
《Python工匠》是一本专注于提升Python代码质量的进阶读物,尤其适合希望强化编码能力的开发者。本书第一章聚焦于代码的“门面”——变量与注释,它们是代码中最接近自然语言的部分,直接决定了代码的可读性与可维护性。
《Python 工匠》简介
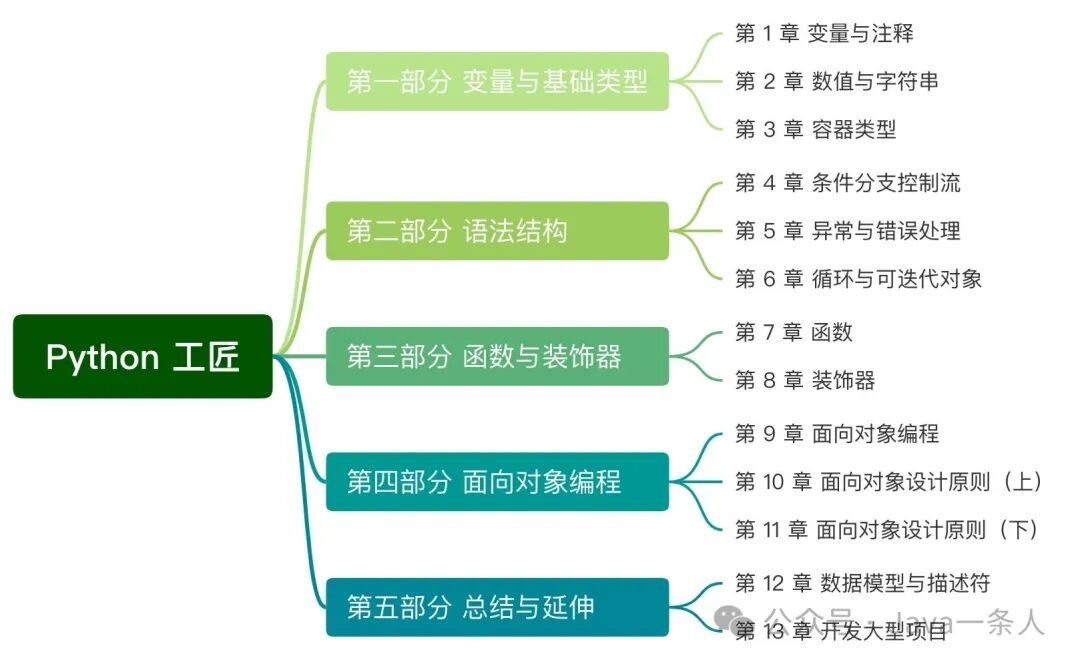
本书作者朱雷(piglei)拥有十余年后端开发与架构设计经验。全书分为五大部分共13章,结构清晰。除第10章与第11章外,其余章节内容独立,读者可按兴趣选读。每章均包含三大板块:基础知识、案例故事与编程建议。
在深入学习前,建议准备以下工具:
- 命令行工具(已安装Python3),推荐使用Warp。
- IDE,推荐使用PyCharm。
1. 基础知识
1.1. 变量
声明和赋值
Python作为动态类型语言,无需预先声明变量类型,可直接赋值。
>>> author = 'piglei'
>>> author
'piglei'
Python支持一行内同时操作多个变量,例如交换两个变量的值,这一特性在排序算法实现中非常有用。
>>> author, reader = 'piglei', 'Java一条人'
>>> author, reader = 'Java一条人', 'piglei'
>>> author
'Java一条人'
>>> reader
'piglei'
解包
变量解包允许我们将一个可迭代对象的所有成员一次性赋值给多个变量。
>>> usernames = ['piglei', 'raymond']
>>> author, reader = usernames
>>> author
'piglei'
>>> reader
'raymond'
使用星号表达式(*variables)可以进行动态解包,贪婪地捕获多个值。
>>> data = ['piglei', 'apple', 'orange', 'banana', 100]
>>> username, *fruits, score = data
>>> username
'piglei'
>>> fruits
['apple', 'orange', 'banana']
>>> score
100
单下划线变量名
单下划线 _ 常作为无意义的占位符,用于忽略某些变量。
# 解包时忽略第二个变量
>>> author, _ = usernames
# 解包时忽略中间所有变量
>>> username, *_, score = data
在Python交互式命令行中,_ 默认保存上一个表达式的返回值。
给变量注明类型
为解决动态类型带来的可读性问题,可采用类型注解。
from typing import List
def remove_invalid(items: List[int]):
""" 剔除 items 里面无效的元素
:param items: 待删除的对象
:return:
"""
提示:List是typing模块提供的类型注解工具。Python 3.9开始,内置的list也支持泛型语法,可优先使用list[int]。
添加类型注解能提升代码可读性、获得更智能的IDE提示、并方便进行静态类型检查。
变量命名原则
- 遵循PEP 8:普通变量使用蛇形命名法(
snake_case),常量使用全大写(MAX_VALUE),内部使用变量加下划线前缀(_local_var),避免与关键字冲突可加下划线后缀(class_)。
- 描述性要强:在合理长度内,变量名应尽可能精确描述其内容,例如
file_chunks优于data。
- 要尽量短:命名需结合上下文,在已知情境下可使用较短但明确的名称。
- 要匹配类型:
bool类型常用is_、has_开头。int/float类型常用port、age、user_id、max_length、user_count等。- 避免使用名词复数表示数量,易与列表类型混淆。
- 超短命名:在约定俗成的场景下可使用,如索引
i, j, k、整数n、字符串s、异常e等,但应优先使用更精确的名称。
1.2. 注释
Python注释主要包括代码内注释(#)和函数文档字符串。
# 用户输入可能会有空格,使用 strip 去掉空格
username = extract_username(input_string.strip())
class Person:
"""人
:param name: 姓名
