在Java高并发开发中,对于下面这段结合了事务与锁的代码,开发者可能很熟悉:在Service层的方法上同时使用@Transactional注解和Lock锁。
控制层代码示例 (Controller):
@ApiOperation(value="秒杀实现方式——Lock加锁")
@PostMapping("/start/lock")
public Result startLock(long skgId){
try {
log.info("开始秒杀方式一...");
final long userId = (int) (new Random().nextDouble() * (99999 - 10000 + 1)) + 10000;
Result result = secondKillService.startSecondKillByLock(skgId, userId);
if(result != null){
log.info("用户:{}--{}", userId, result.get("msg"));
}else{
log.info("用户:{}--{}", userId, "哎呦喂,人也太多了,请稍后!");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
}
return Result.ok();
}
业务层代码示例 (Service):
@Override
@Transactional(rollbackFor = Exception.class)
public Result startSecondKillByLock(long skgId, long userId) {
lock.lock();
try {
// 校验库存
SecondKill secondKill = secondKillMapper.selectById(skgId);
Integer number = secondKill.getNumber();
if (number > 0) {
// 扣库存
secondKill.setNumber(number - 1);
secondKillMapper.updateById(secondKill);
// 创建订单
SuccessKilled killed = new SuccessKilled();
killed.setSeckillId(skgId);
killed.setUserId(userId);
killed.setState((short) 0);
killed.setCreateTime(new Timestamp(System.currentTimeMillis()));
successKilledMapper.insert(killed);
// 模拟支付
Payment payment = new Payment();
payment.setSeckillId(skgId);
payment.setSeckillId(skgId);
payment.setUserId(userId);
payment.setMoney(40);
payment.setState((short) 1);
payment.setCreateTime(new Timestamp(System.currentTimeMillis()));
paymentMapper.insert(payment);
} else {
return Result.error(SecondKillStateEnum.END);
}
} catch (Exception e) {
throw new ScorpiosException("异常了个乖乖");
} finally {
lock.unlock();
}
return Result.ok(SecondKillStateEnum.SUCCESS);
}
乍看之下,这段在业务方法上加事务、在核心逻辑外加锁的代码似乎没有问题。然而,这种写法存在一个严重的隐患,会导致超卖。下图展示了模拟1000个并发请求抢购100件商品时的测试结果:
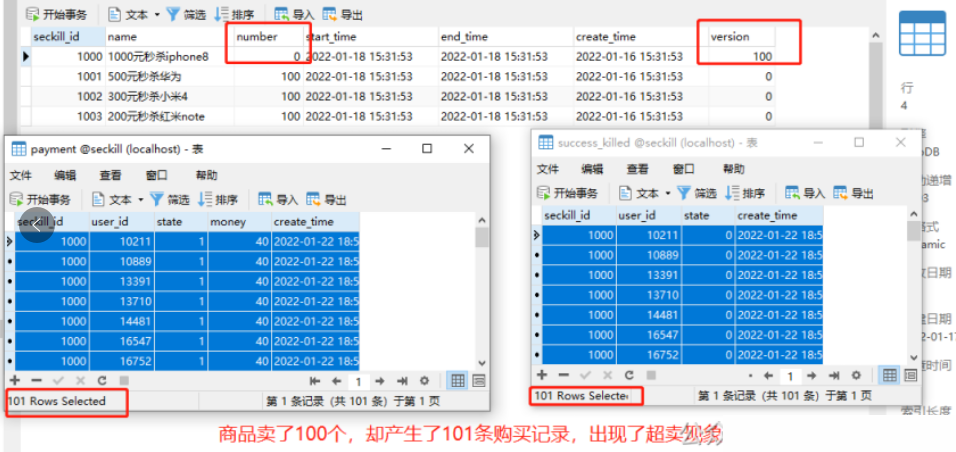
问题的根源在于锁释放与事务提交的时机不一致。在上述代码中,锁在finally块中释放,但 @Transactional 声明的事务提交发生在整个方法执行完毕之后。这意味着,有可能在锁释放后、事务提交前,另一个线程已经获取到锁并读取到了未更新的“脏”库存数据,从而导致超卖。
因此,确保加锁范围覆盖整个事务周期是解决此问题的关键。
解决方案
1. 改进版程序锁(Controller层加锁)
最直接的解决方式是将加锁时机提前到调用Service方法之前,确保锁的持有周期包含整个事务。
@ApiOperation(value="秒杀实现方式——Lock加锁")
@PostMapping("/start/lock")
public Result startLock(long skgId){
// 在调用业务方法前加锁
lock.lock();
try {
log.info("开始秒杀方式一...");
final long userId = (int) (new Random().nextDouble() * (99999 - 10000 + 1)) + 10000;
Result result = secondKillService.startSecondKillByLock(skgId, userId);
if(result != null){
log.info("用户:{}--{}", userId, result.get("msg"));
}else{
