在Linux并发编程的世界里,线程栈扮演着程序运行“幕后推手”的关键角色,却也潜藏着诸如栈溢出崩溃、配置不当引发的性能瓶颈等“隐形陷阱”。深入理解其底层原理,是编写稳定、高效多线程程序的必修课。
本文将系统剖析Linux线程栈的工作原理,厘清其与进程栈的核心差异,并结合实际开发场景,详解栈溢出的成因、排查工具与方法,最终提供栈大小优化、内存使用精简等实战策略。无论您是刚接触多线程编程,还是正在解决棘手的并发性能问题,都能从中获得启发。
一、线程栈基础:原理与差异
线程栈是每个线程独有的一块内存区域,用于存储函数调用过程中的局部变量、参数、返回地址等临时数据。其工作方式如同一个“后进先出”的临时仓库,保障了每个线程执行的独立性。
在Linux系统中,线程与进程虽统一由task_struct表示,但其栈管理机制存在本质区别:
- 进程栈(主线程):在
fork()时通过写时拷贝机制复制父进程地址空间,并支持动态向下增长(直至触及资源上限)。访问未映射页不会立即出错,仅在扩展超限时报错。
- 子线程栈:由
pthread_create()创建,其栈空间是在进程的共享内存区域中通过mmap()预先分配的固定大小内存,无法动态增长。一旦耗尽即导致栈溢出(如无限递归会立刻触发段错误)。该栈虽为线程私有,但因同一进程的所有线程共享地址空间,其他线程仍可能通过指针访问到它,需注意线程安全与同步问题。
Linux线程的实现由两部分协同完成:一是用户态的glibc库(提供pthread_create等接口),二是内核态的clone系统调用(负责创建共享地址空间的轻量级进程)。当需要分配新栈时,若无法从缓存获取,glibc会通过mmap申请一块匿名内存页。
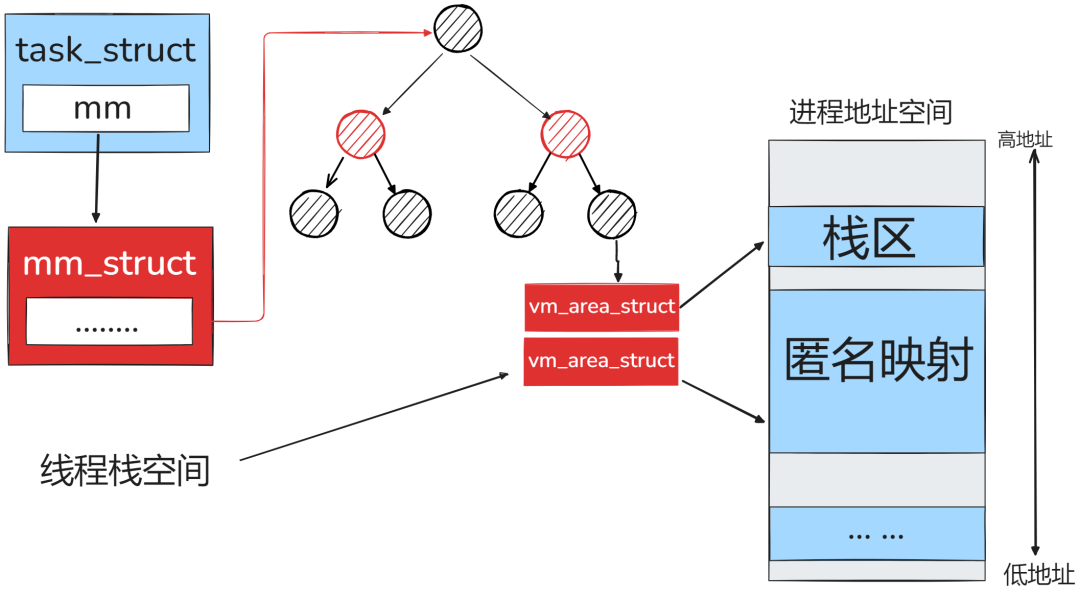
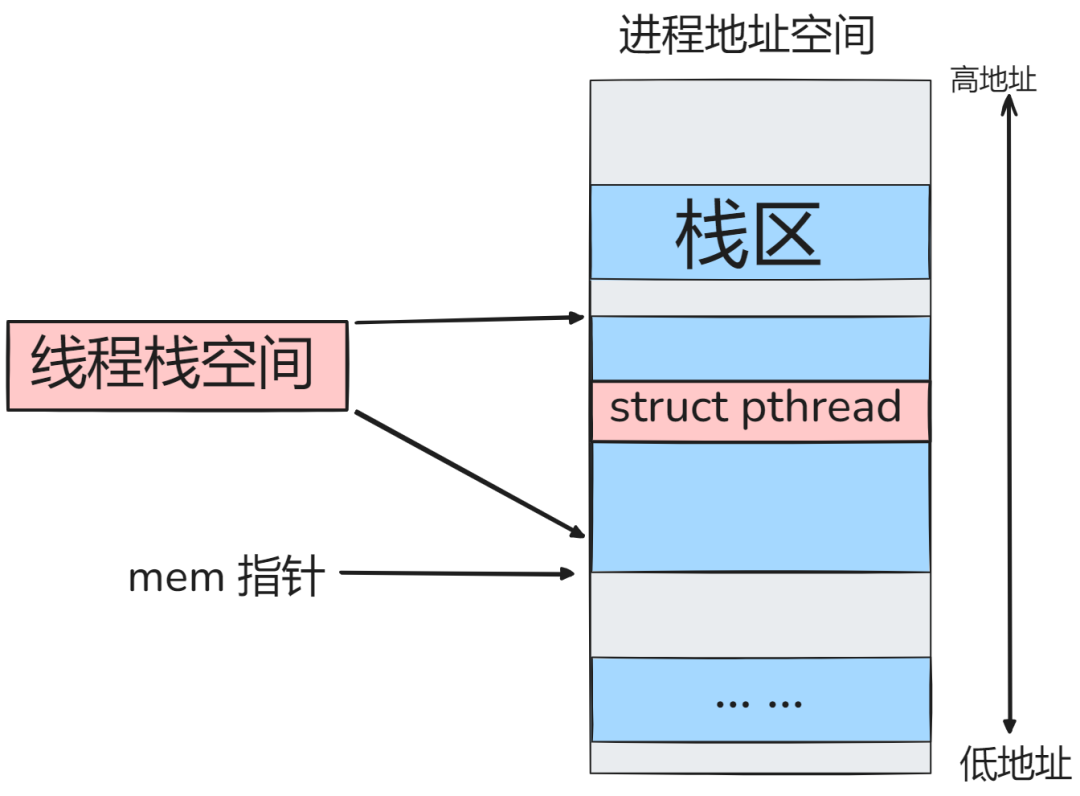
申请到的内存区域(低地址起始)会经过精密计算与对齐,将线程控制结构体struct pthread放置在高地址端,剩余部分则作为实际的运行栈空间。这种设计将元数据与运行栈紧凑结合,提升了内存利用效率。
二、线程栈的工作原理
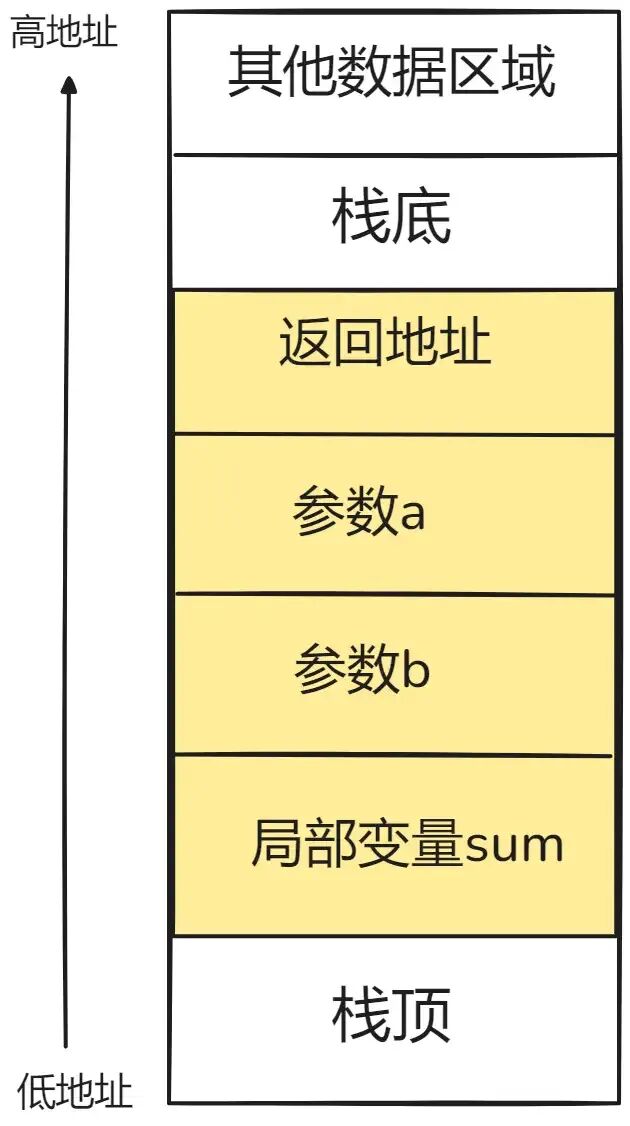
2.1 内存布局与生长方向
线程栈的内存布局清晰有序:栈底位于高地址,栈顶位于低地址,栈的生长方向是从高地址向低地址延伸。每次函数调用,参数、返回地址、局部变量等会被依次“压入”栈中;函数返回时,这些数据再被“弹出”。
例如,对于函数:
int add_numbers(int a, int b) {
int sum = a + b;
