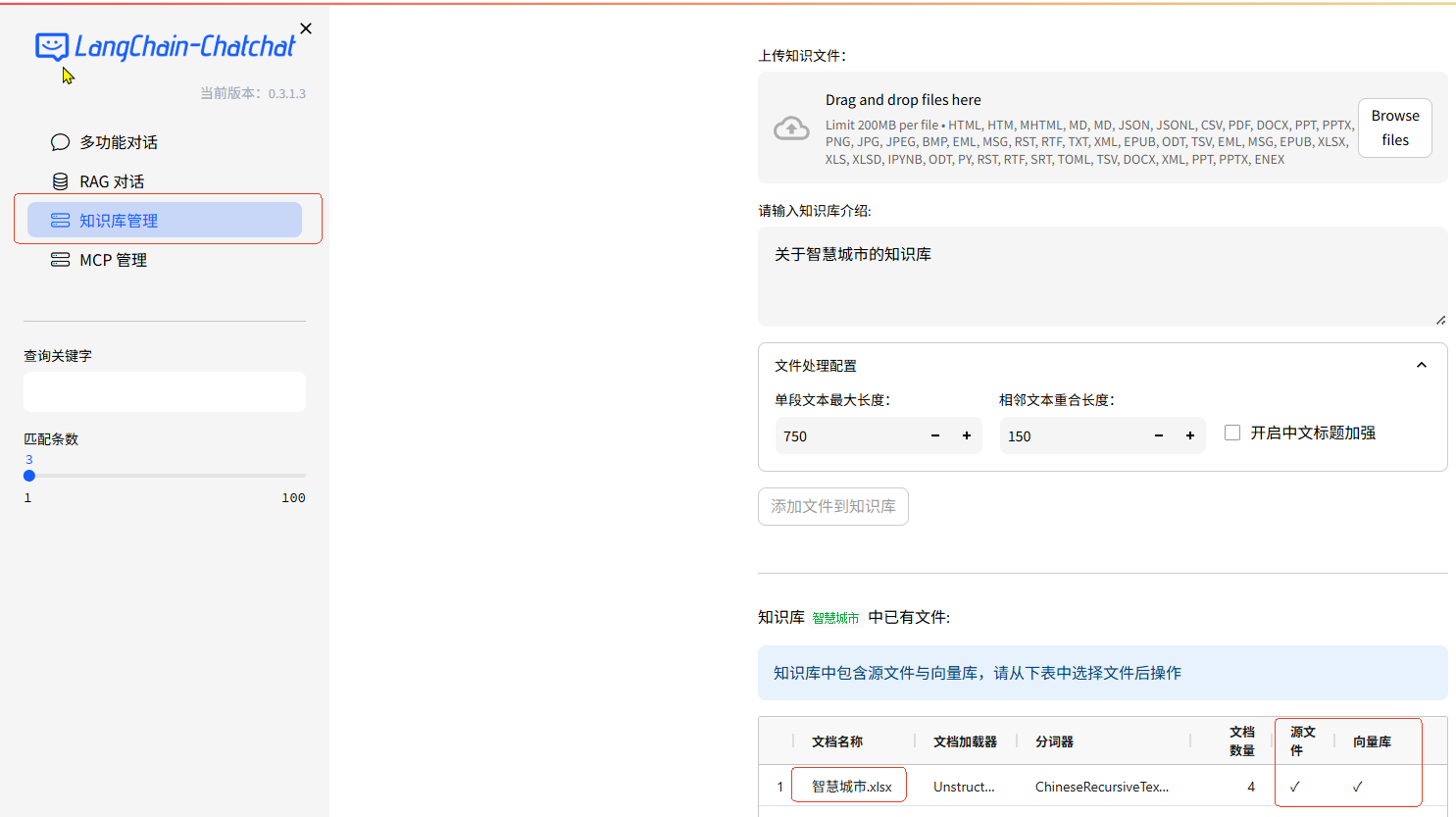
知识库管理界面概览,支持知识库创建、文件上传及配置
知识库创建与文件处理的整体流程由前端界面、API 服务层、知识库服务层以及底层的向量库和文件系统共同协作完成。
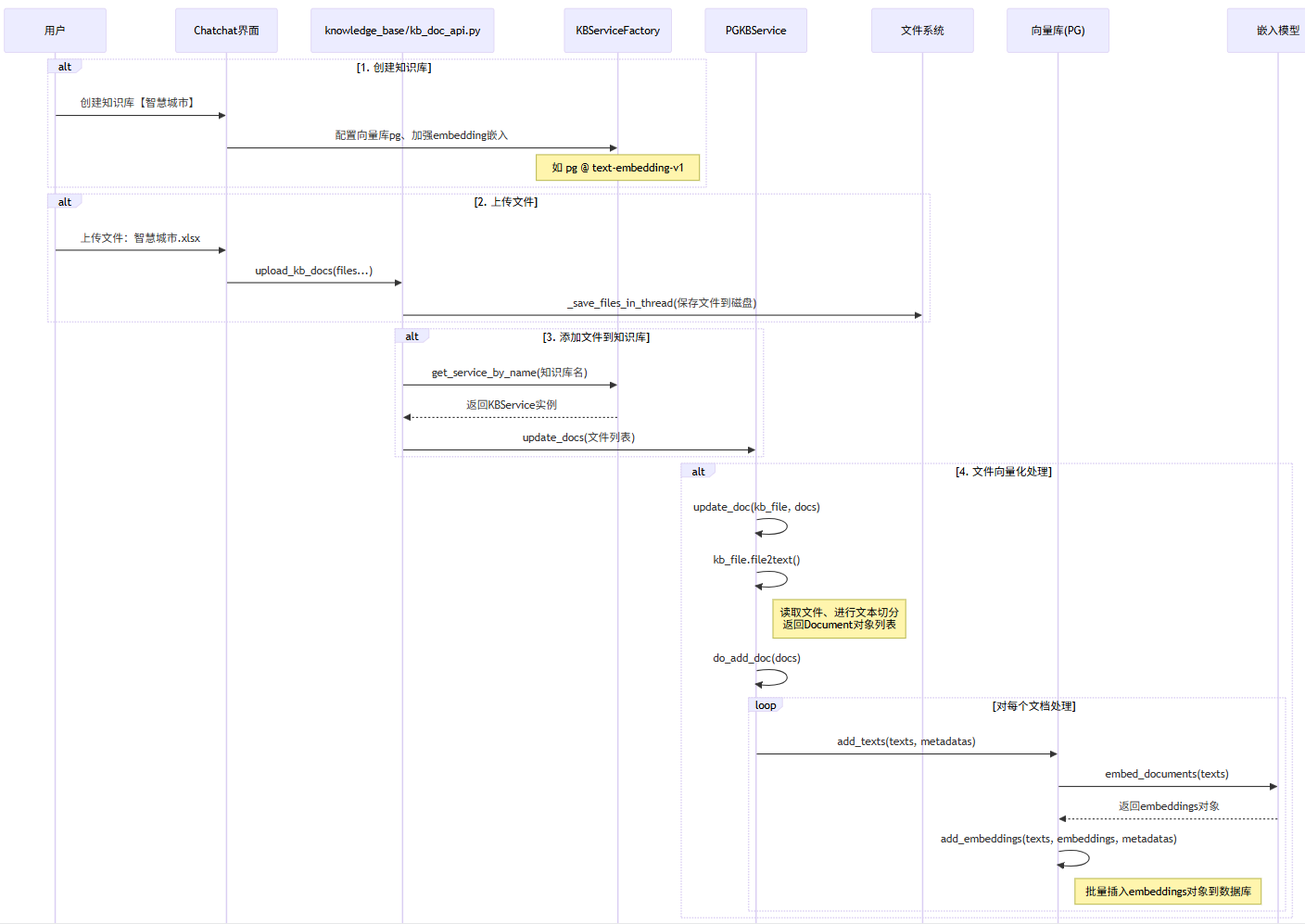
图1:知识库创建与数据流转的核心流程
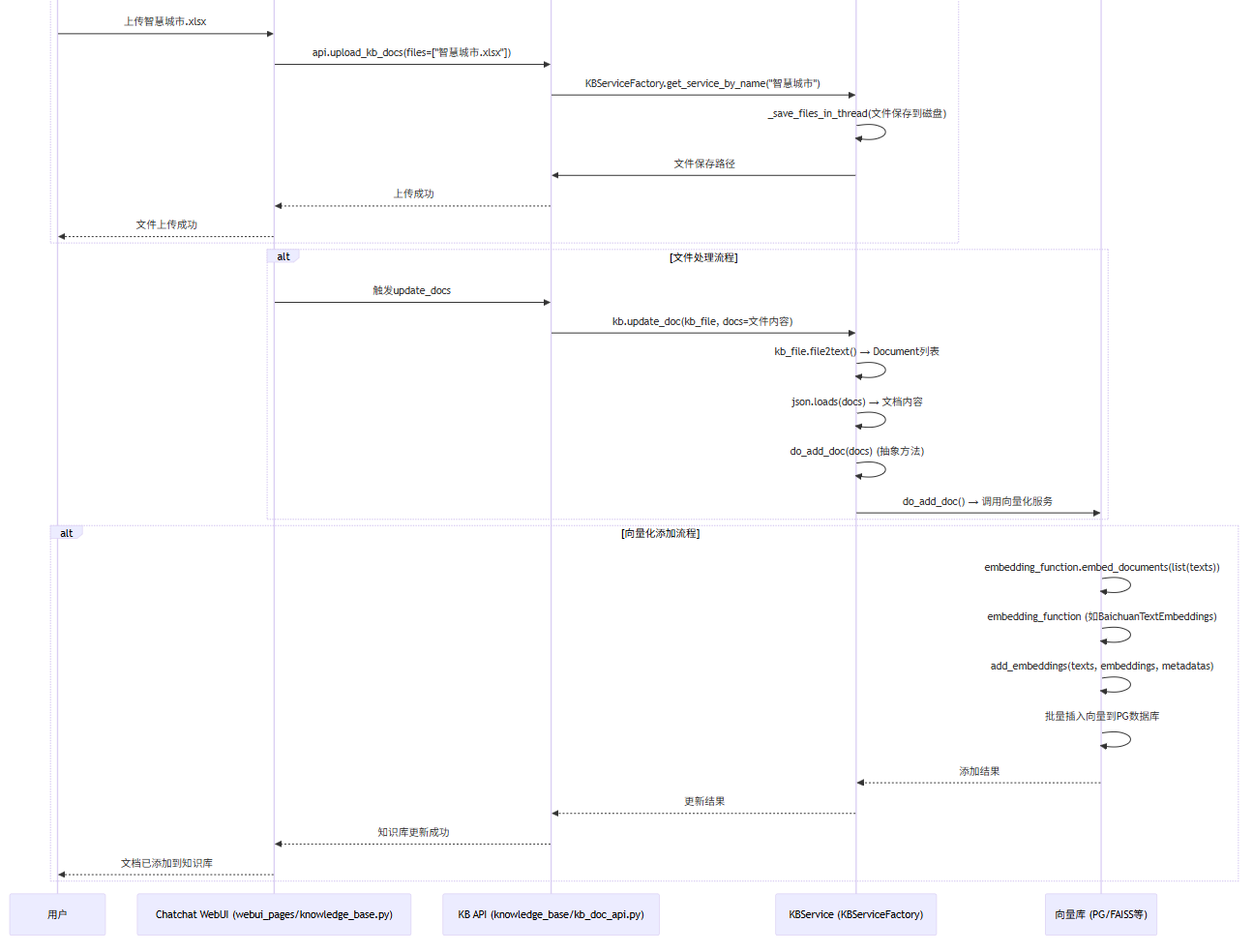
图2:文件上传、向量化到存储的详细调用链
二、流程核心:文本嵌入与向量入库
整个流程中最关键的步骤是将文档文本转化为向量并存入数据库。这主要通过 add_texts 方法实现。
抽象方法与具体实现
在 vectorstores.py 中定义了抽象的 add_texts 方法,它声明了将文本嵌入后添加到向量库的通用接口。
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
这是一个抽象方法,由具体的向量库类(如 FAISS、Milvus、PG 等)实现其逻辑。
PGVector 的具体实现
以 PostgreSQL 向量库(PGVector)为例,其 add_texts 方法在 pgvector.py 中实现:
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
kwargs: vectorstore specific parameters
Returns:
List of ids from adding the texts into the vectorstore.
"""
embeddings = self.embedding_function.embed_documents(list(texts))
return self.add_embeddings(
texts=texts, embeddings=embeddings, metadatas=metadatas, ids=ids, **kwargs
)
该方法主要完成两个核心操作:
- 文本向量化:调用
embedding_function.embed_documents(list(texts)),利用大模型的嵌入模型(如 BaichuanTextEmbeddings、ZhipuAIEmbeddings)将文本列表转化为向量(embeddings)列表。
- 调用入库:将得到的向量、文本及元数据传递给
add_embeddings 方法执行实际的数据库插入操作。
向量数据批量入库
add_embeddings 方法负责将向量数据批量插入到 PostgreSQL 数据库中,这是连接 Python 应用与 数据库/中间件 的关键环节。
def add_embeddings(
self,
texts: Iterable[str],
embeddings: List[List[float]],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Add embeddings to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
embeddings: List of list of embedding vectors.
metadatas: List of metadatas associated with the texts.
