

本文将围绕GPU的10个核心知识点展开,首先对比GPU与CPU的架构差异,然后明确GPU与显卡的概念区别以及集成/独立显卡的分类。接着,我们将介绍GPGPU的定义、特点及其与传统GPU的不同,并细分消费级、专业级和数据中心级三类GPU卡。
此外,文章还会分析涡轮散热卡与风扇散热卡、公版与非公版显卡的区别,对比PCIe卡与SXM卡的规格参数及应用场景。最后,会说明NVIDIA HGX与DGX系列产品的关联,NVLink与NVSwitch互联技术的作用,以及A800、H800在特定参数上的调整情况,力求全面覆盖GPU的核心知识体系。
1. GPU vs CPU:核心架构差异
CPU(中央处理器)设计追求的是低延迟(Low Latency),擅长快速处理复杂的串行任务。其核心数量较少(通常为几个到几十个),但每个核心都非常强大,拥有大量的缓存(Cache)和控制单元,能够高效处理分支预测、乱序执行等复杂逻辑。
GPU(图形处理器)的设计目标则是高吞吐量(High Throughput),专为处理大规模并行计算任务而生。它拥有成千上万个精简的计算核心(Streaming Processors或CUDA Cores),这些核心结构相对简单,缓存较小,但通过数量优势,能够同时对海量数据(如图像像素、矩阵元素)执行相同的简单操作。
简单比喻:CPU像是一位博学多才的教授,能快速解答各种复杂难题;而GPU则像是一支庞大的学生军队,每人只做一道简单的算术题,但整体效率极高。
2. GPU 与显卡:概念辨析
GPU是一个具体的芯片,是执行图形和并行计算任务的核心处理器。
显卡(Graphics Card)则是一个完整的硬件板卡。它通常包含:
- GPU芯片:计算核心。
- 显存(VRAM):为GPU提供高速数据存储。
- 散热系统:如风扇或散热鳍片。
- 电源电路(PCB):为GPU和显存供电。
- 视频输出接口:如HDMI, DisplayPort。
因此,GPU是显卡上最核心的部件,但二者不能完全等同。
3. 集成显卡 vs 独立显卡
集成显卡(Integrated Graphics):
- GPU核心被集成在CPU芯片内部或主板芯片组中。
- 共享系统主内存作为显存,带宽和容量受限。
- 功耗低,发热小,成本低。
- 性能一般,适用于日常办公、高清视频播放和轻度游戏。
独立显卡(Discrete Graphics Card):
- 独立的板卡,通过PCIe插槽与主板连接。
