Kafka消息堆积,本质上是生产者端的消息生成速率持续高于消费者端的处理能力所导致的结果,而非Kafka服务本身宕机。要有效解决这一问题,需要从多个维度进行系统性优化。
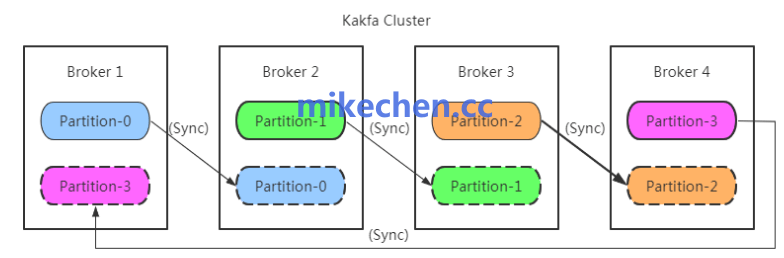
1. 增强消费者处理能力
提升消费端的吞吐量是应对堆积最直接的方法,具体策略包括:
- 横向扩展:增加消费者实例数量,通过扩容消费组来提升并行处理能力。需要注意的是,消费组的并行度上限由Topic的分区数决定,因此增加消费者数量的前提是拥有足够的分区。
- 纵向优化:
- 优化业务逻辑:精简消费者应用的处理代码,减少不必要的计算或I/O开销。
- 采用批量/异步处理:在业务允许的情况下,将单条处理改为批量处理,或使用异步非阻塞方式提升效率。
- 调整消费者配置:适当增大
fetch.min.bytes(获取最小字节数)或 max.partition.fetch.bytes(每分区最大获取字节数),并合理设置 max.poll.records(单次拉取最大记录数)与 max.poll.interval.ms(拉取间隔),以提升单次拉取的效率。
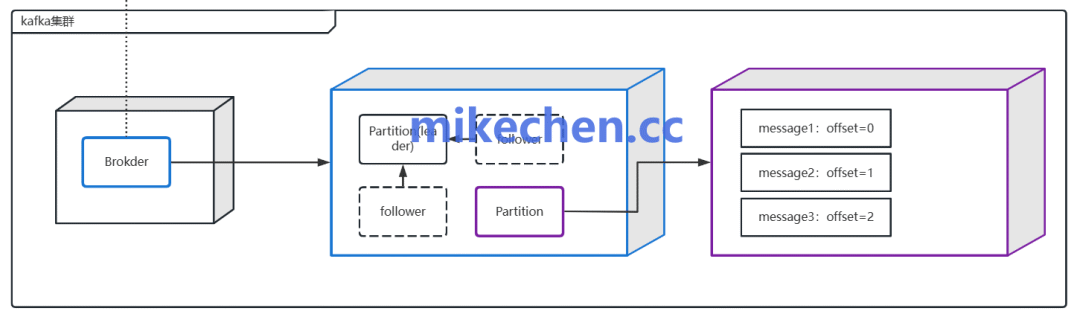
2. 增加Topic分区数
Kafka的消费并行度根本上是受分区数量制约的。当消费者实例数已接近或等于分区数时,继续增加消费者将无效。此时,最有效的手段是增加Topic的分区数。
例如,将Topic的Partition数量从10个扩展到30个,理论上消费组的最大并行度即可提升至30。
在进行分区扩容等操作时,也需同步关注Kafka集群本身的健康度与配置合理性。应检查并优化诸如副本因子、日志段大小(segment.bytes)、保留策略等核心参数。同时,对于生产环境中的Kafka集群,密切监控磁盘I/O、网络带宽及JVM GC情况至关重要,必要时需要扩容Broker节点或升级硬件,从根源上消除性能瓶颈。
