awk、grep、sed是Linux系统中处理文本的三大利器,常被合称为“文本三剑客”,也是必须掌握的Linux命令。虽然三者都用于文本处理,但侧重点不同:grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,而awk则更适合格式化文本,能进行更复杂的格式处理和编程逻辑。
1、grep:强大的文本搜索工具
1.1 什么是grep和egrep
grep(Global Regular Expression Print)是一种强大的文本搜索工具,它能够使用正则表达式搜索文本,并将匹配的行打印出来(默认会高亮显示匹配部分)。grep的工作方式是在一个或多个文件中搜索给定的字符串模板。如果模板包含空格,则必须被引用。搜索的结果会输出到标准输出,不会影响原文件内容。
grep命令的退出状态码非常有用:如果模板搜索成功,返回0;搜索不成功,返回1;如果搜索的文件不存在,则返回2。这使得grep可以方便地用于Shell脚本,实现自动化的文本处理逻辑。
egrep = grep -E:它使用扩展的正则表达式引擎,除了\<、\>、\b这几个词边界锚定字符,其他正则表达式元字符都可以省略转义反斜杠\。
1.2 使用grep
1.2.1 命令格式
grep [option] pattern file
1.2.2 命令参数(常用参数已加粗)
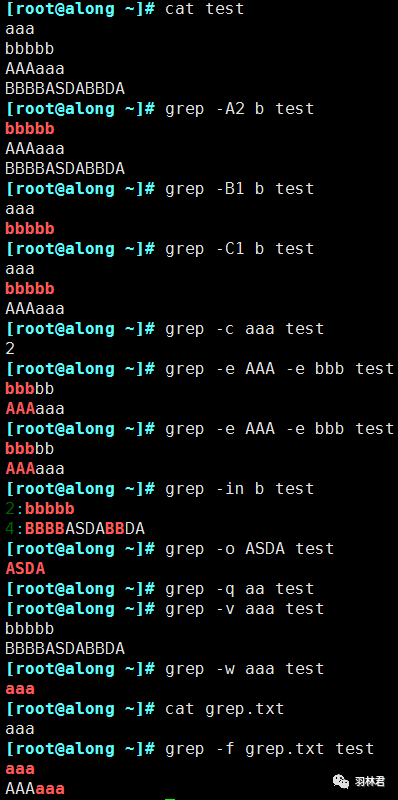
- -A<显示行数>:除了显示匹配行,还显示该行之后的内容。
- -B<显示行数>:除了显示匹配行,还显示该行之前的内容。
- -C<显示行数>:除了显示匹配行,还显示该行前后的内容。
- -c:统计匹配的行数。
- -e:实现多个选项间的逻辑
OR关系。
- -E:使用扩展的正则表达式。
- -i:忽略字符大小写。
- -n:显示匹配行的行号。
- -o:仅显示匹配到的字符串本身。
- -v:显示不被pattern匹配到的行,相当于反向匹配。
- -w:匹配整个单词。
1.3 grep实战演示
2、正则表达式
2.1 认识正则
正则表达式应用广泛,在绝大多数编程语言中都可以使用。在Linux的文本处理中,它结合grep、sed、awk等工具能发挥极大作用。常用的正则引擎有:
- POSIX 基本正则表达式(BRE)引擎
- POSIX 扩展正则表达式(ERE)引擎
2.2 基本正则表达式
2.2.1 匹配字符
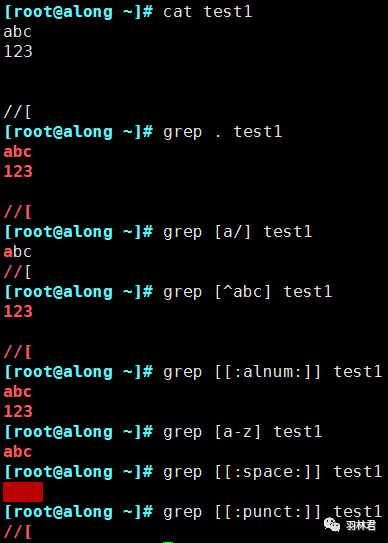
.:匹配任意单个字符(不能匹配空行)。[]:匹配指定范围内的任意单个字符。[^]:取反,匹配不在指定范围内的任意单个字符。[:alnum:]:字母和数字,等价于[0-9a-zA-Z]。[:digit:]:十进制数字,等价于[0-9]。
2.2.2 配置次数
- *``**:匹配前面的字符任意次(包括0次),贪婪模式。
- *`.`**:匹配任意长度的任意字符(不包括0次)。
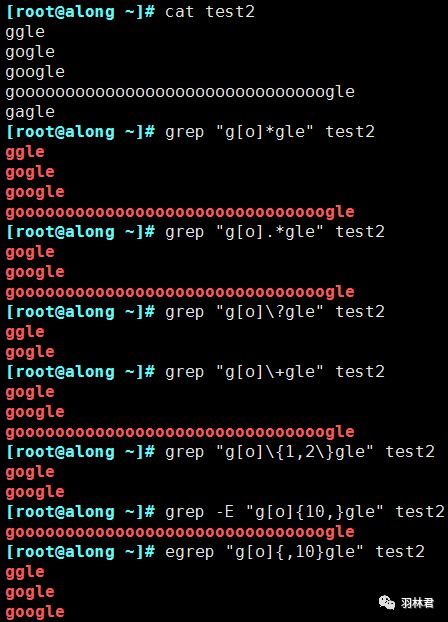
\?:匹配前面的字符0次或1次。\+:匹配前面的字符至少1次。\{n\}:匹配前面的字符恰好n次。\{m,n\}:匹配前面的字符至少m次,至多n次。
