一、微服务监控的核心挑战
与传统的单体应用相比,微服务架构的监控面临着根本性的复杂度跃升。
监控复杂度对比分析:
| 维度 |
单体应用 |
微服务架构 |
| 实例数量 |
几个实例 |
数百个实例 |
| 网络调用 |
本地调用 |
分布式调用链 |
| 数据量 |
GB级别 |
TB级别日志/指标 |
| 问题定位 |
单点排查 |
全链路追踪 |
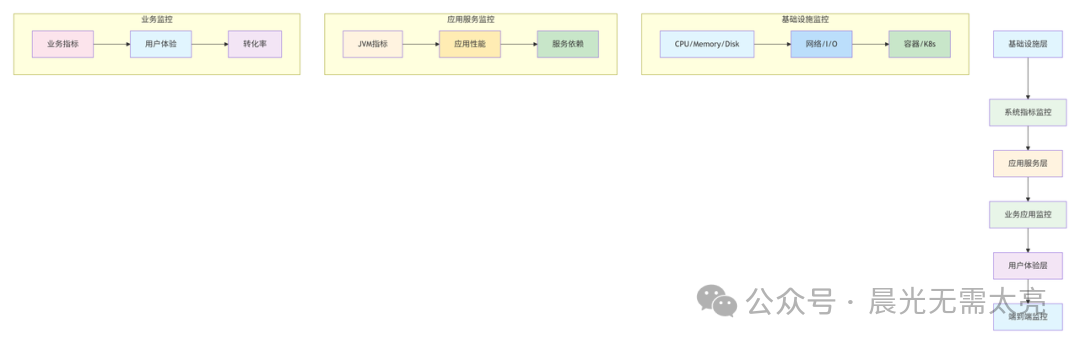
二、微服务监控体系全景图
1. 监控四大支柱
一个健全的微服务监控体系建立在四大支柱之上:
| 支柱 |
核心目标 |
关键技术 |
业务价值 |
| 指标 (Metrics) |
系统性能量化 |
Prometheus, Grafana |
性能分析、容量规划 |
| 日志 (Logging) |
事件记录追踪 |
ELK Stack, Loki |
问题排查、审计分析 |
| 追踪 (Tracing) |
请求链路还原 |
SkyWalking, Jaeger |
性能瓶颈定位 |
| 健康检查 (Health) |
服务状态监控 |
Spring Boot Actuator |
服务可用性保障 |
2. 监控层次架构
三、核心技术栈深度解析
1. 指标监控:Prometheus + Grafana
Prometheus 核心数据模型:
Prometheus 定义了四种核心指标类型,是构建监控体系的基础。
// 指标类型示例
public class MetricTypes {
// 1. 计数器(Counter) - 只增不减
// 示例:http_requests_total{method="POST", handler="/api/users"} 1024
// 2. 仪表盘(Gauge) - 可增可减
// 示例:memory_usage_bytes{service="user-service"} 536870912
// 3. 直方图(Histogram) - 统计分布(服务端计算)
// 示例:http_request_duration_seconds_bucket{le="0.1"} 125
// http_request_duration_seconds_bucket{le="0.5"} 345
// 4. 摘要(Summary) - 客户端计算分位数
// 示例:http_request_duration_seconds{quantile="0.5"} 0.234
}
Spring Boot 集成配置:
在基于 Spring Boot 的项目中,通过简单的配置即可暴露指标给 Prometheus。
# application.yml
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
metrics:
export:
prometheus:
enabled: true
tags:
application: ${spring.application.name}
environment: ${spring.profiles.active}
distribution:
percentiles-histogram:
http.server.requests: true
endpoint:
metrics:
enabled: true
prometheus:
enabled: true
# 自定义指标配置
micrometer:
metrics:
enable:
jvm: true
logback: true
system: true
自定义业务指标实践:
除了系统指标,定义业务指标对于理解应用状态至关重要。
@Service
public class OrderMetricsService {
// 1. 定义订单相关指标
private final Counter orderCreatedCounter;
private final Counter orderFailedCounter;
private final Timer orderProcessTimer;
private final Gauge orderQueueSizeGauge;
@Autowired
private MeterRegistry meterRegistry;
public OrderMetricsService(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
// 初始化计数器、计时器等指标
this.orderCreatedCounter = Counter.builder("order.created.total")
.description("Total number of orders created")
.tag("application", "order-service")
.register(meterRegistry);
this.orderFailedCounter = Counter.builder("order.failed.total")
.description("Total number of failed orders")
.tag("application", "order-service")
.register(meterRegistry);
this.orderProcessTimer = Timer.builder("order.process.duration")
.description("Order processing time")
.tag("application", "order-service")
.register(meterRegistry);
// Gauge需要绑定到动态获取值的方法上
this.orderQueueSizeGauge = Gauge.builder("order.queue.size")
.description("Current order queue size")
.tag("application", "order-service")
.register(meterRegistry, this, OrderMetricsService::getQueueSize);
}
@EventListener
public void handleOrderCreated(OrderCreatedEvent event) {
orderCreatedCounter.increment();
// 记录处理耗时
orderProcessTimer.record(() -> {
processOrder(event.getOrder());
});
}
@EventListener
public void handleOrderFailed(OrderFailedEvent event) {
// 可增加更细粒度的标签,如失败原因
orderFailedCounter.increment(
Counter.builder("order.failed.total")
