当 AI 大模型训练需要 TB 级数据吞吐、云计算面临百万级 IOPS 并发压力时,传统存储架构中 CPU 与 NVMe SSD 的性能错配、东西向流量泛滥等问题愈发尖锐。数据处理器(DPU)的出现,不仅是硬件层面的升级,更是对数据中心 “计算、存储、网络” 协同范式的根本性重构。
文章将从技术原理、架构创新、场景落地三个维度,解析 DPU 如何突破传统存储瓶颈,成为 AI 与云计算时代的核心基础设施。
一、DPU 的技术本质:从 “智能网卡” 到 “存储大脑”
在存算分离架构中,DPU 绝非简单的硬件加速器,而是集 “网络处理、存储卸载、安全隔离” 于一体的独立计算单元。其核心价值在于将原本由 CPU 承担的存储协议处理、数据校验、副本同步等 “非业务型计算” 完全接管,让 CPU 专注于 AI 训练、业务逻辑等核心任务,同时通过硬件级优化解决存储系统的性能瓶颈。
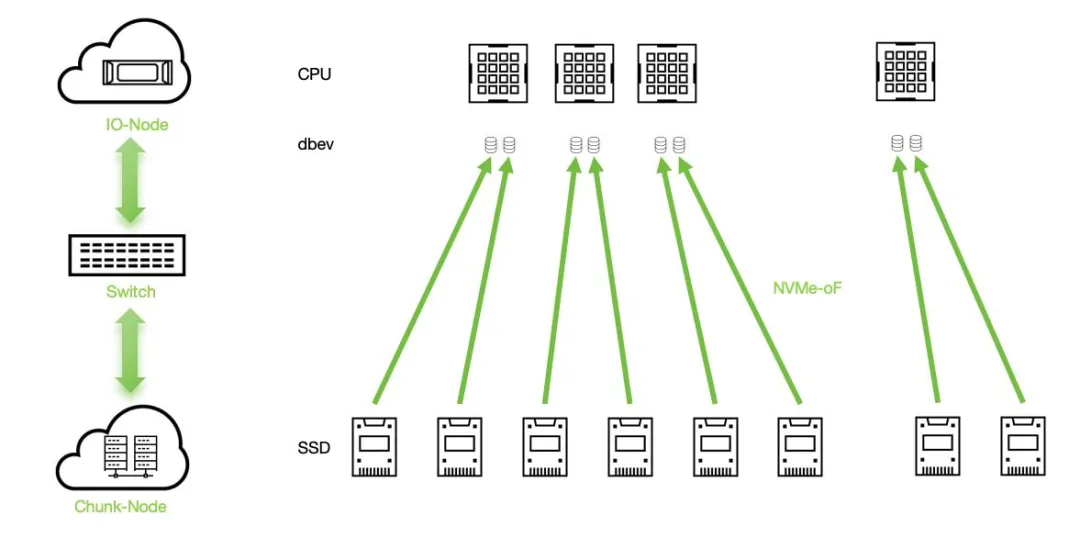
从硬件构成来看,以 NVIDIA BlueField-3 DPU 为代表的主流产品,已形成 “多核计算 + 专用加速 + 高速互联” 的三位一体架构:
- 多核计算核心:集成 16 核 ARM Cortex-A78 处理器,可独立运行完整操作系统与存储服务,支持复杂的存储逻辑调度,例如 Ceph OSD 管理、分布式 RAID 控制等,性能相当于一台小型服务器。
- 专用硬件加速引擎:内置加密 / 解密、压缩 / 解压缩、纠删码(EC)计算等专用模块,以 EC 加速为例,传统 CPU 处理 1TB 数据重建需数小时,而 DPU 通过硬件加速可将时间缩短至分钟级,且几乎不占用计算资源。
