在日常处理网格数据集时,我们接触的时间维度大多采用标准的公历(standard calendar)。使用xarray读取这类数据时,时间维度能够被自动解码为numpy.datetime64类型,从而可以方便地利用NumPy和Pandas提供的时间处理函数进行分析。
然而,在处理某些特定的气候模式输出数据时,直接读取可能会遇到解码错误。这类数据的时间维度通常采用了 360_day历法。本文将介绍如何处理这种特殊时间维度的网格数据。
CF 规范支持的时间(日历)类型
CF(Climate and Forecast) conventions 定义了一系列标准日历类型,主要分为三大类。
1️⃣ 真实公历类(与现实世界一致)
-
standard / gregorian
- 包含闰年与2月29日。
- 1582年后严格遵循格里高利历。
- 适用场景:观测数据、再分析数据、业务预报数据。
-
proleptic_gregorian
- 向过去无限延拓的公历,不考虑历史上的历法改革。
- 适用场景:时间跨度非常长的古气候数据。
2️⃣ 简化公历类(为计算模型设计)
-
365_day (又称 noleap)
- 每年固定为365天,不含闰年。
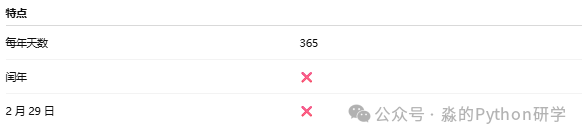
- 适用场景:许多气候模式的输出数据,比360_day更接近现实。
-
366_day (又称 all_leap)
-
360_day
- 每年固定为360天,每月固定为30天,属于经典的气候模式日历。
3️⃣ 非常规 / 自定义类型(极少使用)
包括julian、none以及自定义calendar(一般不推荐使用)。
实战案例:处理 360_day 日历数据
当我们尝试直接用xarray打开一份采用360_day日历的NetCDF数据时:
import xarray as xr
data = xr.open_dataset('data.nc')
data

程序会抛出错误。
报错原因分析
xarray在默认情况下会尝试使用Pandas来解码时间坐标。然而,Pandas并不支持360_day这类非标准日历。NetCDF文件中时间变量的关键属性通常如下:
units: months since 1960-01-01
calendar: 360
xarray试图用pandas.Timestamp来解码这个基于360日历的时间,因此导致了失败。具体的错误信息是:
OutOfBoundsDatetime: Cannot decode times from a non-standard calendar, ‘360‘, using pandas.
核心问题:Pandas无法识别360日历,因此不能将时间单位(如months since 1960-01-01)转换为标准的numpy.datetime64对象。
解决方案
解决此问题的关键在于使用专门处理CF时间标准的CFTime库,而非依赖Pandas。具体步骤如下:
-
首先,定义一个解码函数。该函数会将日历属性名从简写的"360"修正为完整的"360_day"(符合CFTime库的预期),然后启用xarray的CF时间解码功能。
def decode_cf(ds, time_var):
"""将时间维度解码为CFTime标准格式。"""
if ds[time_var].attrs.get("calendar") == "360":
ds[time_var].attrs["calendar"] = "360_day"
ds = xr.decode_cf(ds, decode_times=True)
return ds
-
读取数据时,先关闭自动时间解码,然后应用我们定义的解码函数。
import xarray as xr
# 首次读取时不解码时间
data = xr.open_dataset('data.nc', decode_times=False)
# 使用自定义函数进行正确解码
data = decode_cf(data, 'T')
data
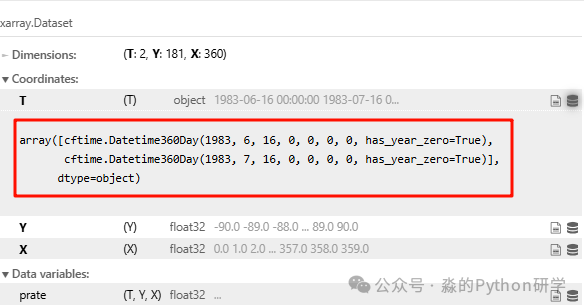
解码成功后,时间维度T的数据类型显示为object,但其内部实际上是CFTime对象。这意味着我们依然可以方便地使用.dt访问器进行时间筛选。
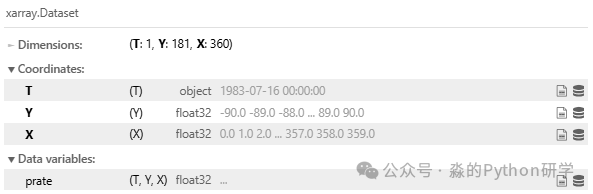
例如,筛选出所有七月份的数据:
july = data.sel(T=data['T'].dt.month == 7)
july

|  发表于 2025-12-22 18:35:47
|
查看: 389|
回复: 0
发表于 2025-12-22 18:35:47
|
查看: 389|
回复: 0
