从惊艳的Demo到生产环境,是许多AI项目的一道鸿沟。当应用开始答非所问、延迟飙升、成本失控时,问题的核心往往在于:我们是否只把大模型当成了一个“魔术盒”?
真正可上线、可扩展、可控成本的生产级LLM应用,依赖的并非灵光一现的提示词,而是一整套涵盖检索、推理、部署与观测的完整工程方法。下面这八大核心技能,将把“会调Prompt”的手艺,转化为可复现、可评测、可迭代的工程体系。
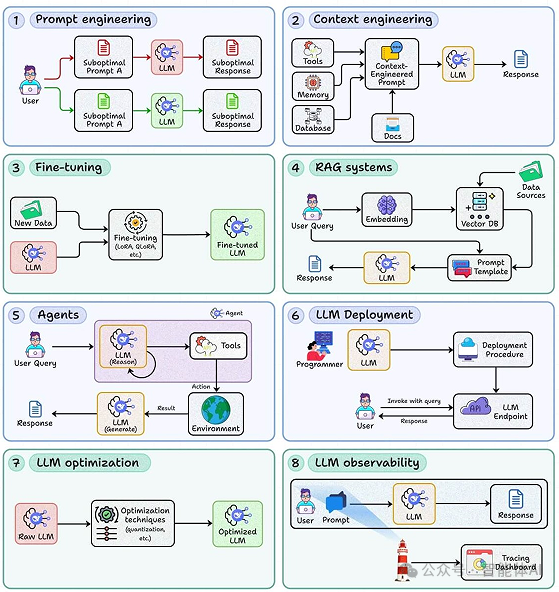
一、从“玩具”到“产品”:为什么LLM开发不止于提示词?
如果应用仅在演示中表现良好,一上线便暴露问题——如生成幻觉、延迟恶化、成本激增——这意味着它仍停留在“玩具级”。构建生产级LLM应用的关键,在于将整个链路工程化:数据、检索、推理、部署、观测与优化,环环相扣。以下八项技能构成了从零到一再到稳定运营的完整骨架。
二、八大支柱:从交互、架构到运维的完整体系
第1部分:基础交互层(决定模型的“思考”与“响应”)
1. 提示工程:与模型沟通的工程化方法
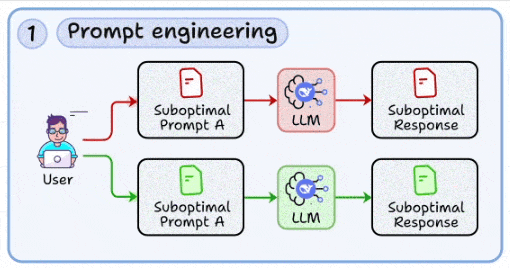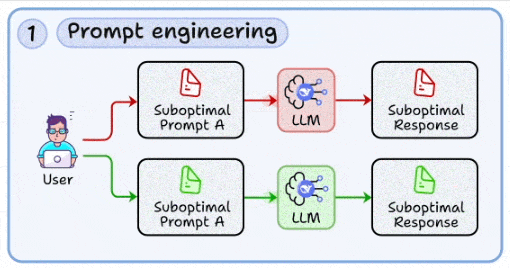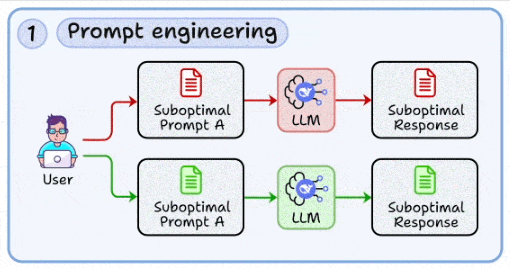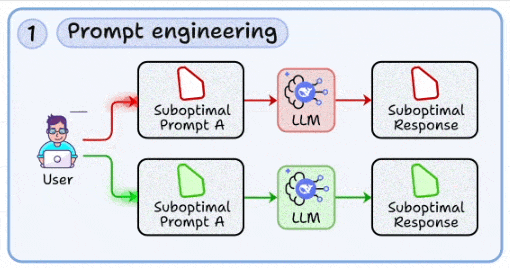
- 核心:从试错走向标准化,确保输出可预期、可复现、可评测。
- 实操要点:
- 结构化提示:明确角色、任务、输入、约束及输出格式,用示例固定风格与边界。
- 思维链策略:鼓励中间推理但避免冗长泄露;面向生产时,“隐式推理+显式检查表”更为稳健。
- 少样本示例:用代表性样例覆盖常见与极端场景,维持格式一致,减少模型“跑偏”。
- 守护规则:加入禁答域、合规提示与拒答模板,利用后置校验约束输出。
- 升华:提示词不是文案,而是“接口设计”。每个提示都应支持版本化管理、回滚与AB测试。
2. 上下文工程:为模型注入“外部记忆”
