什么是SDD?
规范驱动开发(Specification-Driven Development,简称SDD),是一种规范优先的开发模式。其核心思想是将那些约定俗成的规范、沟通达成的决策,沉淀为结构化的文档(通常使用Markdown格式),并以此驱动AI进行设计、开发和测试。而开发者的主要职责则转变为编写规范、审阅AI生成的设计与代码。
OpenSpec的使用
OpenSpec 是一个面向AI助手的、基于SDD理念构建的开源工具。你可以通过其 GitHub 仓库 了解更多信息并进行安装。
项目初始化
以在Cursor中集成使用为例,首先通过openspec init命令对项目进行初始化。执行后,会观察到项目根目录下新增了一个AGENT.md文件和/openspec文件夹,目录结构大致如下:
openspec/
├── changes/
│ ├── arhive/
├── AGENTS.md
├── project.md
AGENT.md
同时,在项目的.cursor目录下会新增三个预定义的命令文件:
.cursor/commands/
├── openspec-apply.md
├── openspec-archive.md
├── openspec-proposal.md
打开初始化生成的openspec/AGENT.md文件,其核心内容定义了一个三阶段的工作流:
## Three-Stage Workflow
### Stage 1: Creating Changes
Create proposal when you need to:
- Add features or functionality
- Make breaking changes (API, schema)
- Change architecture or patterns
- Optimize performance (changes behavior)
- Update security patterns
Triggers (examples):
- "Help me create a change proposal"
- "Help me plan a change"
- "Help me create a proposal"
- "I want to create a spec proposal"
- "I want to create a spec"
Loose matching guidance:
- Contains one of: `proposal`, `change`, `spec`
- With one of: `create`, `plan`, `make`, `start`, `help`
Skip proposal for:
- Bug fixes (restore intended behavior)
- Typos, formatting, comments
- Dependency updates (non-breaking)
- Configuration changes
- Tests for existing behavior
**Workflow**
1. Review `openspec/project.md`, `openspec list`, and `openspec list --specs` to understand current context.
2. Choose a unique verb-led `change-id` and scaffold `proposal.md`, `tasks.md`, optional `design.md`, and spec deltas under `openspec/changes/<id>/`.
3. Draft spec deltas using `## ADDED|MODIFIED|REMOVED Requirements` with at least one `#### Scenario:` per requirement.
4. Run `openspec validate <id> --strict` and resolve any issues before sharing the proposal.
### Stage 2: Implementing Changes
Track these steps as TODOs and complete them one by one.
1. **Read proposal.md** - Understand what‘s being built
2. **Read design.md** (if exists) - Review technical decisions
3. **Read tasks.md** - Get implementation checklist
4. **Implement tasks sequentially** - Complete in order
5. **Confirm completion** - Ensure every item in `tasks.md` is finished before updating statuses
6. **Update checklist** - After all work is done, set every task to `- [x]` so the list reflects reality
7. **Approval gate** - Do not start implementation until the proposal is reviewed and approved
### Stage 3: Archiving Changes
After deployment, create separate PR to:
- Move `changes/[name]/` → `changes/archive/YYYY-MM-DD-[name]/`
- Update `specs/` if capabilities changed
- Use `openspec archive <change-id> --skip-specs --yes` for tooling-only changes (always pass the change ID explicitly)
- Run `openspec validate --strict` to confirm the archived change passes checks
这三个阶段分别对应Cursor中生成的三个命令:
• 创建提案:/openspec-proposal
• 实施变更:/openspec-apply
• 归档变更:/openspec-archive
能力扩展
为了让AI更精准地理解项目并高效地执行维护任务,可以对OpenSpec的默认配置进行能力扩展。
project.md
首先需要修改openspec/project.md文件,补充项目的核心信息,形成AI开发的基准上下文。这包括:
• 项目描述与技术栈架构
• 开发约定与策略(如代码规范)
• 业务核心概念与流程
• 上下文知识库路径(docs/context/)及其维护规范:
## 上下文知识库
系统维护了一套完整的上下文知识库文档(`docs/context/`),用于记录各业务模块的实现现状、技术细节和关键知识点。这些文档在每次OpenSpec变更归档后会同步更新,确保知识积累的持续性。
openspec/AGENT.md
-
强化change-id约束:
明确要求使用Jira任务ID作为唯一标识(如 XXX-16666),便于需求追溯。这需要修改AGENT.md中关于change-id生成的指引部分,使其符合项目管理规范,这对于云原生/IaaS项目的标准化管理尤为重要。
## 快速检查清单
...
