一个系统的性能如何,很大程度上取决于缓存设计的优劣。面对本地缓存、Redis、CDN等多种技术,如何根据场景做出正确选择?本文将从原理到实战,深入剖析工作中最核心的六种缓存方案。
为什么缓存如此重要?
设想一个电商首页场景:每次打开都要从数据库查询轮播图、商品信息。若每秒有1万次访问,数据库将不堪重负。
// 无缓存时的查询
public Product getProductById(Long id) {
// 每次都直接查询数据库
return productDao.findById(id); // 每次都是慢速的磁盘IO
}
这就是典型的无缓存场景。磁盘IO速度远低于内存,高并发下将导致服务响应变慢甚至不可用。
缓存性能提升的核心公式如下:
系统性能 = (缓存命中率 × 缓存访问速度) + ((1 - 缓存命中率) × 后端访问速度)
其理论基础源自计算机科学的两大原理:
- 局部性原理:程序访问的数据在时间和空间上具有聚集性。
- 存储层次结构:不同存储介质速度差异巨大(内存比SSD快约100倍)。
从用户请求到数据返回,数据在系统中的流转与缓存层级如下图所示:
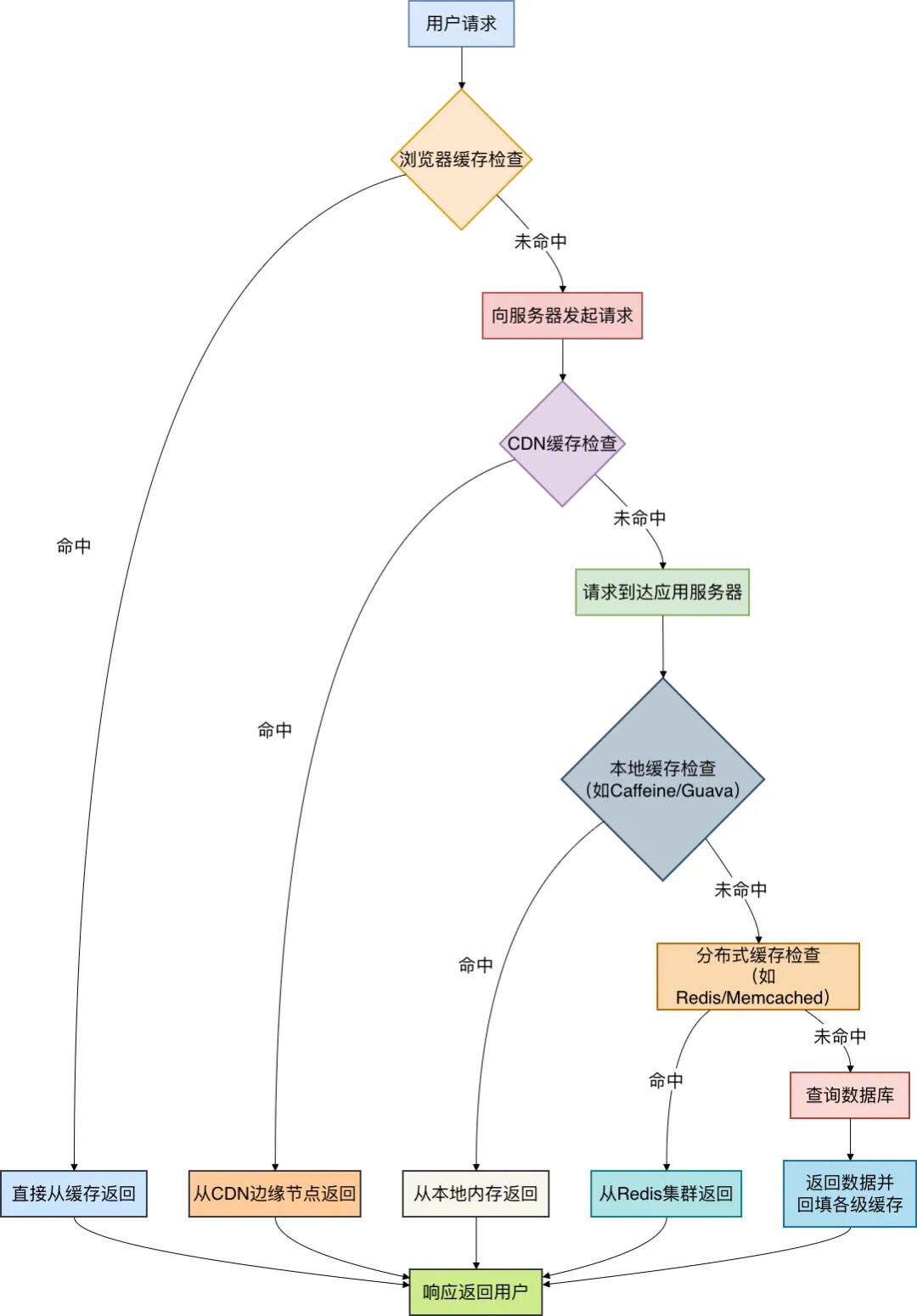
本地缓存:应用进程内的极速存储
本地缓存将数据直接存储在应用进程的JVM堆内存中。
核心特点
- 访问极快:内存直接操作,无任何网络开销。
- 实现简单:无需依赖外部服务。
- 数据隔离:每个应用实例拥有独立的缓存副本。
常用实现方案
1. Guava Cache
Google提供的强大本地缓存库,功能丰富。
// Guava Cache 示例
LoadingCache<Long, Product> productCache = CacheBuilder.newBuilder()
.maximumSize(10000) // 最大缓存项数
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.expireAfterAccess(5, TimeUnit.MINUTES) // 访问后5分钟过期
.recordStats() // 开启统计
.build(new CacheLoader<Long, Product>() {
@Override
public Product load(Long productId) {
// 缓存未命中时,自动加载数据
return productDao.findById(productId);
}
});
// 使用缓存
public Product getProduct(Long id) {
try {
return productCache.get(id);
} catch (ExecutionException e) {
throw new RuntimeException("加载产品失败", e);
}
}
2. Caffeine
作为Guava Cache的现代替代品,Caffeine在性能上表现更为优异,特别是在高并发读写场景下。
// Caffeine 示例
Cache<Long, Product> caffeineCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.refreshAfterWrite(1, TimeUnit.MINUTES) // 支持异步刷新
.recordStats()
.build(productId -> productDao.findById(productId));
// 异步获取
public CompletableFuture<Product> getProductAsync(Long id) {
return caffeineCache.get(id, productId ->
CompletableFuture.supplyAsync(() -> productDao.findById(productId)));
}
适用场景与注意事项
- 适用场景:数据量小(如10万条以内)、变化不频繁的只读数据,例如系统配置、静态字典、短期会话信息。
- 优点:访问速度极致、零网络延迟、集成简单。
