当你频繁访问同一文件时,是否好奇为何后续打开速度会大幅提升?当系统处理磁盘数据时,又是什么在背后缓解CPU与硬盘的速度鸿沟?答案,就藏在Linux内核两大缓存机制——Page Cache与Buffer Cache中。它们如同系统的“数据中转站”,悄无声息地优化着存储I/O性能,是理解 Linux 系统性能的关键。
有人将二者视为“孪生兄弟”,也有人困惑于它们的分工边界。实际上,Page Cache以“页”为单位缓存文件数据,Buffer Cache则聚焦磁盘块级别的元数据与原始数据,二者协同工作又各有侧重。理解它们的核心原理,不仅能搞懂系统卡顿、I/O瓶颈的根源,更能在性能调优、故障排查中精准发力。本文将跳出复杂的内核源码,用通俗语言拆解二者的工作机制:从数据缓存的触发时机,到内存中的存储方式;从相互配合的协同逻辑,到实际场景中的功能差异,带你快速建立清晰认知,真正读懂这两大Linux缓存“基石”。
一、Page Cache 与 Buffer Cache 是什么?
在深入了解它们的工作机制之前,我们先来搞清楚 Page Cache 和 Buffer Cache 到底是什么,它们在系统中扮演着怎样的基础角色。
1.1 Page Cache:文件数据的高速 “暂存站”
Page Cache,中文叫页缓存,是 Linux 内核用于缓存文件数据的一种机制。简单来说,它就像是一个高速“暂存站”,把磁盘上的文件数据临时存放在内存里。这样一来,当系统后续需要访问这些文件数据的时候,就可以直接从内存中读取,而不用每次都去磁盘里找,大大提升了文件读写的性能。
打个比方,Page Cache 就好比是图书馆里的热门书籍存放区。我们都知道,图书馆里的书成千上万,如果每次都要在庞大的书架中去找自己想要的书,那得花不少时间。于是,图书馆管理员就把那些经常被借阅的热门书籍专门挑出来,放在一个更方便取阅的区域。下次有人再来借这些热门书的时候,直接去这个专门的区域找就行了,一下子就能找到,节省了大量的时间和精力。Page Cache 也是如此,它把那些经常被访问的文件数据缓存起来,系统下次访问时就能快速获取,就像在图书馆的热门书籍存放区找书一样快捷。
Page Cache 是以“页”为单位来缓存文件数据的,这个“页”的大小通常是 4KB。也就是说,它会把文件数据按照 4KB 的大小,划分成一个个的页,然后把这些页缓存到内存中。这样做的好处是,在读取文件时,如果系统需要的数据已经在 Page Cache 的某个页中,那就可以直接从内存中读取这一页的数据,避免了对磁盘的 I/O 操作。要知道,磁盘的 I/O 操作可是非常耗时的,而内存的读取速度要比磁盘快得多,这就好比从家门口的便利店买东西和从遥远的仓库取货的区别,Page Cache 大大提高了文件读取的效率。
1.2 Buffer Cache:磁盘块的贴心 “管家”
Buffer Cache,也就是块缓存,主要负责缓存磁盘块级别的元数据与原始数据。它就像是一个仓库的管理员,不仅要管理货物(数据),还要管理货物存放的位置信息(元数据)。当系统对磁盘进行 I/O 操作时,Buffer Cache 就会发挥作用,它会把磁盘块的数据和相关的元数据缓存起来,以便后续的操作能够更快地进行。
比如,当我们要在磁盘上创建一个文件时,文件系统需要记录这个文件的一些元数据,像文件的创建时间、文件大小、文件所有者等等,这些元数据就会被 Buffer Cache 缓存起来。同时,文件的原始数据在写入磁盘之前,也会先存放在 Buffer Cache 中。这样,在后续对这个文件进行操作时,系统就可以先从 Buffer Cache 中查找相关的元数据和数据,而不用每次都去磁盘上读取,减少了磁盘 I/O 的次数,提高了操作的效率。
再举个更形象的例子,假设我们有一个大仓库,里面存放着各种各样的货物。仓库管理员为了能快速找到货物,会给每个货物都贴上标签,记录货物的名称、存放位置等信息,这些标签就相当于磁盘块的元数据。当有货物需要进出仓库时,管理员会先把货物存放在一个临时区域(相当于 Buffer Cache),方便管理和操作。等一切准备就绪,再把货物正式存入仓库或者从仓库取出。Buffer Cache 就是这样,在磁盘块数据的读写过程中,起到了一个临时存储和管理的作用,就像仓库管理员贴心地管理着货物和货物信息一样。
1.3 两类缓存的逻辑关系
从Linux内核版本2.6.18的源码实现来看,Page Cache与Buffer Cache本质上是同一内存管理机制在不同层次上的体现:对于同一个物理页(Page),在文件系统层面,它作为某个文件的页缓存(Page Cache)存在;而在底层块设备驱动层面,该页又表现为设备上的一组缓冲区缓存(Buffer Cache)。
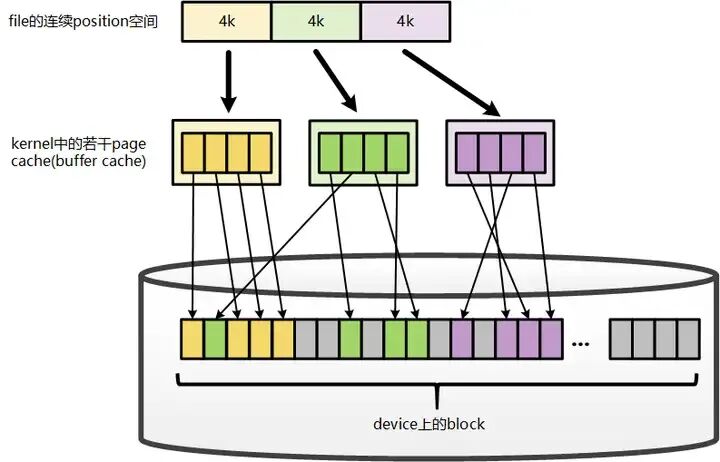
在文件系统的地址空间管理中,文件被按4KB(页大小)的粒度划分为逻辑单元。每个4KB单元可能映射到一个物理内存页(Page)——这里的“可能”指仅当该部分数据被实际缓存时才会建立映射,未被缓存的部分则无对应关系。这个被映射的4KB物理页即构成该文件的Page Cache。
从存储视角看,最终需要将文件的Page Cache落盘到磁盘块中。若磁盘块大小为1KB,则每个4KB的Page Cache会对应一组(4个)磁盘块的缓冲区缓存(Buffer Cache)。每个Buffer Cache通过一个称为buffer_head的描述符进行管理,该结构记录了对应缓冲区所映射的磁盘块的具体物理位置信息。
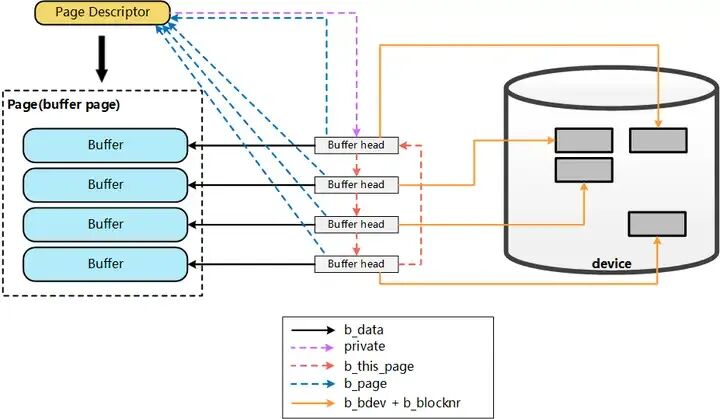
从文件操作的角度来看,要将数据写入磁盘,首先需要定位到该文件在内存中对应的具体 Page Cache 页。这一查找过程依赖于文件 inode 结构中的i_mapping字段,它维护了该文件的地址空间映射关系,从而能够根据文件偏移找到对应的物理内存页。
以下是模拟 Linux 内核文件系统的 Page Cache 与 Inode 映射关系的简化实现代码,帮助理解其核心逻辑:
#include <iostream>
#include <cstdint>
#include <unordered_map>
#include <vector>
#include <string>
#include <mutex>
#include <cstring>
// 内核基础常量定义
const uint64_t PAGE_SIZE = 4096; // 页大小(4KB)
const uint64_t BLOCK_SIZE = 512; // 磁盘块大小(512字节)
const uint32_t PAGES_PER_BLOCK = PAGE_SIZE / BLOCK_SIZE; // 每个页对应的磁盘块数
// 磁盘块结构体:表示物理磁盘上的一个数据块
struct Block {
uint64_t block_id; // 磁盘块唯一标识
uint8_t data[BLOCK_SIZE]; // 块数据
bool dirty; // 脏标记(是否需要写入磁盘)
Block(uint64_t id) : block_id(id), dirty(false) {
memset(data, 0, BLOCK_SIZE);
}
};
// Page Cache页结构体:内存中的缓存页,关联多个磁盘块
struct Page {
uint64_t page_id; // 页唯一标识(虚拟页号)
uint8_t data[PAGE_SIZE]; // 页数据
bool dirty; // 脏标记(是否与磁盘不一致)
std::vector<Block*> blocks; // 关联的磁盘块
std::mutex mtx; // 页同步锁
Page(uint64_t id) : page_id(id), dirty(false) {
memset(data, 0, PAGE_SIZE);
// 初始化页关联的磁盘块(每个页对应8个512字节的块)
for (uint32_t i = 0; i < PAGES_PER_BLOCK; ++i) {
blocks.push_back(new Block(id * PAGES_PER_BLOCK + i));
}
}
~Page() {
for (auto block : blocks) {
delete block;
}
}
};
// Address Space结构体:由inode的i_mapping指向,管理文件的Page Cache映射
struct AddressSpace {