log.info("用户:{}--{}", userId, "哎呦喂,人也太多了,请稍后!");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 业务方法执行完毕后释放锁
lock.unlock();
}
return Result.ok();
}
此时,Service方法内部不再需要加锁。经压力测试(并发1000,商品100),此方案可有效防止超卖。
2. AOP版程序锁(更优雅的解耦)
在Controller层加锁可能破坏代码层次结构,使用AOP(面向切面编程)可以更优雅地在事务开始前加锁。
自定义注解:
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceLock {
String description() default "";
}
定义切面类:
@Slf4j
@Component
@Scope
@Aspect
@Order(1) // order越小越是最先执行,但更重要的是最先执行的最后结束
public class LockAspect {
// 使用ReentrantLock实现互斥锁
private static Lock lock = new ReentrantLock(true);
@Pointcut("@annotation(com.scorpios.secondkill.aop.ServiceLock)")
public void lockAspect() {
}
@Around("lockAspect()")
public Object around(ProceedingJoinPoint joinPoint) {
lock.lock();
Object obj = null;
try {
obj = joinPoint.proceed(); // 执行被注解修饰的业务方法
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException();
} finally{
lock.unlock();
}
return obj;
}
}
在业务方法上使用注解:
@Override
@ServiceLock // 通过AOP在事务前加锁
@Transactional(rollbackFor = Exception.class)
public Result startSecondKillByAop(long skgId, long userId) {
// ... 业务逻辑与之前相同,但无需手动加锁
try {
// 校验库存、扣减、创建订单等逻辑...
} catch (Exception e) {
throw new ScorpiosException("抛出业务异常");
}
return Result.ok(SecondKillStateEnum.SUCCESS);
}
这种方式将对锁的控制与业务逻辑完全解耦,代码更加清晰美观。
3. 数据库悲观锁(SELECT ... FOR UPDATE)
利用数据库自身的行级锁机制,在事务中锁定要更新的记录。
// Service方法
@Override
@Transactional(rollbackFor = Exception.class)
public Result startSecondKillByUpdate(long skgId, long userId) {
try {
// 使用FOR UPDATE查询,锁定该行数据直到事务结束
SecondKill secondKill = secondKillMapper.querySecondKillForUpdate(skgId);
Integer number = secondKill.getNumber();
if (number > 0) {
// ... 后续扣减库存、创建订单逻辑
}
} catch (Exception e) {
throw new ScorpiosException("抛出业务异常");
}
return Result.ok(SecondKillStateEnum.SUCCESS);
}
// Mapper接口
@Repository
public interface SecondKillMapper extends BaseMapper<SecondKill> {
@Select(value = "SELECT * FROM seckill WHERE seckill_id=#{skgId} FOR UPDATE")
SecondKill querySecondKillForUpdate(@Param("skgId") Long skgId);
}
注意:FOR UPDATE必须在事务中才生效,事务提交后锁才会释放。当并发量接近商品数量时,可能出现少数请求无法成功的情况(属正常竞争)。
4. 数据库悲观锁(UPDATE 原子操作)
通过一条原子性的UPDATE语句直接在数据库中完成库存校验与扣减,利用MySQL等数据库的写锁机制。
// Service方法
@Override
@Transactional(rollbackFor = Exception.class)
public Result startSecondKillByUpdateTwo(long skgId, long userId) {
try {
// 原子性扣减库存,number>0是条件
int result = secondKillMapper.updateSecondKillById(skgId);
if (result > 0) {
// 扣减成功,创建订单...