- 高速互联能力:支持 400Gbps 以太网或 InfiniBand 网络,配合 NVMe-over-Fabrics(NVMe-oF)协议与 RDMA 技术,实现存储设备的 “远程本地访问”—— 计算节点访问远端 JBOF(全闪存储服务器)中的 NVMe SSD 时,延迟可低至 10 微秒级,与本地访问性能相差不足 5%。
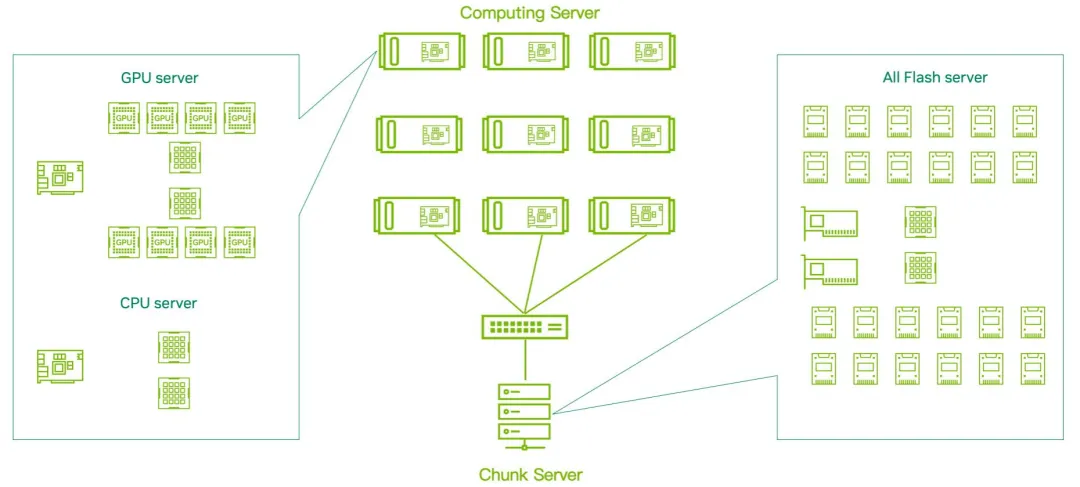
更关键的是,DPU 的 “独立运行” 特性打破了传统架构的依赖枷锁。通过独立供电设计,即使计算节点意外关机,DPU 仍能持续处理存储 I/O 请求,保障数据一致性;而独立主机模式(Separate Host Mode)则让 DPU 可同时扮演 “存储控制器” 与 “高性能网卡” 双重角色,既简化架构,又提升资源利用率。
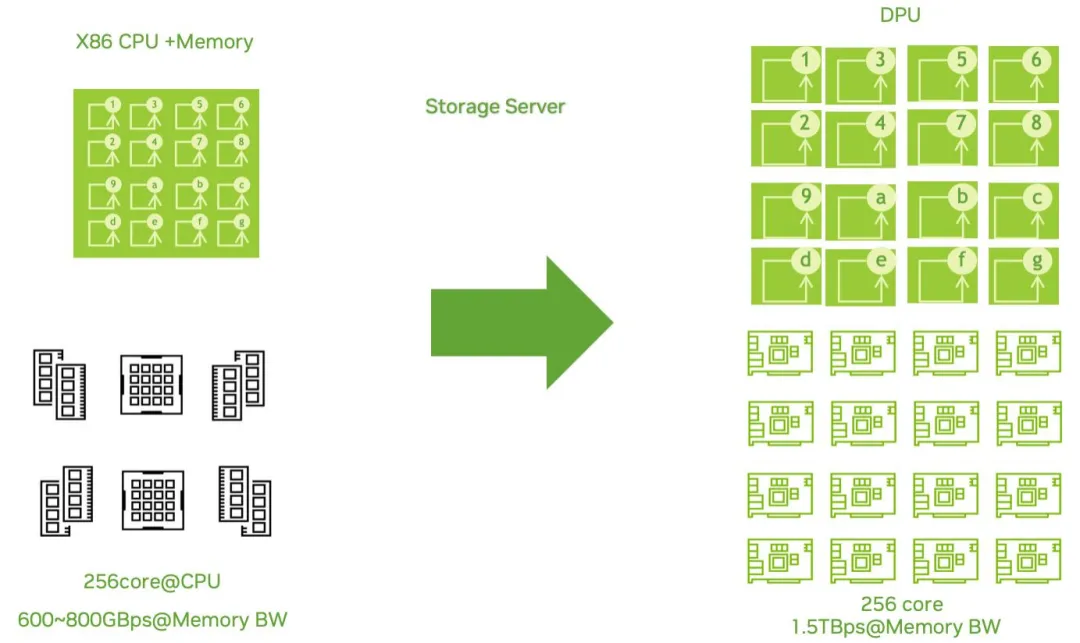
二、架构革命:DPU 如何破解传统存储三大死结
传统分布式存储架构长期受困于 “资源错配、流量泛滥、恢复缓慢” 三大问题,而 DPU 通过存算分离的深度优化,从根本上重塑了存储系统的运行逻辑。
1. 资源错配:从 “绑定浪费” 到 “独立扩展”
传统存算一体架构中,CPU 与存储资源的绑定设计导致 “两难困境”:为满足存储压缩、加密等计算需求,需配置高性能 CPU,但在存储 IO 需求较低时,CPU 资源利用率不足 30%;而当部署大量 NVMe SSD 时,CPU 又会成为 IO 处理瓶颈,导致 SSD 性能仅能发挥 50%。
DPU 通过 “计算 - 存储解耦” 彻底解决这一问题:计算节点专注于业务处理,存储逻辑由 DPU 接管,存储资源则集中于 JBOF 节点形成资源池。以 AI 训练场景为例,当需要扩展存储容量时,仅需向 JBOF 中增加 NVMe SSD,无需同步升级计算节点;若需提升存储处理能力,可单独增加 DPU 数量,实现 “按需扩展”。测试数据显示,这种架构下 CPU 利用率提升 40%,NVMe SSD 性能释放率超过 90%,硬件投资回报率(ROI)提升 2 倍以上。
