在上一篇文章中,我们分析了Queued Spin Lock的核心数据结构qspinlock。其设计精巧之处在于,通过一个32位的union,将变量划分为不同的位域,每个位域对应一个特定角色,服务于锁竞争过程中的不同参与者。这种设计使得qspinlock仅用一个4字节的数据结构,就实现了对原有自旋锁API的良好兼容,并构建了公平的MCS等待队列。
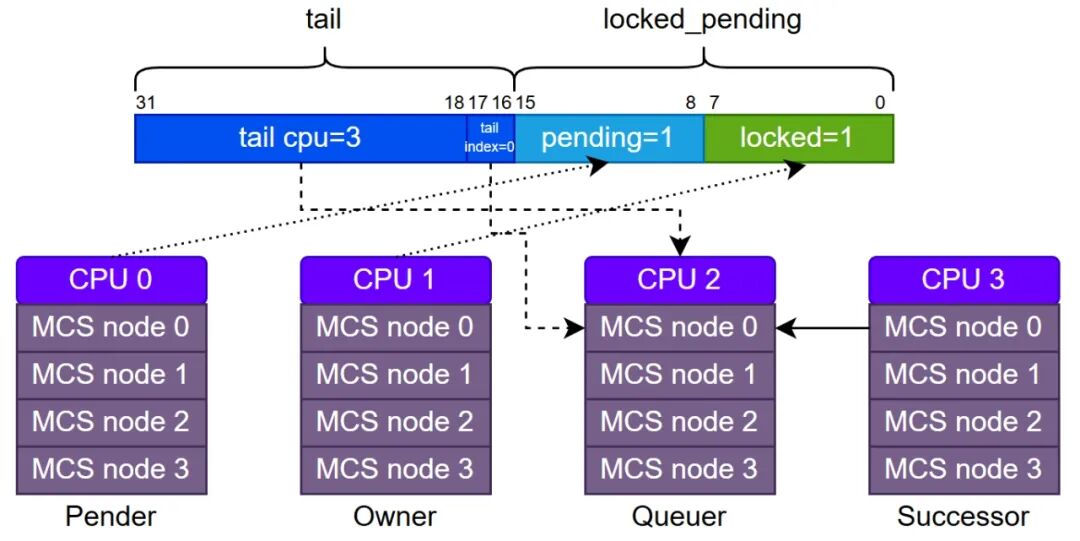
下图展示了qspinlock结构的字段划分。当只有两个CPU争抢锁时,仅会用到locked和pending字段,此时不会启用MCS等待队列。只有当争抢锁的CPU超过两个时,MCS等待队列才会被激活,tail字段将指向队列的尾节点。
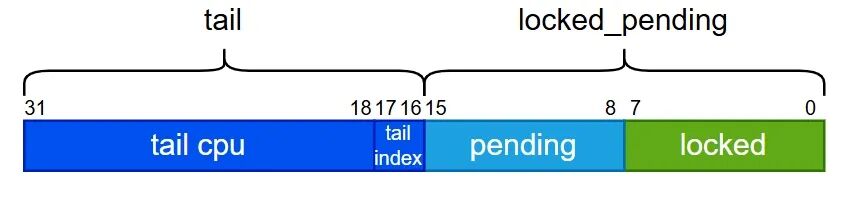
在实现上,Queued Spin Lock采用静态方式为每个CPU预先分配4个MCS节点,分别代表四种可能的执行上下文(进程、软中断、硬中断、NMI)。需要特别注意的是,qspinlock结构中的tail字段并非一个直接的指针,它由两部分构成:tail cpu(队尾节点所属CPU编号加1)和tail index(该CPU上的上下文编号)。