- 选择唯一的 `change-id`:取自jira的id,示例:XXX-16666,唯一,如果无法确定,则向提案人提问获取
...
## 创建变更提案
### 提案结构
1. **创建目录:** `changes/[change-id]/`(change-id 取自jira的id,示例:XXX-16666,唯一,如果提案里没有给出,则向提案人提问获取)
...
-
扩展“阶段 2:实施变更”:
新增实施衍生文档的生成要求,确保开发过程可追溯、知识可沉淀。
### 阶段 2:实施变更
...(中间部分省略)
7. **创建衍生文档** - 在 `docs/derivatives/[change-id]/` 目录下生成实施相关的文档:
- 配置文档(config-*.md):参数配置、环境变量等
- 接口文档(api-*.md):API 接口定义、请求/响应格式等
- 总结文档(implementation-summary-*.md):实施要点、关键决策、注意事项等
- 测试指南(test-guide-*.md):测试场景、测试步骤等
- 其他相关的技术文档
-
扩展“阶段 3:归档变更”:
强化知识库同步更新机制,确保系统状态与文档完全同步。
### 阶段 3:归档变更
...(中间部分省略)
- **更新上下文知识库** - 归档后必须更新 `docs/context/` 目录下相关模块的上下文文档:
- 识别变更影响的业务模块或技术模块
- 更新对应的上下文文档(如 `docs/context/process-order.md`、`docs/context/param-config.md` 等)
- 将新增的需求、场景、设计决策等关键信息同步到上下文文档中
- 确保上下文文档反映最新的系统状态和知识积累
经过上述扩展,项目的目录结构将更加清晰和完善,如下所示:
openspec/
├── project.md # 项目全局约定与规范
├── specs/ # 当前“真相” - 已构建的内容规范
│ └── [capability]/ # 单一聚焦的功能域
│ ├── spec.md # 需求和场景定义
│ └── design.md # 技术模式与决策
├── changes/ # 进行中的提案 - 计划更改的内容
│ ├── [change-id]/ # 以Jira ID命名的变更目录
│ │ ├── proposal.md # 变更原因、内容、影响分析
│ │ ├── tasks.md # 详细的实施检查清单
│ │ ├── design.md # 具体技术决策(可选)
│ │ └── specs/ # 增量变更规范
│ │ └── [capability]/
│ │ └── spec.md # ADDED/MODIFIED/REMOVED 需求
