在大数据时代,企业业务分析常常面临海量数据查询效率低下的难题。尤其在电商领域,城市销售统计、品类利润分析等需求,往往需要关联订单、客户、商品、分类等多张表进行复杂计算,随着数据量增长,传统查询方式的性能会急剧下降。而 OceanBase 物化视图作为一种高效的数据处理技术,能有效解决这一痛点。

一、物化视图基础:不止于“视图”的进阶形态
1.1 什么是物化视图?
在数据库领域,视图是一个虚拟表,它由查询语句定义,本身不存储数据。而物化视图则是一种特殊的视图,它不仅包含了视图定义的查询逻辑,还会存储该查询执行的结果集,这个将查询结果持久化存储的过程被称为“物化”。
简单来说,物化视图就像是提前把复杂查询的“答案”计算好并保存起来,当用户需要查询相关数据时,无需再重复执行耗时的查询操作,直接读取预存的“答案”即可。这种“空间换时间”的策略,能大幅减少重复计算带来的资源消耗,显著提升查询效率,尤其适用于查询频率高、计算逻辑复杂且数据时效性要求并非极致实时的场景,比如电商系统的销售报表统计、用户行为分析等。
1.2 物化视图与普通视图的核心区别
很多人容易将物化视图与普通视图混淆,实际上二者在数据存储、查询机制、性能表现等方面存在本质差异,具体对比如下表所示:
| 对比维度 |
普通视图 |
物化视图 |
| 数据存储 |
不存储实际数据,仅保存视图定义的查询语句 |
拥有专门的“容器表”,存储查询语句执行后的结果集 |
| 查询执行机制 |
用户每次查询视图时,都会重新执行视图定义中的查询语句,实时计算结果 |
用户查询时,直接读取容器表中预存的结果,无需重新计算 |
| 数据时效性 |
结果完全实时,因为每次查询都基于最新的基础表数据重新计算 |
结果存在一定延迟,需通过“刷新”操作更新容器表数据,以保证与基础表数据的一致性 |
| 性能表现 |
查询性能依赖基础表数据量和查询复杂度,数据量大、逻辑复杂时性能差 |
查询性能优异,无论基础表数据量多大,均为单表查询操作 |
| 资源消耗 |
每次查询都消耗 CPU、IO 等资源,重复查询会造成资源浪费 |
仅在“刷新”时消耗资源,查询阶段资源消耗极低 |
1.3 OceanBase 物化视图的独特优势
OceanBase 作为一款分布式关系型数据库,其物化视图在继承传统数据库物化视图核心能力的基础上,还结合分布式架构特点,具备了更多适配大规模数据场景的优势:
- 高效增量刷新:支持基于物化视图日志(MLOG)的 FAST REFRESH(快速刷新),仅对基础表中发生变更的数据进行增量计算和更新,避免全量刷新带来的巨大资源消耗,尤其适合数据频繁变更的业务场景。
- 灵活的刷新策略:既支持手动触发刷新,也支持按固定时间间隔自动刷新(如每隔 60 秒刷新一次),还能根据业务需求定制刷新时间,平衡数据时效性和系统性能。
- 分布式存储优化:物化视图的容器表采用分布式存储方式,能充分利用 OceanBase 分布式架构的优势,支持海量数据存储和高并发查询,避免单点性能瓶颈。
- 与原生语法兼容:在 MySQL 模式下,OceanBase 物化视图的创建、刷新、查询等操作语法与 MySQL 兼容,降低开发者的学习成本和迁移难度,便于业务快速适配。
二、电商场景实验:OceanBase 物化视图的实战应用
为了更直观地感受物化视图的价值,我们以电商系统“按城市统计总销售额”的业务需求为例,通过实验对比传统多表 JOIN 查询与基于物化视图的单表查询的差异,深入理解物化视图的应用流程和性能优势。
2.1 实验背景与环境说明
业务场景
电商平台需要定期按城市统计总销售额,该需求需关联订单表(orders)、客户表(customers)、订单商品明细表(order_items)、商品表(products)、商品分类表(categories)5 张表,涉及多表 JOIN 和聚合计算,数据量增长后传统查询方式的性能会显著下降。
实验环境
- 数据库:OceanBase 数据库(MySQL 模式)
- 服务器规格:单机版 2C8G(数据导出导入效率会因环境和机器规格不同而存在差异)
- 数据规模:20 笔订单、10 个客户、16 件商品、12 个商品分类
对比方案
- 方案 A:实时多表 JOIN 查询(传统方式),每次查询都重新执行多表关联和聚合计算。
- 方案 B:基于物化视图的单表查询(预计算方式),提前通过物化视图将多表关联结果预存,查询时直接操作物化视图。
2.2 实验核心步骤拆解
步骤一:连接 OceanBase 数据库
使用 obclient 工具连接数据库,命令如下:
其中,-h 指定数据库地址,-P 指定端口,-u 指定用户名(格式为“用户名@租户名”)
obclient -h127.0.0.1 -P2881 -uroot@mysql_tenant -A -Dtest
步骤二:创建基础表与物化视图日志