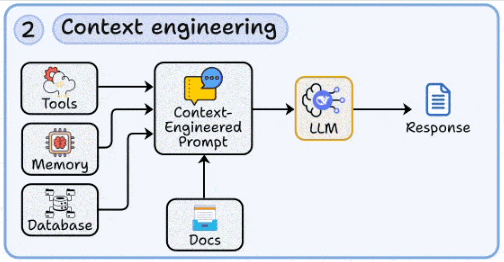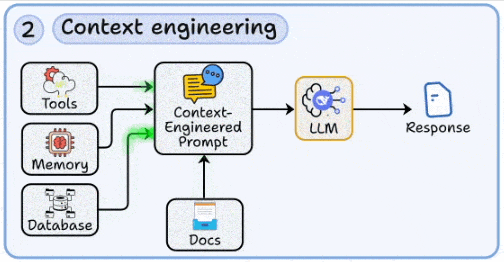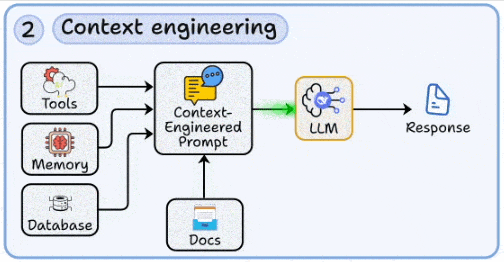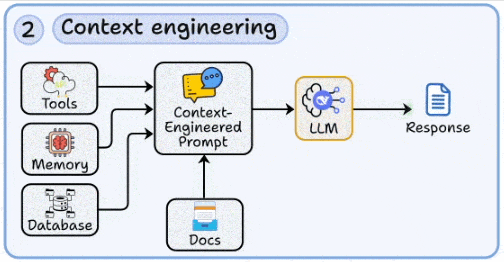
- 核心:将最新、私域、长尾知识按需注入模型上下文,突破训练语料的时效与领域限制。
- 实操要点:
- 切分与压缩:语义切分优于定长切分;对长文本进行摘要压缩、关键句抽取或表格结构化处理。
- 上下文预算:严格控制总token数;采用“查询理解→检索→重排→压缩→生成”的分层管线。
- 冷热分层:热点知识缓存,冷数据实时检索;对重复查询实施响应缓存与模板化。
- 完整性与噪声平衡:宁缺毋滥,优先选择高相关、可溯源的片段。
- 价值:上下文工程是构建RAG(检索增强生成)与智能体能力的地基,决定了应用的“读题能力”。
第2部分:系统架构层(决定应用的“构成”与“运作”)
3. 模型微调:为业务场景“量身定制”
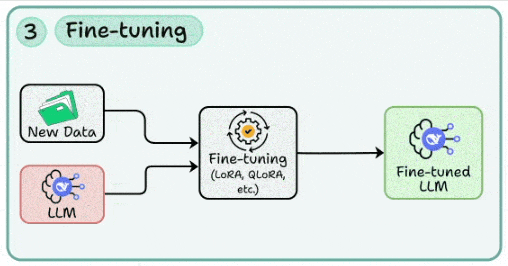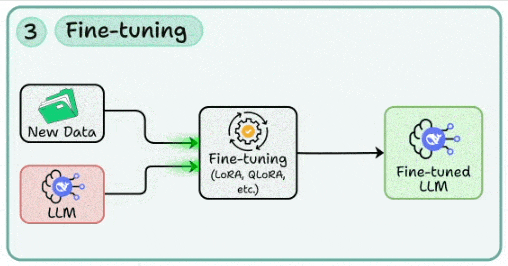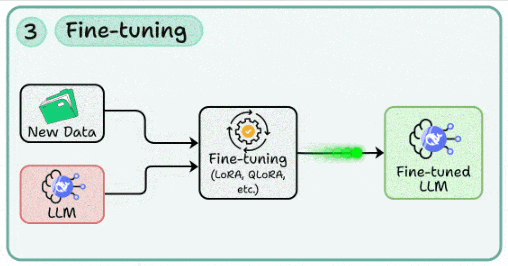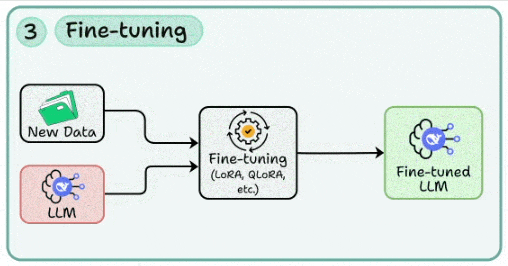
- 核心:当Prompt工程与RAG的效果触及天花板时,通过微调注入特定的风格、术语与流程知识。
- 技术路径:
- SFT + LoRA/QLoRA:低成本适配指令跟随、领域写作与特定对话风格。
- 偏好对齐:利用DPO、ORPO等方法让模型输出更符合人类偏好或专家标准。
- 数据治理:高质量的小规模数据远胜于大噪声数据;注重去重、反模板化与难例采样。
- 风险与控制:防止过拟合与灾难性遗忘;建立离线/在线评测机制,监控训练-推理漂移。