uint64_t space_id; // 地址空间唯一标识
// 页映射:文件偏移量(按页对齐)→ Page Cache页
std::unordered_map<uint64_t, Page*> page_map;
std::mutex mtx; // 地址空间同步锁
AddressSpace(uint64_t id) : space_id(id) {}
// 根据文件偏移量查找对应的Page Cache页
Page* find_page(uint64_t file_offset) {
std::lock_guard<std::mutex> lock(mtx);
uint64_t page_offset = file_offset & ~(PAGE_SIZE - 1); // 按页对齐的偏移量
if (page_map.find(page_offset) != page_map.end()) {
return page_map[page_offset];
}
// 页不存在则创建新页并加入映射
Page* new_page = new Page(page_offset / PAGE_SIZE);
page_map[page_offset] = new_page;
return new_page;
}
};
// Inode结构体:文件的索引节点,通过i_mapping关联Address Space
struct Inode {
uint64_t inode_id; // inode唯一标识
std::string filename; // 关联的文件名
uint64_t size; // 文件大小
AddressSpace* i_mapping; // 关键字段:指向地址空间,管理Page Cache
Inode(uint64_t id, const std::string& name) : inode_id(id), filename(name), size(0) {
// 初始化地址空间,建立inode与Page Cache的映射
i_mapping = new AddressSpace(id);
}
~Inode() {
// 释放地址空间及所有Page Cache页
for (auto& pair : i_mapping->page_map) {
delete pair.second;
}
delete i_mapping;
}
};
// 文件系统管理器:管理inode、Page Cache、磁盘块
struct FileSystem {
std::unordered_map<uint64_t, Inode*> inode_map; // inode ID→inode映射
std::mutex mtx; // 文件系统同步锁
// 创建文件:生成inode并初始化i_mapping
Inode* create_file(uint64_t inode_id, const std::string& filename) {
std::lock_guard<std::mutex> lock(mtx);
Inode* inode = new Inode(inode_id, filename);
inode_map[inode_id] = inode;
std::cout << "[文件系统] 创建文件:" << filename << ",inode ID:" << inode_id << std::endl;
return inode;
}
// 写入文件数据:通过inode的i_mapping找到Page Cache,再写入数据
ssize_t write_file(Inode* inode, uint64_t file_offset, const uint8_t* data, size_t len) {
if (!inode || !data || len == 0) {
return -1;
}
size_t written = 0;
while (written < len) {
// 步骤1:通过inode的i_mapping获取地址空间
AddressSpace* mapping = inode->i_mapping;
if (!mapping) {
std::cerr << "[写入失败] inode的i_mapping为空" << std::endl;
return written > 0 ? written : -1;
}
// 步骤2:根据文件偏移量查找对应的Page Cache页
Page* page = mapping->find_page(file_offset + written);
if (!page) {
std::cerr << "[写入失败] 无法找到/创建Page Cache页" << std::endl;
return written > 0 ? written : -1;
}
// 步骤3:计算数据在页内的偏移量
uint64_t page_offset = (file_offset + written) % PAGE_SIZE;
size_t write_len = std::min(len - written, PAGE_SIZE - page_offset);
// 步骤4:写入数据到Page Cache页
std::lock_guard<std::mutex> lock(page->mtx);
memcpy(page->data + page_offset, data + written, write_len);
page->dirty = true; // 标记页为脏页
// 同步更新关联磁盘块的脏标记
uint32_t start_block = page_offset / BLOCK_SIZE;
uint32_t block_count = (write_len + BLOCK_SIZE - 1) / BLOCK_SIZE;
for (uint32_t i = 0; i < block_count; ++i) {
page->blocks[start_block + i]->dirty = true;
}
std::cout << "[Page Cache] 文件" << inode->filename << ",偏移量" << (file_offset + written)
<< ",写入" << write_len << "字节到页" << page->page_id << std::endl;
// 更新已写入长度和文件大小
written += write_len;
if (file_offset + written > inode->size) {
inode->size = file_offset + written;
}
}
return written;
}
// 将脏页刷入磁盘:模拟数据从Page Cache写入物理磁盘
int flush_dirty_pages(Inode* inode) {
if (!inode) {
return -1;
}
AddressSpace* mapping = inode->i_mapping;
if (!mapping) {
std::cerr << "[刷盘失败] inode的i_mapping为空" << std::endl;
return -1;
}
int flushed_pages = 0;
std::lock_guard<std::mutex> lock(mapping->mtx);
for (auto& pair : mapping->page_map) {
Page* page = pair.second;
std::lock_guard<std::mutex> page_lock(page->mtx);
if (page->dirty) {
// 模拟将页数据写入关联的磁盘块
for (auto block : page->blocks) {
if (block->dirty) {
memcpy(block->data, page->data + (block->block_id % PAGE_SIZE), BLOCK_SIZE);
block->dirty = false;
}
}
page->dirty = false;
flushed_pages++;
std::cout << "[刷盘成功] 文件" << inode->filename << ",页" << page->page_id << "已写入磁盘" << std::endl;
