下载功能在项目中虽然不频繁出现,但却是不可或缺的基础模块。实现过程有时并不复杂,但涉及多类型资源、格式转换或批量打包时,就会变得相当繁琐。例如,从不同来源获取文件、处理网络资源、打包压缩等步骤,往往导致代码冗长。
为此,我们开发了一个库来极大简化下载逻辑,核心目标是:开发者只需关注要下载的数据对象,后续的加载、转换、压缩、响应输出等流程全部自动完成。
借助 @Download 注解,你可以用极简的代码完成下载:
@Download(source = "classpath:/download/README.txt")
@GetMapping("/classpath")
public void classpath() {}
@Download
@GetMapping("/file")
public File file() {
return new File("/Users/Shared/README.txt");
}
@Download
@GetMapping("/http")
public String http() {
return "http://127.0.0.1:8080/concept-download/image.jpg";
}
这看起来只是简化了常见场景?让我们看一个更复杂的需求:导出一个包含所有设备二维码图片的压缩包,且图片需以设备名命名。
传统实现需要:查询设备列表、逐个下载图片(需考虑缓存和并发)、等待全部完成、创建压缩包、处理响应流。代码量轻松超过百行。
而理想的情况是,我只需返回设备列表,其余一切自动处理:
@Download(filename = "二维码.zip")
@GetMapping("/download")
public List<Device> download() {
return deviceService.all();
}
public class Device {
private String name;
// 注解标记需要下载的资源地址
@SourceObject
private String qrCodeUrl;
// 注解指定生成的文件名
@SourceName
public String getQrCodeName() {
return name + ".png";
}
}
通过注解声明资源及其命名规则,库将自动完成下载、重命名、打包等一系列操作。
核心设计思路
整个库的设计基于响应式编程思想,但为了同时兼容 Spring WebMVC 和 SpringBoot WebFlux,内部实现上采用了一种 Mono<InputStream> 的混合模式。
兼容 WebFlux 的挑战
在 WebMVC 中,可通过 RequestContextHolder 获取请求响应对象。在 WebFlux 中,则需通过方法参数注入 ServerHttpResponse。为了保持接口简洁,我们通过自定义 WebFilter 将请求响应存入 Reactor Context,供后续流程获取。
整体架构
下载流程被抽象为一系列可插拔的处理器 (DownloadHandler),灵感来源于 Spring Cloud Gateway 的过滤器链。每个处理器负责一个步骤(如资源加载、压缩、写入),通过 DownloadHandlerChain 串联。DownloadContext 上下文对象贯穿全程,用于传递数据和状态。