kwargs: vectorstore specific parameters
"""
if ids is None:
ids = [str(uuid.uuid4()) for _ in texts]
if not metadatas:
metadatas = [{} for _ in texts]
with Session(self._bind) as session:
collection = self.get_collection(session) # 获取当前操作的集合对象
if not collection:
raise ValueError("Collection not found")
documents = []
for text, metadata, embedding, id in zip(texts, metadatas, embeddings, ids):
# 为每个文档创建ORM模型实例
embedding_store = self.EmbeddingStore(
embedding=embedding,
document=text,
cmetadata=metadata,
custom_id=id,
collection_id=collection.uuid,
)
documents.append(embedding_store)
# 批量插入到数据库
session.bulk_save_objects(documents)
session.commit()
return ids
此方法的核心步骤包括:生成唯一ID、处理元数据、创建ORM模型实例,并最终通过SQLAlchemy会话批量保存到PostgreSQL中,确保数据持久化。
三、核心服务类解析
1. 知识库服务基类:KBService
KBService 类定义在 knowledge_base/kb_service/base.py,它是一个抽象基类(ABC),为各种类型的知识库服务(如Faiss、Milvus、PG等)提供了统一的接口规范。
class KBService(ABC):
# 初始化KBService类的实例
def __init__(
self,
knowledge_base_name: str,
kb_info: str = None,
embed_model: str = get_default_embedding(),
):
self.kb_name = knowledge_base_name
self.kb_info = kb_info
self.embed_model = embed_model # 嵌入模型
self.kb_path = get_kb_path(self.kb_name)
self.doc_path = get_doc_path(self.kb_name)
self.do_init()
该类管理知识库的全生命周期,包括:
create_kb():创建知识库,涉及目录创建、数据库记录添加及调用子类扩展点。add_doc(kb_file, docs):向知识库添加文档的核心方法。它首先将文件内容转换为文档列表,删除旧文档,然后调用子类实现的 do_add_doc 方法进行向量化与存储,最后更新文件数据库。save_vector_store():负责将向量库的数据持久化。这是一个关键方法,在文档上传、删除、更新或向量库重建等操作后被调用,以确保向量库状态被正确保存。
2. 服务工厂:KBServiceFactory
KBServiceFactory 类采用工厂模式,根据参数动态创建具体的知识库服务实例,实现了服务的解耦与灵活配置。
get_service(kb_name, vector_store_type, embed_model):根据向量库类型动态导入并返回对应的服务实例(如 PGKBService, FaissKBService)。get_service_by_name(kb_name):通过知识库名称从数据库加载配置,然后调用 get_service 返回实例。get_default():返回一个默认类型的知识库服务实例。
3. PostgreSQL 服务实现:PGKBService
PGKBService 是 KBService 的子类,位于 knowledge_base/kb_service/pg_kb_service.py,提供了基于 PostgreSQL 和 PGVector 的具体实现。
class PGKBService(KBService):
...
其主要属性包括:
engine:SQLAlchemy 连接引擎,用于数据库交互。pg_vector:PGVector 实例,负责向量的存储与检索。
关键方法:_load_pg_vector(self)
此方法是初始化向量搜索能力的关键,它配置并创建了 PGVector 实例。
def _load_pg_vector(self):
# 创建嵌入函数适配器,基于 embed_model 属性
embed_func = EmbeddingsFunAdapter(self.embed_model)
# 初始化 PGVector 实例
self.pg_vector = PGVector(
embedding_function=embed_func,
collection_name=self.kb_name,
distance_strategy=DistanceStrategy.EUCLIDEAN, # 使用欧氏距离
connection=PGKBService.engine,
connection_string=kbs_config.get("pg").get("connection_uri"),
)
流程说明:
- 创建
EmbeddingsFunAdapter 适配器,它封装了文本嵌入模型,支持同步/异步调用,是实现 人工智能 语义理解的基础。
- 使用知识库名称作为 PostgreSQL 中的集合(collection)名。
- 指定距离策略为欧氏距离(
DistanceStrategy.EUCLIDEAN),用于计算向量间的相似度。
- 传入数据库连接引擎和连接字符串,完成 PGVector 的初始化。
通过 _load_pg_vector 方法,PGKBService 具备了将文本查询转化为向量,并在 PostgreSQL 中执行高效相似度搜索的能力,从而支撑起整个 RAG 对话系统的检索环节。
 发表于 2025-12-14 02:26:39
|
查看: 252|
回复: 0
发表于 2025-12-14 02:26:39
|
查看: 252|
回复: 0