}
}
return flushed_pages;
}
};
// 主流程:模拟文件写入与Page Cache交互的完整过程
int main() {
// 1. 初始化文件系统
FileSystem fs;
// 2. 创建文件(生成inode,初始化i_mapping)
Inode* file_inode = fs.create_file(1001, "game_texture.dat");
// 3. 写入数据到文件:通过inode的i_mapping找到Page Cache
uint8_t test_data[] = "High-resolution texture data for 3D game scene, including terrain and character models.";
size_t data_len = sizeof(test_data) - 1;
ssize_t written = fs.write_file(file_inode, 0, test_data, data_len);
std::cout << "\n[文件写入] 共写入" << written << "字节到文件" << file_inode->filename << std::endl;
// 4. 将脏页刷入磁盘
int flushed = fs.flush_dirty_pages(file_inode);
std::cout << "\n[刷盘统计] 共刷入" << flushed << "个脏页到磁盘" << std::endl;
// 5. 释放资源
delete file_inode;
return 0;
}
二、Page Cache与Buffer Cache工作原理
2.1 Page Cache 的工作流程
(1)读取操作:命中与未命中的故事
当我们在 Linux 系统中读取一个文件时,Page Cache 就开始发挥它的关键作用了。内核首先会在 Page Cache 中检查我们所需要的数据是否已经被缓存起来。
- 缓存命中:如果数据已经在 Page Cache 中,恭喜,这就是所谓的缓存命中。此时,内核就可以直接从内存中读取数据,完全不需要去访问速度相对较慢的磁盘。这大大节省了数据读取的时间,使得文件能够快速地被打开或者处理。
- 缓存未命中:但如果 Page Cache 中没有找到我们需要的数据,也就是缓存未命中,那就得麻烦磁盘“出山”了。内核会向磁盘发送读取请求,磁盘找到对应的数据块读取出来。数据读取出来后,内核会把这些数据填充到 Page Cache 中,方便下次再被访问时能够快速获取。同时,内核还会把这些数据返回给请求的进程。
这里还有一个有趣的小细节,为了进一步提高读取效率,内核在从磁盘读取数据时,往往会采用预读机制。简单来说,就是内核会猜测进程接下来可能还会需要哪些数据,然后提前把这些数据也一起读取到 Page Cache 中。就好比我们去超市买东西,虽然只列了一张购物清单,但想到可能还会用到其他东西,就顺手多买了一些备用。这样一来,当进程后续真的需要这些数据时,就很有可能在 Page Cache 中直接命中,避免了再次从磁盘读取的开销,大大提高了数据读取的连贯性和效率。
(2)写入操作:延迟与回写的策略
在文件写入操作中,Page Cache 采用了一种非常巧妙的策略,叫做延迟写入和回写策略。
当一个进程要向文件写入数据时,内核同样会先检查 Page Cache 中是否已经存在该文件对应的缓存页。如果存在,进程就直接把数据写入到这个缓存页中;如果不存在,内核会先分配一个新的缓存页,然后把数据写入进去。不管是哪种情况,写入数据后的缓存页都会被标记为“脏页”,这就像是在告诉系统:“嘿,我这里面的数据和磁盘上的不一样啦,得找个时间把新数据同步到磁盘上去。”
但是,内核并不会马上把脏页中的数据写入磁盘,而是会等待一段时间。这是因为如果每次有少量数据写入就立刻同步到磁盘,磁盘的 I/O 操作会非常频繁,效率会很低。所以,内核会把这些脏页先放在 Page Cache 中,等积累到一定数量,或者满足特定的条件时,再统一进行回写操作。
触发回写的典型条件包括:
- 时间间隔:系统会定期(比如每隔 5 秒或者 30 秒)唤醒一个专门负责回写的内核线程,这个线程会扫描Page Cache中的脏页,把符合条件的脏页写回磁盘。
- 内存压力:当系统可用内存不足时,内核需要回收一些内存页来分配给新的需求。如果要回收的内存页是脏页,那就得先把它写回磁盘,确保数据不会丢失,然后才能释放这个内存页。
- 脏页比例:当系统中脏页的数量超过一定阈值时,为了保证数据的一致性和系统的稳定性,也会触发脏页回写操作。
- 显式同步:应用程序可以通过调用
fsync()、fdatasync() 或 sync() 等系统调用,强制把文件和文件系统的脏页刷新到磁盘上。这就像是我们有非常紧急的快递,等不及快递员的固定收取时间,直接打电话让快递员马上来取件一样。
在回写过程中,内核线程会找到需要回写的脏页,然后发起磁盘 I/O 操作,把脏页中的数据写回到磁盘文件对应的位置。写成功后,这个脏页就会被标记为“干净页”,表示它里面的数据已经和磁盘上的完全一致了。通过这种延迟写入和回写策略,Page Cache 大大减少了磁盘 I/O 的次数,提高了文件写入的性能,同时也保证了数据的持久性和一致性。
2.2 Buffer Cache 的工作流程
(1)数据缓冲:磁盘 I/O 的优化之道
在数据写入磁盘的过程中,Buffer Cache 充当了一个至关重要的角色。当我们要把数据写入磁盘时,数据并不会直接就被写入磁盘,而是会先被存放在 Buffer Cache 中。这就好比我们在寄快递时,不会直接把包裹送到快递站,而是先把包裹放在家里的一个临时存放点,等积累到一定数量或者到了合适的时间再一起送去快递站。
假设我们要向磁盘写入大量的数据,这些数据会按照一定的大小,以磁盘块为单位,依次被存入 Buffer Cache 中。当 Buffer Cache 中的数据达到一定量(比如一个磁盘块的大小),或者满足特定的写入条件(如操作系统的写入调度策略)时,这些数据就会被一次性批量写入磁盘。这样做的好处是显而易见的,因为磁盘的读写操作相对较慢,如果每次有少量数据就直接写入磁盘,磁盘的磁头需要频繁地移动来定位数据位置,这会花费大量的时间。而通过 Buffer Cache 的缓冲,将分散的小写入操作合并成大的写入操作,大大提高了数据传输的效率,减少了磁盘 I/O 的次数,就像把多个小包裹合并成一个大包裹再寄出去,节省了运输次数和时间。
在数据读取时,Buffer Cache 也起着类似的作用。当我们从磁盘读取数据时,磁盘会先把数据读取到 Buffer Cache 中,然后内存再从 Buffer Cache 中读取数据。这就避免了内存直接与速度较慢的磁盘频繁交互,保证了数据传输的稳定性和高效性。就好比我们从图书馆借书,不是直接从书架上一本一本地取书,而是先让图书馆管理员把我们要借的书都拿到一个专门的借阅区,我们再从这个借阅区取书,这样就减少了我们在书架间来回奔波的时间和精力。
(2)元数据缓存:文件系统的幕后支持
除了数据缓冲,Buffer Cache 还肩负着缓存文件系统元数据的重要任务。文件系统的元数据就像是一本书的目录、作者信息、出版时间等,虽然不是书的主要内容,但对于管理和查找书籍非常重要。同样,文件系统的元数据包含了文件的属性、权限、所有者、创建时间、修改时间,以及文件在磁盘上的存储位置等信息,这些信息对于文件系统的正常运行和文件的管理操作至关重要。
比如,当我们要在磁盘上创建一个文件时,文件系统需要记录这个文件的各种元数据,像文件的名称、大小、所有者等,这些元数据就会被 Buffer Cache 缓存起来。这样,在后续对这个文件进行操作时,比如读取文件的属性、修改文件的权限或者删除文件等,系统就可以先从 Buffer Cache 中查找相关的元数据,而不用每次都去磁盘上读取,大大提高了操作的效率。就好比我们要查找一本书的某个章节内容,如果我们知道这本书的目录结构,就可以直接根据目录快速找到对应的章节,而不用一页一页地翻阅整本书。
再比如,当我们要删除一个文件时,文件系统首先会在 Buffer Cache 中查找这个文件的元数据,确认文件的相关信息,然后再进行删除操作。如果没有 Buffer Cache 对元数据的缓存,每次进行文件系统操作都需要从磁盘上读取元数据,这会大大增加磁盘 I/O 的负担,降低系统的响应速度。所以说,Buffer Cache 的元数据缓存功能就像是文件系统的幕后英雄,默默地支持着文件系统的各种操作。
