传统爬虫开发中,最耗费精力的往往并非获取页面本身,而是在于后续的维护工作:一旦目标网页结构发生变化,精心编写的XPath或CSS选择器规则便会全部失效,需要人工重新分析并调整。
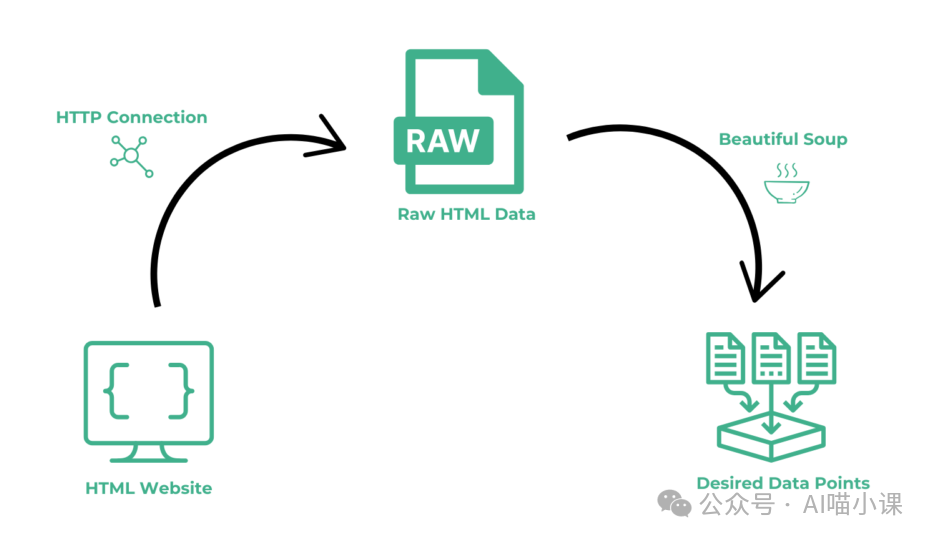
这正是Crawlab AI旨在解决的核心痛点。它的目标并非替代完整的爬虫框架来处理请求、反爬或调度,而是聚焦于一个更具体的环节:将繁琐且脆弱的页面解析规则生成工作,交由大语言模型自动完成。
本文将从实际应用出发,逐步演示如何使用Crawlab AI,涵盖代码编写、字段描述技巧、常见陷阱及适用场景分析。
传统工作流与AI介入点
一个典型的爬虫流程如下:
- 发起页面请求(使用requests、Playwright等工具)。
- 打开开发者工具分析页面。
- 人工审视DOM结构。
- 编写XPath/CSS Selector解析规则。
- 若页面改版,则重复步骤2-4。
其中的高昂成本不在于初次编写规则,而在于持续的规则维护。Crawlab AI的定位非常清晰:它接管从原始HTML到结构化数据的解析环节。
请求页面 → 反爬 → 拿到HTML → [解析] → 结构化数据 → 存储
↑
Crawlab AI 接管
环境准备
开始前,请确保满足以下条件:
- Python 环境(版本 ≥ 3.8)
- 有效的 Crawlab AI API Key
- 可访问外网(用于模型推理)
安装Crawlab AI的官方SDK:
pip install crawlab-ai
安装后,在Python环境中尝试导入以验证:
import crawlab_ai
实战:文章信息抽取
我们以一个常见且结构多变的页面类型——资讯/博客文章页为例,演示如何抽取指定字段。
目标字段:
title: 文章标题author: 作者publish_time: 发布时间content: 正文内容(需排除相关推荐、广告、评论等无关信息)
示例代码:
from crawlab_ai import CrawlabAI
# 初始化客户端,替换为你的API Key
client = CrawlabAI(api_key="YOUR_API_KEY")
# 调用extract方法进行解析
result = client.extract(
url="https://example.com/article/123",
fields={
"title": "文章标题",
"author": "作者姓名",
"publish_time": "文章发布时间",
"content": "文章主体内容,排除广告、推荐、评论、作者介绍等非正文部分"
}
)
print(result)
字段描述的关键性:
使用Crawlab AI时,核心转变在于将“编写精确的XPath规则”转换为“提供清晰的字段语义描述”。描述的质量直接决定结果的准确性。
例如,若仅将content字段描述为"正文",模型很可能将推荐阅读、作者简介乃至版权声明都包含进来。通过将其明确描述为"文章主体内容,排除广告、推荐、作者介绍和评论区",可以显著提升抽取精度。
返回结果:
解析成功将返回一个结构化的JSON对象,格式如下:
{
"title": "示例文章标题",
"author": "作者名",
"publish_time": "2023-10-27 10:00:00",
"content": "这里是经过清洗的文章正文内容……"
}
获取到结构化数据后,便可轻松进行后续操作,如存入数据库、转换为Markdown、进行向量化处理或喂给其他下游大模型。
常见陷阱与最佳实践
-
字段描述过于简略
错误示例:"content": "正文"
这会导致模型无法理解边界,引入大量噪音。
正确做法:像给人下达指令一样,明确排除项。例如:"content": "文章主体内容,排除广告、推荐、评论区、版权声明"。
-
一次性抽取过多字段
初次尝试时,建议将字段数量控制在3-5个以内,先验证模型对页面结构和指令的理解是否准确,再逐步增加。
-
误用于强一致性场景
Crawlab AI基于概率模型生成结果,并非确定性规则引擎。因此,它不适用于要求100%精确的场景,例如:
总结与适用性评估
基于实际使用经验,Crawlab AI在不同字段上的表现可归纳如下:

- 高可靠性字段:文章标题、作者、有明确标识的发布时间等。
- 需注意校正的字段:长篇文章的正文边界、复杂的图文混排内容。
- 不推荐使用的场景:对精确性有绝对要求的数值型数据、金融统计数据。
结论:Crawlab AI并非万能,其准确性也非完美无缺。然而,在应对频繁变化的网页解析需求时,它能将开发者从枯燥的规则维护中解放出来,通过Python脚本实现解析流程的智能化,总体成本效益远高于传统人工维护方式。
 发表于 2025-12-16 01:18:36
|
查看: 224|
回复: 0
发表于 2025-12-16 01:18:36
|
查看: 224|
回复: 0
