本文详细探讨了多线程的10大核心雷区及其解决方案,涵盖从基础概念到生产环境调优的全面解析。
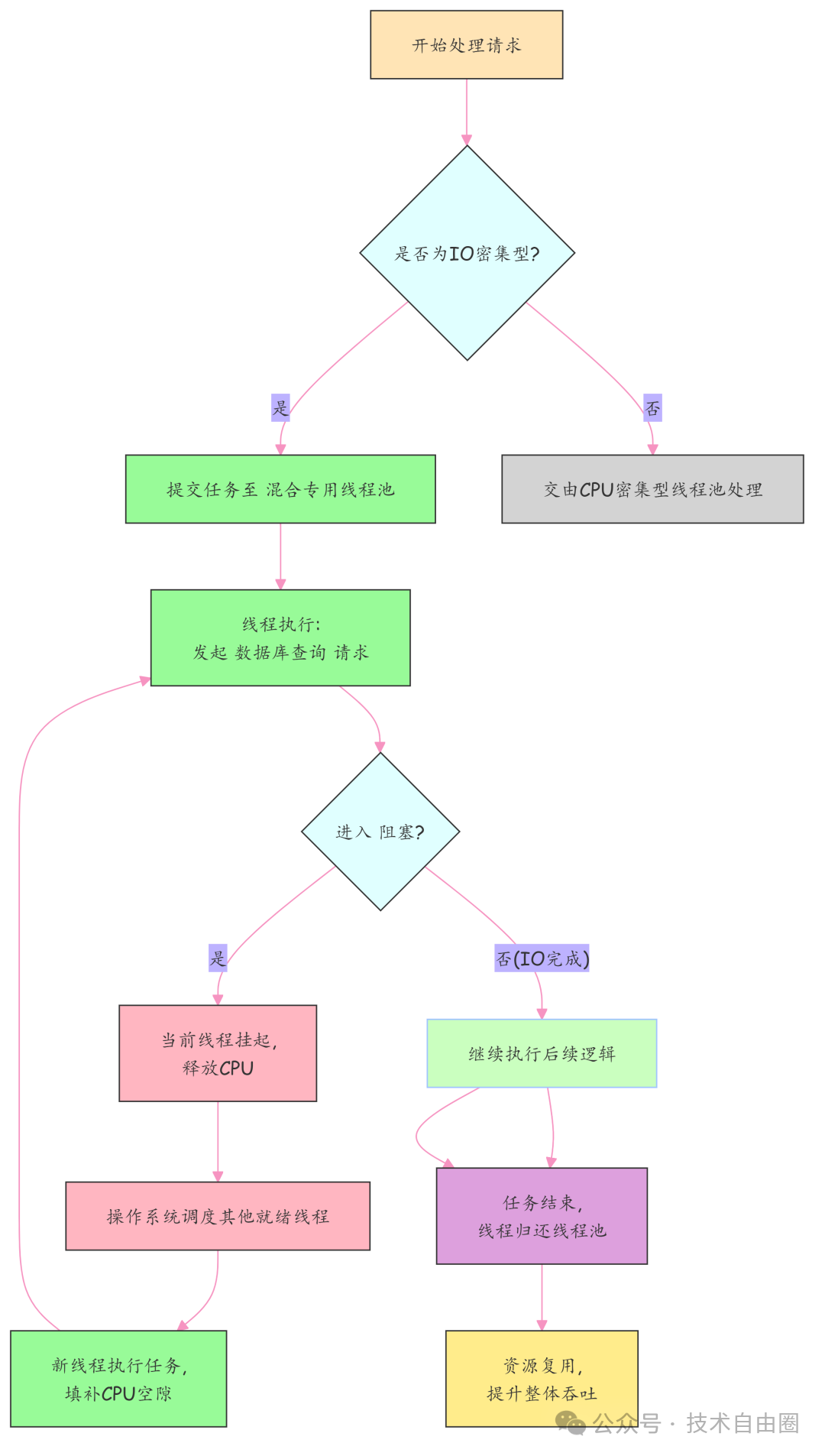
雷区一:单线程IO等待导致CPU资源浪费
核心痛点:
单线程在执行IO操作时会陷入阻塞等待,导致CPU资源长时间空转,无法处理其他任务。这种资源浪费在现代多核服务器上尤为严重。
解决方案:
通过多线程并发模型,利用线程间上下文切换机制,在等待IO时调度其他就绪线程使用CPU,实现时间片高效复用。
技术原理:上下文切换与CPU复用
当线程A发起IO请求进入阻塞状态时,操作系统立即将CPU控制权交给线程B执行其他任务。虽然切换本身有开销(微秒级),但相比毫秒级的IO等待时间可忽略不计。
实践建议:IO密集型任务线程池配置
// 示例:针对IO密集型任务的线程池配置
int coreCount = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor ioExecutor = new ThreadPoolExecutor(
coreCount * 2, // 核心线程数:通常设为CPU核心数的2倍以上
50, // 最大线程数:允许突发扩容
60L, TimeUnit.SECONDS, // 空闲线程存活时间
new LinkedBlockingQueue<>(1000) // 有界任务队列
);
配置依据:
- 线程数大于CPU核心数:因为线程大部分时间在等待IO,真正占用CPU时间短
- 推荐公式:最优线程数 ≈ CPU核心数 × (1 + 平均等待时间/平均计算时间)
雷区二:单线程无法利用多核算力
核心痛点:
多核服务器仅使用单线程执行,造成"一核满载,多核闲置"的资源浪费,严重制约系统吞吐能力。
解决方案:
将计算任务拆分为子任务,通过并行框架调度到不同CPU核心同时执行。
并行计算实践:使用parallelStream
List<Order> orders = getAllSeckillOrders();
// 启用并行流,自动利用多核处理
orders.parallelStream().forEach(order -> {
complexFinancialCalculate(order);
});
工具选型指南:
- 计算密集型:Stream.parallel() / ForkJoinPool
- IO密集型/混合型:ThreadPoolExecutor
- 异步编排:CompletableFuture
雷区三:多线程不一定更快
关键洞察:
盲目使用多线程可能因上下文切换开销和资源竞争而降低性能。
性能对比场景:
| 场景类型 |
多线程效果 |
原因分析 |
| CPU密集型+线程数>核心数 |
更慢 |
频繁上下文切换,CPU缓存失效 |
| 任务粒度过小 |
更慢 |
调度成本高于任务本身 |
| 锁竞争激烈 |
更慢 |
线程多数时间阻塞等待 |
| IO密集型任务 |
更快 |
填充IO等待间隙,提升CPU利用率 |
避坑指南:
- CPU密集型任务:线程数 ≈ CPU核心数
- 使用线程池复用线程,避免频繁创建销毁
- 减少锁竞争:使用ConcurrentHashMap、AtomicInteger等无锁结构
- 监控指标:上下文切换次数、CPU利用率、锁等待时间
雷区四:手动创建线程的风险
核心风险:
每次new Thread()都会创建操作系统级线程,消耗约1MB栈内存。高并发下线程爆炸式增长,易导致内存耗尽和服务崩溃。
正确实践:自定义ThreadPoolExecutor
ThreadPoolExecutor executor = new ThreadPoolExecutor(