物化视图日志(MLOG)是实现 FAST REFRESH(快速刷新)的关键,它会记录基础表的数据变更(如插入、更新、删除操作),当物化视图刷新时,仅需根据日志中的变更数据进行增量更新,无需重新全量计算。
我们需要为实验涉及的 5 张基础表分别创建表结构和对应的物化视图日志,以下为核心表的创建语句示例:
-
客户表(customers):存储客户基本信息,包括客户 ID、姓名、所在城市、注册日期等。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city VARCHAR(50),
registration_date DATE
);
对应的物化视图日志创建语句:
CREATE MATERIALIZED VIEW LOG ON customers
WITH PRIMARY KEY, ROWID, SEQUENCE (customer_name, city, registration_date) INCLUDING NEW VALUES;
WITH PRIMARY KEY:表示日志中包含基础表的主键,用于定位变更数据。ROWID:记录数据行的物理地址,辅助定位数据。SEQUENCE:指定需要记录的列,此处为客户表除主键外的核心业务列。INCLUDING NEW VALUES:记录数据变更后的新值,用于增量更新物化视图。
-
订单表(orders):存储订单基本信息,关联客户表(通过 customer_id 外键)。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
status VARCHAR(20),
total_amount DECIMAL(10,2),
FOREIGN KEY(customer_id) REFERENCES customers(customer_id)
);
对应的物化视图日志创建语句:
CREATE MATERIALIZED VIEW LOG ON orders
WITH PRIMARY KEY, ROWID, SEQUENCE(customer_id, order_date, status, total_amount) INCLUDING NEW VALUES;
同理,我们还需创建商品分类表(categories)、商品表(products)、订单商品明细表(order_items)及其对应的物化视图日志,确保所有基础表的变更都能被记录,为物化视图增量刷新提供支持。
-
商品分类表(categories)
CREATE TABLE categories (
category_id INT PRIMARY KEY,
category_name VARCHAR(50),
parent_category_id INT
);
对应的物化视图日志创建语句:
CREATE MATERIALIZED VIEW LOG ON categories
WITH PRIMARY KEY, ROWID, SEQUENCE (category_name, parent_category_id) INCLUDING NEW VALUES;
-
商品表(products)
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100),
category_id INT,
price DECIMAL(10,2),
cost DECIMAL(10,2),
FOREIGN KEY (category_id) REFERENCES categories(category_id)
);
对应的物化视图日志创建语句:
CREATE MATERIALIZED VIEW LOG ON products
WITH PRIMARY KEY, ROWID, SEQUENCE(product_name, category_id, price, cost) INCLUDING NEW VALUES;
-
订单商品明细表(order_items)
CREATE TABLE order_items (
order_item_id INT PRIMARY KEY,
order_id INT,
product_id INT,
quantity INT,
unit_price DECIMAL(10,2),
subtotal DECIMAL(10,2),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
对应的物化视图日志创建语句:
CREATE MATERIALIZED VIEW LOG ON order_items
WITH PRIMARY KEY, ROWID, SEQUENCE(order_id, product_id, quantity, unit_price, subtotal) INCLUDING NEW VALUES;