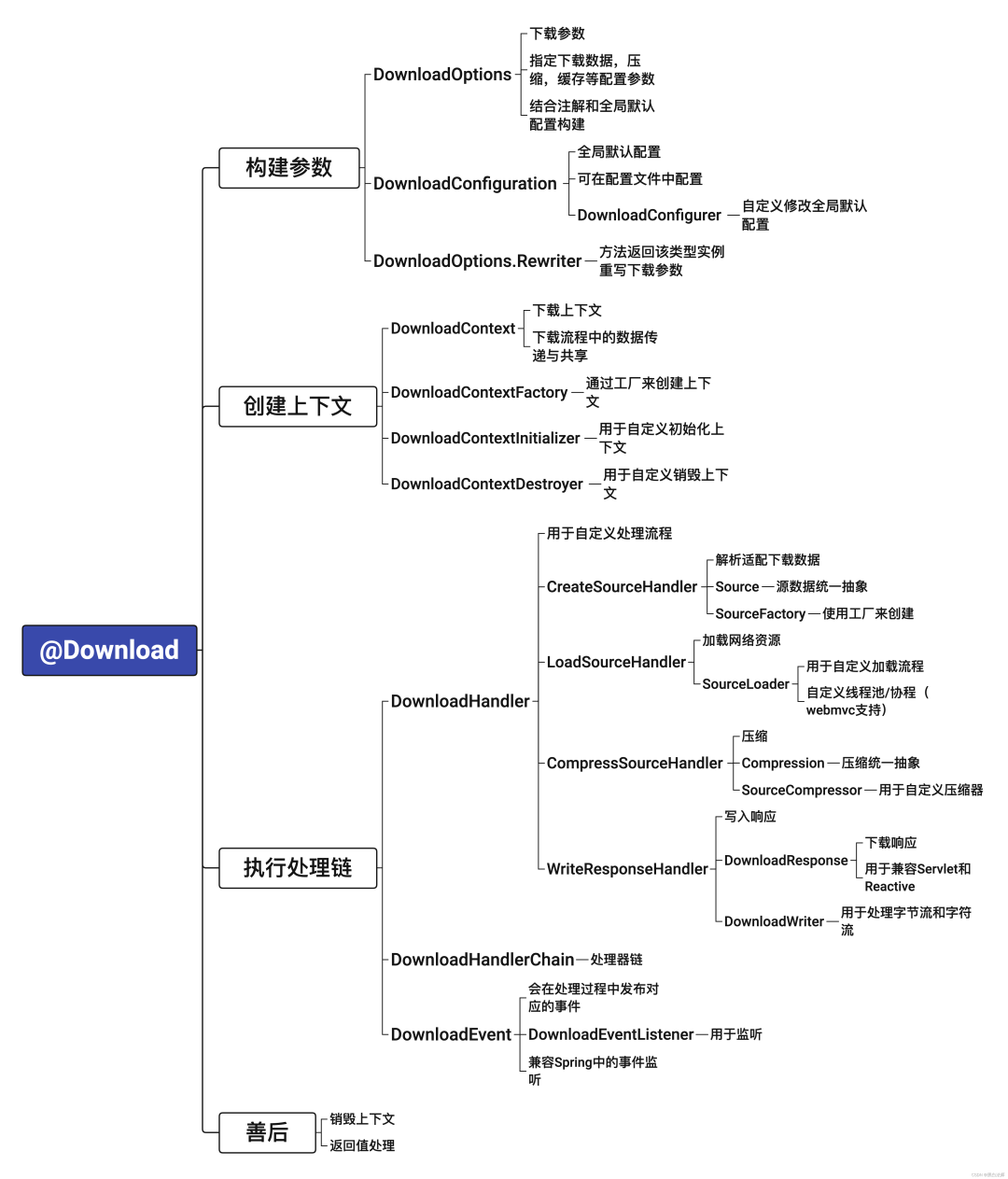
1. 多类型资源支持 (Source)
将各种下载对象抽象为 Source(资源源)。例如 FileSource 对应文件,HttpSource 对应网络资源。通过 SourceFactory 接口,我们可以匹配并创建不同类型的 Source。
对于自定义对象(如上文的 Device),通过在字段或方法上标注 @SourceObject、@SourceName 等注解,利用反射机制提取下载地址和文件名,再交由相应的 SourceFactory 处理,从而实现高度灵活性。
2. 并发加载 (SourceLoader)
对于网络资源等需要 IO 等待的操作,提供了 SourceLoader 接口支持并发加载。开发者可以根据需求定制线程池或采用其他异步策略,优化下载效率。
3. 压缩处理 (SourceCompressor)
压缩过程被抽象为 Compression 对象。库内置了常见的压缩格式支持,并提供了 SourceCompressor 接口,允许完全自定义压缩算法和格式。压缩支持内存操作和临时文件两种模式,以适应不同大小的数据。
4. 响应写入 (DownloadResponse)
为了兼容 HttpServletResponse 和 ServerHttpResponse,抽象了 DownloadResponse 接口。写入的核心是处理 InputStream 到 OutputStream 的转换。这里的一个技术难点是将 WebFlux 的 DataBuffer 发布流包装成传统的 OutputStream,我们通过自定义适配器成功实现了这一转换。
DownloadWriter 接口负责具体的流读写操作,支持自定义缓冲区大小、编码处理以及断点续传(Range头)等高级特性。
5. 事件与监控
整个下载流程的各个环节都发布了相应的事件,并提供了 DownloadEventListener 接口。基于事件机制,我们实现了详细的日志系统,可以记录每个步骤的执行情况、进度更新以及耗时分析,极大地便利了调试和监控。
注意事项
在实现过程中,需要注意处理流程的完整性。特别是在 WebFlux 中,响应写入后返回 Mono.empty(),会导致后续的处理器不被调用。因此,上下文初始化和销毁等收尾工作需要单独管理,确保在流程终止时被执行。
总结
通过 @Download 注解及其配套的扩展接口,我们能够将复杂的文件下载逻辑极度简化。这套设计将下载流程模块化、配置化,开发者只需通过注解和简单配置声明“要什么”,而无需关心“怎么下”和“怎么写”,显著提升了开发效率与代码可维护性。该库充分展示了 SpringBoot 生态下注解驱动和约定优于配置的威力,同时也为兼容响应式编程模型提供了良好实践。对于涉及网络IO和文件处理的场景,合理管理输入输出流是保证性能与稳定性的关键。
 发表于 2025-12-15 07:35:59
|
查看: 230|
回复: 0
发表于 2025-12-15 07:35:59
|
查看: 230|
回复: 0