- 实践建议:先利用弱监督数据构建基线模型,再结合真实用户反馈迭代进行偏好对齐。微调过程常依赖Python生态中的相关框架与工具。
4. RAG系统:让模型“引经据典”,大幅降低幻觉
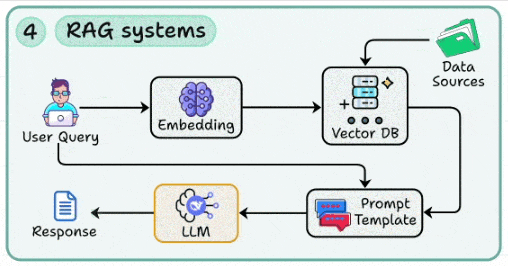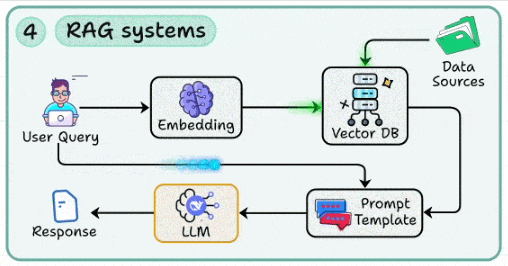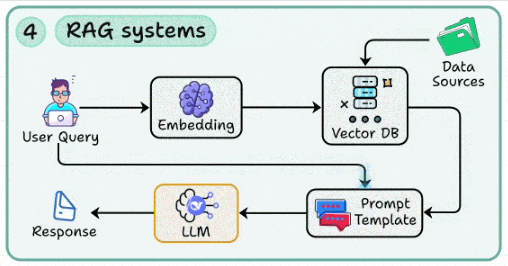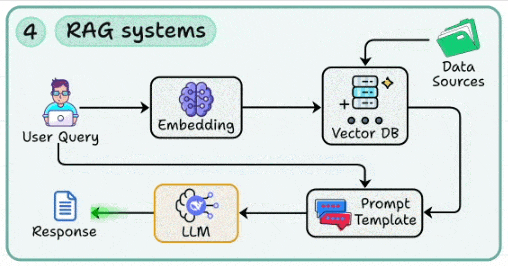
- 核心:检索增强生成,用外部事实支撑生成过程,显著减少模型编造。
- 关键构件:
- 向量索引:使用HNSW、IVF等算法;嵌入模型选型应以领域特性为先(如多语种、代码、法务)。
- 检索流水线:构建“召回→重排(结合BM25/交叉编码器)→去冗→上下文构造→提示拼装”的完整流程。
- 提示融合:将证据块结构化地嵌入提示,并附带来源、时间戳、置信度等信息。
- 质量闭环:
- 指标:关注检索@k准确率、支持度覆盖率、答案忠实度、端到端用户满意度。
- 评测集:构建包含真实问题、标准证据与期望答案的数据集,用于持续回归测试。
- 进阶:探索多路检索(关键词、语义、表格)、查询改写、基于任务复杂度的动态k值调整。
5. 智能体(Agent):让AI从“问答机”升级为“执行者”
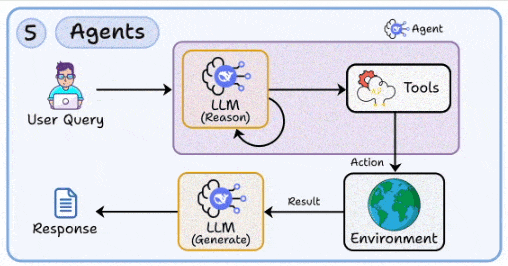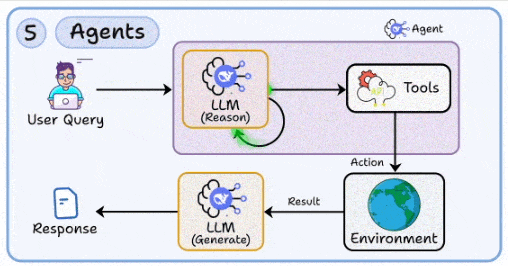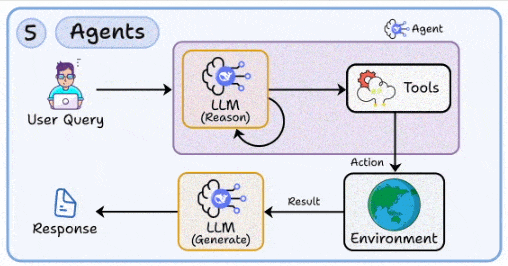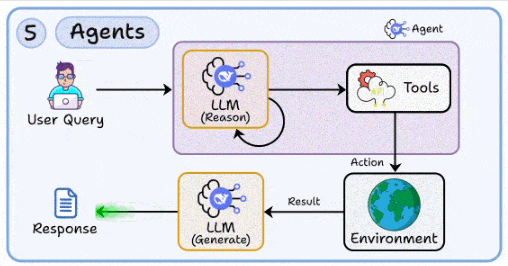
- 核心:实现多步骤推理、工具调用以及计划—执行—反思的闭环。
- 设计要点:
- 工具接口:确保函数、HTTP接口等定义清晰、操作幂等、可重试,并明确超时与速率限制。
- 状态管理:采用有限状态机或DAG工作流以提升可控性;记录计划、上下文、产出与决策原因。
- 错误恢复:设计超时、半故障、幂等补偿及回滚策略;为未知异常准备安全出口。