│ └── archive/ # 已完成的变更历史
docs/
├── derivatives/ # 实施过程衍生文档
│ └── [change-id]/ # 按变更ID组织
│ ├── config-*.md # 配置文档
│ ├── api-*.md # 接口文档
│ ├── implementation-summary-*.md # 实施总结
│ ├── test-guide-*.md # 测试指南
│ └── ... # 其他技术文档
└── context/ # 核心上下文知识库(随归档更新)
├── [module].md # 各模块的知识积累
└── ... # 业务/技术上下文文档
SDD模式开发实践
基于一段时间的探索,我们初步总结出一套适用于日常需求的开发流程。以下以“加工单上架”需求为例,回顾具体实践过程。
0. 需求背景
任何需求,无论大小,都源于特定的业务背景和目标。它可能是一段简短描述,也可能是一份完整的产品需求文档(PRD)。
1. 梳理相关知识库
根据PRD内容,定位需求所依赖的核心功能模块,并梳理出对应的上下文知识库文档。例如,“加工单上架”需求涉及以下模块:
• 加工单模块:docs/context/process-order.md
• 上架模块:docs/context/putaway.md
• 参数配置模块:docs/context/param-config.md
• 状态管理机制:docs/context/status-management.md
• 异常处理机制:docs/context/exception-handling-guidelines.md

注:如果某个模块缺失对应的上下文知识库文档,可以引导AI基于现有代码进行反向分析并生成初始版本进行补充。


2. 润色PRD
对原始PRD进行结构化处理,利用Markdown语法突出关键信息,这能显著提升AI的理解精度:
• 核心功能(使用标题、列表、加粗进行强调)
• 约束条件(使用列表、加粗、斜体进行标注)
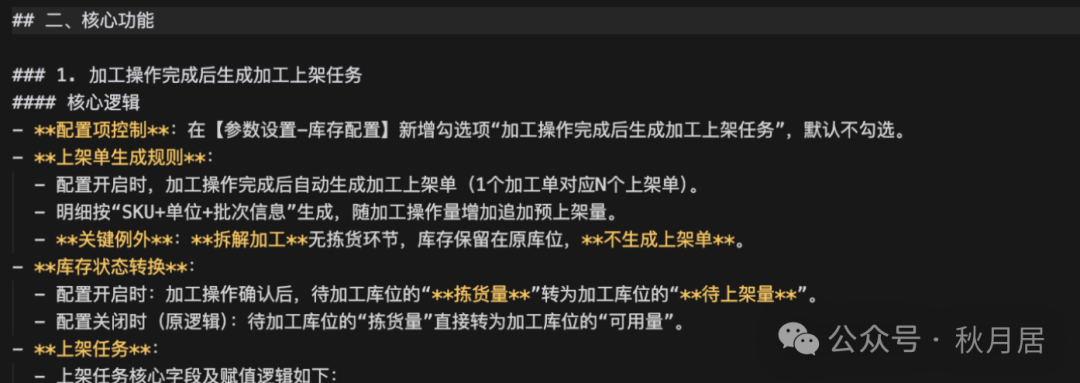

3. 生成设计文档与评审
结合润色后的PRD和已梳理的项目上下文知识库,在Cursor中通过/openspec-proposal命令创建变更提案。AI将据此生成初步的设计文档与详细设计报告。
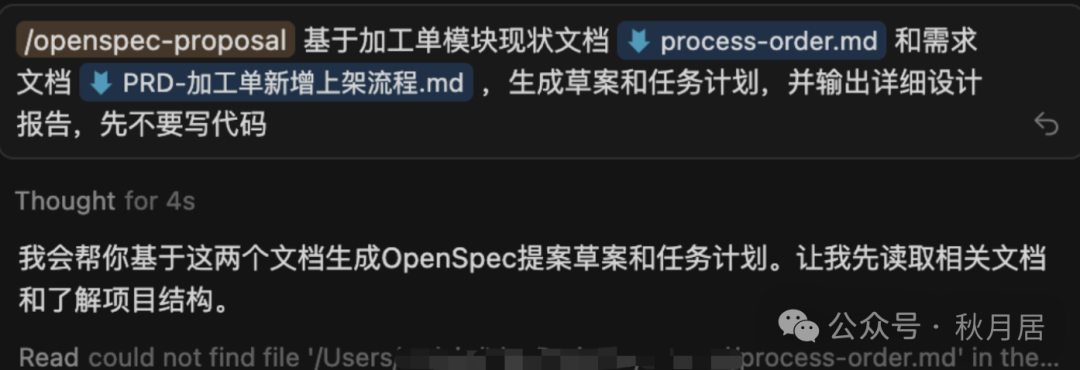
生成的文档通常包含:
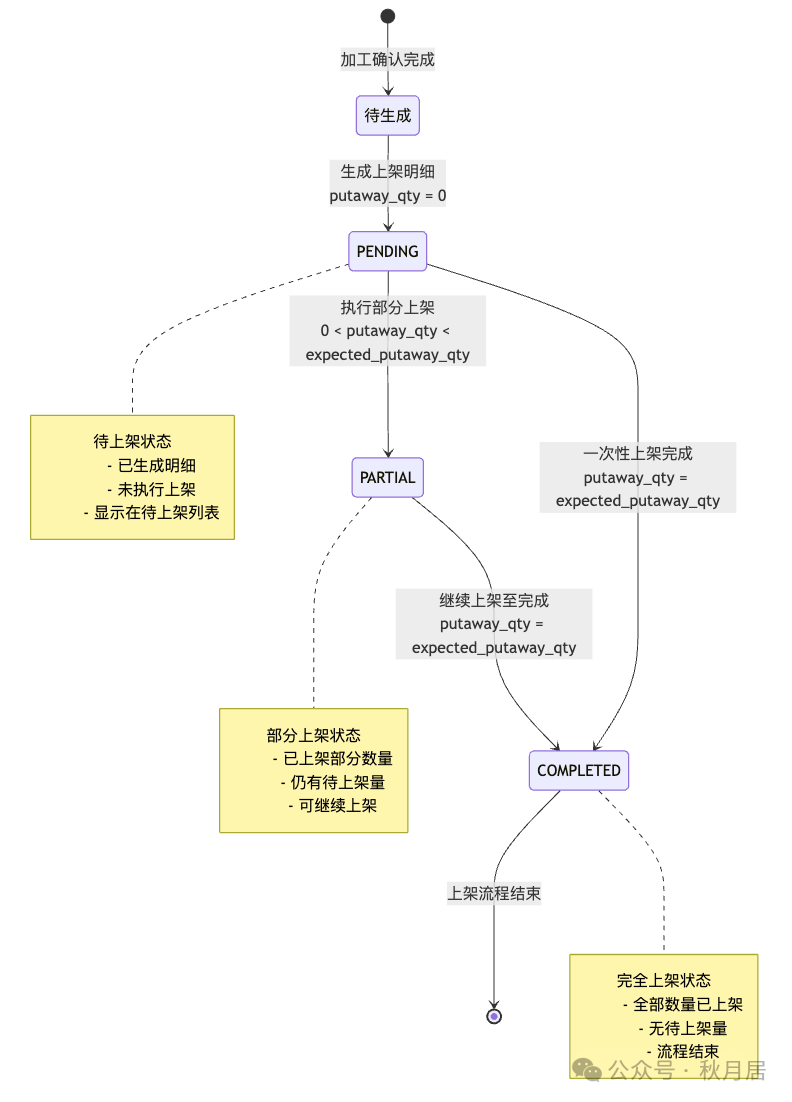
• 状态机设计:定义上架任务的状态流转逻辑(如待上架 → 部分上架 → 完全上架)。
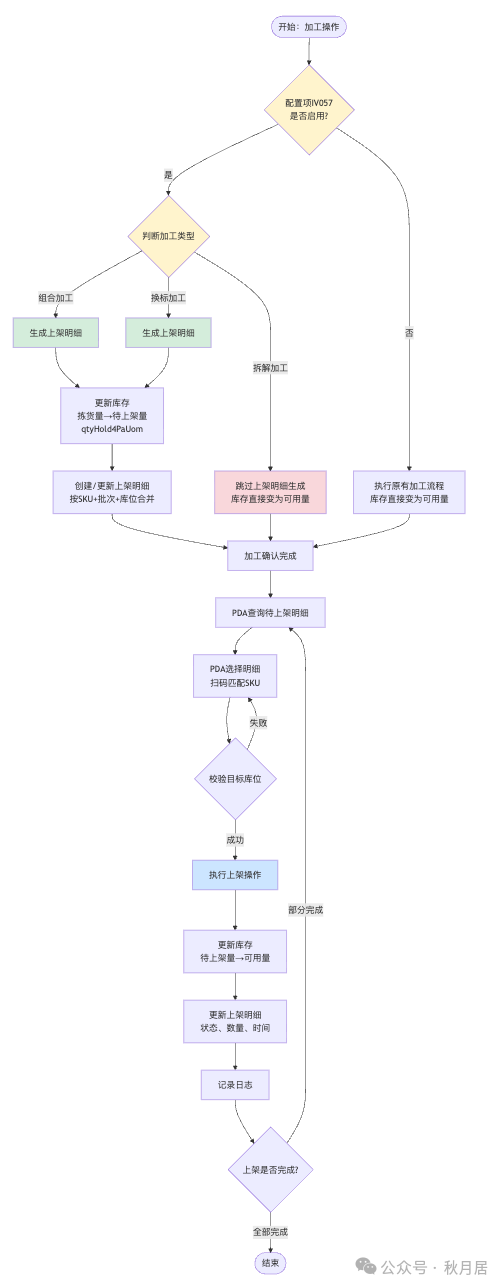