.tag("reason", event.getReason())
.register(meterRegistry)
);
}
private int getQueueSize() {
// 动态获取队列大小
return orderQueue.size();
}
// 通过注解进行方法级别监控
@Timed(value = "order.service.process", description = "Order processing time")
@Counted(value = "order.service.invocation", description = "Order service invocation count")
public Order processOrder(Order order) {
// 业务处理逻辑
return orderService.process(order);
}
}
Grafana 监控面板配置示例:
通过 Grafana 可以将 Prometheus 采集的指标进行可视化。
{
"dashboard": {
"title": "订单服务监控",
"panels": [
{
"title": "QPS",
"type": "stat",
"targets": [
{
"expr": "rate(http_server_requests_seconds_count{application=\"order-service\"}[5m])",
"legendFormat": "{{method}} {{status}}"
}
]
},
{
"title": "响应时间P95",
"type": "graph",
"targets": [
{
"expr": "histogram_quantile(0.95, rate(http_server_requests_seconds_bucket{application=\"order-service\"}[5m]))",
"legendFormat": "P95响应时间"
}
]
},
{
"title": "JVM内存使用",
"type": "gauge",
"targets": [
{
"expr": "jvm_memory_used_bytes{area=\"heap\", application=\"order-service\"}",
"legendFormat": "堆内存使用"
}
]
}
]
}
}
2. 日志监控:ELK Stack
结构化日志配置 (Logback):
结构化日志是高效日志分析的前提,推荐使用 JSON 格式输出。
<!-- logback-spring.xml -->
<configuration>
<springProperty scope="context" name="APP_NAME" source="spring.application.name"/>
<springProperty scope="context" name="LOG_LEVEL" source="logging.level.root" defaultValue="INFO"/>
<appender name="JSON" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp/>
<logLevel/>
<loggerName/>
<message/>
<mdc/>
<arguments/>
<stackTrace/>
<pattern>
<pattern>
{
"app": "${APP_NAME}",
"traceId": "%mdc{traceId}",
"spanId": "%mdc{spanId}",
"thread": "%thread",
"class": "%logger{40}"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/${APP_NAME}.log</file>
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/${APP_NAME}.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
<root level="${LOG_LEVEL}">
<appender-ref ref="JSON"/>
<appender-ref ref="FILE"/>
</root>
</configuration>
业务日志记录最佳实践:
良好的日志记录习惯能极大提升问题排查效率。
@Slf4j
@RestController
@RequestMapping("/api/orders")
public class OrderController {
@PostMapping
public ResponseEntity<Order> createOrder(@RequestBody @Valid CreateOrderRequest request) {
// 1. 使用MDC记录上下文信息,便于日志关联
MDC.put("userId", request.getUserId().toString());
MDC.put("orderSource", request.getSource());
log.info("开始创建订单",
kv("productId", request.getProductId()),
kv("quantity", request.getQuantity()),
kv("amount", request.getAmount()));
try {
// 2. 业务处理
Order order = orderService.createOrder(request);
log.info("订单创建成功",
kv("orderId", order.getId()),
kv("orderNo", order.getOrderNo()));
return ResponseEntity.ok(order);
} catch (BusinessException e) {
// 3. 业务异常应记录明确的信息,而非简单打印堆栈
log.error("订单创建失败-业务异常",
kv("errorCode", e.getErrorCode()),
kv("errorMsg", e.getMessage()),
e);
return ResponseEntity.badRequest().build();
} catch (Exception e) {
log.error("订单创建失败-系统异常", e);
throw e;
} finally {
// 4. 请求结束时清理MDC,避免内存泄漏和信息错乱
MDC.clear();
}
}
// AOP拦截:慢查询日志监控
@Around("execution(* com.example..repository.*Repository.*(..))")
