Redis作为现代分布式系统的核心组件,其卓越的性能使其能够在高并发场景下稳定支撑百万级别的QPS(每秒查询率)。实现这一目标并非偶然,而是源于其精心的架构设计与多层面的性能优化。下文将详细解析其中关键的四大技术支撑点。
1. 纯内存操作
Redis性能卓越的首要基础是其纯内存操作模型。所有数据的读写均在内存中完成,彻底规避了传统磁盘数据库因I/O寻道和旋转延迟带来的性能瓶颈。这决定了其单次操作的延迟极低,通常在微秒级别,从而为极高的请求吞吐量奠定了硬件级的优势基础。

2. 多实例分片集群
单个Redis实例的性能存在物理上限。为了突破瓶颈,实现横向扩展,必须采用集群(Cluster) 架构。通过将整个数据集按照规则分片(Sharding)到多个Redis节点上,请求被分散到不同实例并行处理,这显著降低了单个节点的压力,并线性提升了系统的整体吞吐能力。例如,在一个设计良好的系统中,若单实例可承载10万QPS,那么一个由10个主节点组成的集群理论上即可满足百万QPS的需求。
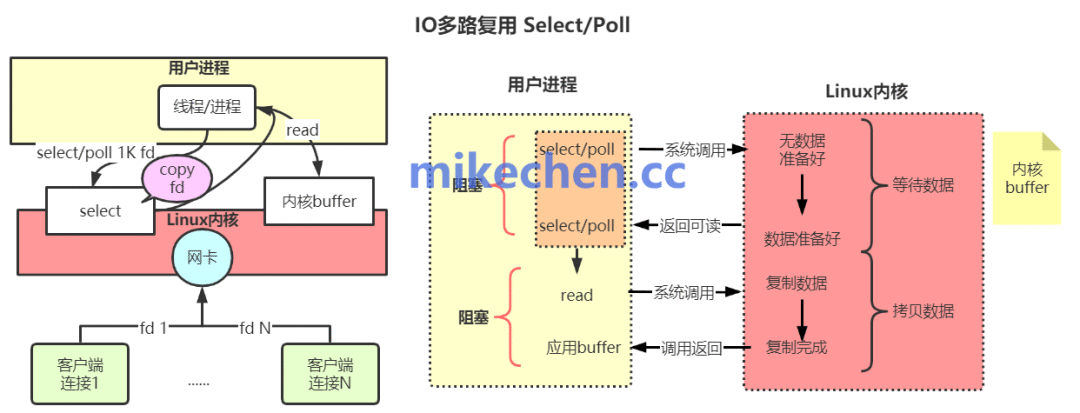
3. 高效的I/O多路复用机制
Redis的核心网络模型采用了I/O多路复用技术,结合单线程事件循环。在Linux系统下,它使用高效的epoll机制,使得单个线程能够同时监视和管理成千上万的网络连接。这种事件驱动的非阻塞I/O模型,避免了多线程环境下频繁的上下文切换和锁竞争开销,在保持系统并发处理能力的同时,极大地提升了资源利用效率和连接处理性能。
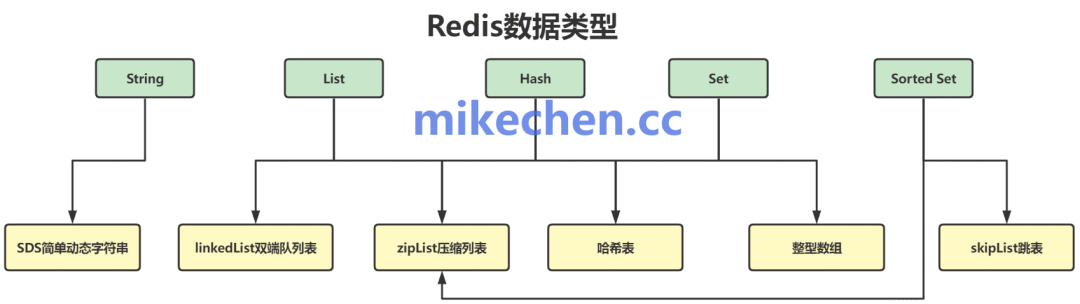
4. 精心优化的数据结构
除了底层I/O模型的优势,Redis提供的多种高级数据结构也是其高性能的关键。这些数据结构,包括字符串(String)、哈希(Hash)、列表(List)、集合(Set)和有序集合(Sorted Set),都经过了极致的性能与内存优化。例如,用于存储普通键值对的结构,其底层是高效的哈希表实现,确保了GET和SET操作的时间复杂度平均为O(1),这使得Redis非常适合作为高性能的缓存和数据库中间件使用。
综上所述,Redis通过纯内存存储、可扩展的集群架构、高效的I/O模型以及精心设计的数据结构,共同构筑了其支撑百万级QPS高并发访问能力的坚实基石。理解这些核心原理,是进行系统架构设计与性能调优的重要前提。 |  发表于 2025-12-17 23:56:50
|
查看: 164|
回复: 0
发表于 2025-12-17 23:56:50
|
查看: 164|
回复: 0