• 流程设计:绘制从加工单操作完成到触发创建上架任务的业务流程图。
• 类图设计
• 数据模型设计
• 接口设计
整理AI输出的设计文档后,组织产品、开发、测试等相关同学进行设计评审,确认:
• 状态流转逻辑是否正确。
• 业务流程是否符合需求预期。
• 涉及的接口、类、数据模型设计是否准确且符合项目规范。
在实际操作中,AI设计的宏观流程通常没有问题,问题往往出在具体的实现细节上。
4. 生成任务清单(To-do List)
在上一步执行/openspec-proposal命令的同时,AI会生成一份详细的实施任务清单tasks.md,将开发工作拆解为具体的、可执行的任务项。
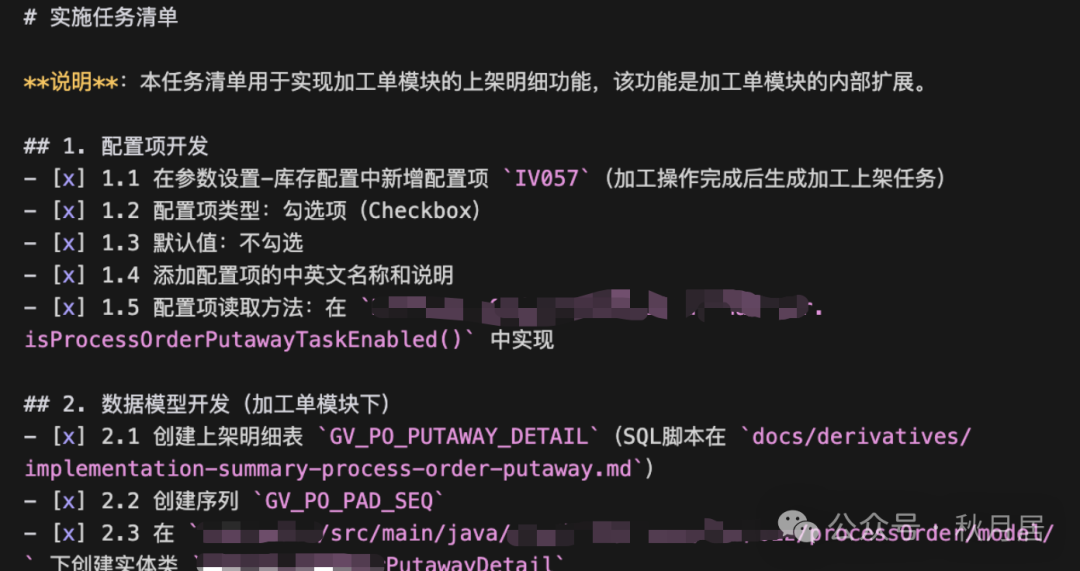
5. 检查与优化任务清单
结合需求本身与生成的任务清单,可以分两步进行优化:
- 先让AI自检:要求AI检查任务清单的完整性、逻辑顺序以及是否有遗漏的边界情况。
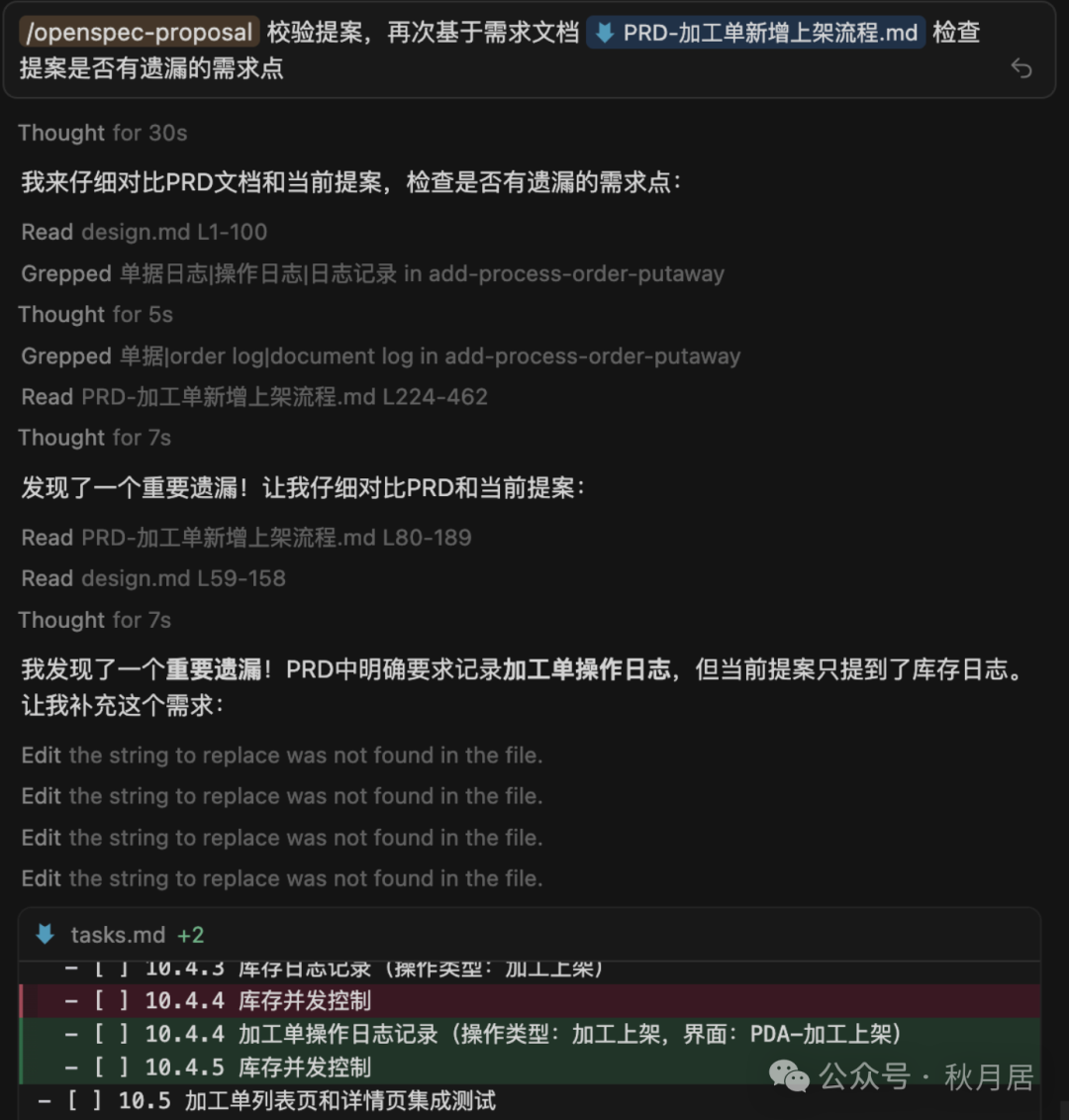
- 再进行人工Review:开发者基于自身经验,补充AI可能遗漏的关键任务或技术细节。
6. 按任务清单实施开发
在Cursor中输入/openspec-apply命令,开始依据tasks.md实施开发。在AI编写代码的过程中,开发者需要持续进行代码评审,及时澄清模糊需求,并校正AI在实现上不规范或错误的地方。这个过程对优化前端框架/工程化和后端架构的实现模式都很有帮助。