public Object logDatabaseQuery(ProceedingJoinPoint joinPoint) throws Throwable {
long startTime = System.currentTimeMillis();
try {
return joinPoint.proceed();
} finally {
long duration = System.currentTimeMillis() - startTime;
if (duration > 1000) { // 超过1秒记录为慢查询
log.warn("慢数据库查询检测",
kv("method", joinPoint.getSignature().getName()),
kv("duration", duration),
kv("threshold", 1000));
}
}
}
}
3. 链路追踪:SkyWalking集成
SkyWalking Agent 基础配置:
通过 Agent 以无侵入的方式集成链路追踪功能。
# skywalking-agent.config
agent.service_name=${SW_AGENT_NAME:order-service}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:localhost:11800}
# 采样配置
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}
# 插件配置
plugin.springmvc.collect_http_params=${SW_PLUGIN_SPRINGMVC_COLLECT_HTTP_PARAMS:true}
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_SERVER_HOST:localhost}
plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_SERVER_PORT:11800}
业务代码中的追踪实践:
可以通过注解或手动编码的方式增强追踪信息。
@Service
public class OrderProcessService {
// 使用注解自动追踪方法调用并添加自定义标签
@Trace
@Tags({
@Tag(key = "order.amount", value = "arg[0].amount"),
@Tag(key = "order.channel", value = "arg[0].channel")
})
public OrderResult processOrder(OrderRequest request) {
// 此方法调用会被自动记录到追踪链中
return doProcess(request);
}
// 手动创建追踪跨度 (Span),用于复杂业务流程
public void completeOrderWorkflow(OrderContext context) {
try {
Span span = Tracing.getTracer().spanBuilder("completeOrderWorkflow")
.setAttribute("orderId", context.getOrderId())
.setAttribute("workflowType", context.getWorkflowType())
.startSpan();
try (Scope scope = span.makeCurrent()) {
// 业务流程步骤
step1_ValidateOrder(context);
span.addEvent("validation.completed");
step2_ProcessPayment(context);
span.addEvent("payment.processed");
step3_UpdateInventory(context);
span.addEvent("inventory.updated");
span.setStatus(StatusCode.OK);
} catch (Exception e) {
span.setStatus(StatusCode.ERROR);
span.recordException(e);
throw e;
} finally {
span.end();
}
} catch (Exception e) {
log.error("订单工作流执行失败", e);
throw e;
}
}
}
4. 健康检查:Spring Boot Actuator
基础健康检查配置:
Actuator 提供了开箱即用的健康检查端点。
management:
endpoint:
health:
enabled: true
show-details: always
show-components: always
health:
db:
enabled: true
redis:
enabled: true
diskspace:
enabled: true
mail:
enabled: true
自定义深度健康检查指示器:
可以扩展健康检查,涵盖数据库、缓存、外部服务依赖等。
@Component
public class CustomHealthIndicator implements HealthIndicator {
@Autowired
private OrderRepository orderRepository;
@Autowired
private RedisTemplate redisTemplate;
@Value("${health.check.threshold.orderCount:10000}")
private long orderCountThreshold;
@Override
public Health health() {
Health.Builder builder = new Health.Builder();
try {
// 1. 数据库健康与容量检查
long orderCount = orderRepository.count();
if (orderCount > orderCountThreshold) {
builder.withDetail("orderCount", orderCount)
.withDetail("threshold", orderCountThreshold)
.status("WARNING");
} else {
builder.withDetail("orderCount", orderCount);
}
// 2. 缓存服务健康检查
String redisStatus = checkRedisHealth();
builder.withDetail("redis", redisStatus);
// 3. 下游依赖服务健康检查
Map<String, String> dependencies = checkDependencies();
builder.withDetail("dependencies", dependencies);
return builder.up().build();
} catch (Exception e) {
return builder.down(e).build();
}
}
private String checkRedisHealth() {
try {
redisTemplate.opsForValue().get("health-check");
return "CONNECTED";
} catch (Exception e) {
return "DISCONNECTED: " + e.getMessage();
}
}
private Map<String, String> checkDependencies() {
Map<String, String> dependencies = new HashMap<>();
// 模拟检查支付服务、库存服务等下游依赖
dependencies.put("payment-service", checkServiceHealth("http://payment-service/actuator/health"));
dependencies.put("inventory-service", checkServiceHealth("http://inventory-service/actuator/health"));
return dependencies;
}
}
四、生产环境监控体系
1. 分层告警策略
使用 Alertmanager 实现告警的分级、分组和路由,避免告警风暴。
# alertmanager.yml
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alertmanager@example.com'
route:
group_by: ['alertname', 'cluster']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
routes:
- match:
severity: critical
receiver: 'pagerduty'
repeat_interval: 5m
- match:
severity: warning
receiver: 'slack'
- match:
service: order-service
receiver: 'order-team'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://alert-handler:8080/alerts'
- name: 'pagerduty'
pagerduty_configs:
- service_key: 'your-pagerduty-key'
- name: 'slack'
slack_configs:
- channel: '#alerts'
api_url: 'https://hooks.slack.com/services/...'
