在本地进行数据分析时,你是否经常遇到超大CSV文件导致Excel直接卡死崩溃,或是使用Pandas读取大型数据集时遭遇内存不足的窘境?有时为了临时的分析任务去搭建MySQL、PostgreSQL这类完整的数据库/中间件服务,又显得过于繁重。
最近,一款在GitHub上流行的嵌入式分析数据库——DuckDB,为解决此类问题提供了出色的方案。它专为快速SQL分析、数据探索及嵌入式数据处理而设计,兼具轻量与高性能。
项目简介
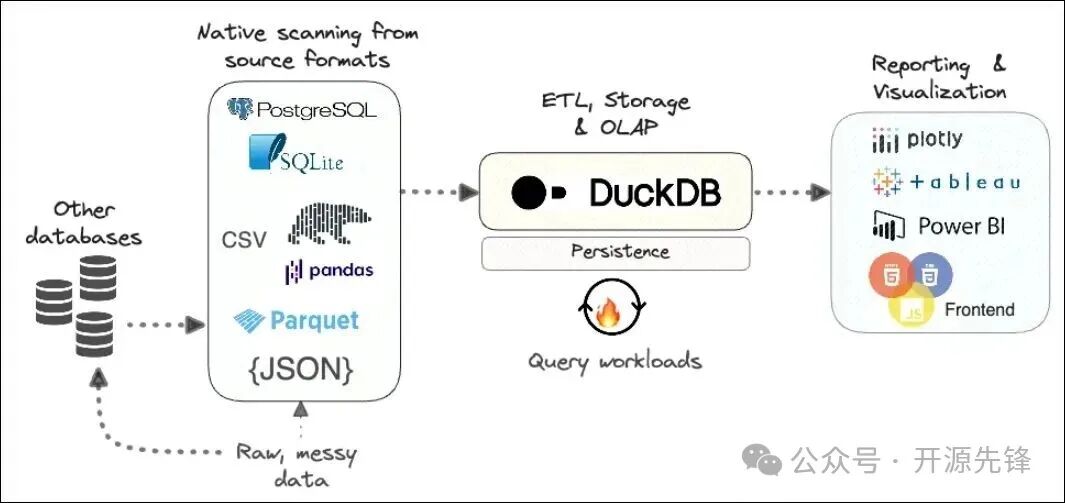
DuckDB 是一款开源的内嵌式列式关系型数据库管理系统(RDBMS),其设计核心聚焦于在线分析处理(OLAP)与复杂查询的高速执行。与需要独立服务进程的MySQL或PostgreSQL不同,DuckDB可直接嵌入到你的应用程序进程或Python等语言环境中运行。它提供了强大的SQL支持,并能够直接读取多种格式的数据文件,无需预先导入。
该项目在GitHub上已获得超过34.7k的Star,拥有活跃的社区和日益完善的生态,成为数据分析开发者青睐的工具。
核心功能特性
- 轻量嵌入式:无需独立的服务器进程,像SQLite一样直接嵌入应用,但专门为分析场景优化。
- 高性能分析:采用列式存储与向量化查询引擎,在聚合、过滤、扫描等分析型查询上表现卓越。
- 完整SQL支持:支持子查询、窗口函数、复杂数据类型等高级SQL功能,媲美专业分析工具。
- 多格式直接查询:可直接通过SQL语句查询CSV、Parquet、JSON等格式的文件,省去繁琐的ETL步骤。
- 多语言生态:原生支持Python、R、Java、Node.js、WASM等,并能与pandas、Apache Arrow等库深度集成。
- 可扩展架构:支持通过扩展插件来增强功能,例如添加地理空间数据处理或支持更多文件格式。
快速安装与使用
DuckDB支持跨平台及多语言环境的快速安装。
安装方式
命令行安装 (CLI):
# macOS 系统
brew install duckdb
# Ubuntu/Debian 系统
sudo apt-get install duckdb
# 通用脚本安装
curl https://install.duckdb.org | sh
Python 环境安装:
pip install duckdb
此外,也提供了针对R、Java、Node.js及WASM的安装方式,具体可查阅官方文档。
基础使用示例
1. 命令行交互模式
启动DuckDB CLI:
duckdb
执行SQL操作:
CREATE TABLE users (id INTEGER, name VARCHAR);
INSERT INTO users VALUES (1, 'Alice'), (2, 'Bob');
SELECT * FROM users;
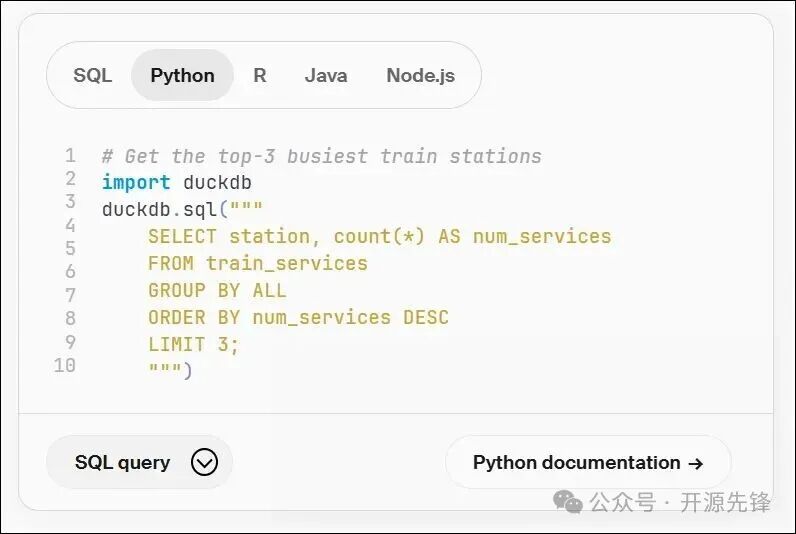
2. 在Python中直接分析CSV/Parquet文件
import duckdb
# 直接查询CSV文件
result = duckdb.sql("SELECT COUNT(*) FROM 'data.csv' WHERE age > 30").fetchall()
print(result)
