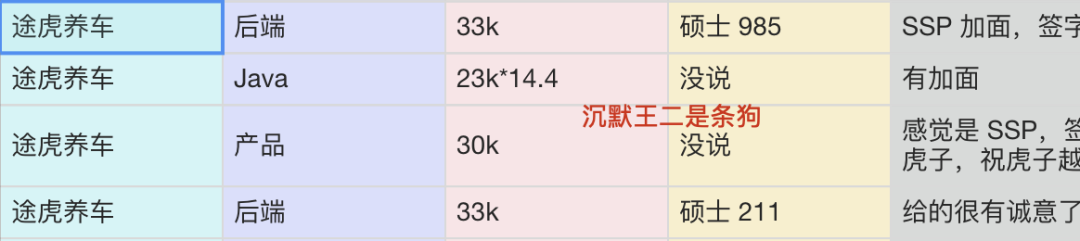
途虎养车在今年校园招聘中提供的薪资水平表现出色,已可媲美部分一线互联网公司。一些拿到途虎offer的同学甚至表示,因秋招签约过早而感到后悔,希望能重新选择加入途虎。
根据一份Java 面试指南专栏收录的途虎26届校招薪资信息来看,待遇确实颇具吸引力:
- 硕士985,后端岗,薪资33k,有SSP加面,可谈签字费,base上海;
- Java岗,薪资23k,有加面,base武汉;
- 产品岗,薪资30k(疑似SSP),签字费2+1万,base上海;
- 硕士211,后端岗,薪资33k,base上海。
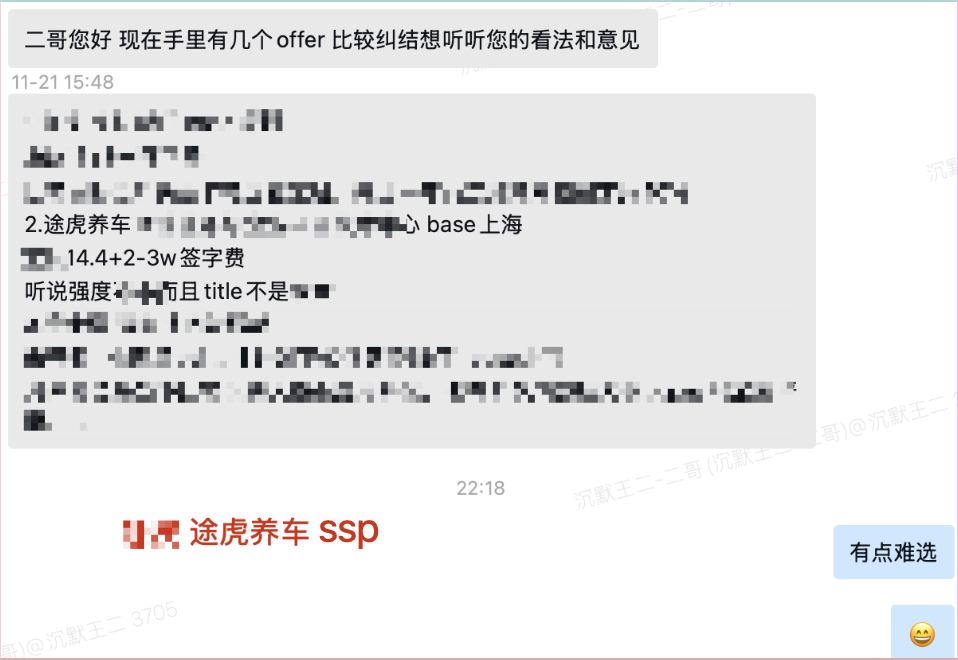
另一位同学的分享也佐证了这一点:其拿到了途虎养车的SSP offer,在多个offer比较中,途虎给出了最高的base薪资。当然,该同学对途虎的平台知名度和工作强度仍抱有一些疑虑。
这种考虑是合理的,途虎并非传统意义上的互联网大厂。对于初入职场的同学而言,平台的选择确实重要,尤其是计划在未来几年跳槽的。
然而,如果没有更理想平台的offer,选择途虎也是一个非常不错的选择。据称其用户规模已达1.4亿。途虎养车的平台负责人曾表示:“途虎每年在产研上的投入是亿万量级的,这种在数据化和人才方面持续、大规模的投入,在汽车后市场行业是独一无二的。”
那么,途虎既然能提供接近一线的薪资,其面试究竟看重什么呢?