- 拥有独立的GPU芯片和专用的高速GDDR显存。
- 性能强大,功耗和发热较高,成本也高。
- 适用于大型3D游戏、专业图形设计、科学计算和人工智能与深度学习等重度负载场景。对于需要进行大规模并行计算的开发者,掌握Python及其相关科学计算库是高效利用GPU资源的关键。
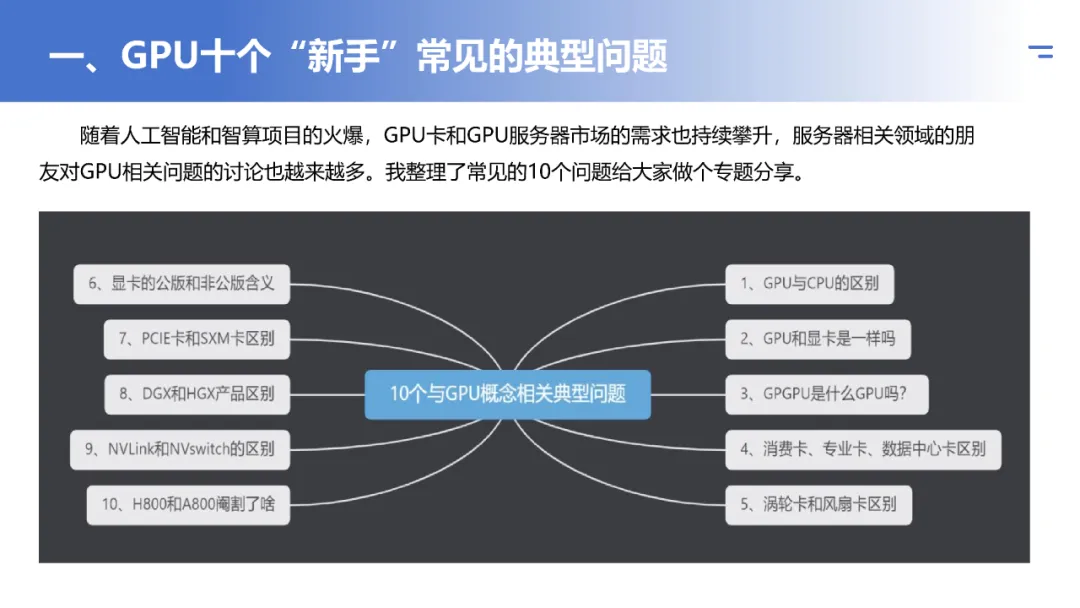
4. GPGPU:通用图形处理器计算
GPGPU(General-Purpose computing on Graphics Processing Units) 是指利用GPU原本为图形处理设计的大规模并行架构,来执行非图形渲染的通用计算任务。
- 传统GPU:固定功能的图形渲染管线,专为处理顶点、纹理、像素等图形数据优化。
- GPGPU:通过如CUDA、OpenCL等编程模型,将GPU暴露为通用的并行计算设备。程序员可以编写核函数(Kernel),让成千上万的线程同时处理科学模拟、数据分析、密码破译、AI模型训练等任务。
正是GPGPU概念的兴起,使得GPU从单纯的游戏和图形工作站设备,转变为现代人工智能和高性能计算(HPC)的基石。
5. GPU产品分类:消费卡、专业卡、数据中心卡
根据应用场景和优化目标,GPU产品主要分为三类:
消费级显卡(Geforce系列):
- 目标市场:游戏玩家、普通消费者。
- 特点:针对游戏帧率(FPS)优化,性价比高。
- 驱动:Game Ready驱动,为热门游戏提供优化。
- 代表:NVIDIA RTX系列,AMD Radeon RX系列。
专业级显卡(Quadro / RTX系列):
- 目标市场:CAD/CAM/CAE设计、媒体内容创作(DCC)、科学研究可视化。
- 特点:注重渲染精度、稳定性、支持专业API(如OpenGL),通常配备ECC显存。
- 驱动:Studio或专业版驱动,经过ISV(独立软件供应商)认证。
- 代表:NVIDIA RTX A系列。
数据中心/计算卡(Tesla系列):
- 目标市场:人工智能训练与推理、高性能计算、数据中心。
- 特点:极致计算性能(FP64/FP32/Tensor Core),高显存带宽和容量,支持NVLink高速互联,通常采用被动散热(需机箱风道配合)。
- 驱动:专为数据中心环境优化的驱动。
- 代表:NVIDIA A100, H100, AMD Instinct MI系列。