- 安全护栏:实施输入净化、输出校验、权限最小化(仅授予必要的工具与数据访问权)。
- 运营实践:为关键步骤记录详细日志与可回放的“剧本”,便于事后复盘与模型再训练。
第3部分:运维优化层(决定应用如何“跑得稳、跑得省”)
6. LLM部署:将模型转化为可靠的生产力API
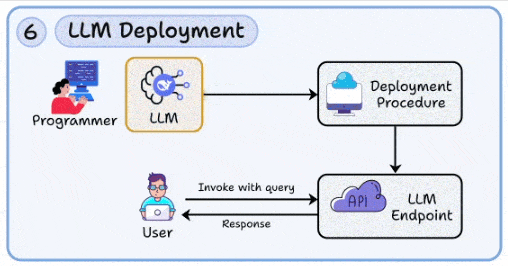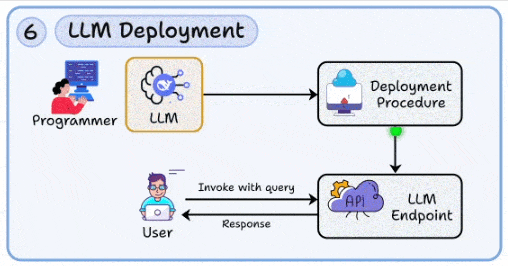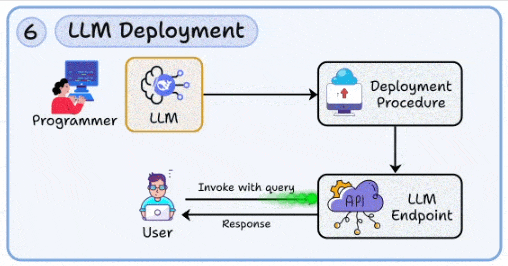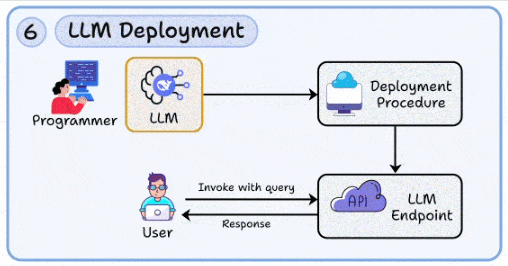
- 核心:实现高可用、弹性可扩展与成本可控的模型服务。
- 关键能力:
- 推理引擎:采用vLLM、TGI、TensorRT-LLM等;利用动态批处理、PagedAttention、KV缓存优化性能。
- 性能与弹性:实施并发控制、请求队列与优先级划分、灰度发布与熔断机制、自适应扩缩容。
- 成本与安全:建立分层路由(小模型兜底/大模型提质)、配额与速率限制、完善的鉴权与审计日志。
- 上手工具:利用Ray Serve、KServe、Beam等平台简化服务部署与扩缩容管理;按SLA划分不同服务层级。现代LLM应用的部署常与Docker及Kubernetes等云原生技术紧密结合。
7. LLM优化:在不牺牲质量的前提下“瘦身提速”
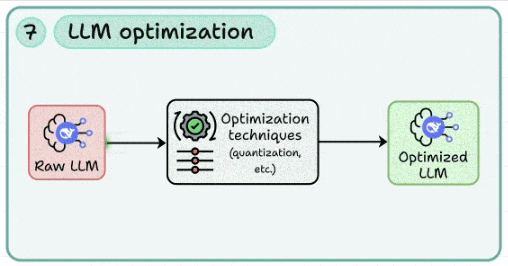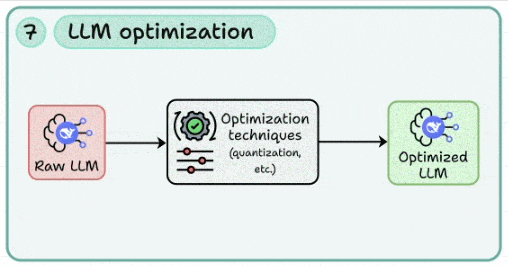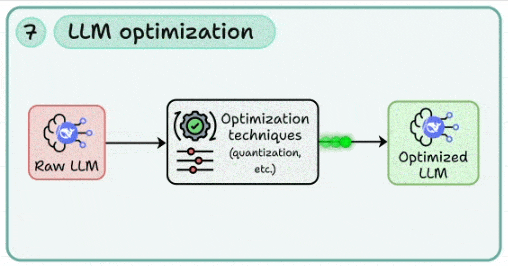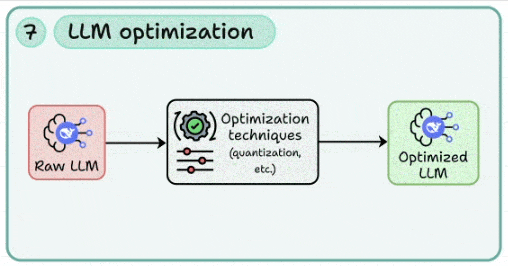
- 核心:以单位效果最低成本为目标的系统性优化。
- 技术选型:
- 量化:应用INT8/4、AWQ、GPTQ、FP8等技术;需评估精度回退并进行任务级对齐验证。