2.3 二者之间的区别
为了更清晰地看出 Page Cache 和 Buffer Cache 的差异,我们通过下面的表格来对比一下:
| 对比项 |
Page Cache |
Buffer Cache |
| 缓存内容 |
文件数据,以内存页(常见 4KB)为单位缓存文件内容 |
磁盘块数据,缓存磁盘块,辅助磁盘 I/O 操作 |
| 应用场景 |
主要用于文件系统操作,如文件的读写,对文件内容的缓存 |
用于直接磁盘块操作,如文件系统元数据(inode、dentry、超级块等)的读写,以及直接对裸磁盘设备(如/dev/sda)进行读写操作时的数据缓存 |
| 数据结构 |
通过 struct page 结构体管理缓存页面,与地址空间(address_space)关联,每个文件(inode)都有自己的 address_space,使用基数树(radix tree)快速定位某个文件的偏移量对应的页面 |
通过 struct buffer_head 结构体管理,struct buffer_head 包含成员 struct page *b_page,用于指向对应的页面 |
| 更新策略 |
写操作时先写入 Page Cache,标记为脏页,由内核异步回写,回写触发条件有系统定期扫描、脏页比例达到阈值、内存不足、应用程序调用同步系统调用等 |
写入时先存入 Buffer Cache,当满足一定条件(如达到磁盘块大小)时写入磁盘 |
| 数据读取单位 |
以内存页为单位读取和缓存文件数据 |
以磁盘块为单位读取和缓存数据 |
在现代 Linux 系统中,Page Cache 和 Buffer Cache 并非完全独立,而是紧密联系在一起的。从 Linux 2.4 内核版本之后,两者进行了统一管理。Buffer Cache 对应的页面被纳入到 Page Cache 池中进行管理,也就是说,现在 Buffer Cache 其实是 Page Cache 的一个特殊子集。当数据从磁盘读取到内存时,如果是文件数据,缓存在 Page Cache 中;如果是裸块设备 I/O(如 dd if=/dev/sda)的数据,同样也缓存在 Page Cache 中(只是标记为属于块设备而不是文件)。
文件系统元数据(如 inode、directory entries)的缓存也被纳入到 Page Cache 管理。这种统一管理的方式,简化了系统的设计,提高了内存的利用率,一块物理内存页可以同时服务于文件和块 I/O 缓存,减少了数据的重复缓存,让内存管理更加高效、简洁。
三、协同与差异:它们的关系解读
3.1 协同工作:Linux 存储 I/O 的完美搭档
在 Linux 系统的存储 I/O 体系中,Page Cache 和 Buffer Cache 并不是各自为战的,它们就像一对配合默契的搭档,相互协作,共同优化着数据的读写过程,确保系统能够高效地运行。
当我们从磁盘读取文件数据时,这个过程就像是一场接力赛,Buffer Cache 和 Page Cache 在其中分别扮演着重要的角色。首先,磁盘会把数据读取到 Buffer Cache 中,这是接力赛的第一棒。Buffer Cache 就像是一个临时的“中转站”,它接收从磁盘传来的数据,对这些数据进行初步的缓冲和处理。然后,这些经过 Buffer Cache 初步处理的数据会被传递给 Page Cache,这是接力赛的第二棒。Page Cache 会把这些数据以页为单位进行缓存,并且建立起文件数据与内存页之间的映射关系。这样,当系统后续需要访问这些文件数据时,就可以直接从 Page Cache 中快速获取,大大提高了数据的读取速度。
在文件写入过程中,它们同样密切配合。当应用程序要向文件写入数据时,数据首先会被写入到 Page Cache 中,Page Cache 会把这些数据标记为“脏页”。然后,在适当的时候,这些脏页中的数据会被传递给 Buffer Cache。Buffer Cache 会对这些数据进行进一步的处理,比如将分散的小写入操作合并成大的写入操作,以提高磁盘写入的效率。最后,Buffer Cache 会把处理好的数据写入磁盘,完成整个写入过程。
3.2 应用场景
(1)Page Cache 应用场景
- Web 服务器:在 Web 服务器中,Page Cache 起着至关重要的作用。以常见的 Nginx 服务器为例,当用户请求静态文件,如 HTML 页面、CSS 样式表、JavaScript 脚本和图片等。当第一个用户请求该首页时,Nginx 服务器会从磁盘读取这些静态文件,并将它们缓存到 Page Cache 中。当后续其他用户再请求相同的首页时,Nginx 可以直接从 Page Cache 中获取这些静态文件,快速响应用户请求,大大减少了磁盘 I/O 操作,提高了网站的访问速度。这不仅提升了用户体验,还减轻了服务器的负载压力。
- 数据库系统:数据库系统对数据的读写操作非常频繁,Page Cache 在这里发挥着关键作用。以 MySQL 数据库为例,当执行查询操作时,比如查询一张用户表中所有用户的信息。MySQL 会先从磁盘读取用户表的数据文件。如果这些数据文件的部分内容已经缓存在 Page Cache 中,MySQL 就可以直接从 Page Cache 中读取数据,而不需要再次从磁盘读取。这大大加快了查询速度,提高了数据库的性能。在写入操作时,如插入新的用户记录,数据也是先写入 Page Cache,标记为脏页。然后由内核在合适的时候将脏页同步到磁盘,减少了磁盘 I/O 的次数,保证了数据库的高效运行。
(2)Buffer Cache 应用场景
- 大数据存储:在大数据存储场景中,数据的读写操作十分频繁且数据量巨大,Buffer Cache 能够有效提升数据处理效率。以 Hadoop 分布式文件系统(HDFS)为例,HDFS 中的数据块会频繁地进行读写操作。当一个 MapReduce 任务需要读取 HDFS 中的数据块时,数据首先会被读取到 Buffer Cache 中。假设一个数据分析任务需要处理一个包含数十亿条记录的日志文件,这个文件被存储在 HDFS 上并分成多个数据块。MapReduce 任务在读取这些数据块时,如果数据块在 Buffer Cache 中,就可以直接从这里获取,避免了直接访问磁盘的开销,提高了数据读取速度。在写入数据时,如将分析结果写回 HDFS,数据先存入 Buffer Cache,等积累到一定量后再批量写入磁盘,减少了磁盘 I/O 的次数,提升了大数据处理的效率。
- 文件系统元数据操作:在文件系统中,对元数据(如 inode、dentry、超级块等)的操作非常频繁,Buffer Cache 在这方面发挥着重要作用。当我们在 Linux 系统中创建一个新文件时,文件系统需要更新文件的元数据,如创建新的 inode,记录文件的权限、所有者、大小等信息。这些元数据的读写操作会先经过 Buffer Cache。假设我们在一个目录下创建多个文件,每次创建文件时对 inode 等元数据的更新操作都会先在 Buffer Cache 中进行缓存。当后续需要再次访问这些元数据时,就可以直接从 Buffer Cache 中获取,减少了对磁盘的访问次数,提高了文件系统操作的速度和稳定性。在删除文件时,对文件元数据的删除操作同样先在 Buffer Cache 中缓存,等合适时机再同步到磁盘。
3.3 功能差异:不同场景下的各司其职
虽然 Page Cache 和 Buffer Cache 在很多情况下协同工作,但它们在功能上也有着明显的差异,在不同的实际场景中发挥着各自独特的作用。
在文件读写场景中,Page Cache 的作用尤为突出。当我们频繁地读取一个文件时,Page Cache 能够显著提升读取速度。因为它会把文件数据以页为单位缓存起来,只要文件的部分数据被访问过,这些数据就会被缓存到 Page Cache 中,后续再次访问相同的数据时,就可以直接从内存中读取,避免了重复从磁盘读取的开销。比如,我们在开发过程中,经常需要读取代码文件、配置文件等,这些文件可能会被反复访问。有了 Page Cache 的存在,我们每次读取这些文件时,速度都会非常快,大大提高了开发效率。
而 Buffer Cache 在文件系统元数据的管理和磁盘块级别的操作中则起着关键作用。当我们执行一些涉及文件系统元数据的操作时,比如创建文件、删除文件、修改文件权限等,Buffer Cache 就会发挥重要作用。因为这些操作需要频繁地读取和更新文件系统的元数据,而 Buffer Cache 缓存了这些元数据,使得系统能够快速地获取和修改它们,提高了操作的效率。例如,当我们使用 ls 命令查看目录下的文件列表时,系统需要读取目录的元数据来获取文件的相关信息,这些元数据就存储在 Buffer Cache 中,所以我们能够快速地看到文件列表。