- name: 'order-team'
email_configs:
- to: 'order-team@example.com'
2. Prometheus 告警规则定义
根据 SLO (服务等级目标) 定义清晰的告警规则。
# alert-rules.yml
groups:
- name: order-service
rules:
# 服务可用性告警
- alert: OrderServiceDown
expr: up{job="order-service"} == 0
for: 1m
labels:
severity: critical
service: order-service
annotations:
summary: "订单服务不可用"
description: "订单服务实例 {{ $labels.instance }} 已宕机超过1分钟"
# 高错误率告警
- alert: HighErrorRate
expr: rate(http_server_requests_seconds_count{status=~"5..",job="order-service"}[5m]) / rate(http_server_requests_seconds_count{job="order-service"}[5m]) * 100 > 5
for: 2m
labels:
severity: warning
annotations:
summary: "订单服务错误率过高"
description: "订单服务5xx错误率超过5%,当前值: {{ $value }}%"
# 慢响应告警
- alert: SlowResponse
expr: histogram_quantile(0.95, rate(http_server_requests_seconds_bucket{job="order-service"}[5m])) > 2
for: 3m
labels:
severity: warning
annotations:
summary: "订单服务响应缓慢"
description: "订单服务P95响应时间超过2秒,当前值: {{ $value }}秒"
# JVM内存告警
- alert: HighMemoryUsage
expr: (jvm_memory_used_bytes{area="heap",job="order-service"} / jvm_memory_max_bytes{area="heap",job="order-service"}) * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: "订单服务内存使用率过高"
description: "订单服务堆内存使用率超过80%,当前值: {{ $value }}%"
3. 关键业务监控指标
将业务数据转化为可观测的指标,直接反映业务健康度。
@Component
public class BusinessMetricsService {
@Autowired
private MeterRegistry meterRegistry;
public void trackOrderMetrics(Order order) {
// 订单金额分布
DistributionSummary.builder("order.amount")
.baseUnit("yuan")
.tag("orderType", order.getType())
.register(meterRegistry)
.record(order.getAmount().doubleValue());
// 用户下单频率
Counter.builder("user.order.frequency")
.tag("userId", order.getUserId().toString())
.tag("userLevel", order.getUserLevel())
.register(meterRegistry)
.increment();
// 商品销量统计
Counter.builder("product.sales.volume")
.tag("productId", order.getProductId().toString())
.tag("category", order.getProductCategory())
.register(meterRegistry)
.increment(order.getQuantity());
}
// 转化率监控
public void trackConversion(String event, String userId, String source) {
Counter.builder("conversion.event")
.tag("event", event)
.tag("source", source)
.register(meterRegistry)
.increment();
}
}
五、监控体系最佳实践
1. 监控黄金指标 (The Four Golden Signals)
