将SQL查询转换为向量嵌入,以便精确地聚类、比较和分析数据湖中的行为
在数据工程领域,一个反复出现的挑战是了解用户如何与数据湖交互。有些用户遵循最佳实践,编写高效的查询,避免扫描不必要的数据——这有助于控制AWS Athena等引擎的成本。而另一些用户则可能编写低效或重复的查询。这时,了解用户如何编写查询、如何搜索、过滤和访问数据就变得至关重要。这引出了一个核心问题:我们如何量化地测量两个SQL查询之间的差异?
对于数字,计算差值很简单。但当处理的是文本,尤其是SQL语句时,直接相减是行不通的。那么,以下两个查询之间的距离是多少?
SELECT * FROM datalake_x
和
SELECT name FROM datalake_y
嵌入技术:将文本转换为数值向量
这正是嵌入技术所能够实现的。“向量嵌入”将文本转换为高维空间中的数值向量。一旦完成这种转换,SQL查询就变成了向量空间中的点,使得各种数学操作成为可能:
- 测量查询之间的距离或相似度
- 查找语义上相似的查询
- 按查询意图或模式进行自动聚类分组
- 检测异常的或低效的查询模式
- 可视化查询之间的整体关系
因为嵌入过程会捕获文本的深层语义信息,所以“感觉”上相似的查询在向量空间中也会更接近。
环境准备与依赖安装
本项目基于 Python 实现,您需要以下环境:
- Python 3.6+
- chromadb
- sentence-transformers
- numpy
- scikit-learn
- matplotlib
使用 pip 一键安装所有依赖:
pip install -U chromadb sentence-transformers numpy scikit-learn matplotlib
我们将从一个 CSV 文件开始,该文件包含一列(query)SQL查询。以下是一个示例数据集:
query
"SELECT * FROM datalake_x"
"SELECT name FROM datalake_y"
"SELECT id, name FROM users WHERE active = 1;"
"SELECT COUNT(*) FROM orders WHERE order_date >= '2023-01-01';"
"SELECT u.id, u.name, o.total FROM users u JOIN orders o ON u.id = o.user_id WHERE o.total > 100;"
"WITH recent_orders AS (SELECT * FROM orders WHERE order_date > CURRENT_DATE - INTERVAL '30 days') SELECT user_id, COUNT(*) FROM recent_orders GROUP BY user_id;"
"UPDATE users SET last_login = NOW() WHERE id = 123;"
"INSERT INTO audit_log (user_id, action, created_at) VALUES (456, 'login', NOW());"
"DELETE FROM sessions WHERE expires_at < NOW();"
"SELECT name, AVG(rating) as avg_rating FROM reviews GROUP BY name HAVING AVG(rating) > 4.5;"
使用 ChromaDB 存储和检索查询向量
首先,我们初始化 ChromaDB 客户端并创建一个用于存储查询向量的集合。ChromaDB 作为一个轻量级的向量数据库,非常适合存储和检索文档嵌入。
def setup_chroma_db():
"""初始化ChromaDB客户端和集合"""
import chromadb
client = chromadb.Client()
try:
client.delete_collection("sql_queries")
except Exception as e:
print(f"删除集合时出错: {e}")
collection = client.create_collection(
name="sql_queries",
metadata={"description": "用于相似性分析的SQL查询"}
)
