近年来,大语言模型在需要复杂推理的任务上表现突飞猛进,很大程度上归功于其逐步思考能力的增强。诸如思维链提示等方法,通过引导模型拆解问题为一系列中间步骤,显著提升了其在数学、逻辑等任务上的准确性与可靠性。
然而,这种“一步一思考”的模式也带来了显著挑战。其中最突出的便是推理开销问题:模型倾向于对所有问题都生成冗长的思考过程,导致响应延迟和计算成本大幅增加。这种不考虑问题难度而“过度思考”的现象,在追求高性价比部署的真实应用场景中,成为了一个亟待解决的瓶颈。
针对这一问题,哔哩哔哩Index-llm Team提出了SABER(Switchable and Balanced Training for Efficient LLM Reasoning)框架。这是一个基于强化学习的训练范式,旨在让大语言模型习得一种可控、可切换、且受预设计算预算约束的推理能力。
SABER核心方法论
1. 动态预算划分与分级训练
SABER的核心思想是为不同难度的训练样本分配不同的“思考预算”。具体做法是:首先使用基座模型处理每个训练样本,并统计其生成思考内容(位于 <think> 和 </think> 标签之间)所需的token数量。根据统计分布,将样本划分为三个难度等级,并赋予相应的推理长度上限:
- 简单:128 token
- 中等:4096 token
- 困难:16384 token
这种分级策略既确保了模型能在大量样本上学习到长度约束,又能尊重难题本身的复杂性需求,使训练过程更加稳定。系统提示词会明确告知模型当前样本的推理预算上限。

图1:SABER框架中四种推理模式(NoThink, FastThink, CoreThink, DeepThink)对应的系统提示词。
2. 训练稳定性控制
为了防止模型在训练初期因严格的预算约束而产生不稳定行为,SABER引入了两项关键机制:
- 基于准确率的样本过滤:仅对基座模型能够正确回答的样本(约占60%)施加预算降级惩罚,对模型答错的样本则保持宽松约束,这有效降低了早期训练的不稳定性。
- 推理长度比例约束:为了避免模型为规避惩罚而生成过短的无效思考(即“奖励破解”),SABER要求模型生成的思考长度不能低于基座模型原始长度的某个比例。
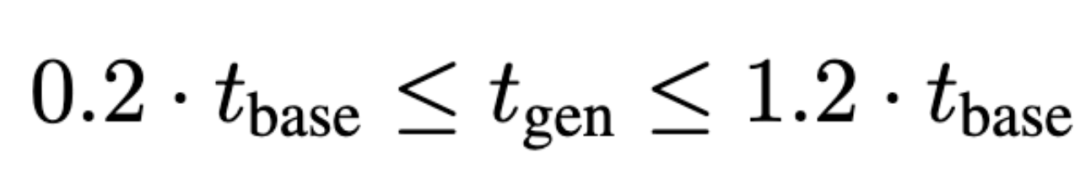
3. 支持无思考模式
为了满足用户希望直接获得答案而无须推理过程的需求,SABER在训练数据中显式加入了“NoThink”样本。这些样本使用极短的占位思考块,引导模型学习跳过推理直接给出答案。这一设计显著增强了模型在关闭显式推理模式下的输出稳定性。
4. 基于GRPO的直接强化学习优化
与许多需要监督微调预热的方案不同,SABER的设计与模型原始行为高度一致,因此可以直接使用GRPO进行强化学习优化,简化了训练流程。其奖励函数由四部分组成:
- 格式奖励:确保输出遵循
<think>...推理...</think> 答案 的结构化格式。
- 答案奖励:数学任务检查最终答案,代码任务则通过执行测试用例来判定正确性。
- 长度惩罚:对超过预算的思考内容进行扣分。
- 比例惩罚:对思考长度严重偏离基座模型原始长度的行为进行扣分。