2.2.3 位置锚定
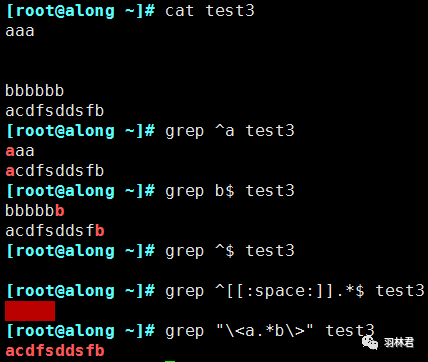
^:行首锚定。$:行尾锚定。^PATTERN$:用于匹配整行。^$:匹配空行。\< 或 \b:词首锚定。\> 或 \b:词尾锚定。
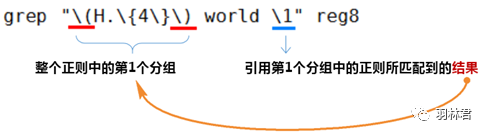
2.2.4 分组和后向引用
- 分组
\(\):将多个字符捆绑为一个整体处理。
- 后向引用
\1, \2...:引用前面分组括号中匹配到的内容。
流程分析:
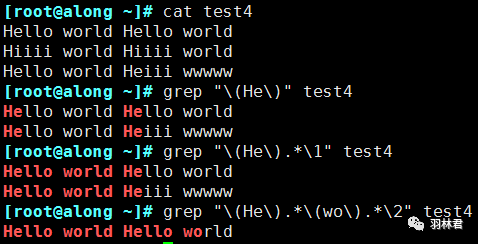
演示:
2.3 扩展正则表达式
扩展正则表达式简化了部分元字符的转义:
- 次数匹配:
*, ?, +, {m}, {m,n}(无需反斜杠)。
- 分组:
()(无需反斜杠)。
- 注意:词边界锚定
\<, \b, \>在扩展正则中仍需转义。
3、sed:流编辑器
3.1 认识sed
sed是一种流编辑器,它逐行处理文本。处理时,将当前行存储在“模式空间”中,用sed命令处理完毕后输出到屏幕,然后读取下一行。除非使用重定向或-i选项,否则原文件内容不会改变。它主要用来自动编辑一个或多个文件,简化重复性操作。
3.2 使用sed
3.2.1 命令格式
sed [options] '[地址定界] command' file(s)
3.2.2 常用选项options
- -n:禁止自动打印模式空间,只打印被处理的行。
- -e:允许多点编辑。
- -f file:从指定文件中读取
sed脚本。
- -r:支持扩展正则表达式。
- -i[.bak]:直接修改文件(可选先备份)。
3.2.3 地址定界
- 空地址:对全文处理。
- 单地址:
n(第n行)或/pattern/(匹配该模式的行)。
- 地址范围:
n,m(第n到m行)、n,+m(第n行及其后m行)、/pat1/,/pat2/。
3.2.4 编辑命令command
- d:删除模式空间内容,开始下一循环。
- p:打印当前模式空间内容。
- a\text:在行后追加文本。
- i\text:在行前插入文本。
- c\text:替换整行为新文本。
- s/pattern/replacement/[flags]:查找替换,支持其他分隔符(如
s###),g表示行内全局替换。
3.3 sed用法演示
3.3.1 常用选项演示
[root@along ~]# cat demo
aaa
bbbb
AABBCCDD
[root@along ~]# sed -n "/aaa/p" demo # -n只显示匹配行
aaa
[root@along ~]# sed -e "s/a/A/" -e "s/b/B/" demo # -e多点编辑
Aaa
Bbbb
AABBCCDD
[root@along ~]# sed -i.bak "s/a/A/g" demo # -i直接修改并备份
3.3.2 地址界定演示
[root@along ~]# sed -n "1,2p" demo # 打印1-2行
aaa
bbbb