- 缺点:在分布式环境下,各节点缓存数据可能不一致;受JVM堆内存限制;应用重启会导致缓存丢失。
关键点:本地缓存适用于对一致性要求不高的只读或弱一致性数据。在分布式系统中过度依赖本地缓存是常见的设计误区。
分布式缓存:Redis 的王者之道
当数据需要在多个服务实例间共享时,必须引入分布式缓存。Redis以其丰富的功能和卓越的性能成为该领域的首选。
核心优势与使用模式
// Spring Boot + Redis 示例
@Component
public class ProductCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String PRODUCT_KEY_PREFIX = "product:";
private static final Duration CACHE_TTL = Duration.ofMinutes(30);
// 标准的缓存查询模式
public Product getProduct(Long id) {
String key = PRODUCT_KEY_PREFIX + id;
// 1. 先查缓存
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 2. 缓存未命中,查数据库
product = productDao.findById(id);
if (product != null) {
// 3. 写入缓存
redisTemplate.opsForValue().set(key, product, CACHE_TTL);
}
return product;
}
}
丰富的数据结构应对多样场景
Redis远不止简单的KV存储,其数据结构是针对特定场景的高度抽象:
| 数据结构 |
典型应用场景 |
示例 |
| String |
缓存对象、计数器 |
SET user:1 '{"name":"张三"}' |
| Hash |
存储对象属性 |
HSET product:1001 name "手机" price 2999 |
| List |
消息队列、最新列表 |
LPUSH news:latest "新闻标题" |
| Sorted Set |
排行榜、延迟队列 |
ZADD leaderboard 95 “玩家A” |
| Bitmap |
用户签到、活跃统计 |
SETBIT sign:2023:10 1 1 |
集群架构选型
根据数据量、可用性和性能需求,可以选择不同的Redis集群模式:
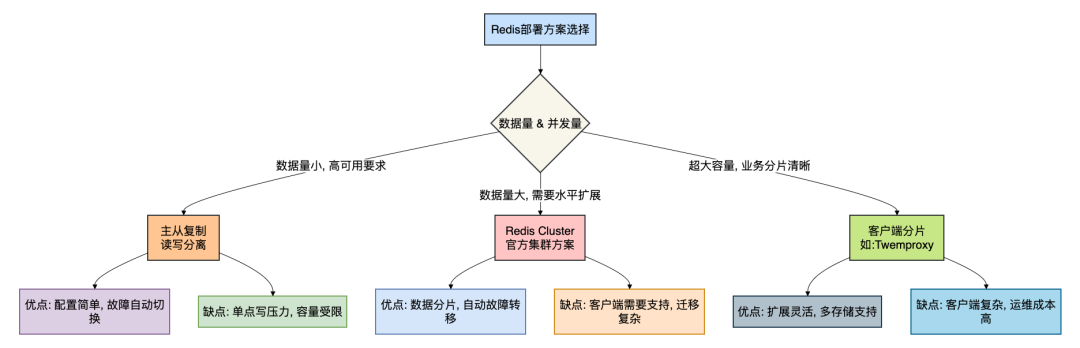
适用场景
- 分布式Session存储
- 热点数据缓存
- 排行榜与计数器
- 轻量级消息队列
- 分布式锁实现
设计建议:充分理解并利用Redis多样化的数据结构,能让系统设计更加简洁高效,避免“用瑞士军刀只开瓶盖”的浪费。
Memcached:纯粹高效的分布式缓存选择
在Redis流行之前,Memcached是分布式缓存的事实标准。其设计极度纯粹,专注于高性能的Key-Value缓存。
与Redis的核心差异对比
// Memcached 客户端使用示例 (XMemcached)
public class MemcachedService {
private MemcachedClient memcachedClient;
public Product getProduct(Long id) throws Exception {
String key = "product_" + id;
// 从Memcached获取
Product product = memcachedClient.get(key);
if (product != null) {
return product;
}
// 缓存未命中
product = productDao.findById(id);
if (product != null) {
// 存储到Memcached,过期时间30分钟
memcachedClient.set(key, 30 * 60, product);
}
return product;
}
}
特性对比一览:
| 特性 |
Redis |
Memcached |