步骤三:创建物化视图(销售宽表)
在基础表和物化视图日志创建完成后,我们创建用于“按城市统计总销售额”的物化视图 sales_wide_view(即销售宽表),该视图会预计算 5 张表的关联结果,并存储关键业务字段。
创建语句如下:
CREATE MATERIALIZED VIEW sales_wide_view
REFRESH FAST
START WITH SYSDATE()
NEXT SYSDATE() + INTERVAL 60 SECOND
AS
SELECT
o.order_id,
o.order_date,
o.status as order_status,
o.total_amount,
c.customer_id,
c.customer_name,
c.city,
c.registration_date,
p.product_id,
p.product_name,
p.price as product_price,
p.cost as product_cost,
cat.category_id,
cat.category_name,
oi.quantity,
oi.unit_price,
oi.subtotal,
(oi.subtotal - (p.cost * oi.quantity)) as profit, -- 计算单条订单商品利润
(oi.unit_price - p.cost) as unit_profit, -- 计算单位商品利润
EXTRACT(YEAR FROM o.order_date) as order_year, -- 提取订单年份
EXTRACT(MONTH FROM o.order_date) as order_month, -- 提取订单月份
EXTRACT(QUARTER FROM o.order_date) as order_quarter, -- 提取订单季度
TO_CHAR(o.order_date, 'YYYY-MM') as order_year_month -- 格式化订单年月
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
JOIN categories cat ON p.category_id = cat.category_id
WHERE o.status = 'completed'; -- 仅统计已完成的订单
该物化视图的核心配置解读:
REFRESH FAST:指定采用增量刷新方式,基于物化视图日志更新数据,而非全量重新计算。START WITH SYSDATE() NEXT SYSDATE() + INTERVAL 60 SECOND:设置刷新策略,从当前时间开始,每隔 60 秒自动刷新一次,确保物化视图数据与基础表数据的时效性。- 查询逻辑:关联 5 张表,不仅包含基础业务字段,还预计算了利润、订单时间维度等衍生字段,满足后续多维度分析需求。
步骤四:插入测试数据与手动刷新(可选)
-
插入测试数据:向 5 张基础表中插入实验所需的测试数据,例如向客户表插入 10 条客户数据,向订单表插入 20 条已完成的订单数据等。插入完成后,可通过 SELECT COUNT(*) FROM 表名 验证数据条数,确保数据插入正确。 以订单表数据验证为例:SELECT COUNT(*) FROM orders; 正常返回结果应为 20,表示 20 条订单数据已成功插入。
向客户表 customers 插入客户数据。
INSERT INTO customers (customer_id, customer_name, city, registration_date) VALUES
(1, '张三', '北京', '2023-01-15'),
(2, '李四', '上海', '2023-02-20'),
(3, '王五', '广州', '2023-03-10'),
(4, '赵六', '深圳', '2023-01-25'),
(5, '钱七', '北京', '2023-04-05'),
(6, '孙八', '杭州', '2023-02-28'),
(7, '周九', '上海', '2023-03-15'),
(8, '吴十', '成都', '2023-05-01'),
(9, '郑十一', '北京', '2023-04-20'),
(10, '王十二', '深圳', '2023-03-08');
向商品分类表 categories 插入商品分类数据。
INSERT INTO categories (category_id, category_name, parent_category_id) VALUES
(1, '电子产品', NULL),
(2, '服装鞋帽', NULL),
(3, '家居用品', NULL),
(11, '手机', 1),