} else {
return Result.error(SecondKillStateEnum.END); // 库存不足
}
} catch (Exception e) {
throw new ScorpiosException("抛出业务异常");
}
return Result.ok(SecondKillStateEnum.SUCCESS);
}
// Mapper接口
@Update(value = "UPDATE seckill SET number=number-1 WHERE seckill_id=#{skgId} AND number > 0")
int updateSecondKillById(@Param("skgId") long skgId);
这种方式效率较高,锁的粒度在数据库层面控制。
5. 数据库乐观锁(Version版本号)
通过增加版本号字段,在更新时校验数据是否被其他事务修改过。
// Service方法
@Override
@Transactional(rollbackFor = Exception.class)
public Result startSecondKillByPesLock(long skgId, long userId, int number) {
try {
SecondKill kill = secondKillMapper.selectById(skgId);
if(kill.getNumber() >= number) {
// 基于版本号更新,版本号不一致则更新失败
int result = secondKillMapper.updateSecondKillByVersion(number, skgId, kill.getVersion());
if (result > 0) {
// 更新成功,创建订单...
} else {
return Result.error(SecondKillStateEnum.END); // 版本冲突或库存不足
}
}
} catch (Exception e) {
throw new ScorpiosException("抛出业务异常");
}
return Result.ok(SecondKillStateEnum.SUCCESS);
}
// Mapper接口
@Update(value = "UPDATE seckill SET number=number-#{number},version=version+1 WHERE seckill_id=#{skgId} AND version = #{version}")
int updateSecondKillByVersion(@Param("number") int number, @Param("skgId") long skgId, @Param("version")int version);
缺点:在高并发场景下,版本冲突失败率很高,容易出现大量“少卖”(实际成功订单数小于库存数),不推荐在秒杀场景单独使用。
6. 内存阻塞队列
将秒杀请求放入一个固定容量的内存阻塞队列,由单独的消费者线程顺序处理,实现请求的串行化,从而避免并发问题。这是常见的削峰填谷思路。
秒杀队列实现(单例):
public class SecondKillQueue {
static final int QUEUE_MAX_SIZE = 100;
static BlockingQueue<SuccessKilled> blockingQueue = new LinkedBlockingQueue<>(QUEUE_MAX_SIZE);
private SecondKillQueue(){};
private static class SingletonHolder{
private static SecondKillQueue queue = new SecondKillQueue();
}
public static SecondKillQueue getSkillQueue(){
return SingletonHolder.queue;
}
// 生产入队 (非阻塞)
public Boolean produce(SuccessKilled kill) {
return blockingQueue.offer(kill);
}
// 消费出队 (阻塞)
public SuccessKilled consume() throws InterruptedException {
return blockingQueue.take();
}
public int size() {
return blockingQueue.size();
}
}
队列消费者(随应用启动):
@Slf4j
@Component
public class TaskRunner implements ApplicationRunner{
@Autowired
private SecondKillService seckillService;
@Override
public void run(ApplicationArguments var){
new Thread(() -> {
log.info("秒杀队列消费者启动成功");
while(true){
try {
SuccessKilled kill = SecondKillQueue.getSkillQueue().consume();
if(kill != null){
// 调用业务方法处理秒杀,此处无需额外加锁
Result result = seckillService.startSecondKillByAop(kill.getSeckillId(), kill.getUserId());
log.info("用户:{} 秒杀结果:{}",kill.getUserId(),result.get("msg"));
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
Controller接收请求:
@ApiOperation(value="秒杀实现方式六——消息队列")
@PostMapping("/start/queue")
public Result startQueue(long skgId){
try {
log.info("开始秒杀方式六...");
final long userId = (int) (new Random().nextDouble() * (99999 - 10000 + 1)) + 10000;
SuccessKilled kill = new SuccessKilled();
kill.setSeckillId(skgId);
kill.setUserId(userId);
Boolean flag = SecondKillQueue.getSkillQueue().produce(kill);
if(flag){