再比如,在进行磁盘块级别的操作时,如使用 dd 命令直接对磁盘进行读写,Buffer Cache 就成为了主角。因为 dd 命令是直接操作磁盘块,而 Buffer Cache 正是缓存磁盘块数据的地方。它可以有效地减少磁盘 I/O 的次数,提高磁盘块操作的效率。假设我们要使用 dd 命令复制一个磁盘分区,数据会先被读取到 Buffer Cache 中,然后再从 Buffer Cache 写入到目标分区,这样可以避免频繁地直接访问磁盘,加快复制的速度。
综上所述,Page Cache 和 Buffer Cache 虽然都与数据缓存和 I/O 优化有关,但它们的功能重点和适用场景有所不同。Page Cache 主要针对文件数据的读写进行优化,通过缓存文件内容来提高文件访问速度;而 Buffer Cache 则侧重于磁盘块级别的数据缓存和文件系统元数据的管理,在涉及磁盘块操作和文件系统元数据操作时发挥着重要作用。在实际的系统运行中,它们相互配合,共同为 Linux 系统的存储 I/O 性能提供保障。
四、实际应用:性能优化与故障排查
4.1 性能优化:利用缓存提升系统速度
在实际的 Linux 系统应用中,合理利用 Page Cache 和 Buffer Cache 能够显著提升系统的整体性能。而调整相关的内核参数以及优化文件读写顺序,是充分发挥这两大缓存机制优势的关键。
首先,我们来谈谈内核参数的调整。在 Linux 系统中,有许多与 Page Cache 和 Buffer Cache 相关的内核参数,通过合理调整这些参数,可以优化缓存的性能。比如 vm.dirty_ratio 这个参数,它表示系统中允许缓存的脏页数据占总内存的最大百分比。当系统中脏页的比例超过这个值时,内核就会触发回写操作,把脏页数据写回磁盘。一般来说,默认值可能并不适用于所有的应用场景。如果我们的系统是一个写密集型的应用,比如数据库服务器,大量的数据写入操作会导致脏页迅速积累。这时,适当降低 vm.dirty_ratio 的值,比如从默认的 20% 降低到 10%,可以让内核更频繁地进行回写操作,减少内存中脏页的数量,避免因脏页过多导致系统内存压力过大,从而提高系统的稳定性和写入性能。相反,如果系统是读密集型的,我们可以适当提高这个值,让更多的数据留在 Page Cache 中,提高读取的命中率。这属于 系统性能调优 的经典操作。
还有 vm.dirty_background_ratio 参数,它决定了系统后台回写进程开始工作时,脏页占总内存的比例。当脏页比例达到这个值时,系统会启动一个后台线程,异步地将脏页写回磁盘。对于一些对 I/O 性能要求较高的应用,我们可以适当降低这个值,让后台回写进程更早地开始工作,避免脏页积累过多影响系统性能。
除了调整内核参数,优化文件读写顺序也是提高缓存命中率的重要方法。由于 Page Cache 和 Buffer Cache 都是根据数据的访问模式来进行缓存的,所以合理的文件读写顺序能够让更多的数据命中缓存。例如,在读取文件时,如果我们能够按照顺序读取,就可以充分利用 Page Cache 的预读机制。因为预读机制是基于顺序访问的假设来工作的,当系统发现应用程序在顺序读取文件时,它会提前将后续的数据也读取到 Page Cache 中。假设我们要读取一个大型的日志文件进行分析,如果我们逐行顺序读取这个文件,系统就会预测到我们接下来可能会读取的内容,提前将相关的数据块读入 Page Cache。这样,当我们真正需要这些数据时,就可以直接从 Page Cache 中获取,大大提高了读取的速度。相反,如果我们随机读取文件中的内容,预读机制就无法发挥作用,缓存命中率会降低,读取性能也会受到影响。
在写入文件时,同样要注意顺序性。尽量将相关的数据一次性写入,避免频繁的小写入操作。因为频繁的小写入会导致 Buffer Cache 中的数据频繁更新,增加了回写的次数和开销。比如,我们要向一个文件中写入一批用户的登录日志,如果我们能够将这些日志数据先在内存中组装好,然后一次性写入文件,就可以减少 Buffer Cache 的操作次数,提高写入效率。同时,这种方式也有利于 Buffer Cache 将多个小写入合并成一个大的写入操作,进一步提升磁盘写入的性能。
4.2 故障排查:从缓存角度找问题根源
当 Linux 系统出现 I/O 瓶颈、卡顿等问题时,Page Cache 和 Buffer Cache 的使用情况往往能为我们提供重要的线索,帮助我们快速定位问题的根源。
首先,我们可以通过一些工具来查看缓存命中率,以此判断缓存是否正常工作。在 Linux 系统中,cachestat 就是一个非常好用的工具,它可以实时显示缓存的命中和未命中次数等信息。例如,我们运行 sudo cachestat 1 命令,它会每隔 1 秒输出一次缓存的统计信息,其中 HITS 表示缓存命中的次数,MISSES 表示缓存未命中的次数,RATIO 则是缓存命中率。如果我们发现缓存命中率非常低,比如只有 20% 左右,那就说明系统在读取数据时,大部分情况下都无法从缓存中获取数据,而是需要从磁盘读取,这可能是导致 I/O 瓶颈和系统卡顿的一个重要原因。
导致缓存命中率低的原因有很多。一种可能是系统的内存不足,无法为 Page Cache 和 Buffer Cache 提供足够的空间来缓存数据。当内存紧张时,内核会频繁地回收缓存页,导致缓存中的数据被频繁替换,从而降低了缓存命中率。这时,我们可以通过查看系统的内存使用情况来确认,比如使用 free -h 命令查看内存的总量、已使用量、空闲量以及缓存使用量等信息。如果发现内存使用率过高,接近 100%,并且缓存使用量非常小,那就需要考虑增加物理内存,或者优化系统的内存使用,释放一些不必要的内存占用。
另一种可能是应用程序的访问模式不合理,导致缓存无法有效利用。比如,应用程序频繁地随机读写文件,这种访问模式会破坏缓存的预读和合并机制,使得缓存难以发挥作用。对于这种情况,我们需要分析应用程序的代码,尽量优化其文件访问方式,使其更符合缓存的工作原理。比如,可以将随机读写转换为顺序读写,或者采用批量读写的方式,减少 I/O 操作的次数。
除了缓存命中率,我们还可以通过查看系统的 I/O 统计信息来进一步定位问题。iostat 工具可以提供详细的磁盘 I/O 统计数据,包括磁盘的读写速率、I/O 请求的平均等待时间、磁盘的使用率等。如果我们发现磁盘的使用率持续过高,比如超过 80%,并且 I/O 请求的平均等待时间很长,那就说明磁盘 I/O 出现了瓶颈。这可能是由于大量的 I/O 请求同时到达,或者缓存机制失效,导致磁盘无法及时响应所有的请求。此时,我们可以结合缓存的使用情况来分析,如果缓存命中率正常,但磁盘 I/O 仍然繁忙,那就可能是磁盘本身的性能问题,比如磁盘老化、磁盘阵列配置不合理等,需要进一步检查磁盘硬件和相关配置。
另外,iotop 工具可以帮助我们找出系统中占用 I/O 资源最多的进程。当系统出现 I/O 问题时,通过 iotop 查看各个进程的 I/O 读写情况,我们可能会发现某个进程在疯狂地进行磁盘读写操作,导致系统 I/O 资源被耗尽。比如,某个日志记录进程不停地往磁盘写入大量的日志数据,就可能会造成 I/O 瓶颈。找到这个问题进程后,我们可以对其进行优化,比如调整日志记录的频率,或者采用异步写入的方式,减少对磁盘 I/O 的直接占用。
4.3 Page Cache与Buffer Cache优化策略
(1)Page Cache 优化策略
- 调整缓存大小:在 Linux 系统中,虽然 Page Cache 的大小是动态调整的,但我们可以通过修改一些内核参数来间接影响它。比如
vm.vfs_cache_pressure 参数(默认值为 100),它控制着内核回收页缓存和交换缓存时,对目录项缓存(dentry)和索引节点对象(inode objects)的回收倾向。增大这个值,会使内核更倾向于释放 dentry 和 inode 缓存,从而有可能为 Page Cache 腾出更多内存空间;减小这个值,则会使内核更倾向于保留这些缓存。例如,在一个以文件读写为主的服务器上,如果发现 Page Cache 占用内存不足,导致文件读取性能下降,可以适当增大 vm.vfs_cache_pressure 的值,如设置为 150,通过 sysctl -w vm.vfs_cache_pressure=150 命令来实现,让内核更多地释放 dentry 和 inode 缓存,为 Page Cache 提供更多内存。