3. 实现流控与背压机制
面对突发的流量洪峰,在消息链路上设计流控和背压机制,可以有效避免系统被瞬间压垮。
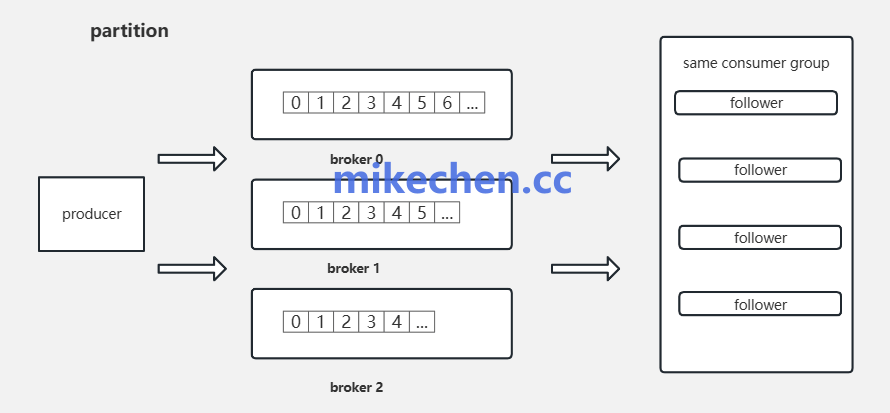
- 生产者端限流:在消息生产者处实施速率控制,平滑写入流量,避免短时高峰冲击Broker。
- 智能化重试:为生产者配置带有退避(Backoff)策略的重试机制,在网络波动或Broker短暂压力大时自动延缓发送。
- 消费者背压:在消费者端根据自身处理能力动态调整消费速率,并将压力反馈至上游,这是一种重要的云原生架构设计模式。
- 引入缓冲层:在上下游之间加入缓冲层,如使用Redis、内存队列或临时的Kafka Topic,以削峰填谷,隔离上下游的速度差异。
4. 优化消息策略与容量规划
从消息生命周期和系统容量的角度进行治理,可以防患于未然。
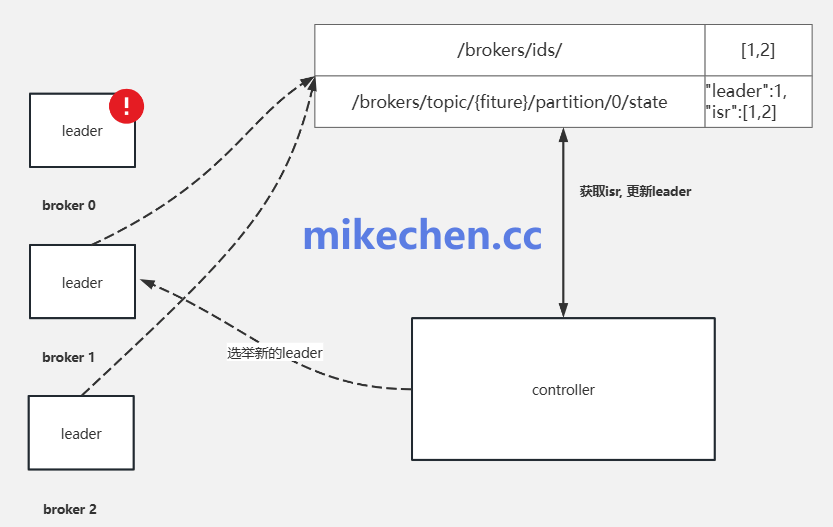
- 消息降级与清理:对非关键业务数据或已过时的历史数据,制定降级策略,如进行压缩、合并归档,或在极端情况下直接丢弃,以释放存储和计算资源。
- 均衡分区负载:设计合理的消息键(Key),确保数据能均匀分布到各个分区,避免产生“热点分区”。对于已存在的热点分区,可考虑进行数据迁移或重建Topic。
- 前瞻性容量规划:定期基于业务增长趋势和峰值流量进行容量评估与压力测试,预留充足的集群资源(包括磁盘、CPU、网络带宽等)。这属于高效的运维与SRE实践范畴,是保障系统长期稳定运行的基础。
|  发表于 2025-12-21 21:39:44
|
查看: 285|
回复: 0
发表于 2025-12-21 21:39:44
|
查看: 285|
回复: 0