| 数据结构 |
丰富(String, Hash, List等) |
简单(纯Key-Value) |
| 持久化 |
支持(RDB/AOF) |
不支持 |
| 线程模型 |
单线程(核心) |
多线程 |
| 内存管理 |
复杂策略,可持久化 |
纯内存,重启丢失 |
| 核心定位 |
缓存 + 多功能数据结构 |
纯内存缓存 |
何时考虑选择Memcached?
- 纯粹缓存场景:业务只需要简单的KV缓存,无需复杂数据结构。
- 超大Value存储:对于存储超大value(如超过1MB),Memcached的传统内存分配策略可能更稳定。
- 极端多线程读:在某些极端高并发、多线程读取的场景下,其多线程模型可能展现出理论优势。
CDN缓存:静态资源的全球加速网络
CDN(内容分发网络)通过在全球部署边缘节点,将静态资源缓存至离用户最近的位置,是从地理维度上“最近”的缓存。
工作原理与最佳实践
// 生成带版本号的CDN链接,避免缓存旧文件
public class CDNService {
private String cdnDomain = "https://cdn.yourcompany.com";
public String getCDNUrl(String relativePath) {
String version = getFileVersion(relativePath); // 获取文件哈希或版本号
return String.format("%s/%s?v=%s", cdnDomain, relativePath, version);
}
}
服务器可通过配置强制CDN和浏览器缓存静态资源:
# Nginx 缓存配置示例
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d; # 缓存一年
add_header Cache-Control "public, immutable";
# 带版本号的请求永久缓存
if ($query_string ~* "^v=\d+") {
expires max;
}
}
适用场景
- 图片、样式表、JavaScript文件等静态资源
- 软件安装包、应用更新包
- 音视频流媒体内容
- 面向全球用户访问的网站资源
浏览器缓存:面向终端用户的首道防线
合理利用浏览器缓存,可以显著减少重复的网络请求,直接提升用户体验并降低服务器负载。
HTTP缓存头策略详解
在Spring Boot中,可以方便地针对不同类型资源设置缓存策略:
@RestController
public class ResourceController {
@GetMapping("/static/{filename}")
public ResponseEntity<Resource> getStaticFile(@PathVariable String filename) {
Resource resource = loadResource(filename);
return ResponseEntity.ok()
.cacheControl(CacheControl.maxAge(7, TimeUnit.DAYS).cachePublic()) // 强缓存7天
.eTag(computeETag(resource)) // 设置ETag用于协商缓存
.lastModified(resource.lastModified())
.body(resource);
}
@GetMapping("/dynamic/data")
public ResponseEntity<Object> getDynamicData() {
Object data = getData();
// 动态数据设置较短的缓存时间
return ResponseEntity.ok()
.cacheControl(CacheControl.maxAge(30, TimeUnit.SECONDS))
.body(data);
}
}
浏览器缓存类型

最佳实践原则
- 静态资源:使用
Cache-Control: public, max-age=31536000(一年),并通过文件名哈希(如main.a1b2c3.js)或查询参数版本号来管理更新。