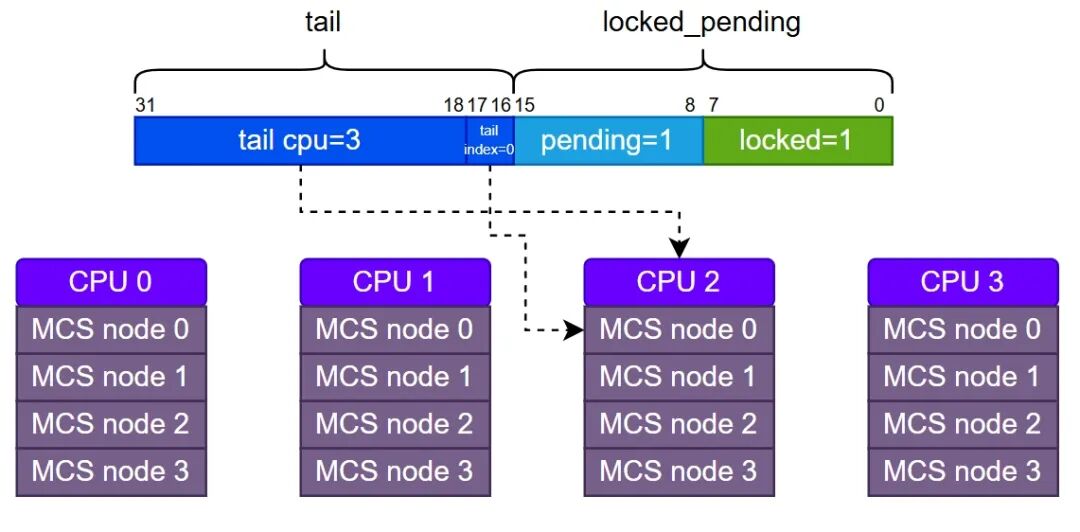
在Queued Spin Lock的争抢逻辑中,CPU被清晰地划分为四个角色:
- Owner:锁的当前持有者。加锁时负责将
locked字段置1,解锁时负责将其清零。
- Pender:锁的第一顺位等待者。它将
pending字段置1,并在locked字段上自旋等待。一旦检测到Owner释放锁(locked清零),Pender会立即将pending清零、locked置1,从而晋升为Owner。
- Successor:MCS等待队列的队首等待者,即第二顺位等待者。它会在
locked_pending组合字段上自旋等待。当Owner和Pender都退出后,它检测到locked_pending清零,便将locked置1,获取锁并晋升为Owner。
- Queuer:MCS等待队列中除队首(Successor)外的其他等待者。它们各自在自己的MCS节点的
locked字段上自旋等待。
接下来,我们深入分析Linux内核中Queued Spin Lock的实现。加锁函数queued_spin_lock包含快速路径和慢速路径。快速路径处理锁空闲(lock->val=0)的情况,CPU通过cmpxchg原子操作检查后立即获取锁,将locked置1后返回。慢速路径则在锁已被持有时触发,CPU会进入核心函数queued_spin_lock_slowpath,这里集中体现了Queued Spin Lock设计的精髓。