# 直接查询Parquet文件
duckdb.sql("SELECT * FROM 'data.parquet' WHERE revenue > 10000").show()
无需预先将数据导入数据库,即可进行查询。
3. 与Pandas DataFrame无缝协作
import duckdb
import pandas as pd
df = pd.read_csv("sales.csv")
# 使用SQL查询DataFrame
res = duckdb.sql("SELECT region, SUM(amount) AS total FROM df GROUP BY region").df()
print(res)
Web Shell 在线体验
DuckDB官方提供了一个非常实用的Web Shell在线演示环境,无需任何安装与配置,打开浏览器即可体验其完整能力。
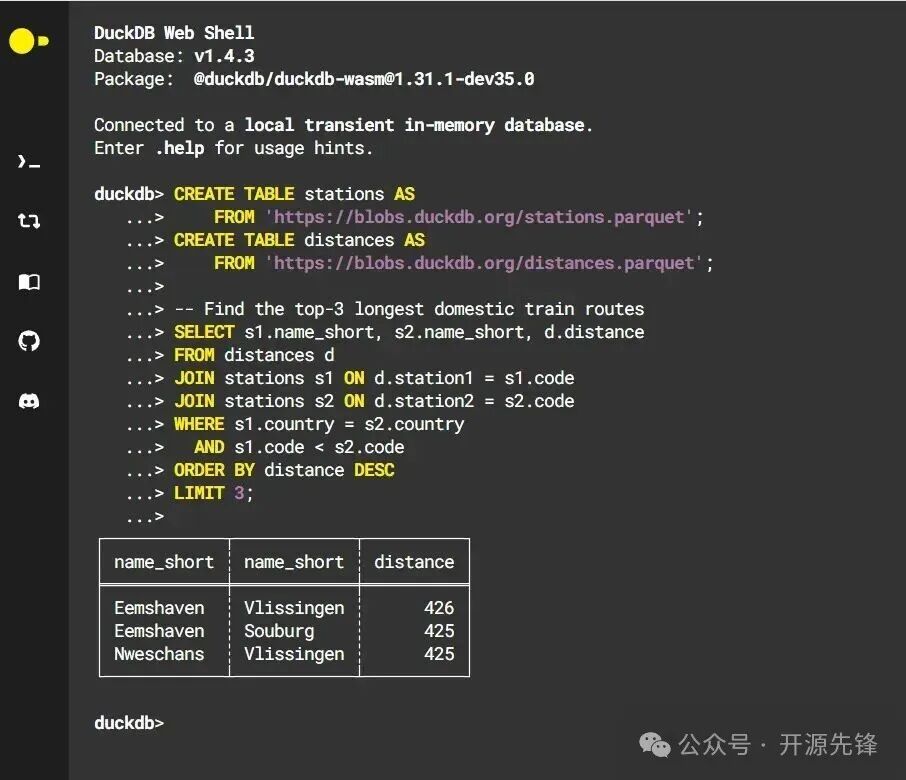
进入Web Shell后,会看到连接提示:
Connected to a local transient in-memory database.
这表示你已连接到一个本地临时内存数据库,非常适合快速分析与实验。
以下是一个演示案例,DuckDB可以直接将远程Parquet文件创建为表:
CREATE TABLE stations AS FROM 'https://blobs.duckdb.org/stations.parquet';
CREATE TABLE distances AS FROM 'https://blobs.duckdb.org/distances.parquet';
表创建完成后,即可执行复杂查询。例如,查找同一国家内距离最长的3条国内铁路线路:
SELECT
s1.name_short,
s2.name_short,
d.distance
FROM distances d
JOIN stations s1 ON d.station1 = s1.code
JOIN stations s2 ON d.station2 = s2.code
WHERE s1.country = s2.country
AND s1.code < s2.code
ORDER BY distance DESC
LIMIT 3;
此查询包含了多表JOIN、条件过滤、排序和结果条数限制。执行后,DuckDB会迅速返回结果:
| name_short |
name_short |
distance |
| Eemshaven |
Vlissingen |
426 |
| Eemshaven |
Souburg |
425 |
| Nieuweschans |
Vlissingen |
425 |
总结
DuckDB是一款定位清晰的嵌入式OLAP数据库。它并非旨在替代PostgreSQL、MySQL这类通用事务型数据库,也非完全取代Pandas这类数据科学库,而是在单机数据分析、轻量级ETL、应用原型开发等场景中,提供了一个更高效、更便捷的“瑞士军刀”式解决方案。
若想深入了解其更多细节与高级功能,可访问项目GitHub地址:
https://github.com/duckdb/duckdb
 发表于 2025-12-20 07:44:20
|
查看: 290|
回复: 0
发表于 2025-12-20 07:44:20
|
查看: 290|
回复: 0