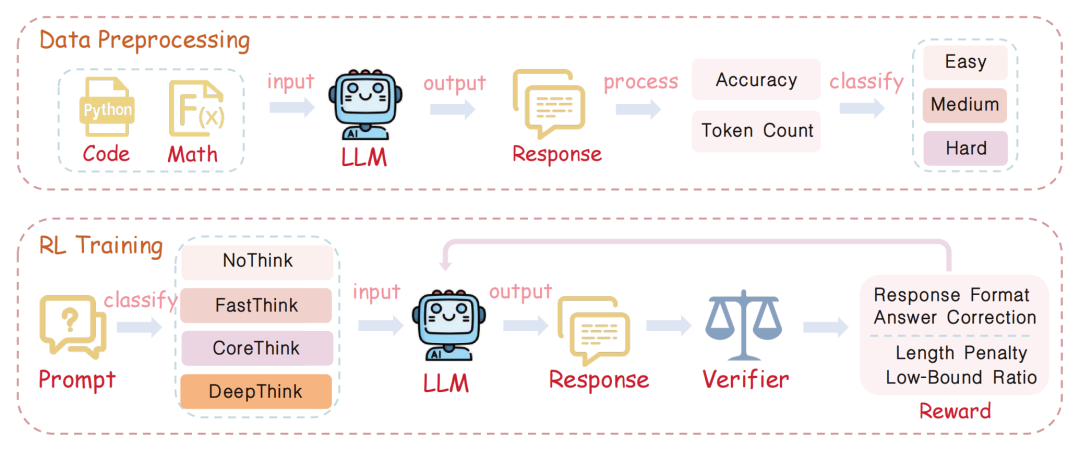
图2:SABER框架概览。上半部分为数据预处理与预算分级,下半部分展示了强化学习训练流程。
实验验证与结果分析
研究团队在数学推理(MATH, GSM8K)、代码生成(MBPP)及逻辑推理(LiveBench-Reasoning)等任务上对SABER进行了系统评估。
1. 核心性能优势
在1.5B参数模型上,SABER支持的所有推理模式均显著优于原始基座模型:
- FastThink模式在保持甚至略微提升准确率的同时,将平均推理长度压缩了70%以上,实现了极高的推理效率。
- CoreThink模式在精简推理的基础上,进一步提升了整体任务准确率。
- DeepThink模式在维持较高推理完整性的同时,也实现了可观的长度压缩,并取得了最佳的准确率表现。
与同类方法如L1约束和SelfBudgeter相比,SABER在仅使用2K训练数据(对比30K)的情况下,取得了更好的准确率与效率权衡。
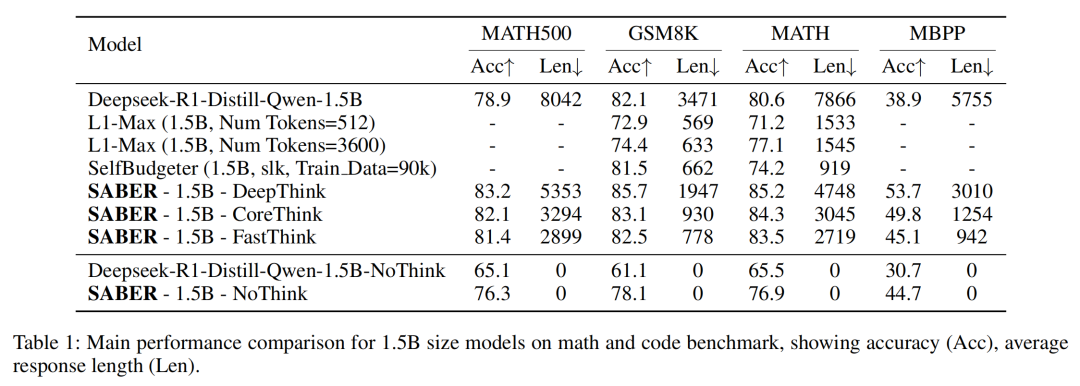
图3:SABER在1.5B模型规模下,于数学和代码任务上的性能表现。
2. 跨规模与跨领域泛化能力
将SABER的训练范式应用到7B参数模型时,其优势依然保持:
- FastThink模式能减少超过80%的推理长度。
- DeepThink模式同样实现了压缩与精度的双重提升。
更重要的是,尽管训练数据仅包含数学和代码样本,但习得的推理模式切换能力成功迁移到了全新的逻辑推理任务上,展现了良好的领域泛化性。
3. 消融实验验证设计必要性
通过对SABER各核心组件进行逐项移除的消融实验,证实了其设计的必要性:
- 移除预算降级:会严重损害模型学习短推理模式的能力。
- 移除NoThink数据:导致无推理模式性能急剧下降。
- 移除准确率过滤:引入噪声,使训练过程不稳定。
4. 不同推理模式的行为差异
案例分析清晰地展示了不同模式的行为特点。面对同一道数学题:
- FastThink:仅列出最关键的解题步骤,极为简洁。
- CoreThink:在关键步骤中加入额外的解释和局部反思,推理更完整。
- DeepThink:在得出答案后,会进行自我校验和解题总结,展现出更深层、更具反思性的推理风格。

图4:SABER的FastThink, CoreThink, DeepThink三种模式在解答同一数学问题时的推理内容对比。
总结
SABER提出了一种创新的模式切换混合思考训练范式。它通过结构化的奖励设计、离散化的推理模式以及动态的预算分配策略,使大语言模型能够在无需额外监督微调的情况下,学习高效、可控的推理行为。实验表明,SABER在多项复杂任务上均能实现显著的效率提升与性能优化,其模式切换机制具备良好的跨模型规模和跨任务领域的泛化能力,为构建高性价比、可控的大模型推理系统提供了一个颇具前景的解决方案。
论文信息:该研究已被AAAI 2026接收,论文及更多细节可访问:https://arxiv.org/abs/2508.10026
 发表于 2025-12-19 18:50:57
|
查看: 248|
回复: 0
发表于 2025-12-19 18:50:57
|
查看: 248|
回复: 0
