在Linux内核的网络层或图形处理等场景中,常会涉及大量的 dma_map_sg()、dma_unmap_sg()、dma_sync_sg_for_device() 和 dma_sync_sg_for_cpu() 操作。若硬件本身不支持 DMA 一致性(dma-coherence),则需由 CPU 执行大量的缓存失效(cache invalidate)和清理(clean)操作。这一过程极其耗时,在频繁使用 DMA 缓冲区的场景下,往往成为性能剖析火焰图中的热点,并导致显著的图形处理延迟。遗憾的是,许多硬件设备确实不具备此特性。
在 arm64 体系架构下,当发出针对数据缓存(dc)的操作指令后,实际上可以通过 dsb 指令来批量等待所有操作完成。这一点在 ARM 架构规范中有明确说明:

这意味着,不仅可以批量处理 TLB 无效化(tlbi),缓存同步操作同样可以进行批量化处理。
关于 TLB 的批量处理,笔者此前已在 Linux 主线内核中解决了内存回收与迁移时的批量 TLB 无效化问题,相关提交为:
arm64: support batched/deferred tlb shootdown during page reclamation/migration
(https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=43b3dfdd04553171488cb11d46d21948b6b90e27)
现在,是时候解决缓存同步的批量处理问题了。当前 Linux 内核的实现存在优化空间。例如,对于一个包含上万个条目(entry)的散列表(scatterlist),现有实现是为每个条目执行一次操作并等待一次。我们完全可以改为批量模式:为上万个条目连续发出所有的缓存 dc 指令,最后仅通过一次 dsb 指令进行同步等待。
在笔者提交的 [PATCH 0/6] dma-mapping: arm64: support batched cache sync 补丁集中,为 arm64 平台新增了三个回调函数:
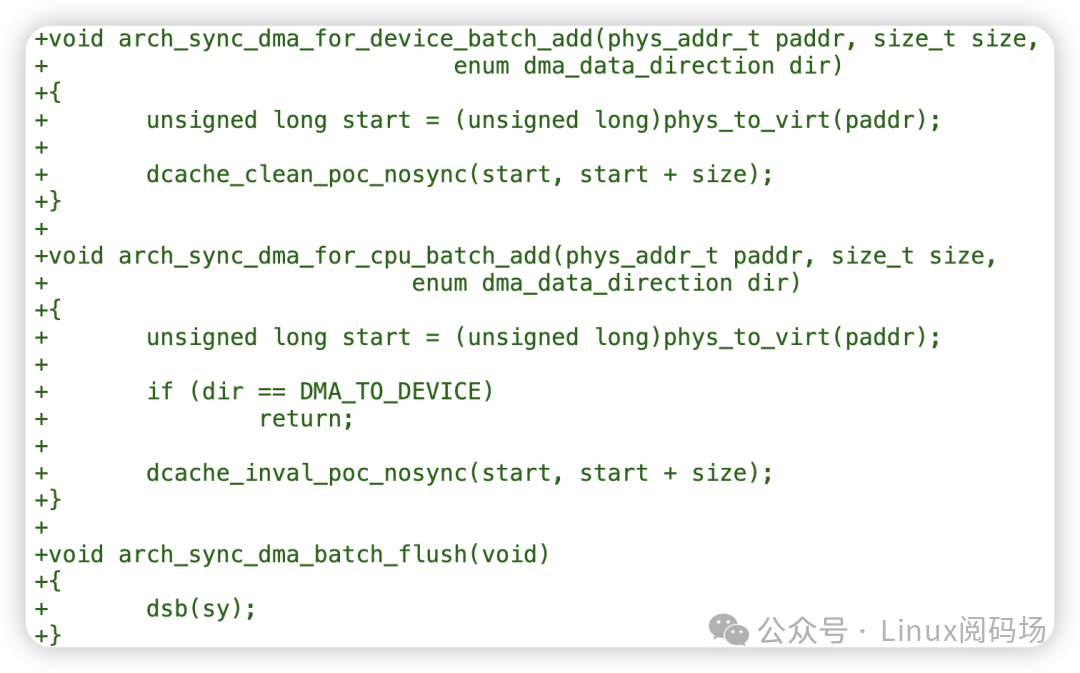
当 DMA 映射核心层检测到架构支持批量 DMA 同步后,便会采用批量操作。处理前面的 N 个散列表条目时均使用批量模式,在最终完成时调用一次 sync_dma_batch_flush()。
具体示例:
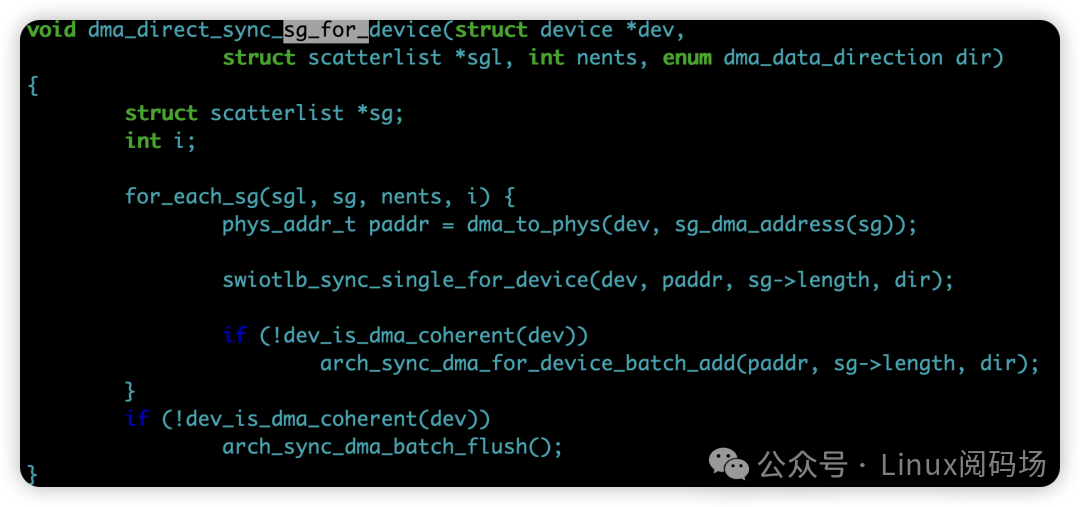
该补丁集共包含 6 个补丁,其中大部分涉及 arm64 汇编代码的修改:

堂权测试结果显示:在 MTK 天玑 9500 平台上,dma_map_sg() 的执行时间减少了 64.61%,而 dma_unmap_sg() 的执行时间减少了 66.60%。
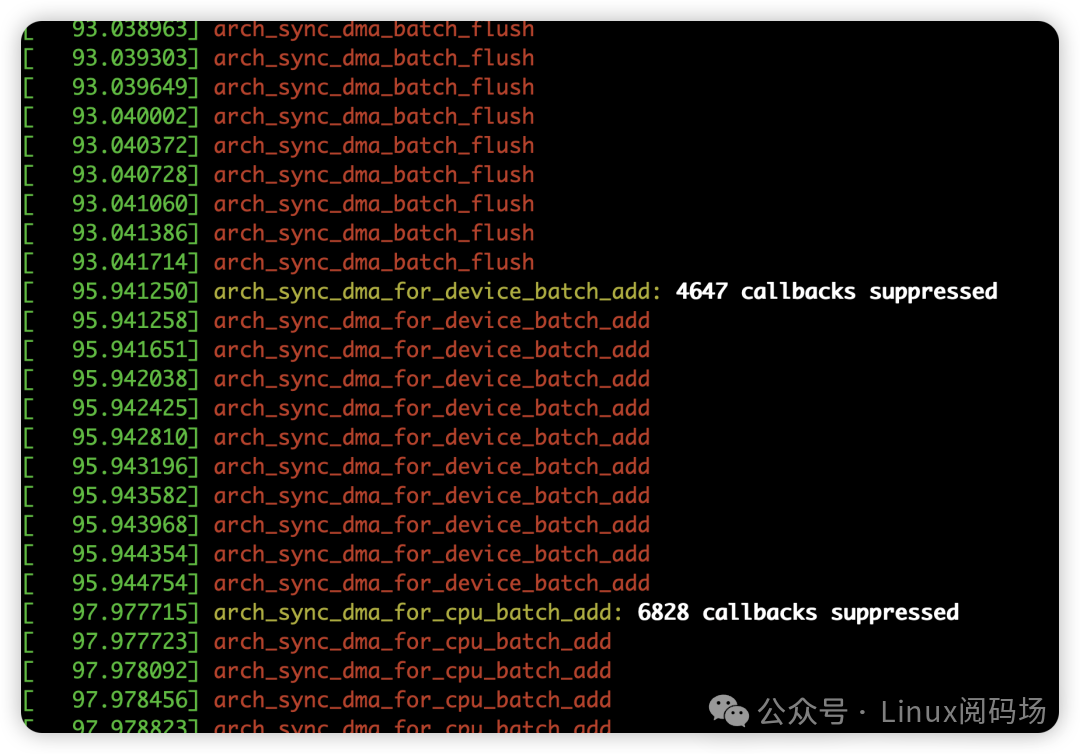
Rockchip RK3588 平台(Rock 5B+)也提供了有力验证。将补丁集运行在最新的 Linux 6.19-rc1 内核上,可以观察到大量的 DMA 缓存同步操作被成功批量处理:
编译方法是将补丁文件放入 Armbian 的 userpatch 目录:

随后执行编译命令:
./compile.sh BOARD=rock-5b-plus BRANCH=edge KERNELSOURCE='https://github.com/torvalds/linux' KERNELBRANCH='branch:master' kernel
补丁集链接:https://lore.kernel.org/lkml/CAGsJ_4yKeUHgxRJJHiOcdaVcV1pjeHRjbybvEs5YLm=AJoe-Dw@mail.gmail.com/
目前,第 6 个补丁 dma-iommu: Allow DMA sync batching for IOVA link/unlink 因缺少相关硬件进行测试,已被标记为 RFC(请求评论),欢迎拥有对应硬件的开发者协助测试。
至此,笔者的三个补丁集分别针对 DMA 缓冲区的 mmap、vmap 和缓存同步进行了优化,构成了一个相对完整的 DMA 缓冲区优化链:
-
mmap 潜在提速 35 倍:该优化已合入内核主线。
-
vmap 潜在提速 17 倍:该优化已进入 mm-new 分支进行迭代。
-
DMA 缓存同步潜在提速 3 倍:即本文介绍的补丁集。
 发表于 2025-12-22 01:11:59
|
查看: 292|
回复: 0
发表于 2025-12-22 01:11:59
|
查看: 292|
回复: 0