7. 测试验证
• AI辅助测试:要求AI生成核心代码的单元测试用例。
• 人工测试:开发者执行测试用例,进行功能验证。
现状:在实践中发现,AI生成的单元测试质量往往不尽如人意,这部分仍需持续探索和人工主导。
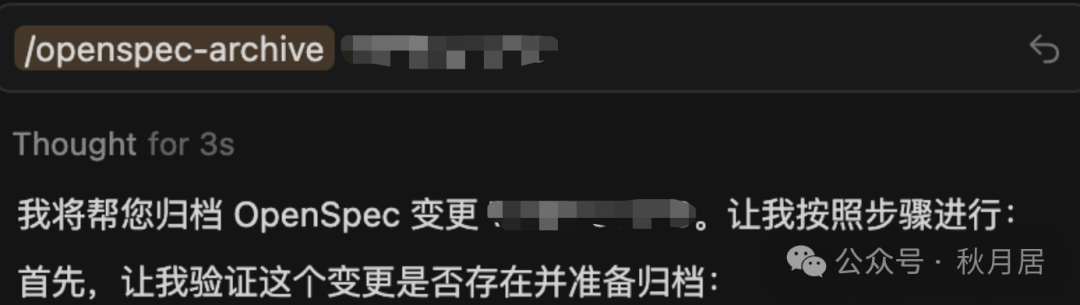
8. 归档与更新知识库
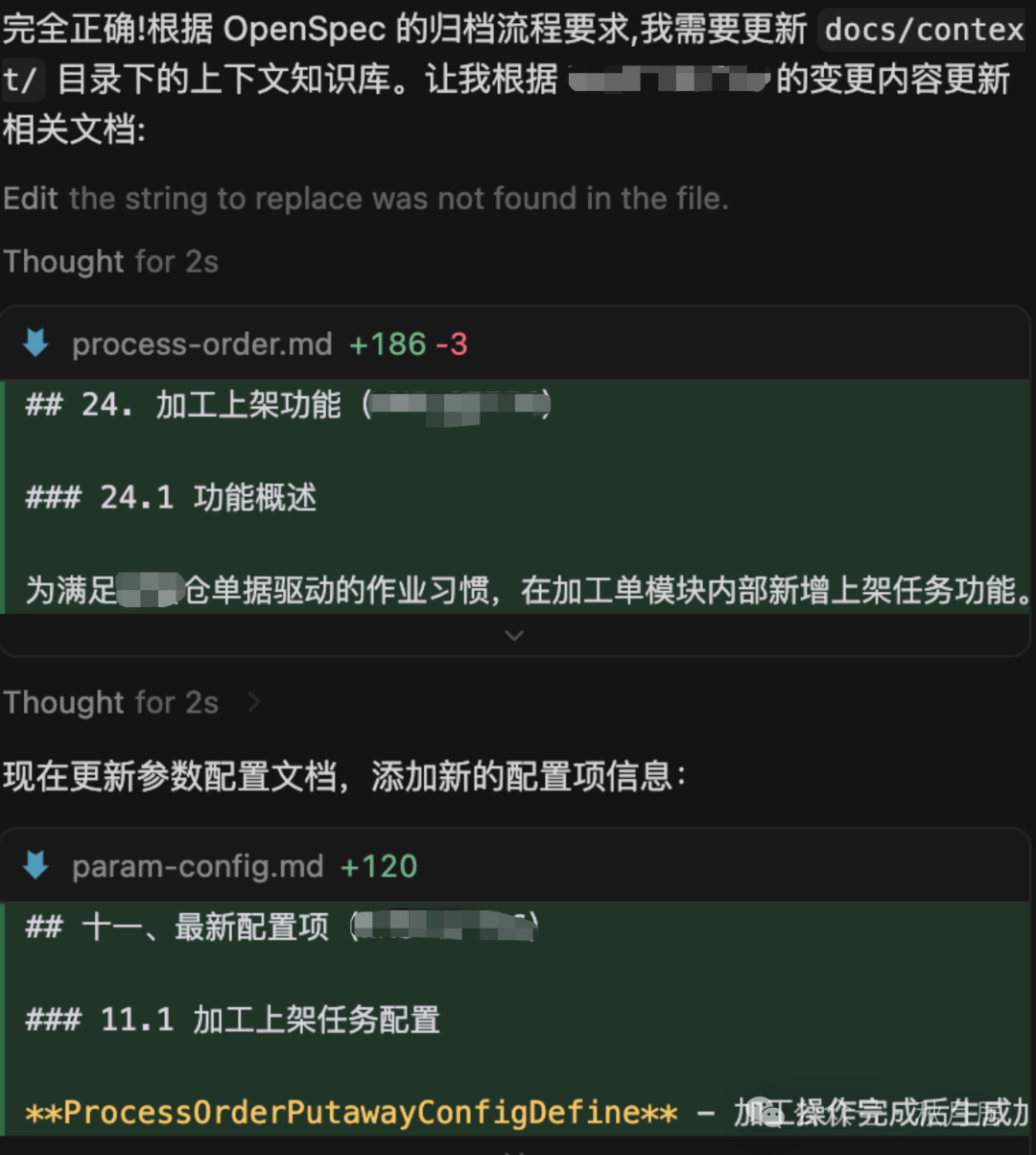
开发与测试完成后,通过/openspec-archive命令对此次变更进行归档。归档过程会自动触发知识库更新机制:
• 在docs/context/process-order.md中补充“加工单上架任务”相关的业务逻辑。
• 在docs/context/param-config.md中补充本次新增的参数配置项及其说明。
实践心得
• 知识库是SDD的核心基石:完善、准确的上下文知识库(涵盖业务核心流程、功能模块规范等)是避免AI“想当然”开发的关键。接到需求后,开发者首先要理解需求,并抽取出所依赖的功能模块,在创建提案时将这些模块知识库告知AI,能极大提升AI设计与开发的规范性。