(12, '笔记本电脑', 1),
(13, '平板电脑', 1),
(21, '男装', 2),
(22, '女装', 2),
(23, '运动鞋', 2),
(31, '厨房用品', 3),
(32, '床上用品', 3),
(33, '家具', 3);
向商品表 products 插入商品数据。
INSERT INTO products (product_id, product_name, category_id, price, cost) VALUES
(101, 'iPhone 15 Pro', 11, 8999.00, 6500.00),
(102, '华为 Mate 60', 11, 6999.00, 5200.00),
(103, '小米 14', 11, 3999.00, 3000.00),
(104, '三星 Galaxy S24', 11, 5999.00, 4500.00),
(201, 'MacBook Pro 16寸', 12, 18999.00, 14500.00),
(202, 'ThinkPad X1', 12, 12999.00, 9800.00),
(203, '华为 MateBook', 12, 6999.00, 5200.00),
(204, '戴尔 XPS', 12, 8999.00, 6800.00),
(301, 'iPad Air', 13, 4799.00, 3500.00),
(302, '华为 MatePad', 13, 3299.00, 2400.00),
(401, '男士休闲衬衫', 21, 299.00, 180.00),
(402, '男士牛仔裤', 21, 399.00, 250.00),
(501, '女士连衣裙', 22, 599.00, 350.00),
(502, '女士针织衫', 22, 399.00, 240.00),
(601, '不粘锅套装', 31, 899.00, 550.00),
(602, '餐具套装', 31, 299.00, 180.00);
向订单表 orders 插入订单数据。
INSERT INTO orders (order_id, customer_id, order_date, status, total_amount) VALUES
(1001, 1, '2024-01-10', 'completed', 8999.00),
(1002, 2, '2024-01-12', 'completed', 13998.00),
(1003, 3, '2024-01-15', 'completed', 3999.00),
(1004, 4, '2024-01-18', 'completed', 18999.00),
(1005, 5, '2024-01-20', 'completed', 10997.00),
(1006, 1, '2024-02-05', 'completed', 12998.00),
(1007, 6, '2024-02-08', 'completed', 4799.00),
(1008, 2, '2024-02-10', 'completed', 898.00),
(1009, 7, '2024-02-12', 'completed', 5999.00),
(1010, 8, '2024-02-15', 'completed', 3299.00),
(1011, 3, '2024-02-18', 'completed', 1899.00),
(1012, 9, '2024-02-20', 'completed', 6999.00),
(1013, 10, '2024-02-25', 'completed', 1198.00),
(1014, 4, '2024-03-01', 'completed', 8999.00),
(1015, 5, '2024-03-05', 'completed', 4799.00),
(1016, 6, '2024-03-08', 'completed', 12999.00),
(1017, 1, '2024-03-10', 'completed', 599.00),
(1018, 7, '2024-03-12', 'completed', 18999.00),
(1019, 8, '2024-03-15', 'completed', 3299.00),
(1020, 2, '2024-03-18', 'completed', 6999.00);
向订单商品明细表 order_items 插入订单商品明细数据。
INSERT INTO order_items (order_item_id, order_id, product_id, quantity, unit_price, subtotal) VALUES