2. 流量泛滥:从 “3 倍损耗” 到 “零东西向流量”
传统存储系统的 “三副本” 机制是网络流量的 “吞噬者”—— 每写入 1GB 数据,需同步传输 2GB 副本数据,导致东西向流量占比超过 60%,不仅浪费带宽,还易引发网络拥塞。以 100 节点集群为例,传统架构下副本同步产生的额外流量,会使网络带宽利用率仅为 33%,成为性能瓶颈。
DPU 通过 “副本本地化处理” 重构流量模型:将副本生成与同步逻辑下沉至 DPU 内部,计算节点写入数据时,仅需将数据传输至 DPU,副本由 DPU 在本地内存中完成复制后,直接分发至存储节点,无需跨 DPU 传输。以广泛使用的 Ceph 存储系统 为例,采用 DPU 架构后,东西向流量完全消除,网络带宽 100% 用于业务数据传输,三副本写入性能提升 17%,EC(纠删码)模式写入性能更是提升 174%,彻底释放网络潜力。
3. 故障恢复:从 “小时级” 到 “分钟级”
传统存储系统中,单块 NVMe SSD 故障后的重建过程完全依赖所在节点的 CPU,受限于 “计算孤岛” 效应,即使集群有数百个 CPU 核心,仅故障节点的 CPU 参与重建,导致 TB 级数据恢复需数小时,期间系统性能下降 50% 以上。
DPU 通过 “分布式并行重建” 颠覆这一现状:借助 SR-IOV(单根 I/O 虚拟化)技术,将单块 NVMe SSD 虚拟化为 8-16 个独立虚拟功能(VF),每个 VF 可映射至不同 DPU 节点。当 SSD 故障时,集群内所有 DPU 可同时访问故障 SSD 的不同逻辑分区,并行执行数据重建。测试显示,采用 DPU 的分布式 RAID 方案,6 块设备 RAID6 配置下随机读取性能可达 422 万 IOPS,1TB 数据重建时间从 3 小时缩短至 20 分钟,且对业务性能影响不足 10%。