return sum;
}
调用时,参数a、b和局部变量sum会按规则入栈。函数返回后,这些数据占用的栈空间被释放。下图直观展示了此过程:
2.2 线程栈的创建与配置
线程通过pthread_create函数创建:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg);
若attr参数为NULL,则使用默认栈大小(通常为8MB,可通过ulimit -s查看或修改)。如需自定义,需使用pthread_attr_t相关函数:
#include <pthread.h>
#include <stdio.h>
void* thread_function(void* arg) {
// 线程执行的代码
return NULL;
}
int main() {
pthread_t new_thread;
pthread_attr_t attr;
size_t stack_size = 2 * 1024 * 1024; // 2MB
pthread_attr_init(&attr);
pthread_attr_setstacksize(&attr, stack_size); // 设置自定义栈大小
if (pthread_create(&new_thread, &attr, thread_function, NULL) != 0) {
perror("Failed to create thread");
return 1;
}
pthread_join(new_thread, NULL);
pthread_attr_destroy(&attr);
return 0;
}
2.3 线程栈与进程的关系
同一进程下的多个线程共享进程的地址空间(代码段、数据段、堆等),但各自拥有独立的栈。这种机制的优势在于线程间通信高效(无需跨进程),但也带来了风险:共享数据的并发访问需谨慎同步,且一个线程的栈溢出等问题可能波及整个进程。
三、常见问题与排查手段
3.1 栈溢出 (Stack Overflow)
栈溢出通常由过深的函数调用(尤其是无限递归)或过大的局部变量引发,导致程序触发段错误(Segmentation Fault)。
#include <stdio.h>
void recursive_function() {
int large_array[1000000]; // 巨大的栈上数组
recursive_function(); // 无限递归,无终止条件
}
int main() {
recursive_function();
return 0;
}
运行上述程序将快速耗尽栈空间并崩溃。
3.2 内存泄漏