[root@along ~]# sed -n "/aaa/,/DD/p" demo # 打印从匹配aaa到匹配DD的行
aaa
bbbb
AABBCCDD
3.3.3 编辑命令演示
[root@along ~]# sed "2d" demo # 删除第2行
aaa
AABBCCDD
[root@along ~]# sed "2a123" demo # 在第2行后追加
aaa
bbbb
123
AABBCCDD
[root@along ~]# sed 's/[a-z]/\u&/g' demo # 将所有小写字母替换为大写
AAA
BBBB
AABBCCDD
3.4 sed高级编辑命令
- h/H:将模式空间内容覆盖/追加到保持空间。
- g/G:将保持空间内容覆盖/追加到模式空间。
- x:交换模式空间和保持空间的内容。
- n/N:读取下一行覆盖/追加到模式空间。
演示:倒序输出文本
[root@along ~]# seq 3 | sed '1!G;h;$!d'
3
2
1
示意图:
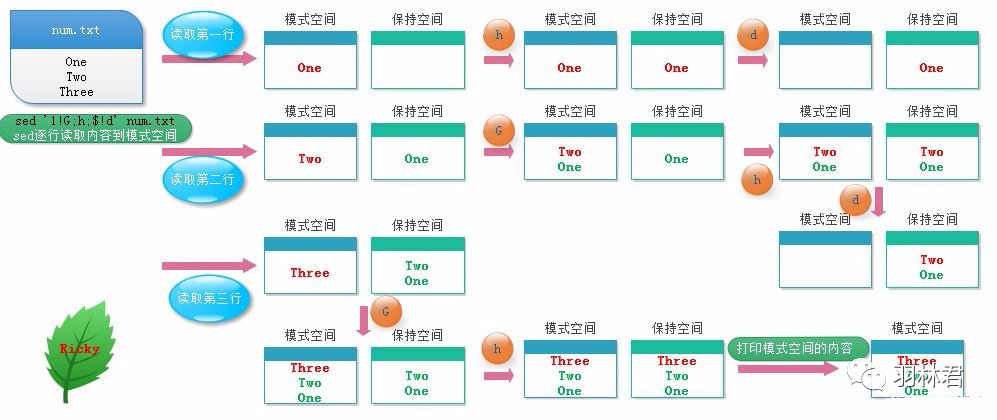
保持空间是模式空间的一个临时数据缓冲区,协助完成更复杂的数据处理。
4、awk:模式扫描与处理语言
4.1 认识awk
awk不仅仅是一个命令,更是一种功能强大的编程语言,用于在Linux/Unix下对文本和数据进行处理。它支持用户自定义函数、动态正则表达式、数组等高级特性。awk将输入行视为记录,通过指定分隔符将其划分为字段,然后以字段为单位进行处理,灵活性极高。
4.2 使用awk
4.2.1 语法
awk [options] 'program' file…
awk [options] 'BEGIN{...} pattern{...} END{...}' file…
4.2.2 常用命令选项
- -F fs:指定输入字段分隔符(如
-F:)。
- -v var=value:定义变量并将外部值传递给awk。
4.3 awk变量
4.3.1 内置变量
- FS:输入字段分隔符,默认为空白。
- OFS:输出字段分隔符,默认为空白。
- NF:当前记录的字段数量。
$NF表示最后一个字段。
- NR:当前处理的总行号(跨文件累加)。
- FNR:当前文件的行号(各文件单独计数)。
演示:
[root@along ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:you
[root@along ~]# awk -F: '{print $1, NF}' awkdemo
hello 2
linux 4
along 3
4.3.2 自定义变量
- 通过
-v选项定义:awk -v name="along" '{print name}'
- 在
program中直接定义。
4.4 printf命令
比print功能更强,需指定格式且不会自动换行。
# 格式化输出用户名和UID,左对齐
[root@along ~]# awk -F: '{printf "%-15s --- %5d\n", $1, $3}' /etc/passwd | head -3
root --- 0
bin --- 1