log.info("用户:{} 请求已进入队列,等待处理", userId);
}else{
log.info("用户:{} 秒杀失败,队列已满", userId);
}
} catch (Exception e) {
e.printStackTrace();
}
return Result.ok();
}
重要提示:
- 消费线程中调用的业务方法不能抛出运行时异常,否则会导致消费线程终止。
- 队列长度需合理设置。若队列长度与商品数量一致,可能因“进队-出队”的时间差导致“少卖”。建议队列容量略大于商品数量。
- 此方案的本质是将高并发请求转为串行处理,适用于并发量特别高的场景,是处理
高并发问题的有效手段之一。
7. Disruptor高性能队列
Disruptor是一个高性能的有界内存队列,其性能远超BlockingQueue。实现思路与阻塞队列类似,但性能更高。
核心组件实现:
// 1. 事件定义
public class SecondKillEvent implements Serializable {
private long seckillId;
private long userId;
// getter/setter
}
// 2. 事件工厂
public class SecondKillEventFactory implements EventFactory<SecondKillEvent> {
@Override public SecondKillEvent newInstance() { return new SecondKillEvent(); }
}
// 3. 事件消费者(处理器)
@Slf4j
public class SecondKillEventConsumer implements EventHandler<SecondKillEvent> {
private SecondKillService secondKillService = (SecondKillService) SpringUtil.getBean("secondKillService");
@Override
public void onEvent(SecondKillEvent seckillEvent, long seq, boolean bool) {
Result result = secondKillService.startSecondKillByAop(seckillEvent.getSeckillId(), seckillEvent.getUserId());
log.info("Disruptor处理结果: 用户{} {}", seckillEvent.getUserId(), result.get("msg"));
}
}
// 4. 工具类(初始化Disruptor)
public class DisruptorUtil {
static Disruptor<SecondKillEvent> disruptor;
static{
SecondKillEventFactory factory = new SecondKillEventFactory();
int ringBufferSize = 1024; // 必须为2的幂
ThreadFactory threadFactory = runnable -> new Thread(runnable);
disruptor = new Disruptor<>(factory, ringBufferSize, threadFactory);
disruptor.handleEventsWith(new SecondKillEventConsumer());
disruptor.start();
}
public static void producer(SecondKillEvent kill){
RingBuffer<SecondKillEvent> ringBuffer = disruptor.getRingBuffer();
// 发布事件
ringBuffer.publishEvent((event, sequence, arg1, arg2) -> {
event.setSeckillId(arg1);
event.setUserId(arg2);
}, kill.getSeckillId(), kill.getUserId());
}
}
Controller调用:
@ApiOperation(value="秒杀实现方式七——Disruptor队列")
@PostMapping("/start/disruptor")
public Result startDisruptor(long skgId){
try {
final long userId = (int) (new Random().nextDouble() * (99999 - 10000 + 1)) + 10000;
SecondKillEvent kill = new SecondKillEvent();
kill.setSeckillId(skgId);
kill.setUserId(userId);
DisruptorUtil.producer(kill); // 发布到Disruptor队列
log.info("用户:{} 请求已发布至Disruptor队列", userId);
} catch (Exception e) {
e.printStackTrace();
}
return Result.ok();
}
Disruptor队列同样需要注意消费者线程异常处理和队列容量设置问题,其性能优于BlockingQueue,但实现相对复杂。
方案总结与对比
| 方式 |
核心思想 |
优点 |
缺点/注意事项 |
| 1&2. 程序锁改进 |
确保锁范围覆盖事务 |
理解直观,可控性强 |
集群环境下需用分布式锁 |
| 3. 悲观锁(FOR UPDATE) |
数据库行级锁 |
利用数据库机制,简单可靠 |
性能有损耗,可能死锁 |
| 4. 悲观锁(UPDATE) |
数据库原子操作 |
效率高,SQL层面解决 |
无法在扣减前进行复杂业务校验 |
| 5. 乐观锁(Version) |
数据版本控制 |
并发度高时冲突小 |
秒杀场景失败率高,易“少卖” |
| 6&7. 内存队列 |
请求串行化 |
削峰,避免数据库瞬间压力 |
存在延迟,需防消费者线程崩溃 |
选型建议:
- 对于中小型并发,方案4(UPDATE悲观锁) 是实现简单且可靠的选择。
- 若需要在扣减库存前执行复杂逻辑,方案2(AOP锁) 或 方案3(FOR UPDATE) 更合适。
- 面对极高并发(如万人抢购),应采用 队列(方案6/7) 进行削峰,配合方案2或3的锁机制处理队列中的请求,并考虑引入
Redis 等缓存中间件进一步优化。
 发表于 2025-12-17 00:10:19
|
查看: 185|
回复: 0
发表于 2025-12-17 00:10:19
|
查看: 185|
回复: 0