(1, 1001, 101, 1, 8999.00, 8999.00),
(2, 1002, 101, 1, 8999.00, 8999.00),
(3, 1002, 103, 1, 3999.00, 3999.00),
(4, 1003, 103, 1, 3999.00, 3999.00),
(5, 1004, 201, 1, 18999.00, 18999.00),
(6, 1005, 102, 1, 6999.00, 6999.00),
(7, 1005, 401, 2, 299.00, 598.00),
(8, 1005, 402, 1, 399.00, 399.00),
(9, 1006, 202, 1, 12999.00, 12999.00),
(10, 1007, 301, 1, 4799.00, 4799.00),
(11, 1008, 401, 2, 299.00, 598.00),
(12, 1008, 402, 1, 399.00, 399.00),
(13, 1009, 104, 1, 5999.00, 5999.00),
(14, 1010, 302, 1, 3299.00, 3299.00),
(15, 1011, 501, 2, 599.00, 1198.00),
(16, 1011, 502, 1, 399.00, 399.00),
(17, 1012, 203, 1, 6999.00, 6999.00),
(18, 1013, 502, 2, 399.00, 798.00),
(19, 1013, 602, 1, 299.00, 299.00),
(20, 1014, 204, 1, 8999.00, 8999.00),
(21, 1015, 301, 1, 4799.00, 4799.00),
(22, 1016, 201, 1, 18999.00, 18999.00),
(23, 1017, 501, 1, 599.00, 599.00),
(24, 1018, 201, 1, 18999.00, 18999.00),
(25, 1019, 302, 1, 3299.00, 3299.00),
(26, 1020, 203, 1, 6999.00, 6999.00);
查看订单表 orders 数据条数。
SELECT COUNT(*) FROM orders;
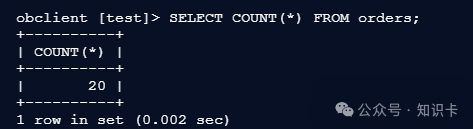
查看订单商品明细表 order_items 数据条数。
SELECT COUNT(*) FROM order_items;

-
手动刷新物化视图:虽然已设置每 60 秒自动刷新,但为了确保数据立即同步,可手动触发一次增量刷新,命令如下:
CALL DBMS_MVIEW.REFRESH('sales_wide_view', 'F');
其中,'F' 表示 FAST REFRESH(增量刷新),若需全量刷新,可将参数改为 'C'(COMPLETE REFRESH)。
2.3 实验结果对比:性能差距一目了然
我们分别执行方案 A(传统多表 JOIN 查询)和方案 B(基于物化视图的单表查询),对比两者在查询结果、逻辑读、CPU 消耗、查询复杂度等维度的差异。
1. 查询语句与结果
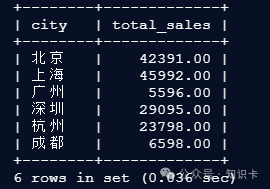
-
方案 A:多表 JOIN 查询
SELECT c.city, SUM(oi.subtotal) as total_sales
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id
JOIN order_items oi
ON o.order_id = oi.order_id
JOIN products p
ON oi.product_id = p.product_id
WHERE o.status = 'completed'
GROUP BY c.city;
返回结果(按城市统计的总销售额):
-
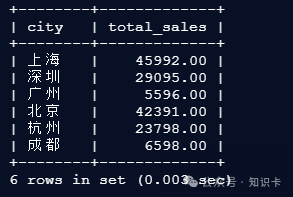
方案 B:物化视图单表查询
SELECT city, SUM(subtotal) as total_sales FROM sales_wide_view GROUP BY city;
返回结果与方案 A 完全一致,确保了数据的一致性,而且速度更快。
2. 性能指标对比
| 性能指标 |
方案 A(多表 JOIN) |
方案 B(物化视图) |
| 逻辑读 |
高(需扫描 5 张表,读取大量数据页) |
低(仅扫描物化视图 1 张表) |
| CPU 消耗 |
高(需执行多表 JOIN + 聚合计算) |
低(仅需对单表数据进行聚合操作) |
| 查询复杂度 |
复杂(需编写完整的多表 JOIN 逻辑) |