三、场景落地:三大核心方案解锁 DPU 价值
DPU 并非 “通用解决方案”,而是需结合具体场景进行优化适配。目前,基于 DPU 的 CSAL QLC 加速、SRIOV 存储虚拟化、分布式 RAID 三大方案,已在 AI 训练、云计算、高性能计算(HPC)等领域实现规模化落地,成为解决行业痛点的关键技术。
1. CSAL QLC 加速:让大容量存储兼具性能与成本
QLC(四层级单元)NVMe SSD 凭借 “每 TB 成本低至传统 TLC 的 60%” 的优势,成为大规模数据存储的首选,但随机写入性能差、写入放大(WAF)高(可达 10 倍)等问题限制其应用。DPU 结合 CSAL(云存储加速层)技术,构建 “TLC 缓存 + QLC 容量” 的分层存储架构,完美平衡性能与成本。
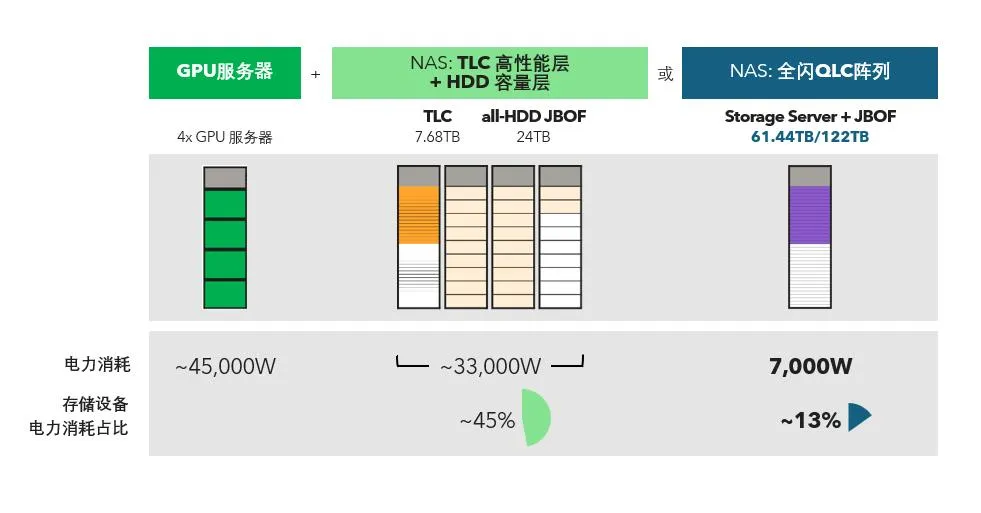
其核心逻辑是:DPU 通过 CSAL 层实时分析 IO 模式,将随机小 IO(如 AI 推理中的 RAG 应用 4K 写入)缓存至 TLC SSD 或 DPU 内存中,积累至 64K/128K 块后,以顺序写入方式写入 QLC SSD,实现 “随机转顺序” 的优化。测试数据显示,该方案下 4K 随机写入性能相比单独 QLC SSD 提升 20 倍,写入放大系数从 10 降至 1.2,同时 QLC SSD 寿命延长 3 倍以上。在 AI 训练场景中,采用该方案的存储系统可同时满足 “ checkpoint 保存(大块顺序写)” 与 “RAG 推理(小块随机读)” 的需求,硬件成本降低 40%。