6. 涡轮卡 vs 风扇卡(鼓风机 vs 开放式散热)
涡轮散热(Blower Style):
- 单个离心风扇,将冷空气从显卡前端吸入,加热后通过显卡尾部的挡板排到机箱外。
- 优点:热量直接排出机箱,不影响机箱内其他部件(如CPU)的散热,适合多卡并联或空间紧凑的机箱。
- 缺点:散热效率相对较低,噪音通常较大。
风扇散热(Open-Air / Axial Fan):
- 多个轴流风扇,将冷空气吹向散热鳍片,热量在机箱内部扩散,依靠机箱风道排出。
- 优点:散热效率高,噪音相对较小(在良好风道下)。
- 缺点:热空气排在机箱内,对机箱整体风道要求高,多卡并联时上层卡会吸入下层卡排出的热风,导致散热效率下降。
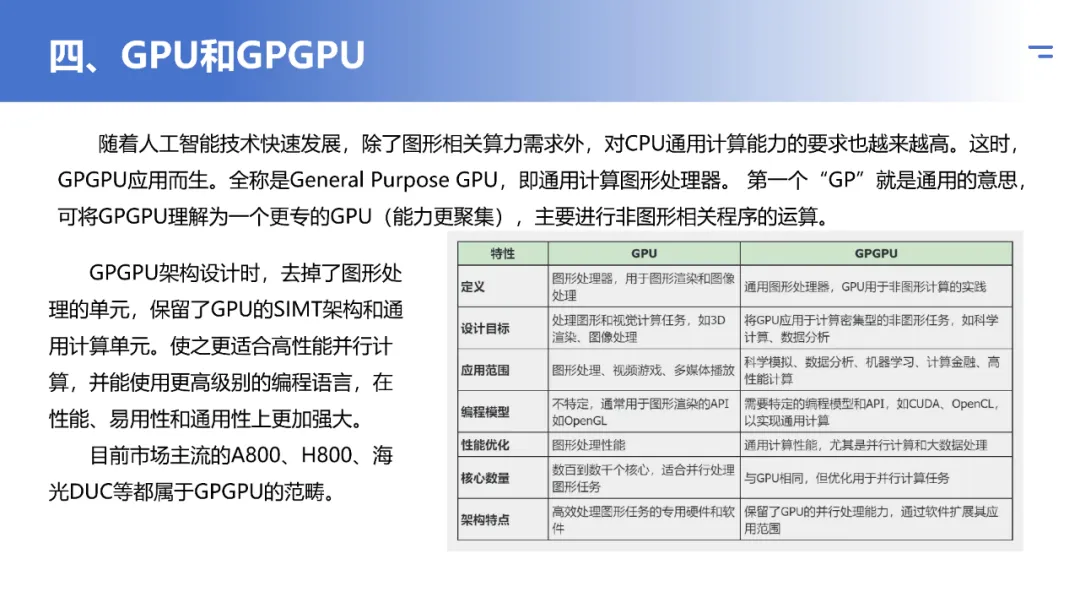
7. 公版 vs 非公版
公版显卡(Reference Card):
- 由GPU芯片制造商(如NVIDIA、AMD)亲自设计或提供基础设计方案。
- 旨在定义该GPU芯片的标准规格和外观,确保稳定性和兼容性。
- 通常首发上市,用料和散热设计相对保守。
非公版显卡(Non-Reference / AIB Card):
- 由合作伙伴(如华硕、微星、技嘉等AIC厂商)基于公版设计进行再设计。
- 可能在PCB电路、供电相数、散热器(三风扇、水冷)、核心频率(超频版)、外观灯效等方面进行强化或改动。
- 选择多样,能满足不同用户对性能、静音、外观的特定需求。