return client, collection
接下来,我们将从CSV读取的SQL查询列表存储到ChromaDB中,每个查询会被分配一个唯一ID和简单的元数据。
def store_queries_in_chroma(collection, queries):
"""将SQL查询存储在ChromaDB中"""
ids = [f"query_{i}" for i in range(len(queries))]
collection.add(
documents=queries,
ids=ids,
metadatas=[
{"type": "sql_query", "index": i}
for i in range(len(queries))
]
)
print(f"在ChromaDB中存储了{len(queries)}个SQL查询")
生成查询向量嵌入
我们使用 Sentence Transformers 库中的 all-MiniLM-L6-v2 模型来生成高质量的文本嵌入。这个预训练模型能够将句子(包括SQL语句)映射到一个384维的语义空间中。
def get_embeddings_for_clustering(collection):
"""从ChromaDB获取嵌入用于聚类"""
from sentence_transformers import SentenceTransformer
results = collection.get()
documents = results['documents']
ids = results['ids']
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(documents)
return embeddings, documents, ids
基于 K-Means 的查询聚类分析
有了数值化的向量表示,我们可以应用传统的机器学习算法进行分析。这里使用 K-Means 算法对查询进行无监督聚类,以发现查询模式。
def perform_clustering(embeddings, documents, n_clusters=5):
"""对SQL查询执行K-means聚类"""
from sklearn.cluster import KMeans
import pandas as pd
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(embeddings)
df = pd.DataFrame({
'query': documents,
'cluster': cluster_labels
})
print(f"\n聚类结果 ({n_clusters} 个簇):")
for cluster_id in range(n_clusters):
cluster_queries = df[df['cluster'] == cluster_id]['query'].tolist()
print(f"\n簇 {cluster_id} ({len(cluster_queries)} 个查询):")
for query in cluster_queries[:3]: # 仅打印前3个示例
print(f" - {query}")
if len(cluster_queries) > 3:
print(f" ... 以及另外 {len(cluster_queries)-3} 个查询")
return cluster_labels, df
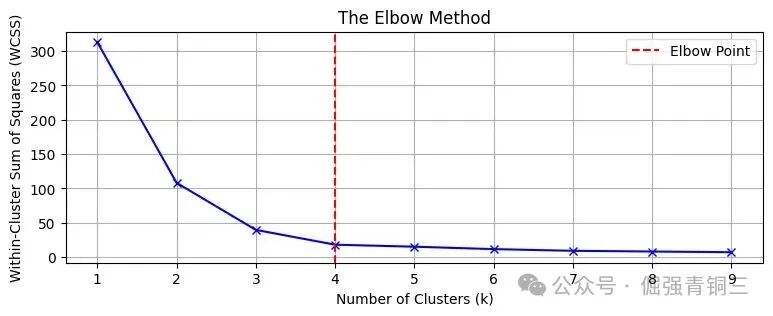
如果无法确定最佳的聚类数量 K,可以应用肘部法则。通过绘制不同K值对应的聚类误差(惯性),选择误差下降趋势发生明显转折的“肘点”作为K值。
测量查询之间的相似度
1. 计算全局相似度矩阵
我们可以计算所有查询两两之间的余弦相似度,形成一个相似度矩阵,并找出最相似的查询对。
def analyze_query_similarity_matrix(embeddings, documents):
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
similarity_matrix = cosine_similarity(embeddings)
print("\n最相似的5个查询对:")
print("=" * 50)