4, // 核心线程数
16, // 最大线程数
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 有界队列
new ThreadFactoryBuilder().setNameFormat("order-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
️重要警告:避免使用Executors.newFixedThreadPool()等工具类,其内部使用无界队列,存在内存耗尽风险。
雷区五:线程池参数科学配置
1. 最大线程数计算
任务类型识别与配置:
2. 队列容量计算
黄金公式:
队列容量 = (峰值QPS - 线程池每秒处理能力) * 最大容忍延迟
实战案例:支付回调优化
- 场景:4核CPU,任务耗时300ms(等待280ms,计算20ms)
- 计算:W/C=14 → 理论线程数=60
- 峰值QPS=400,线程池处理能力=200任务/秒
- 容忍延迟1秒 → 队列容量=200
- 最终配置:core=60, max=60, queue=200
雷区六:任务类型与资源配置错配
典型错误配置及后果:
| 错误类型 |
配置示例 |
后果表现 |
| CPU密集型线程过多 |
8核设32线程 |
上下文切换开销大,sys% CPU高达40% |
| IO密集型线程不足 |
核心线程设4 |
CPU利用率<30%,请求大量积压 |
| 使用无界队列 |
LinkedBlockingQueue() |
内存持续增长,最终OOM |
三步精准配置法:
- 定性识别:准确判断任务类型(CPU/IO/混合型)
- 定量计算:使用公式
N_cpu × (1 + W/C)计算理论最优值
- 防爆控制:有界队列+合适拒绝策略(推荐CallerRunsPolicy)
雷区七:打破"2N"线程数迷思
核心观点:
Netty的"2N"规则(线程数=2×CPU核心数)仅适用于特定IO模型(W≈C),不能套用于所有业务场景。
科学计算方法:
- 测量真实等待时间W和计算时间C
- 代入公式:线程数 = CPU核心数 × (1 + W/C)
- 工程折衷:考虑内存、句柄、上下文切换等资源限制
示例:慢接口场景
- 总耗时T=2000ms,计算C=10ms → W=1990ms
- W/C=199 → 理论线程数≈1600(8核机器)
- 折衷配置:core=200, max=400,配合有界队列
雷区八:Eager模式线程池优化
标准线程池痛点:
采用"先入队后扩容"策略,突发流量下任务排队等待,造成响应延迟飙升。
Eager模式核心:优先创建新线程(至maxPoolSize),线程打满后才将任务入队。
实现原理:自定义队列重写offer()方法
public class TaskQueue<R extends Runnable> extends LinkedBlockingQueue<Runnable> {
private EagerThreadPoolExecutor executor;
@Override
public boolean offer(Runnable runnable) {
// 核心逻辑:当前线程数 < 最大线程数时返回false
// 迫使ThreadPoolExecutor创建新线程
if (executor.getPoolSize() < executor.getMaximumPoolSize()) {
return false;
}
return super.offer(runnable);
}
}
适用场景:
- RPC服务提供方
- API网关/微服务入口
- 对P99/P999延迟敏感的在线业务