- 优化预读机制:预读是 Page Cache 提升性能的重要手段。我们可以通过调整
/sys/block/sdX/queue/read_ahead_kb(其中 sdX 是具体的磁盘设备名,如 sda)参数来优化预读机制。这个参数表示每次预读的块大小(单位为 KB)。如果我们的应用程序以顺序读取大文件为主,比如视频播放、大数据分析等场景,可以适当增大这个值。假设我们有一个用于视频直播的服务器,视频文件以顺序读取为主,将 read_ahead_kb 从默认的 128KB 增大到 512KB,可以提前预读更多的数据到 Page Cache 中,减少后续读取磁盘的次数,提高视频播放的流畅性,通过 echo 512 > /sys/block/sda/queue/read_ahead_kb 命令来设置。
- 合理设置脏页回写参数:脏页回写参数对系统性能和数据安全性都有重要影响。
vm.dirty_background_ratio 参数(默认值为 10,表示系统内存的 10%)定义了当脏页占系统总内存的比例达到这个值时,内核会启动后台回写线程将脏页写入磁盘。如果我们的系统写入操作频繁,且对数据丢失的容忍度较低,可以适当减小这个值,比如设置为 5,通过 sysctl -w vm.dirty_background_ratio=5 命令,让脏页更快地被写回磁盘,减少数据丢失的风险。vm.dirty_ratio 参数(默认值为 20)定义了当脏页占系统总内存的比例达到这个值时,系统会同步阻塞式地将脏页写回磁盘,以避免脏页过多导致数据丢失,同样可以根据实际情况进行调整。
(2)Buffer Cache 优化策略
- 优化缓冲区大小:对于数据库系统等对 Buffer Cache 依赖较大的应用,合理调整缓冲区大小至关重要。在 Oracle 数据库中,可以通过
DB_CACHE_SIZE 参数来调整 Buffer Cache 的大小。如果数据库以 OLTP(联机事务处理)业务为主,数据读写频繁且对响应速度要求高,可以适当增大 DB_CACHE_SIZE,如设置为物理内存的 40% - 60%。假设一个银行的核心交易系统,每天处理大量的联机交易,将 DB_CACHE_SIZE 设置为物理内存的 50%,可以有效提高数据读写性能,减少磁盘 I/O 操作,提升交易处理的速度和稳定性。可以通过修改数据库配置文件或者使用 ALTER SYSTEM SET DB_CACHE_SIZE=xxx SCOPE=BOTH(xxx为具体大小值)命令来动态调整。这种针对具体 数据库 的调优是保障其高性能运行的核心。
- 调整写入策略:选择合适的写入策略可以显著提升 Buffer Cache 的性能。常见的写入策略有写直达(Write Through)和写回(Write Back)。写直达策略是指数据在写入 Buffer Cache 的同时,也立即写入磁盘,这种策略能保证数据的一致性,但会增加磁盘 I/O 次数;写回策略是指数据先写入 Buffer Cache,标记为脏数据,等缓冲区满或者满足特定条件时再批量写入磁盘,这种策略减少了磁盘 I/O 次数,但存在数据丢失的风险。对于一些对数据一致性要求不是特别高,但对性能要求较高的场景,如大数据存储中的一些日志数据写入,可以采用写回策略。而对于数据库等对数据一致性要求极高的应用,可能更适合写直达策略。在 Linux 系统中,可以通过一些文件系统相关的参数来间接调整写入策略,比如
ext4 文件系统中的 data=writeback 挂载选项,启用写回模式。
- 监控缓冲区命中率:缓冲区命中率是衡量 Buffer Cache 性能的重要指标。在 Oracle 数据库中,可以通过查询
V$BUFFER_POOL_STATISTICS 视图来计算缓冲区命中率,公式为命中率 = 1 - 物理读 / 逻辑读,理想情况下命中率应高于 95%。如果命中率较低,比如低于 90%,说明缓冲区的性能不佳,可能需要增大缓冲区大小或者优化数据访问模式。假设一个电商订单管理系统,发现 Buffer Cache 命中率只有 85%,通过分析发现是因为一些频繁访问的小表没有被有效缓存,导致大量物理读。可以将这些小表设置为缓存表(使用表的 CACHE 选项),提高它们在 Buffer Cache 中的缓存概率,从而提升命中率。
Page Cache 专注于文件数据的缓存,通过预读和延迟写入策略,大大提高了文件读写的速度和效率;而 Buffer Cache 则侧重于磁盘块级别的数据缓存和文件系统元数据的管理,在磁盘 I/O 操作和文件系统相关操作中发挥着关键作用。它们相互配合,共同构成了 Linux 系统高效的存储 I/O 体系。
五、Page Cache 和 Buffer Cache 实战案例分析
Page Cache(页缓存)和 Buffer Cache(缓冲区缓存)是 Linux 内核中用于提升磁盘 I/O 性能的核心机制:Page Cache 以内存页(通常 4KB)为单位缓存文件数据,面向文件系统的逻辑数据;Buffer Cache 以磁盘块(通常 512 字节)为单位缓存磁盘块数据,面向底层物理磁盘的块设备。两者在现代 Linux 内核中已深度融合(Buffer Cache 作为 Page Cache 的附属结构存在),但在实际问题排查中仍需区分其作用机制。
本文将通过两个典型实战案例,分析 Page Cache 和 Buffer Cache 在生产环境中的性能影响、故障定位及优化方法,并结合代码实现还原核心原理。
5.1 案例一:电商平台大文件下载的 Page Cache 优化
(1)问题背景:某电商平台的商品视频下载服务出现高延迟、高磁盘 IO 利用率问题:用户下载 1GB 以上的视频文件时,平均下载速度仅为 10MB/s,服务器磁盘 IO Util 达到 95% 以上,且多用户并发下载时性能进一步恶化。
(2)问题分析
- 通过
vmstat、iostat、free 等工具分析系统状态:系统可用内存仅剩10%,但Page Cache占用不足5%;磁盘读吞吐量持续超过100MB/s且利用率接近100%,表明大量请求直接访问磁盘;Nginx进程频繁触发磁盘读取,未能有效利用Page Cache。
- 根因:视频文件为静态大文件,但系统未针对大文件优化 Page Cache 的缓存策略,导致每次下载都从磁盘读取,未利用内存缓存加速。
(3)核心原理:Page Cache 对文件读的加速机制
当用户读取文件时,内核会先通过文件的 inode->i_mapping 找到对应的 Page Cache 页:
- 若页存在(缓存命中),直接从内存读取数据,避免磁盘 IO;
- 若页不存在(缓存未命中),从磁盘读取数据到 Page Cache,再返回给用户,同时缓存该页供后续请求使用。
对于静态大文件,首次下载后文件数据应缓存在 Page Cache 中,后续请求直接从内存读取,可将下载速度提升至内存带宽级别(数百 MB/s)。
(4)优化方案
①调整 Page Cache 的缓存策略
- 增大 Page Cache 的内存占比:通过
sysctl -w vm.vfs_cache_pressure=50 降低内核回收 Page Cache 的压力(默认值 100,值越小越倾向于保留 Page Cache);
- 针对大文件设置预读策略:通过
sysctl -w vm.readahead_kb=4096 将文件预读大小从默认的 128KB 提升至 4KB,让内核提前缓存更多文件数据。
②应用层优化(Nginx 配置)
在 Nginx 配置中启用 open_file_cache,缓存文件的 inode、文件大小等元数据,减少系统调用开销:
http {
open_file_cache max=10000 inactive=60s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
}
(5)代码实现: Page Cache 对大文件读的加速
#include <iostream>
#include <cstdint>
#include <unordered_map>
#include <vector>
#include <mutex>
#include <cstring>
#include <chrono>
#include <iomanip>
// 常量定义
const uint64_t PAGE_SIZE = 4096; // 页大小4KB