- 动态内容:根据数据变化频率设置合理的
max-age(如几秒到几分钟),或使用no-cache配合ETag进行协商缓存。
- API响应:对列表、详情等接口适当使用
ETag或Last-Modified头。
数据库缓存:优化查询的最后一道屏障
除了应用层缓存,数据库自身的缓存机制也至关重要,尤其是MySQL的InnoDB缓冲池(Buffer Pool)。
InnoDB缓冲池详解
缓冲池是InnoDB引擎的核心组件,用于缓存表数据和索引页。其命中率直接决定了磁盘IO频率。
-- 查看缓冲池状态信息
SHOW ENGINE INNODB STATUS;
-- 监控缓冲池命中率(应接近100%)
-- 命中率 = (1 - (innodb_buffer_pool_reads / innodb_buffer_pool_read_requests)) * 100%
数据库缓存优化要点
- 合理设置缓冲池大小:通常配置为系统可用内存的50%-70%。
- 优化查询与索引:避免全表扫描,让查询尽可能通过索引在缓冲池中完成。
- 预热缓存:服务启动后,可主动运行热点查询,将数据页加载到缓冲池。
- 持续监控:关注缓冲池命中率、脏页比例等关键指标。
系统观:数据库缓存是整个缓存体系的基石。即使应用层缓存命中率很高,优化数据库缓存也能让系统在缓存失效或穿透时更加稳健。
综合对比与架构选型指南
不同缓存技术有其鲜明的特点和适用场景,选择时需要综合考量:
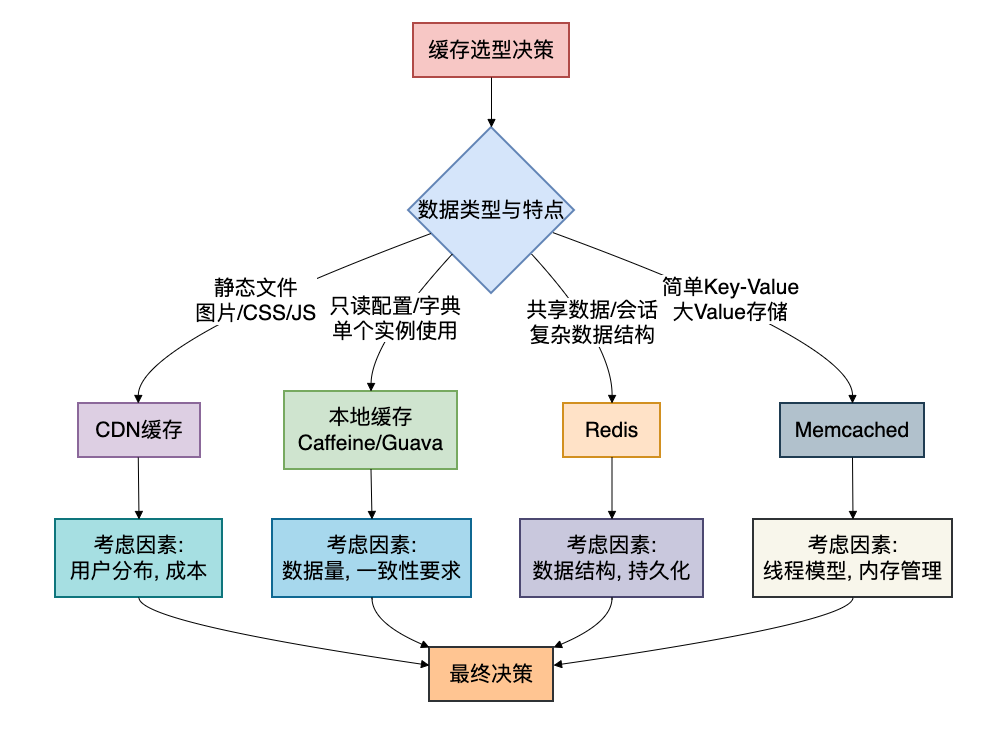
实战中的多级缓存架构
在高并发系统中,通常采用多级缓存策略,组合不同缓存技术的优势。
// 本地缓存(Caffeine) + Redis 二级缓存实战
@Component
public class MultiLevelCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 一级:本地缓存 (短暂,防热点)
private Cache<Long, Product> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(30, TimeUnit.SECONDS)
.build();
private static final Duration REDIS_TTL = Duration.ofMinutes(10);
public Product getProductWithMultiCache(Long id) {
// 1. 查本地缓存
Product product = localCache.getIfPresent(id);
if (product != null) {
return product;
}
// 2. 查Redis
String redisKey = "product:" + id;
product = (Product) redisTemplate.opsForValue().get(redisKey);
if (product != null) {
// 回填本地缓存
localCache.put(id, product);
return product;
}
// 3. 查数据库
product = productDao.findById(id);
if (product != null) {
// 异步或同步写入两级缓存
redisTemplate.opsForValue().set(redisKey, product, REDIS_TTL);
localCache.put(id, product);
}
return product;
}
}
缓存经典问题与解决方案
1. 缓存穿透
问题:大量请求查询数据库中根本不存在的数据,导致请求穿透缓存,直接冲击数据库。
解决方案:缓存空值(Null Value)。
public Product getProductSafe(Long id) {
String key = "product:" + id;
String nullKey = "product:null:" + id; // 空值标记key
// 检查是否已标记为空值