daemon --- 2
4.5 操作符
- 算术操作符:
+, -, *, /, %, ^(幂)。
- 比较操作符:
==, !=, >, <, >=, <=。
- 模式匹配符:
~(匹配),!~(不匹配)。
- 逻辑操作符:
&&, ||, !。
- 三目表达式:
condition ? if-true : if-false
4.6 awk PATTERN 匹配部分
- 空模式:匹配每一行。
/regular expression/:处理匹配正则的行。- 关系表达式:结果为非0或非空字符串时处理。
BEGIN/END:在处理所有行之前/之后执行一次。
4.7 awk高阶用法
4.7.1 控制语句
awk支持完整的编程结构,如if-else条件判断、while、do-while、for循环,以及break、continue、next等流程控制语句。掌握这些是进行高效Shell脚本编程和运维/DevOps自动化任务的基础。
示例:根据UID分类用户
awk -F: '{
if ($3>=1000) {type="Common User"}
else if ($3==0) {type="Super User"}
else {type="System User"};
print type ": " $1
}' /etc/passwd
4.7.2 数组
awk支持关联数组,下标可以是字符串,常用于统计。
# 统计TCP连接状态
netstat -tan | awk '/^tcp/ {state[$NF]++} END {for(s in state) print s, state[s]}'
4.7.3 内置函数
包括数学函数(rand())、字符串函数(length(), sub(), gsub(), split())等。
4.7.4 自定义函数与调用Shell命令
awk允许你定义自己的函数,并能通过system()函数调用外部Shell命令。
5、grep、sed、awk对比与应用场景
grep:核心功能是查找和过滤。它简单快速,适合在文件中快速定位包含特定模式的行。它是文本处理流水线中的“筛选器”。sed:核心功能是编辑和转换。它适合对匹配到的文本进行插入、删除、替换等操作,尤其擅长基于行的、非交互式的批量编辑。awk:核心功能是报告生成和复杂处理。它将每行视为由分隔符分隔的字段,擅长对表格化数据进行分析、计算、格式化输出,内建编程语言特性使其能处理复杂的逻辑。
如何选择?
- 仅需查找特定内容? -> 用
grep。
- 需要对找到的内容进行编辑(如替换)? -> 用
sed。
- 需要基于列(字段)处理数据、进行计算或生成格式化报告? -> 用
awk。
实际上,在复杂的Linux系统管理和数据处理流水线中,三者经常协同工作,通过管道(|)将grep的过滤结果交给sed编辑,再交给awk进行深度分析和格式化,从而高效完成各类文本处理任务。理解它们各自的特性和优势,是提升Linux命令行效率和脚本能力的关键。
 发表于 2025-12-14 18:02:05
|
查看: 229|
回复: 0
发表于 2025-12-14 18:02:05
|
查看: 229|
回复: 0