8. PCIe卡 vs SXM模块卡
PCIe卡:
- 标准形态,通过PCIe插槽与服务器/工作站主板连接。
- 通用性强,兼容绝大多数标准服务器。
- 功耗受限于PCIe插槽供电(通常最高300W,外加外接供电)。
- 代表:绝大多数消费级、专业级和部分数据中心级显卡。
SXM模块卡:
- 专用形态,不包含PCIe金手指,通过特殊的SXM插座垂直插入专用主板。
- 通常用于NVIDIA的高端数据中心GPU(如A100, H100的SXM版本)。
- 优点:提供远超PCIe的供电能力(高达700W),支持更高的GPU功耗和性能释放;通常与NVLink高速互联紧密结合,带宽更高。
- 缺点:必须使用特定的服务器平台(如NVIDIA HGX)。
9. HGX与DGX平台
HGX:
- 是NVIDIA设计的GPU服务器基板参考架构。
- 像一块“主板”,其上可以搭载多个SXM形态的GPU(如4卡或8卡),并通过NVSwitch实现所有GPU间全互联的高带宽通信。
- HGX板卡提供给服务器制造商(如戴尔、惠普、联想、超微),由他们整合成完整的服务器系统出售。
DGX:
- 是NVIDIA自主研发的完整AI超级计算机系统。
- 其核心就是基于HGX基板,并整合了CPU、内存、高速存储、网络以及优化的软件栈(如预装驱动、CUDA、深度学习框架)。
- 代表:DGX A100, DGX H100。DGX是开箱即用的企业级AI计算平台。
简单说,HGX是“核心主板”,DGX是包含这块主板的“品牌整机”。
10. NVLink, NVSwitch与特定型号解析
NVLink:
- NVIDIA开发的高速GPU间互联技术,用于替代传统的PCIe进行多卡通信。
- 带宽远高于PCIe(例如NVLink 4.0可达900GB/s,而PCIe 5.0 x16为~128GB/s)。
- 允许GPU直接访问彼此显存,对于需要大规模显存的应用(如大模型训练)至关重要。
NVSwitch:
- 可以理解为一个用于连接多个GPU的“网络交换机”芯片。
- 在8卡或更多GPU的配置中,它允许所有GPU两两之间以NVLink全带宽互联,形成一个高速通信网络,避免多卡通信时的带宽瓶颈。
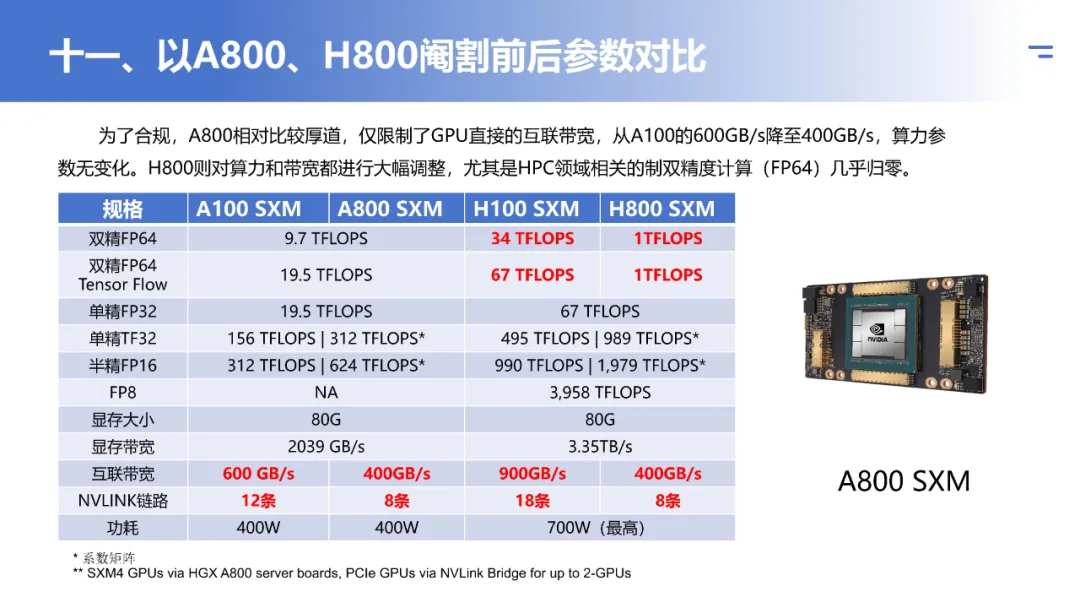
A800与H800:
- 这两款是中国市场特供的数据中心GPU型号,分别基于A100和H100。
- 主要的调整在于NVLink互联带宽被降低至符合相关出口管制规定。例如,A100的NVLink带宽为600GB/s,而A800降至400GB/s。
- GPU本身的核心计算性能(如FP64, Tensor Core)在初期版本中保持不变,但互联带宽的削减会影响多卡并行训练超大模型时的扩展效率。在构建大规模AI训练集群时,这类硬件间的网络通信性能是需要重点考量的因素。

(GPU核心架构示意图)

(不同形态GPU产品对比)
(NVLink高速互联示意图)

(HGX服务器基板架构)

(DGX AI超级计算机系统)

(PCIe与SXM形态对比)
(涡轮与风扇散热原理对比)
|  发表于 2025-12-21 18:23:48
|
查看: 246|
回复: 0
发表于 2025-12-21 18:23:48
|
查看: 246|
回复: 0