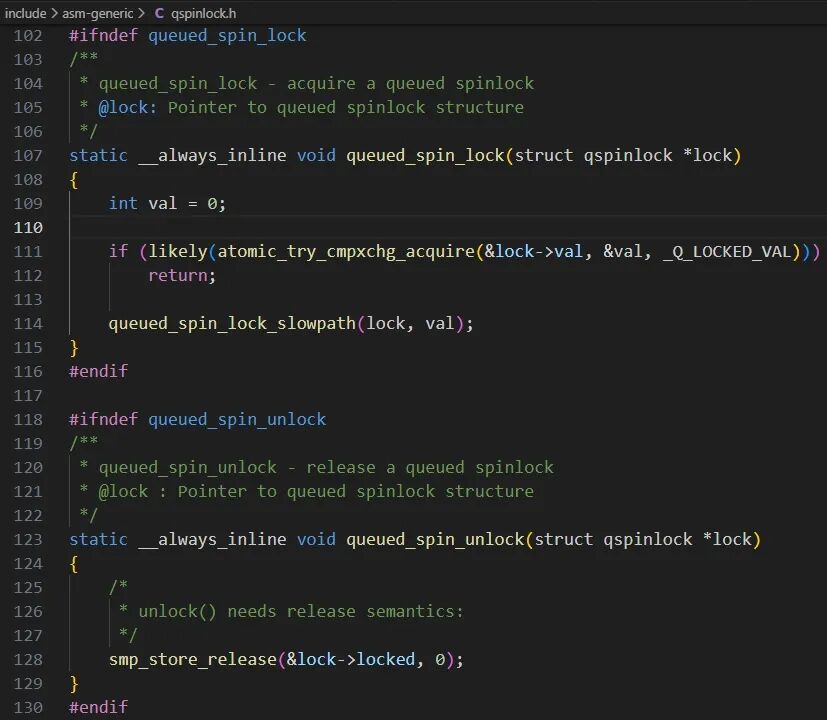
解锁函数queued_spin_unlock非常简单,仅将锁的locked字段清零。按照经典MCS锁的逻辑,释放锁时应唤醒队列中的下一个等待者。但此处并未进行此操作,那么锁所有权的转移究竟在何处完成?答案就在前面的queued_spin_lock_slowpath函数中。
queued_spin_lock_slowpath函数是理解Queued Spin Lock的关键。该函数开头的注释以一种巧妙的状态机形式阐述了其逻辑,理解这段注释就等于掌握了其核心思想。
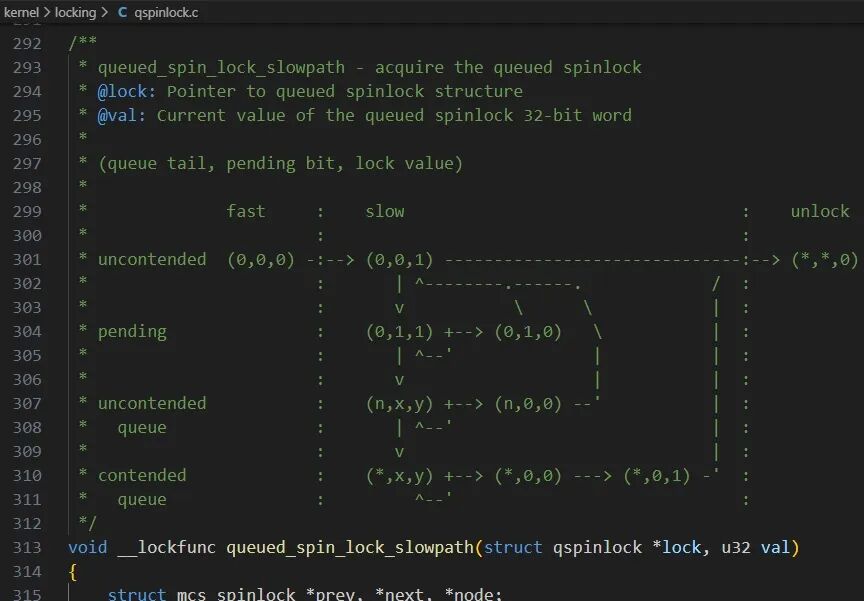
注释中的状态由三元组 (queue tail, pending bit, lock value) 描述:
- queue tail: MCS队列尾节点编号。
0表示队列空,n表示尾节点编号,*表示任意值(无关)。
- pending bit:
pending字段值。0表示无等待者或等待者已入队,1表示有Pender在等待。
- lock value:
locked字段值。0表示锁空闲,1表示锁被持有。
若pending bit和lock value显示为x/y,则表示两者至少有一个为1。
状态机共定义了4种状态及其转换:
- uncontended (无竞争状态):
- 初始状态
(0,0,0)。CPU通过原子操作将锁置为(0,0,1)(快速路径)。Owner释放后变为(*,*,0)。
(0,0,0) -> (0,0,1) -> (*,*,0)
- pending (仅有Pender等待):
- 锁被持有
(0,0,1)时,新CPU成为Pender,状态变为(0,1,1)。Owner释放后(0,1,0),Pender获取锁变为(0,0,1),最终释放。
(0,0,1) -> (0,1,1) -> (0,1,0) -> (0,0,1) -> (*,*,0)
- uncontended queue (第三个CPU加入,形成队列):
- 在
(0,1,1)状态下,第三个CPU加入成为队列中唯一的等待者(既是Successor也是队尾),状态变为(n,x,y)。待Owner和Pender都释放后(n,0,0),Successor获取锁(0,0,1)。
(0,1,1) -> (n,x,y) -> (n,0,0) -> (0,0,1) -> (*,*,0)
- contended queue (队列已存在,新CPU加入):
- 在
(n,x,y)状态下,新CPU加入队尾,状态不变。当前Successor获取锁后,会唤醒其后继者成为新的Successor。
(n,x,y) -> (*,x,y) -> (*,0,0) -> (*,0,1) -> (*,*,0)
值得注意的是,这4种状态并非在所有竞争场景下都会出现。仅2个CPU竞争时,只出现uncontended和pending;3个CPU竞争时,增加uncontended queue;超过3个CPU竞争时,所有状态才会完全出现。
理解了状态机后,我们分段查看代码。第一部分主要处理仅有Owner和Pender的两个CPU竞争场景,逻辑相对直接。
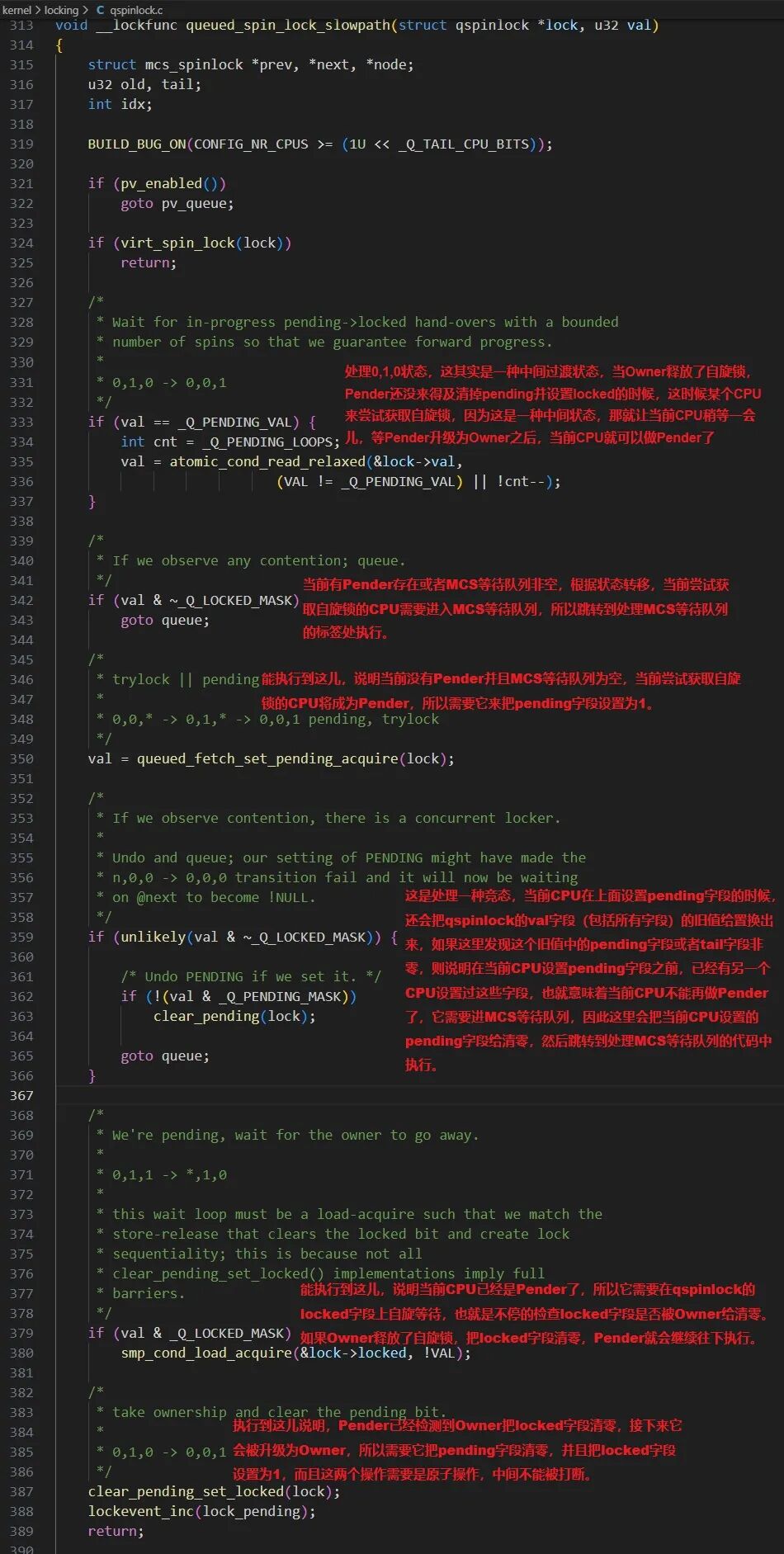
第二部分代码负责获取当前CPU的MCS节点,将qspinlock的tail指向该节点,并将其链接到MCS队列末尾。如果原队列不为空,则当前CPU作为Queuer,在自己的MCS节点locked字段上自旋。
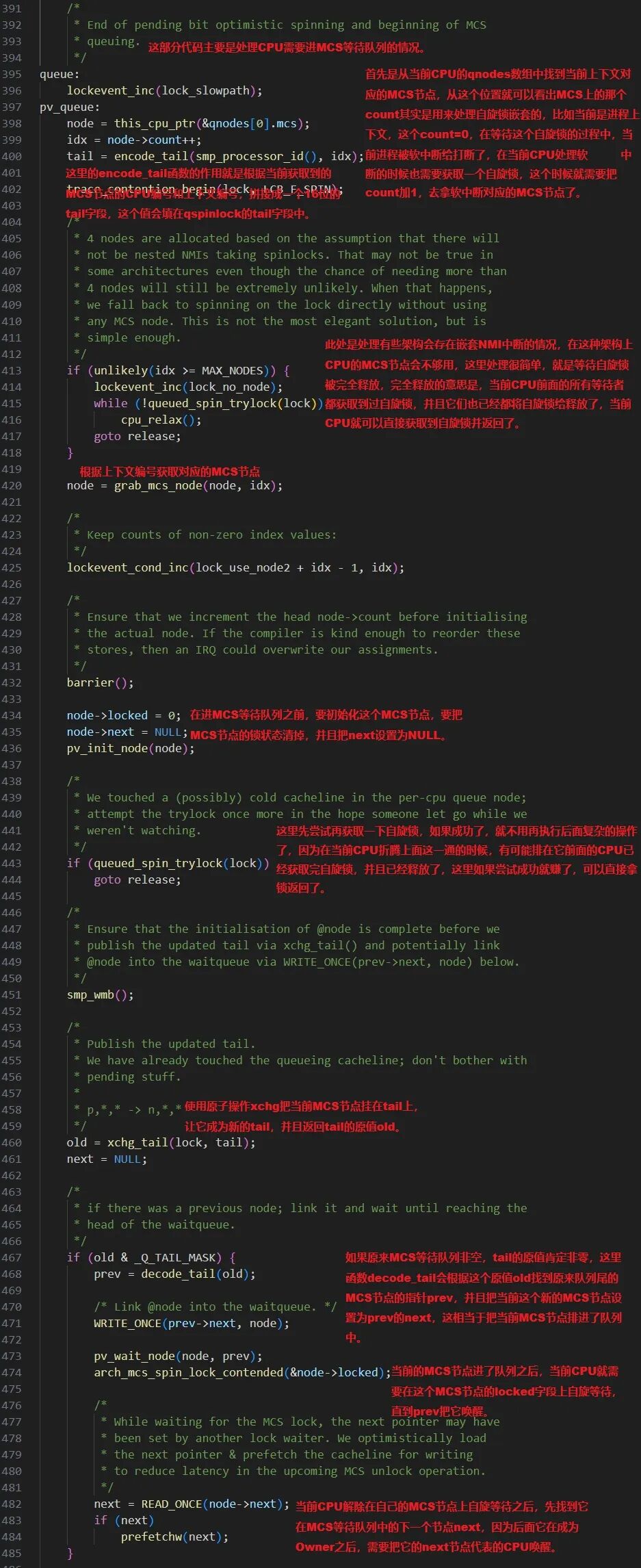
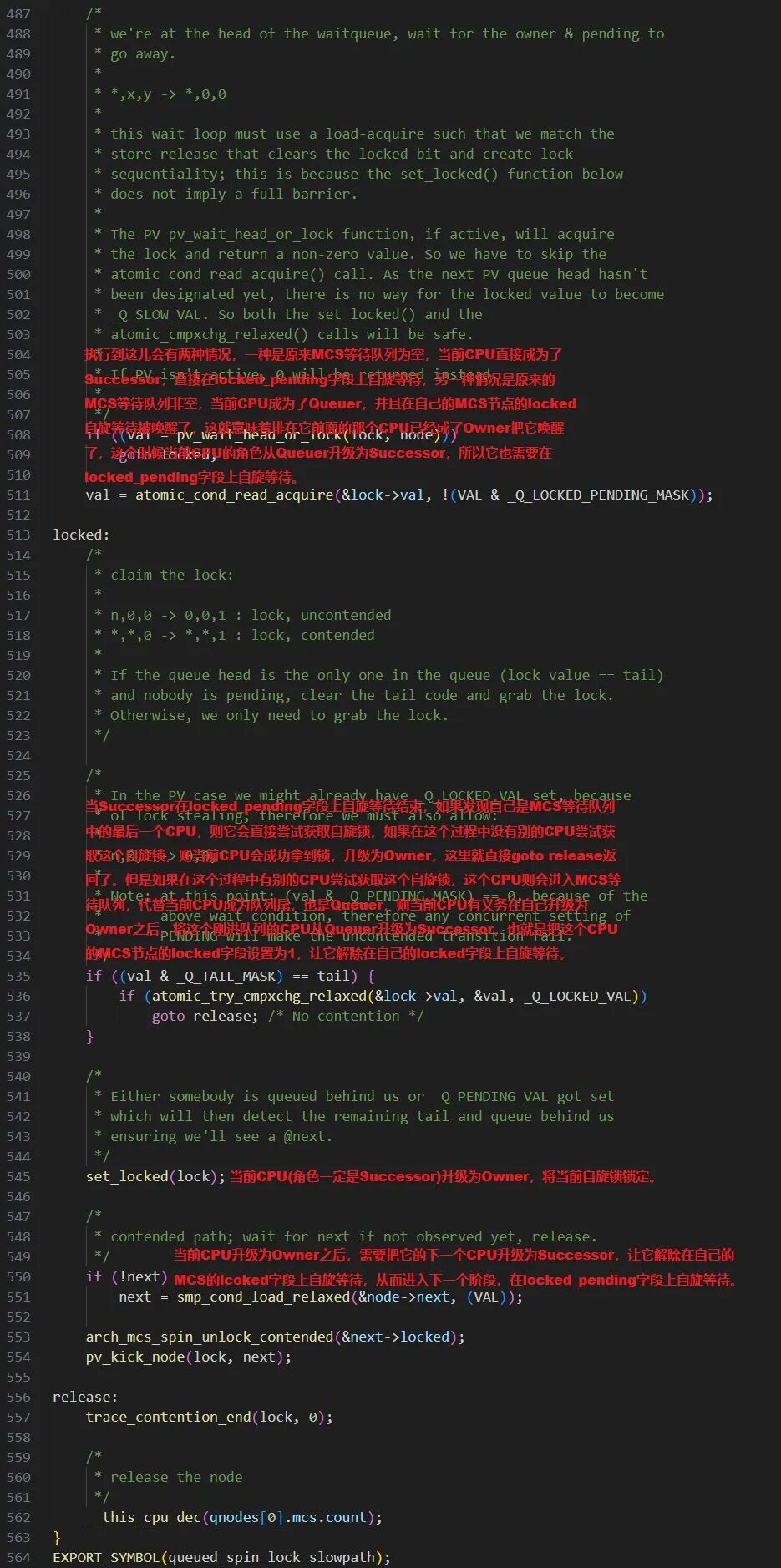