:param age: 年龄
:param favorite_color: 最喜欢的颜色
"""
def __init__(self, name, age, favorite_color):
self.name = name
self.age = age
self.favorite_color = favorite_color
用注释重复代码
注释应提供代码之外的信息,解释“为什么”这么做,而非简单复述代码。
不佳示例:
# 调用 strip() 去掉空格
input_string = input_string.strip()
良好示例:
# 如果直接把带空格的输入传递到后端处理,可能会造成后端服务崩溃
# 因此使用 strip() 去掉首尾空格
input_string = input_string.strip()
指引性注释
这种注释概括代码块功能,充当“代码导读”。但当逻辑可以提炼为独立函数时,应优先使用有意义的函数名。
使用指引性注释:
# 初始化访问服务的 client 对象
token = token_service.get_token()
service_client = ServiceClient(token=token)
service_client.ready()
优化为函数调用(更佳):
service_client = make_client()
弄错接口注释的受众
接口文档应面向函数使用者,着重描述功能、参数和返回值,而非内部实现细节。实现细节应放在函数内部的代码注释中。
2. 案例故事
面试题:实现“魔法冒泡排序”,规则是所有偶数都比奇数大。
>>> numbers = [23, 32, 1, 3, 4, 19, 20, 2, 4]
>>> magic_bubble_sort(numbers)
[1, 3, 19, 23, 2, 4, 4, 20, 32]
一个初级实现可能功能正确但可读性差。优化版本通过以下改进显著提升了代码质量:
- 使用有意义的变量名(如
stop_position, should_swap)。
- 引入解释性临时变量(如
current_is_even)。
- 添加指引性注释阐明交换条件。
- 代码逻辑更清晰,易于理解。
3. 编程建议
3.1. 保持变量的一致性
保持变量命名和类型的一致性。不要将同一个变量名重复用于指向不同类型的对象。
3.2. 变量定义尽量靠近使用
避免在函数开头集中定义所有变量。应将变量定义移动到实际使用它的代码块附近,缩短“定义”与“使用”的距离,提升可读性。
3.3. 定义临时变量提升可读性
将复杂的条件表达式赋值给一个具有描述性的临时变量,可以大大提高代码的可读性。
# 优化前
if user.is_active and (user.sex == 'female' or user.level > 3):
...
# 优化后
user_is_eligible = user.is_active and (user.sex == 'female' or user.level > 3)
if user_is_eligible:
...
3.4. 同一作用域内不要有太多变量
函数内变量过多通常意味着函数过于复杂、承担了太多职责。解决方法是:
- 分组建模:使用数据类(如
dataclass)或简单类将相关变量组织起来。
- 拆分函数:这是降低复杂度的根本方法,将大函数拆分为多个职责单一的小函数。
3.5. 能不定义变量就别定义
不要为了未来可能但不确定的变动而预先定义变量,这可能会牺牲代码当下的简洁性和可读性。
3.6. 不要使用 locals()
避免使用locals()来收集变量进行传递(例如在Web框架中渲染模板时)。虽然这样做代码看似简洁,但违反了“显式优于隐式”的原则,会隐藏实际依赖的变量,大幅降低代码可读性。
3.7. 空行也是一种注释
恰当地使用空行来区分不同逻辑代码块,可以有效提升代码的视觉结构和可读性。
3.8. 先写注释,后写代码
在编写函数体之前,先写好函数接口注释。这能迫使你思考函数的单一职责,并确保不会遗漏重要的文档。如果你无法用几句注释清楚描述函数功能,那么这个函数可能就需要重新设计。养成这个习惯能从根本上提升后端代码的设计质量。
 发表于 2025-12-21 02:19:34
|
查看: 168|
回复: 0
发表于 2025-12-21 02:19:34
|
查看: 168|
回复: 0
