Compute-Sanitizer 是 NVIDIA CUDA Toolkit 中默认集成的运行时正确性检查工具。它能够在程序运行时自动检测多种常见错误,无需开发者手动捕获每一个 CUDA 运行时 API 的返回状态,极大提升了调试效率。在接手或评审他人代码时,先用 Compute-Sanitizer 运行一遍,确认无报错,是验证代码基础正确性的有效手段。该工具支持 CUDA C++、CUDA Fortran、CUDA Python 等多种编程语言。
Compute-Sanitizer 包含多个子工具,分别针对不同类型的错误:
| 子工具 |
功能定位 |
典型检测场景 |
memcheck (默认) |
检测非法代码行为 |
非法指令、内存越界访问、地址对齐错误 |
racecheck |
检测共享内存的数据竞争 |
RAW(写后读)、WAW(写后写)、WAR(读后写)冲突 |
initcheck |
检测未初始化全局内存的访问 |
读取未赋值的全局内存变量 |
synccheck |
检测同步原语的非法使用 |
错误调用 __syncthreads() |
命令行参数完整列表可参考官方文档:https://docs.nvidia.com/cuda/sanitizer-docs/ComputeSanitizer/index.html#command-line-options
memcheck
memcheck 是 Compute-Sanitizer 的默认子工具,官方建议在使用其他子工具前优先运行它。
基本使用命令为:
compute-sanitizer ./my_executable
检测的内核函数错误类型
- 无效/越界内存访问:核函数中访问未分配、已释放或超出范围的设备内存或共享内存。
- 无效 PC/无效指令:核函数中执行非法指令。
- 未对齐的内存加载/存储:访问需要对齐的内存时,地址不符合硬件对齐要求。
核心特性
- 错误定位能力:如果编译时添加了
-lineinfo 选项,memcheck 可以直接将错误定位到源代码的特定行,大幅降低调试成本。
- 性能影响:运行时会增加核函数的执行耗时(因为需要追踪内存访问),但这属于调试阶段可接受的代价。对于大型函数,建议进行分块单元测试。
- 设备内存泄漏检查:支持检测
cudaMalloc 后未 cudaFree 导致的内存泄漏问题。
- 更严格的错误检查:比标准的 CUDA 运行时错误检查更严格,能捕捉到更多潜在错误。例如,对于一个大小为10的数组,访问其第11个元素的位置,标准运行时可能不会报错,但
memcheck 会将其标记为内存越界访问错误。
案例
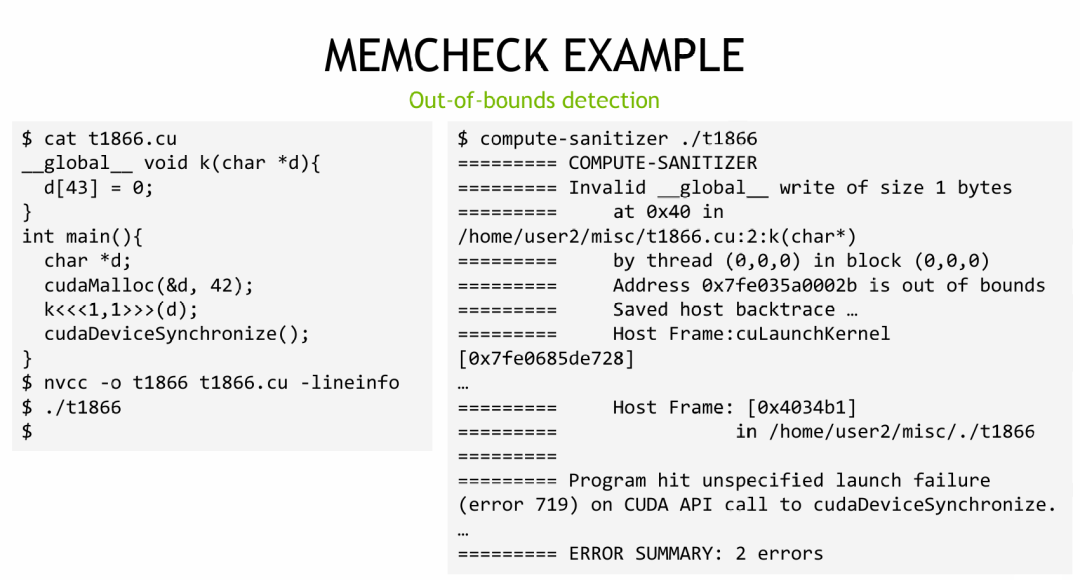
下图展示了一个典型的越界访问错误:一个大小为42的数组,被访问了第43个位置。在没有 Compute-Sanitizer 的情况下,此代码可能“正常”运行并调用同步,但实际上隐藏了一个严重错误。报告 /home/user2/misc/t1866.cu:2:k(char*) 指明了错误发生在第2行的 k 函数中。
racecheck
在 并发编程 模型下,CUDA 线程通常以任意顺序执行,共享内存是线程间通信的关键。此时,读写操作的顺序直接影响程序正确性,数据竞争会导致结果错误,因此需要专门检测。