如果判断原队列为空,则当前CPU成为Successor(队首),它将进入第三段代码的逻辑。这部分主要完成两项关键工作:一是将队列中的Successor升级为Owner;二是将原Successor的后继者唤醒,使其成为新的Successor(即解除其在自身MCS节点上的自旋,转为在locked_pending上等待)。这也解释了为何queued_spin_unlock仅清零locked字段,而唤醒后继者的逻辑被整合到了queued_spin_lock_slowpath中,这是为了优化性能而做的设计权衡。
通过对Queued Spin Lock原理的剖析,我们可以看到Linux内核在并发同步原语设计上如何极致地权衡利弊:
- 保证公平性:基于FIFO的MCS队列确保先到先得。
- 渐进式竞争处理:根据竞争者数量动态选择路径(无竞争 → pending优化 → 完整队列)。
- 最小化开销:两个CPU竞争时避免昂贵的队列操作。
- 缓解激烈竞争:超过两个竞争者时启用MCS队列,有效避免缓存行颠簸(Cacheline Bouncing)导致的性能劣化,这是并发编程中高性能锁设计的核心考量之一。
|
 发表于 2025-12-24 09:12:08
|
查看: 273|
回复: 0
发表于 2025-12-24 09:12:08
|
查看: 273|
回复: 0