- 蒸馏:通过任务蒸馏或回应蒸馏,将大模型能力迁移至更小、更高效的模型。
- 结构优化:探索模型剪枝、推测解码(Speculative Decoding)、早停、响应裁剪与缓存。
- 工程技巧:实施提示裁剪、上下文压缩、可复用中间结果缓存;同时监控缓存命中率与数据新鲜度。
8. 可观测性:没有观测,就没有优化与信任
- 核心:让每一次模型请求的“来龙去脉”和“量化画像”清晰可见。
- 三类信号:
- 链路追踪(Trace):记录从用户请求到工具调用再到最终生成的完整链路(可使用OpenTelemetry等标准)。
- 指标(Metrics):监控p50/p95延迟、请求成功率、Token用量、缓存命中率、单请求成本等。
- 日志与评估(Logs & Evals):留存脱敏后的输入/输出快照、记录拒答率、幻觉告警,并结合离线评测与在线AB测试。
- 闭环:建立“观测→诊断→变更→回归测试→发布→再观测”的持续改进节奏,形成日/周级别的迭代循环。
三、总结与实践路径
- 这八项能力构成一条完整的LLM应用生命周期:需求与交互设计(1-2)→ 系统化实现(3-5)→ 上线与运维保障(6-8)。任何一环的薄弱都将在生产环境中被放大。
- 入门路径建议:
- 初学者:首先夯实“提示工程”与“上下文工程”;接着尝试构建一个最小可用的RAG系统。
- 进阶者:引入“智能体”与“模型微调”以处理复杂任务;同时开始建设“部署”、“优化”与“可观测性”能力。
自检清单(摘录):
- 你的提示词是否已版本化并可进行AB测试?上下文管理是否有预算控制与压缩策略?
- RAG系统是否有可回放的自动化评测集?智能体是否具备可重试、可回滚的容错机制?
- 推理服务是否支持动态批处理与KV缓存?是否实施了分层路由与细粒度成本监控?
- 是否建立了端到端的可观测性体系与数据脱敏规范?是否有按周进行的质量回归测试?
|  发表于 2025-12-15 18:15:12
|
查看: 259|
回复: 0
发表于 2025-12-15 18:15:12
|
查看: 259|
回复: 0