indices = np.triu_indices_from(similarity_matrix, k=1)
similarities = similarity_matrix[indices]
top_indices = np.argsort(similarities)[-5:][::-1]
for idx in top_indices:
i, j = indices[0][idx], indices[1][idx]
similarity = similarities[idx]
print(f"相似度: {similarity:.3f}")
print(f" 查询 1: {documents[i]}")
print(f" 查询 2: {documents[j]}")
print()
2. 针对特定查询查找相似项
这在数据治理中非常有用,例如,当你想找到一个低效查询的“孪生兄弟”或替代写法时。
def find_similar_queries(collection, query, n_results=3):
"""使用ChromaDB的向量检索查找相似的查询"""
results = collection.query(
query_texts=[query],
n_results=n_results
)
print(f"\n查询: {query}")
print("相似的查询:")
for i, (doc, distance) in enumerate(zip(results['documents'][0], results['distances'][0])):
similarity = 1 - distance
print(f" {i+1}. 相似度: {similarity:.3f} - {doc}")
使用 t-SNE 可视化聚类结果
高维向量难以直接观察,我们可以使用 t-SNE 算法将其降至2维进行可视化,直观地展示查询的分布与聚类情况。
def visualize_clusters(embeddings, cluster_labels, documents):
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(
n_components=2,
random_state=42,
perplexity=min(30, len(documents)-1)
)
embeddings_2d = tsne.fit_transform(embeddings)
plt.figure(figsize=(12, 8))
scatter = plt.scatter(
embeddings_2d[:, 0],
embeddings_2d[:, 1],
c=cluster_labels,
alpha=0.7
)
plt.title('SQL查询聚类可视化 (t-SNE降维)')
plt.xlabel('t-SNE 组件 1')
plt.ylabel('t-SNE 组件 2')
plt.colorbar(scatter, label='簇标签')
plt.tight_layout()
plt.savefig('sql_queries_clustering.png')
plt.show()
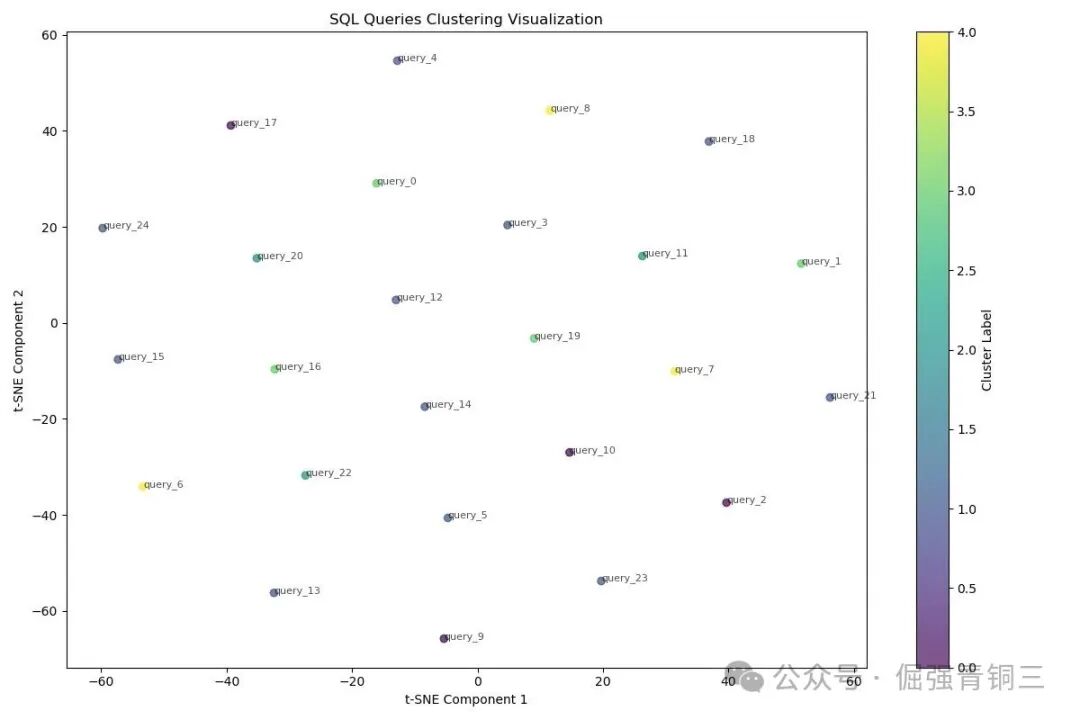
可视化图表可以清晰揭示查询的结构:紧密的簇代表高度相似的查询组,分散的点可能是独特或异常的查询,簇间的距离反映了不同查询模式之间的语义差异。
总结与应用场景
通过将 SQL 查询转化为向量,我们解锁了一套强大的分析能力。这种基于嵌入技术的方法使我们能够:
- 量化查询相似度:精确度量两个查询在语义和结构上的接近程度。
- 理解行为模式:自动聚类识别出用户常用的查询模板和访问模式。
- 优化与治理:发现低效、重复或偏离最佳实践的查询,辅助进行 大数据 平台的成本优化和查询治理。
- 改进文档与推荐:基于相似查询分析,可以自动生成查询文档或构建查询推荐系统。
这种方法将查询分析从主观的文本比对提升为客观的、可量化的向量运算。通过结合 Python 丰富的数据科学生态,数据工程师可以更深入地洞察组织内部的数据使用习惯,为数据平台的性能优化和资源管理提供数据驱动的决策支持。
 发表于 2025-12-22 01:54:04
|
查看: 2641|
回复: 0
发表于 2025-12-22 01:54:04
|
查看: 2641|
回复: 0