简单(仅需单表 GROUP BY 操作) |
| 数据量增长影响 |
性能急剧下降(分钟级延迟) |
性能稳定(秒级响应) |
关键结论:在实验的小规模数据场景下,物化视图已展现出明显的性能优势;而当数据量增长到百万级订单规模时,传统多表 JOIN 查询可能需要几分钟才能返回结果,而物化视图仍能保持秒级响应,性能差距呈指数级扩大。
三、OceanBase 物化视图的进阶知识与最佳实践
3.1 物化视图的刷新方式详解
OceanBase 物化视图支持多种刷新方式,不同方式适用于不同的业务场景,开发者需根据数据时效性、系统资源情况选择合适的刷新策略:
- FAST REFRESH(增量刷新)
- 原理:基于物化视图日志,仅对基础表中发生变更的数据(插入、更新、删除)进行增量计算,并更新物化视图的容器表。
- 优势:刷新效率高,资源消耗低,适合数据变更频繁、时效性要求较高的场景(如电商实时销售监控)。
- 前提:必须为所有基础表创建物化视图日志,且物化视图的查询逻辑需满足增量刷新的语法要求(如不包含 DISTINCT、GROUP BY 中使用复杂函数等)。
- COMPLETE REFRESH(全量刷新)
- 原理:忽略物化视图日志,重新执行物化视图定义的查询语句,将结果集全量覆盖容器表中的旧数据。
- 优势:适用范围广,无需依赖物化视图日志,且不受查询逻辑限制(如支持 DISTINCT、UNION 等语法)。
- 劣势:刷新效率低,资源消耗高,适合数据变更频率低、查询逻辑复杂的场景(如月度销售报表)。
- FORCE REFRESH(强制刷新)
- 原理:优先尝试增量刷新(FAST REFRESH),若增量刷新条件不满足(如物化视图日志损坏、查询逻辑不支持),则自动降级为全量刷新(COMPLETE REFRESH)。
- 优势:兼顾灵活性和可靠性,无需人工判断刷新方式,适合对刷新方式无明确要求的场景。
3.2 物化视图的适用场景与注意事项
适用场景
- 复杂查询高频执行场景:如电商平台的实时销售报表、用户画像分析等,这些查询通常涉及多表关联和复杂计算,且查询频率高,物化视图能显著降低重复计算成本。
- 数据时效性要求非极致实时场景:如按小时、按天统计的业务指标,允许数据存在几秒到几分钟的延迟,此时物化视图的自动刷新策略能平衡时效性和性能。
- 分布式大规模数据场景:OceanBase 物化视图的分布式存储特性,使其能适配 PB 级数据存储和高并发查询,满足大型企业的业务需求。
注意事项
- 存储空间占用:物化视图会存储查询结果集,需占用额外的存储空间,尤其是在数据量较大的场景下,需提前规划存储资源。
- 刷新时机选择:自动刷新会消耗系统资源,应避免在业务高峰期(如电商大促)频繁刷新,可将刷新时间调整到凌晨等低峰期。
- 数据一致性保障:虽然物化视图支持刷新,但在刷新间隔内,数据仍可能与基础表存在不一致,需在业务设计中明确数据一致性要求,避免因数据延迟导致业务问题。
- 索引优化:为了进一步提升物化视图的查询性能,可在物化视图的常用查询字段(如 city、order_date)上创建索引,减少查询时的扫描范围。
3.3 与其他数据库物化视图的差异
OceanBase 作为分布式数据库,其物化视图与传统单机数据库(如 MySQL、Oracle)的物化视图相比,存在以下关键差异:
- 分布式存储与计算:OceanBase 物化视图的容器表采用分布式分片存储,刷新操作也支持分布式并行计算,能充分利用集群资源,而传统单机数据库的物化视图受限于单节点性能。
- 高可用性:OceanBase 基于 Paxos 协议实现数据多副本存储,物化视图的容器表也具备高可用特性,即使某个节点故障,也能快速切换到其他副本,保证查询连续性;传统单机数据库的物化视图若所在节点故障,将无法访问。
- 弹性扩展:当业务数据量增长时,OceanBase 可通过增加节点实现物化视图的存储和计算能力弹性扩展,而传统单机数据库受限于硬件配置,扩展能力有限。
四、总结:物化视图——OceanBase 提升查询性能的关键利器
通过本文的讲解,我们从基础概念、实验实践、进阶知识三个维度全面剖析了 OceanBase 物化视图。可以看到,物化视图通过“预计算+存储结果”的核心机制,将复杂多表查询转化为简单单表查询,大幅提升了查询效率,尤其在电商等大规模数据场景下,其性能优势更为明显。
在实际业务应用中,开发者需结合自身业务需求,合理选择物化视图的刷新方式和刷新时机,平衡数据时效性、系统性能和存储空间三者的关系。相信随着 OceanBase 数据库的不断迭代,物化视图的功能将更加完善,为企业业务分析提供更强大的支持,助力企业在大数据时代实现高效的数据驱动决策。 |
 发表于 2025-12-22 18:28:44
|
查看: 300|
回复: 0
发表于 2025-12-22 18:28:44
|
查看: 300|
回复: 0