- 使用方法:需显式指定工具,命令为
compute-sanitizer --tool racecheck ./my_executable。
- 检测范围:仅针对共享内存的数据竞争(不检测全局内存或寄存器)。
- 竞争类型与危害:
- WAW (写后写):两个线程对同一内存位置的写操作未正确同步。最终结果不确定,破坏数据一致性。
- RAW (写后读):一个线程写入后,另一线程读取,但写入结果对读取线程未确保可见性。可能导致读取到过时或未完成的值,是最典型的数据依赖错误。
- WAR (读后写):一个线程读取后,另一线程写入,缺乏同步可能导致有害的指令重排,使读操作看到本不应看到的新值。
更多报告模式信息请参阅:https://docs.nvidia.com/cuda/sanitizer-docs/ComputeSanitizer/index.html#racecheck-report-modes
案例
下图展示了一个 RAW(写后读)竞争案例。如果在写入共享内存后不进行同步就直接读取,运行较快的线程可能会读到尚未写入的数据,导致结果错误。错误报告明确提示了第4行(写入)和第5行(读取)之间存在风险。

initcheck
在操作系统中,申请内存(如 cudaMalloc)只是在 MMU 的页表中创建虚拟地址到物理地址的映射。必须进行初始化(写入数据)才会真正分配物理内存页。因此,声明后未初始化就直接访问是有问题的。initcheck 专门用于检测对未初始化的全局内存设备的访问。

synccheck 子工具
CUDA 提供了多级同步机制,使用不当会导致死锁或数据错误,synccheck 工具用于检测此类问题。
- 同步层级:线程块级 (
__syncthreads())、Warp 级 (__syncwarp())、协作组 (this_group.sync()) 等。
- 常见错误:
- 线程块级:在条件分支(如
if)中调用 __syncthreads(),导致部分线程未执行该同步。
- Warp 级:
__syncwarp() 的掩码参数使用非法,或部分线程未到达同步点。
- 使用方法:
compute-sanitizer --tool synccheck ./my_executable。
- 架构影响:在计算能力 7.0 (Volta) 及以上的架构中,执行模型放宽了对 Warp 内同步的要求。例如,
__syncwarp() 支持通过掩码指定需要同步的线程子集,只要掩码内的活跃线程全部到达同步点即可合法执行,这降低了部分场景下的错误检出率。
详细案例可参考官方文档:https://docs.nvidia.com/compute-sanitizer/ComputeSanitizer/index.html#synccheck-demo-illegal-syncwarp
作为 人工智能 与高性能计算领域的关键开发工具,熟练掌握 Compute-Sanitizer 对于保障 GPU 程序质量至关重要。它也是进行有效 软件测试,尤其是单元测试环节的重要辅助工具。 |  发表于 2025-12-16 19:19:09
|
查看: 389|
回复: 0
发表于 2025-12-16 19:19:09
|
查看: 389|
回复: 0