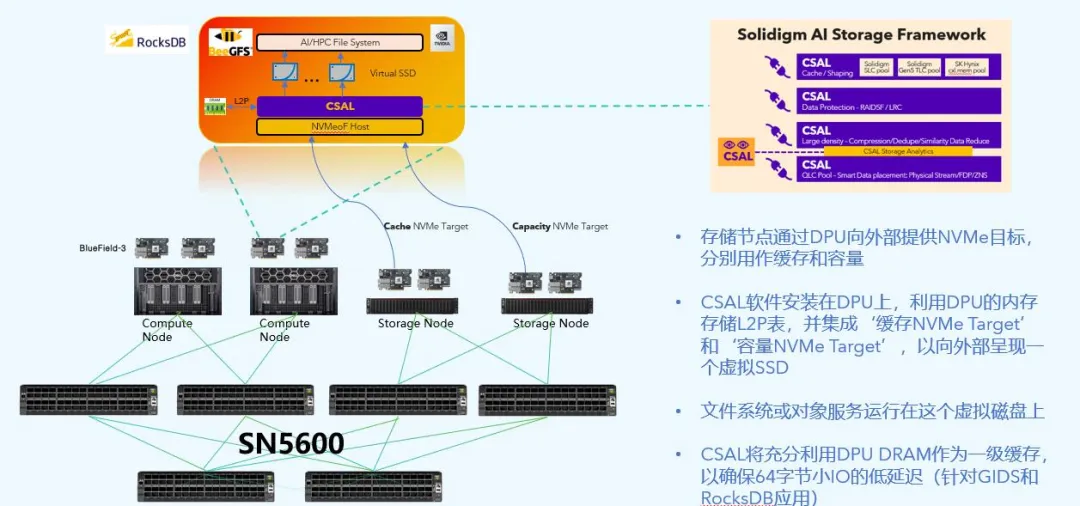
2. SRIOV 存储虚拟化:高密度 OSD 释放 Ceph 性能
Ceph 作为主流分布式存储系统,其性能与 OSD(对象存储设备)数量正相关,但传统架构中每块 NVMe SSD 仅能对应 1 个 OSD,高密度部署需大量服务器,成本高昂。三星 PM1743 NVMe SSD 结合 DPU 的 SRIOV 技术,实现 “1 块 SSD 生成 8 个 VF,对应 8 个 OSD” 的突破,大幅提升存储密度与性能。
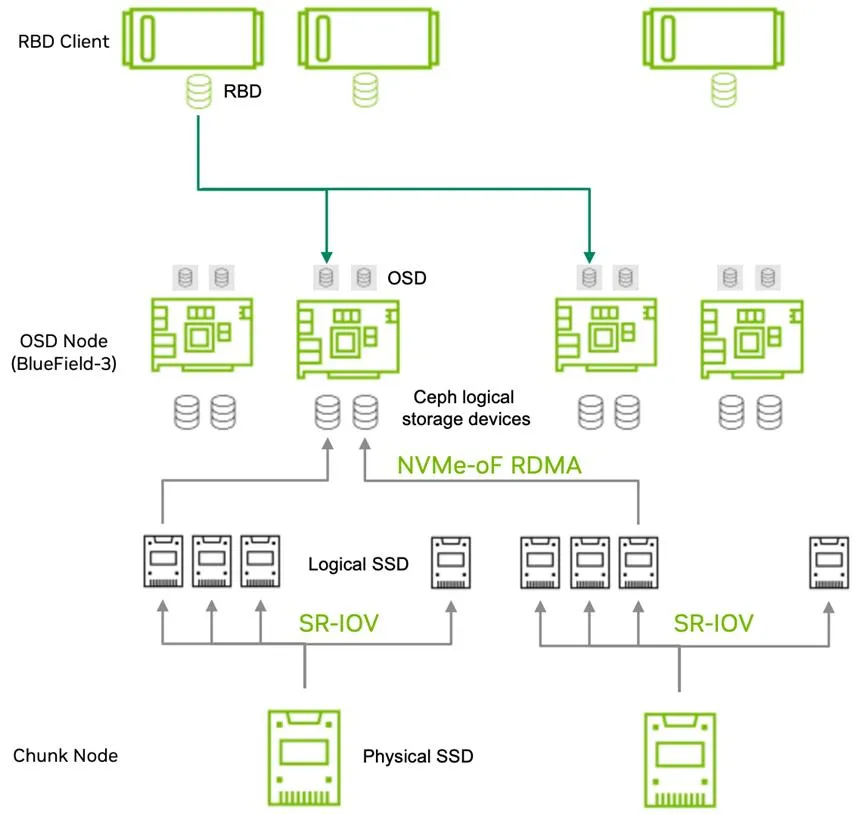
在实际部署中,单台 JBOF 服务器配置 8 块 PM1743 SSD,通过 SRIOV 可生成 64 个 VF,映射至 8 个 BlueField-3 DPU 节点,构建 64 个 OSD 的 Ceph 集群。测试显示,该架构下 Ceph 随机读性能达 32.46GBps,相比传统 3 台 x86 服务器的存算一体方案提升 176%,且硬件成本降低 50%。更重要的是,通过修改 Ceph CRUSH 规则,将副本与 EC 校验块限制在同一 DPU 内,消除跨节点东西向流量,进一步提升写入性能。
3. 分布式 RAID:块级保护简化存储设计
传统分布式存储需在文件系统或对象层实现数据保护(如 HDFS 三副本、Ceph EC),不仅开发复杂,还存在性能损耗。DPU 基于 XiRaid 软件定义 RAID 技术,在块设备层实现分布式保护,让所有存储系统可 “以单副本模式运行,享受 EC 级可靠性”。