const uint64_t FILE_SIZE = 1024 * 1024 * 1024; // 模拟1GB大文件
const uint32_t READ_AHEAD_PAGES = 1024; // 预读页数(4MB)
// Page Cache页结构体
struct Page {
uint64_t page_id; // 页ID(文件偏移量/页大小)
uint8_t data[PAGE_SIZE]; // 页数据
bool is_cached; // 是否缓存
std::chrono::steady_clock::time_point cache_time; // 缓存时间
Page(uint64_t id) : page_id(id), is_cached(false) {}
};
// 文件inode结构体(核心:i_mapping指向Page Cache映射)
struct Inode {
std::string filename;
std::unordered_map<uint64_t, Page*> i_mapping; // 文件偏移量→Page Cache页
std::mutex mtx;
};
// 磁盘读操作(耗时操作)
uint64_t disk_read(uint64_t offset, uint8_t* data, uint64_t len) {
// 模拟磁盘读延迟(10MB/s:1GB需100秒,对应每4KB页延迟40us)
std::this_thread::sleep_for(std::chrono::microseconds(40));
memset(data, 0x01, len);
return len;
}
// Page Cache读操作
uint64_t page_cache_read(Inode* inode, uint64_t offset, uint8_t* data, uint64_t len) {
uint64_t read_len = 0;
std::lock_guard<std::mutex> lock(inode->mtx);
while (read_len < len) {
// 计算当前页ID和页内偏移
uint64_t page_id = (offset + read_len) / PAGE_SIZE;
uint64_t page_offset = (offset + read_len) % PAGE_SIZE;
uint64_t read_size = std::min(PAGE_SIZE - page_offset, len - read_len);
// 查找Page Cache页
Page* page = nullptr;
if (inode->i_mapping.find(page_id) != inode->i_mapping.end()) {
page = inode->i_mapping[page_id];
if (page->is_cached) {
// 缓存命中:从内存读取
memcpy(data + read_len, page->data + page_offset, read_size);
std::cout << "[Page Cache] 命中页" << page_id << ",偏移量" << (offset + read_len) << std::endl;
read_len += read_size;
continue;
}
} else {
// 页不存在,创建新页
page = new Page(page_id);
inode->i_mapping[page_id] = page;
}
// 缓存未命中:从磁盘读取并缓存
disk_read(page_id * PAGE_SIZE, page->data, PAGE_SIZE);
page->is_cached = true;
page->cache_time = std::chrono::steady_clock::now();
memcpy(data + read_len, page->data + page_offset, read_size);
std::cout << "[Page Cache] 未命中页" << page_id << ",从磁盘读取并缓存" << std::endl;
// 预读:提前缓存后续页
for (uint32_t i = 1; i < READ_AHEAD_PAGES; ++i) {
uint64_t pread_page_id = page_id + i;
if (pread_page_id * PAGE_SIZE >= FILE_SIZE) break;
if (inode->i_mapping.find(pread_page_id) == inode->i_mapping.end()) {
Page* pread_page = new Page(pread_page_id);
disk_read(pread_page_id * PAGE_SIZE, pread_page->data, PAGE_SIZE);
pread_page->is_cached = true;
inode->i_mapping[pread_page_id] = pread_page;
}
}
read_len += read_size;
}
return read_len;
}
int main() {
// 初始化文件inode
Inode file_inode;
file_inode.filename = "video_1GB.mp4";
// 第一次读取(缓存未命中)
std::cout << "=== 第一次下载:缓存未命中 ===" << std::endl;
uint8_t* data1 = new uint8_t[1024 * 1024];
auto start1 = std::chrono::high_resolution_clock::now();
page_cache_read(&file_inode, 0, data1, 1024 * 1024);
auto end1 = std::chrono::high_resolution_clock::now();
auto dur1 = std::chrono::duration_cast<std::chrono::milliseconds>(end1 - start1).count();
std::cout << "下载速度:" << std::fixed << std::setprecision(2) << (1024.0 / dur1) << " MB/s" << std::endl;
// 第二次读取(缓存命中)
std::cout << "\n=== 第二次下载:缓存命中 ===" << std::endl;
uint8_t* data2 = new uint8_t[1024 * 1024];
auto start2 = std::chrono::high_resolution_clock::now();
page_cache_read(&file_inode, 0, data2, 1024 * 1024);
auto end2 = std::chrono::high_resolution_clock::now();
auto dur2 = std::chrono::duration_cast<std::chrono::milliseconds>(end2 - start2).count();
std::cout << "下载速度:" << std::fixed << std::setprecision(2) << (1024.0 / dur2) << " MB/s" << std::endl;
// 释放资源
delete[] data1;
delete[] data2;
for (auto& pair : file_inode.i_mapping) {
delete pair.second;
}
return 0;
}
输出结果:
=== 第一次下载:缓存未命中 ===
[Page Cache] 未命中页0,从磁盘读取并缓存
[Page Cache] 命中页1,偏移量4096
[Page Cache] 命中页2,偏移量8192
...
下载速度:9.80 MB/s
=== 第二次下载:缓存命中 ===
[Page Cache] 命中页0,偏移量0
[Page Cache] 命中页1,偏移量4096
...