• PRD润色直接决定开发精度:产品提供的原始PRD多为面向人的叙述,AI可能无法准确识别重点。在创建提案前,用Markdown语法对PRD进行结构化润色,突出核心功能与约束条件,能有效减少后续的遗漏和偏差。
• 设计评审环节不可替代:人工介入设计评审,能够在早期发现AI可能忽略的业务场景和设计缺陷(如接口字段设计不合理),显著减少开发后期的返工成本。
• 小粒度需求更适配当前SDD:考虑到大语言模型的上下文窗口限制,过于复杂庞大的需求容易导致上下文过载,影响AI表现。建议将大需求拆分为聚焦1-2个核心功能的、粒度更小的任务,分次迭代完成。
• 实现知识库的闭环迭代:要求每次变更归档后,必须更新相关模块的上下文知识库。这形成了“开发→沉淀→复用”的良性循环,为后续的需求开发提供了更全面、准确的上下文,是提升团队运维/DevOps效率的关键。
小声哔哔
• 是银弹还是毒药?:当前AI编程工具热潮汹涌,管理者们常视其为提效“银弹”,并被各种炫酷演示所吸引。然而,在实际开发中,开发者深知,在那些看似惊喜的生成结果之下,往往隐藏着需要大量时间处理的“魔鬼细节”。时间并未被真正“节省”,而是转移到了整理文档、制定规范、反复评审代码以及与AI沟通澄清需求上。工具的价值,最终仍取决于使用者的方法与投入。
 发表于 2025-12-25 01:42:11
|
查看: 405|
回复: 0
发表于 2025-12-25 01:42:11
|
查看: 405|
回复: 0