该方案的核心是将 RAID 逻辑从 CPU 卸载至 DPU,通过 NVMe-oF RDMA 聚合不同 JBOF 节点的 NVMe SSD,构建跨节点的分布式 RAID 组。例如,在 6 块设备 RAID6 配置下,XiRaid 方案随机读性能达 422 万 IOPS,顺序写性能达 36GB/s,相比传统 EC 方案性能提升 60%;同时,存储利用率从三副本的 33% 提升至 90% 以上。对于 HDFS、MinIO 等存储系统,无需修改代码即可接入 XiRaid,大幅降低开发与维护成本。
四、未来展望:DPU 引领存储进入 “智能卸载时代”
随着 AI 与云计算的持续渗透,数据中心存储将面临 “更高性能、更低成本、更优能效” 的需求挑战,而 DPU 的发展方向已逐渐清晰:
- 智能化升级:未来 DPU 将融合 AI 能力,实现存储资源的 “预测性调度”—— 通过分析历史 IO 模式,提前将热数据缓存至高速介质,预判故障并主动迁移数据,进一步降低延迟与故障风险。
- 异构协同:DPU 与 GPU、FPGA 的深度融合将成为趋势,例如在 AI 训练中,DPU 可提前完成数据预处理与加载,GPU 专注于模型计算,形成 “DPU 管数据、GPU 算模型” 的协同模式,提升端到端效率。
- 边缘扩展:随着边缘计算对存储性能需求的提升,低功耗 DPU 将成为边缘节点的核心组件,实现 “边缘存算分离”,为工业互联网、自动驾驶等场景提供高效存储支撑。
从技术创新到产业落地,DPU 已不再是 “概念产品”,而是成为重构数据中心存储范式的关键力量。其核心价值不仅在于性能提升,更在于通过架构革新,让存储系统从 “被动支撑” 转向 “主动赋能”,为 AI、云计算等云原生场景 提供坚实的基础设施保障。未来,随着 DPU 生态的不断完善,数据中心将真正进入 “算力卸载革命” 的新时代。
 发表于 2025-12-15 11:48:58
|
查看: 191|
回复: 0
发表于 2025-12-15 11:48:58
|
查看: 191|
回复: 0