if (Boolean.TRUE.equals(redisTemplate.hasKey(nullKey))) {
return null;
}
// ... 正常查询逻辑 ...
if (product == null) {
// 数据库不存在,缓存一个短时间的空值标记
redisTemplate.opsForValue().set(nullKey, "", Duration.ofMinutes(5));
return null;
}
}
2. 缓存雪崩
问题:大量缓存键在同一时间点过期,导致所有请求瞬间涌向数据库。
解决方案:为缓存过期时间添加随机值。
private Duration getRandomTTL() {
long baseMinutes = 30; // 基础30分钟
long randomMinutes = ThreadLocalRandom.current().nextLong(0, 10); // 随机0-10分钟
return Duration.ofMinutes(baseMinutes + randomMinutes);
}
3. 缓存击穿
问题:某个热点key过期瞬间,大量并发请求同时尝试重建缓存,导致数据库压力骤增。
解决方案:使用分布式互斥锁(Mutex Lock),保证只有一个线程去查询数据库并重建缓存。
public Product getProductWithLock(Long id) {
String key = "product:" + id;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product == null) {
String lockKey = "lock:product:" + id;
// 尝试获取分布式锁
Boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", Duration.ofSeconds(10));
if (Boolean.TRUE.equals(locked)) {
try {
// 双重检查,防止其他线程已重建缓存
product = (Product) redisTemplate.opsForValue().get(key);
if (product == null) {
product = productDao.findById(id);
if (product != null) {
redisTemplate.opsForValue().set(key, product, Duration.ofMinutes(30));
}
}
} finally {
// 释放锁
redisTemplate.delete(lockKey);
}
} else {
// 未获得到锁,短暂等待后重试
try { Thread.sleep(50); } catch (InterruptedException e) { /* 处理中断 */ }
return getProductWithLock(id); // 递归重试
}
}
return product;
}
总结
缓存是提升系统性能的核心技术之一。本文系统梳理了从本地到分布式,从前端到数据库的六种核心缓存:
- 本地缓存(如Caffeine):适用于进程内、低频变化的只读数据。
- 分布式缓存(Redis):功能全面,是共享缓存场景的中坚力量。
- Memcached:设计纯粹,在特定高性能KV场景下仍有价值。
- CDN缓存:加速全球范围内的静态资源分发。
- 浏览器缓存:最前端的优化,直接提升用户体验。
- 数据库缓存(如InnoDB Buffer Pool):优化数据库操作的底层保障。
缓存设计的核心原则在于平衡:在合适的层级(分级缓存)、以合适的粒度、采用合适的更新策略。同时,必须建立完善的监控体系,关注命中率、延迟等关键指标,并针对穿透、雪崩、击穿等经典问题设计防御方案。缓存是工具箱中的利器,而非银弹,其成功运用依赖于对业务场景和缓存特性的深刻理解。
 发表于 2025-12-17 02:40:06
|
查看: 232|
回复: 0
发表于 2025-12-17 02:40:06
|
查看: 232|
回复: 0