根据一位成功拿到途虎养车offer的同学反馈,面试官对其简历上的 派聪明 RAG 项目 表现出浓厚的兴趣。面试过程中,问题基本都围绕这个项目展开。

由此可见,AI技术应用能力已成为当前求职市场的重要考察点。
以下为该RAG项目在面试中可能被问到的一些典型问题及详细回答,供大家参考。
原贴地址:https://t.zsxq.com/l6xGP

技术问答解析
问:如何处理复杂文档(如扫描件、手写文件)及表格数据?
答:我们采用了分层处理策略来应对不同类型的文档:
-
通用文档解析:使用Apache Tika的AutoDetectParser自动识别并解析超过1000种格式的文档,包括PDF、Word、PPT等。这为我们的Java后端处理提供了强大的基础支持。
// PaiSmart 使用 Tika AutoDetectParser 自动检测文件类型
AutoDetectParser parser = new AutoDetectParser();
parser.parse(bufferedStream, handler, metadata, context);
-
扫描件/手写文档OCR:
- 对于集成的需求,Tika本身可以通过
tika-parsers-standard-package依赖引入Tesseract OCR。
- 在Java技术栈中,我们选用Tess4J(Tesseract OCR的Java封装)进行高性能的印刷体识别。对于更高精度的需求,可以接入百度、腾讯等商业OCR API或开源的PaddleOCR。
- 解析结果会设置置信度阈值进行过滤,低置信度内容会标记为待人工审核。
- 性能优化亮点:OCR是CPU密集型操作。为避免阻塞主线程,我们将其异步化。
ParseService识别出需OCR的文件后,会发布一条Kafka消息,由独立服务消费处理,完成后再将结果写回数据库和Elasticsearch,确保系统响应速度。
-
表格数据处理:
- Excel、CSV等格式可由Tika直接解析为文本。Word/PDF中的嵌入表格,Tika会尽力保留结构。
- 我们将表格转换为Markdown或JSON格式以保留语义,并添加元信息注释(如“此表格包含3列:姓名、年龄、城市”),因为LLM对Markdown格式理解良好。
- 针对PDF中的复杂表格,引入了Tabula-Java进行专业提取。
- 关键原则:表格作为一个完整的语义单元,不应被随意分割。
- 索引策略亮点:对重要复杂表格,采用【摘要+原文】的双路径索引。先用LLM生成自然语言摘要(如:‘这是一个关于2025年各产品线销售额的表格,其中A产品线最高’),然后将摘要和Markdown原文一同进行向量化索引。这样无论是模糊查询还是精确查询都能有效命中。
// FileTypeValidationService.java
"xls", "xlsx", // Microsoft Excel表格
"csv", // CSV文件
"ods", // OpenDocument电子表格
"numbers", // Apple Numbers表格
-
数据量与性能测试:
- 向量存储采用Elasticsearch 8.10,使用
dense_vector类型,单索引支持百万级文档。
- 向量维度为2048(阿里云Embedding服务),使用余弦相似度计算。
- 文本分块大小为512字符,一个100页PDF约生成500-1000个chunk。
{
"vector": {
"type": "dense_vector",
"dims": 2048,
"index": true,
"similarity": "cosine"
}
}
- 性能数据:单文件最大测试过50MB PDF(约500页),解析至向量化全流程约1-2分钟。知识库总量测试超10万chunk,混合搜索响应时间<200ms。
- 其他优化措施:使用Kafka异步解耦;流式解析避免大文件OOM;采用HanLP保证中文分词语义完整;混合搜索结合KNN向量召回与BM25文本重排以保证精度。
途虎养车敢于提供具有竞争力的薪资,意味着其对人才技术深度的期待也相应提高。求职的核心无外乎八股文、项目经验、算法、简历和场景题。在当前的AI浪潮下,拥有一个像RAG这样的人工智能实践项目,无疑能显著增强你的竞争力。
机会总是留给有准备的人。
|  发表于 2025-12-18 00:02:13
|
查看: 186|
回复: 0
发表于 2025-12-18 00:02:13
|
查看: 186|
回复: 0