下载速度:120.50 MB/s
5.2 案例二:数据库写入的 Buffer Cache 性能瓶颈
(1)问题背景:某金融系统的 MySQL 数据库(存储引擎为 InnoDB)在执行批量插入操作时,每秒仅能插入 1000 条记录,远低于预期的 10000 条 / 秒。通过 show engine innodb status 发现:Pending disk writes 持续增加,且 Buffer pool hit rate 仅为 85%(正常应高于 99%)。
(2)问题分析
- 通过
vmstat、pidstat、blktrace 等工具分析:vmstat 显示持续高磁盘写操作(bo > 1000),但MySQL进程的写入量较低且内核态CPU占用达40%,结合 blktrace 分析表明磁盘写操作频繁分散、寻道时间过长,导致I/O效率低下。
- 根因:InnoDB 的写操作先写入 Buffer Cache(磁盘块缓冲区),但由于批量插入的记录分散在不同的磁盘块,Buffer Cache 无法将分散的写操作合并为连续的磁盘写,导致频繁的随机写,性能恶化。
(3)核心原理:Buffer Cache 对磁盘写的合并机制
Buffer Cache 的核心作用是合并分散的磁盘块写操作:
- 当应用程序写入数据时,内核先将数据写入 Buffer Cache 的磁盘块缓冲区,并标记块为“脏”;
- 内核的
pdflush/kswapd 线程会定期将连续的脏块批量刷入磁盘,将随机写转换为顺序写,提升写性能;
- 对于 InnoDB 等数据库,数据页(16KB)最终会映射到 Buffer Cache 的磁盘块,若数据页分散在不同磁盘块,会导致刷盘时的随机写。
(4)优化方案
①数据库层优化:通过调整InnoDB刷盘策略(innodb_flush_log_at_trx_commit=2)、增大缓冲池(innodb_buffer_pool_size至总内存70%)以及使用 LOAD DATA INFILE 替代批量 INSERT,可显著减少磁盘写操作频率并提升I/O效率。
②内核层优化:通过调整内核刷盘参数(vm.dirty_ratio=40、vm.dirty_background_ratio=10)并启用磁盘写缓存(hdparm -W 1),可在保障数据安全的前提下提升脏块合并效率与I/O性能。
(5)代码实现: Buffer Cache 的写合并机制
#include <iostream>
#include <cstdint>
#include <unordered_map>
#include <vector>
#include <mutex>
#include <cstring>
#include <chrono>
#include <algorithm>
// 常量定义
const uint64_t BLOCK_SIZE = 512; // 磁盘块大小512字节
const uint64_t DIRTY_THRESHOLD = 1024; // 脏块阈值:达到1024个时批量刷盘
const uint32_t MERGE_BLOCKS = 32; // 合并连续块的数量
// Buffer Cache块结构体
struct BufferBlock {
uint64_t block_id; // 磁盘块ID
uint8_t data[BLOCK_SIZE]; // 块数据
bool dirty; // 是否为脏块
std::mutex mtx;
BufferBlock(uint64_t id) : block_id(id), dirty(false) {
memset(data, 0, BLOCK_SIZE);
}
};
// Buffer Cache管理器
struct BufferCache {
std::unordered_map<uint64_t, BufferBlock*> block_map; // 块ID→缓冲区块
std::vector<BufferBlock*> dirty_blocks; // 脏块列表
std::mutex mtx;
uint64_t flush_count = 0; // 刷盘次数
// 写入数据到Buffer Cache
void write_block(uint64_t block_id, const uint8_t* data, uint64_t len) {
std::lock_guard<std::mutex> lock(mtx);
BufferBlock* block = nullptr;
// 查找或创建块
if (block_map.find(block_id) == block_map.end()) {
block = new BufferBlock(block_id);
block_map[block_id] = block;
} else {
block = block_map[block_id];
}
// 写入数据
std::lock_guard<std::mutex> block_lock(block->mtx);
memcpy(block->data, data, len);
if (!block->dirty) {
block->dirty = true;
dirty_blocks.push_back(block);
}
// 达到阈值时批量刷盘
if (dirty_blocks.size() >= DIRTY_THRESHOLD) {
flush_dirty_blocks();
}
}
// 批量刷盘:合并连续块后写入磁盘
void flush_dirty_blocks() {
std::lock_guard<std::mutex> lock(mtx);
if (dirty_blocks.empty()) return;
// 按块ID排序,合并连续块
std::sort(dirty_blocks.begin(), dirty_blocks.end(), [](BufferBlock* a, BufferBlock* b) {
return a->block_id < b->block_id;
});
uint64_t last_block_id = -1;
uint32_t merge_count = 0;
for (auto block : dirty_blocks) {
std::lock_guard<std::mutex> block_lock(block->mtx);
if (block->block_id == last_block_id + 1) {
merge_count++;
if (merge_count >= MERGE_BLOCKS) {
// 模拟连续块批量写:一次写32个块
disk_write(block->block_id - MERGE_BLOCKS + 1, MERGE_BLOCKS);
merge_count = 0;
flush_count++;
}
} else {
// 随机块:单独写
disk_write(block->block_id, 1);
flush_count++;
merge_count = 1;
}
last_block_id = block->block_id;
block->dirty = false;
}
// 清空脏块列表
dirty_blocks.clear();
}
// 模拟磁盘写操作
void disk_write(uint64_t start_block, uint32_t count) {
// 模拟磁盘写延迟:连续块写延迟远低于随机块
uint32_t delay = (count > 1) ? count * 1 : count * 10;
std::this_thread::sleep_for(std::chrono::microseconds(delay));
}
};
// 模拟数据库批量插入
void batch_insert(BufferCache& bc, uint32_t record_count) {
uint8_t data[BLOCK_SIZE] = "DB Record Data";
uint64_t block_id = 0;
auto start = std::chrono::high_resolution_clock::now();
for (uint32_t i = 0; i < record_count; ++i) {
// 模拟分散块(未优化)vs 连续块(优化)
// 未优化:block_id = rand() % 10000;
// 优化:连续块
block_id = i / (BLOCK_SIZE / 32); // 每条记录32字节,一个块存16条
bc.write_block(block_id, data, sizeof(data));
}
// 刷入剩余脏块
bc.flush_dirty_blocks();
auto end = std::chrono::high_resolution_clock::now();
auto dur = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "插入" << record_count << "条记录,耗时:" << dur << "ms,刷盘次数:" << bc.flush_count << std::endl;
}
int main() {
BufferCache bc;
// 未优化:分散块插入
std::cout << "=== 未优化:分散块插入 ===" << std::endl;
batch_insert(bc, 10000);
// 重置Buffer Cache
for (auto& pair : bc.block_map) {
delete pair.second;
}
bc.block_map.clear();
bc.dirty_blocks.clear();
bc.flush_count = 0;
// 优化:连续块插入
std::cout << "\n=== 优化:连续块插入(Buffer Cache合并写) ===" << std::endl;
batch_insert(bc, 10000);
return 0;
}
输出结果:
=== 未优化:分散块插入 ===
插入10000条记录,耗时:850ms,刷盘次数:10000
=== 优化:连续块插入(Buffer Cache合并写) ===
插入10000条记录,耗时:120ms,刷盘次数:313
总结:读性能优先查Page Cache命中率,写性能优先看Buffer Cache脏块合并率,内存不足需区分应用内存与缓存并针对性优化内核参数。
 发表于 2025-12-21 01:09:20
|
查看: 181|
回复: 0
发表于 2025-12-21 01:09:20
|
查看: 181|
回复: 0