雷区九:线程池溢出防护体系
三层防御机制:
-
有界队列防内存爆炸
new ArrayBlockingQueue<>(2000) // 明确容量上限
-
CallerRunsPolicy实现反向背压
-
前置限流拦截无效请求
- 网关层:Nginx/Spring Cloud Gateway限流
- 应用层:Sentinel熔断规则
- 用户侧:排队提示、令牌桶平滑流量
| 生产环境配置对比: |
配置项 |
错误配置 |
正确配置 |
结果差异 |
| 队列类型 |
无界队列 |
ArrayBlockingQueue(2000) |
避免OOM |
| 拒绝策略 |
AbortPolicy |
CallerRunsPolicy |
自动降速 |
| 前置防护 |
无 |
Sentinel限流(QPS=8000) |
平稳过峰 |
雷区十:多线程"假死"排查指南
三步定位法:
第一步:获取线程快照
# 使用jstack
jstack <pid> > thread_dump.txt
# 使用Arthas(生产推荐)
thread --all # 查看所有线程状态
thread --state BLOCKED # 筛选阻塞线程
第二步:分析阻塞根源
常见阻塞场景及特征:
| 场景 |
线程状态 |
识别特征 |
解决方案 |
| 死锁 |
BLOCKED |
jstack提示"Found deadlock" |
统一锁顺序,使用tryLock |
| 线程池满 |
WAITING |
主线程卡在submit() |
调整拒绝策略,上游限流 |
| 外部依赖无响应 |
TIMED_WAITING |
堆栈显示SocketRead |
设置连接/读取超时 |
| 活锁/无限重试 |
RUNNABLE |
CPU高但无进展 |
限制重试次数,指数退避 |
第三步:监控验证
- CPU使用率≈0%:可能死锁或IO阻塞
- CPU持续100%:可能死循环或频繁Full GC
- 全链路追踪中断:被调方无响应
预防措施:
- 强制超时机制:所有网络调用配置超时
- 线程命名规范化:便于排查
- 暴露监控指标:活跃线程数、队列大小等
- 混沌工程演练:定期注入故障验证系统韧性
优雅关闭与任务保障
标准关闭流程:
// 1. 拒绝新任务,执行已有任务
executor.shutdown();
// 2. 等待任务完成,设置超时
if (!executor.awaitTermination(30, TimeUnit.SECONDS)) {
executor.shutdownNow(); // 超时强制关闭
}
// 3. 注册ShutdownHook确保执行
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
// 执行关闭逻辑
}));
兜底保障机制:
- 任务持久化:执行前将状态保存到数据库
- 补偿Job:定期扫描异常任务并重试
- 幂等设计:支持重复执行不产生副作用
总结
多线程编程的核心在于资源调度的艺术而非简单并发。通过科学配置线程池参数、建立多层防护体系、实施系统化监控排查,才能构建稳定高效的高并发系统。真正的高可用不仅在于处理能力,更在于过载时的自我保护能力。
技术要点回顾:
- 根据任务类型(CPU/IO/混合型)科学计算线程数
- 使用有界队列配合合适拒绝策略防止资源失控
- Eager模式优化突发流量响应延迟
- 建立完整监控排查体系快速定位问题
- 实施优雅关闭机制保障数据一致性
 发表于 2025-12-20 02:34:29
|
查看: 225|
回复: 0
发表于 2025-12-20 02:34:29
|
查看: 225|
回复: 0