线程结束后,若其栈内存未被正确释放(如未pthread_join也未设置detach属性),会导致内存泄漏。可使用valgrind工具检测:
valgrind --leak-check=full --show-leak-kinds=all ./your_program
3.3 排查工具
top/htop:查看进程/线程的实时资源占用(top -H -p [PID])。pstack:打印进程中所有线程的调用栈,快速定位问题线程及调用链(pstack [PID])。gdb:强大的调试器。附加到进程(gdb -p [PID])后,使用info threads查看线程,thread [TID]切换线程,bt查看当前线程的调用栈回溯,进行深入分析。
四、优化策略与实践
4.1 合理调整栈大小
- 临时调整:
ulimit -s [SIZE_KB](如 ulimit -s 16384 设为16MB)。
- 永久调整:编辑
/etc/security/limits.conf文件,为相应用户设置soft stack和hard stack限制。
- 编程设置:如第二章所示,使用
pthread_attr_setstacksize在创建线程时指定。
4.2 减少栈内存使用
4.3 应用线程池
频繁创建销毁线程开销大。使用线程池可复用线程,避免栈内存的反复分配与释放,是提升并发程序性能的经典方案。池中的线程数量应根据任务类型(CPU密集型或I/O密集型)合理配置。
五、实战案例:游戏服务器栈溢出排查
5.1 背景
某在线游戏服务器(多线程架构)随玩家数增加频繁崩溃,日志中出现大量段错误。监控显示系统资源未达极限,但处理复杂游戏逻辑的线程常出问题。
5.2 排查
ulimit -s 确认默认栈大小为8MB。- 在崩溃时使用
pstack [PID]检查问题线程,发现其调用栈极深,指向一个递归函数。
- 通过
gdb附加分析,bt命令进一步确认存在无限递归,且递归函数内声明了大数组,共同导致栈空间耗尽。
5.3 解决
- 修复递归逻辑:为递归函数添加明确的终止条件,并设置最大深度限制。
- 转移大数据到堆:将递归函数中的大数组改为从堆上动态分配。
- 代码加固:引入智能指针(如C++的
std::unique_ptr)管理堆内存,确保异常安全;增加栈深度监控与预警。
优化后,服务器经过压力测试运行稳定,未再发生栈溢出崩溃。此案例凸显了理解线程栈特性、合理设计递归算法与内存使用模式的重要性。
 发表于 2025-12-25 08:25:58
|
查看: 152|
回复: 0
发表于 2025-12-25 08:25:58
|
查看: 152|
回复: 0