遵循 Google SRE 提出的四大黄金指标来聚焦核心监控点。
| 指标类型 |
监控项 |
告警阈值 |
优化目标 |
| 延迟 (Latency) |
P95响应时间 |
> 2秒 |
< 1秒 |
| 流量 (Traffic) |
QPS/RPS |
根据容量规划 |
弹性伸缩 |
| 错误 (Errors) |
错误率 |
> 1% |
< 0.1% |
| 饱和度 (Saturation) |
资源使用率 |
> 80% |
< 70% |
2. 监控数据治理策略
合理的数据治理能平衡监控效果与存储成本。
# 监控数据保留策略
retention:
# 原始数据保留时间
raw_data: 15d
# 聚合数据保留时间
aggregated_data: 90d
# 长期趋势数据保留时间
trend_data: 1y
# 监控数据采样策略
sampling:
# 高频指标采样率
high_frequency: 0.1
# 业务指标采样率
business_metrics: 1.0
# 链路追踪采样率
tracing: 0.01
3. 成本优化策略
在 云原生 环境下,监控成本不容忽视。
@Service
public class MonitoringCostOptimizer {
// 动态采样策略:根据系统负载调整采样率
public double getDynamicSamplingRate(String metricName, double currentLoad) {
if (currentLoad > 1000) { // 高负载时降低采样率
return 0.01;
} else if (metricName.startsWith("business.")) {
return 1.0; // 核心业务指标全采样
} else {
return 0.1; // 普通系统指标10%采样
}
}
public void manageDataLifecycle() {
// 实现监控数据的自动归档、压缩和清理逻辑
}
}
六、面试回答技巧与话术
基础回答模板 (简明扼要)
“微服务监控主要围绕指标(Metrics)、日志(Logs)、追踪(Traces)三大维度展开。我们通常采用 Prometheus 收集指标,Grafana 进行可视化;使用 ELK (Elasticsearch, Logstash, Kibana) 栈处理和分析日志;并集成 SkyWalking 或 Jaeger 实现分布式链路追踪,从而构建全方位的可观测性体系。”
深度回答模板 (展现体系化思维)
“在我们实际的微服务架构中,监控是一个分层、多维度的体系:
1. 指标监控层: 以 Prometheus 为核心,通过 Micrometer 客户端采集 JVM、HTTP 请求、数据库 连接池等系统指标,以及自定义的业务指标(如订单量、转化率)。通过 Grafana 配置仪表盘,并基于 SLO 设定多级告警规则。
2. 日志分析层: 推行结构化日志规范,使用 Logstash 或 Filebeat 采集日志至 Elasticsearch,通过 Kibana 进行聚合查询和实时分析。关键是在日志中注入 TraceId,实现与链路追踪的关联。
3. 链路追踪层: 集成 SkyWalking,无侵入地自动采集服务间调用的拓扑关系和性能数据,帮助我们快速定位跨服务调用的性能瓶颈和故障点。
4. 健康检查与探活层: 深度利用 Spring Boot Actuator,不仅提供基础的 /health 端点,还自定义了包含数据库、缓存、消息队列及关键下游服务状态的深度健康检查。
实践价值: 这套体系将我们的平均故障定位时间(MTTD)和平均修复时间(MTTR)显著降低。关键实践包括:依据‘四大黄金指标’定义核心监控项;实施分层告警以避免告警疲劳;建立业务指标与技术指标的关联分析模型;以及对监控数据进行生命周期管理以控制成本。”
可能追问的问题与应对思路
- 如何避免监控系统自身的单点故障?
- 思路:监控组件高可用。Prometheus 采用联邦集群或 Thanos 方案;Elasticsearch 本身是分布式集群,需合理设置分片与副本;Alertmanager 集群化部署。
- 监控数据量过大导致存储和查询压力大怎么办?
- 思路:数据治理。制定合理的采样策略(业务指标全量,性能指标抽样);实施数据分层存储(热数据SSD,温冷数据HDD或对象存储);对历史数据进行聚合和降精度后保留。
- 如何设计有效的、不烦人的告警规则?
- 思路:基于 SLO/SLI 设计,而非随意设定静态阈值。尝试使用动态基线(如同比、环比)告警。严格进行告警分级(紧急、重要、警告),并确保每条告警都有明确的处理手册和负责人。
- 业务监控具体怎么做?
- 思路:首先与业务方确定核心业务流程和关键业务指标(如支付成功率、购物车转化率)。其次,通过埋点或业务代码上报将这些指标纳入统一监控平台(如 Prometheus)。最后,建立业务健康度仪表盘,并设置业务层面的告警。
 发表于 2025-12-15 07:22:14
|
查看: 291|
回复: 0
发表于 2025-12-15 07:22:14
|
查看: 291|
回复: 0
