
前言
随着人工智能工具生态的快速发展,其能力扩展方式也在不断演进。从标准化的数据接口(如Model Context Protocol,即 MCP)到更聚焦于封装工作流程的Agent Skills,AI正在学习如何更深入地理解并执行人类的专业任务。其中,Agent Skills(https://agentskills.io) 规范允许脚本(通常位于scripts/目录)使用Python、Bash、JavaScript等多种语言。而.NET 10 引入的 File-Based Apps特性,为编写这类脚本提供了一个强有力的新选项:仅需一个.cs文件即可运行,具备内联依赖、跨平台及Native AOT编译等特性。
本文旨在解析Agent Skills规范,并详细演示如何利用 .NET File-Based Apps 编写既高效又可靠的Skill脚本。你将看到,.NET凭借其类型安全、高性能和出色的跨平台能力,为Agent Skills的脚本开发带来了独特的优势。
一、什么是 Agent Skills?
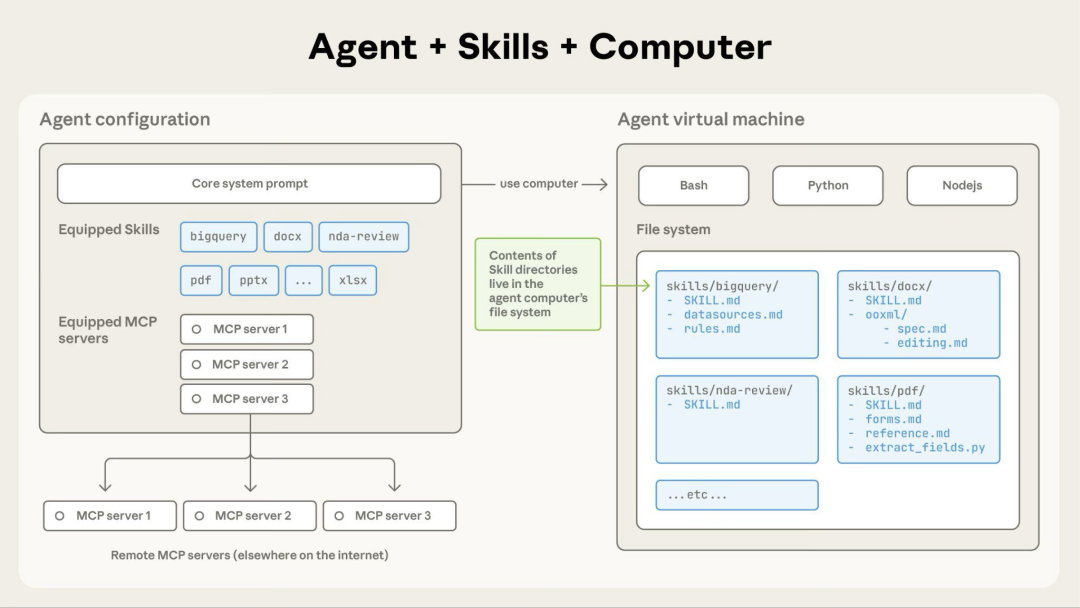
1.1 核心概念
Agent Skills是一种轻量级、开放式的格式,专门用于扩展AI Agent(智能体)的能力边界和知识深度。其本质非常简单:一个Skill就是一个包含核心文件SKILL.md的文件夹。
该核心文件通常包含:
- 元数据:最基础的
name和description。
- 指令:一份告诉Agent如何执行特定任务的Markdown文档。
- 可选资源:可执行脚本、模板文件、参考文档等。
Skills的核心价值体现在以下几个方面:
- 专业知识封装:将特定领域或团队的流程化知识和上下文打包成可复用的单元。
- 按需加载:Agent启动时仅加载所有Skill的名称和描述,仅在任务匹配时才加载完整的指令内容,优化资源使用。
- 可执行能力:通过包含脚本和工具,使Agent能够执行实际的操作。
- 版本化管理:Skills以文件形式存在,便于编辑、使用Git进行版本控制以及团队间共享。
1.2 Agent Skills 能做什么?
根据官方定义,Agent Skills主要应用于以下场景:
领域专长
将专业知识打包为可复用的指令集:
- 法律审查流程:标准化的合同审查清单与审批流。
- 数据分析管道:统一的数据清洗、转换与可视化工作流。
- 代码审查规范:团队内部的编码标准、安全及性能审查指南。
- 医疗诊断协议:基于症状的标准诊断路径与治疗建议流程。
新能力赋予
为Agent拓展原本不具备的实操能力:
- 创建演示文稿:根据给定内容自动生成PPT或Keynote。
- 构建MCP服务器:生成符合Model Context Protocol规范的服务器代码。
- 分析数据集:执行统计分析并生成可视化图表。
- 处理PDF文档:拆分、合并、提取文本或填写表单。
可重复工作流
将复杂的多步骤任务标准化为一致且可审计的流程:
- CI/CD流水线:标准化的构建、测试与部署步骤。
- 客户入职流程:账户创建、权限配置与培训材料发送。
- 月度报告生成:从数据收集、分析到报告编写与分发的完整流程。
- 代码重构任务:识别问题、建议改进、执行修改与验证测试的闭环。
跨工具互操作
实现“一次编写,多处使用”:
- 在 GitHub Copilot 中辅助编码。
- 在 Cursor 中进行项目重构。
- 在 Claude 中进行文档写作。
- 在 Goose 中执行自动化任务。
这种标准化使得组织内部的知识资产能够在不同的AI工具间无缝流转。
1.3 谁在支持 Agent Skills?
目前,该标准已获得多个主流AI开发工具的支持:

二、Agent Skills 规范解读
2.1 基本目录结构
一个最简单的Skill仅需包含SKILL.md文件:
skill-name/
└── SKILL.md # 必需
完整的目录结构可包含以下可选部分:
skill-name/
├── SKILL.md # 必需:技能描述和使用说明
├── scripts/ # 可选:可执行脚本
│ └── tool.py
├── references/ # 可选:详细参考文档
│ └── REFERENCE.md
└── assets/ # 可选:静态资源
└── template.json
2.2 SKILL.md 格式规范
SKILL.md文件由两部分构成:YAML前置元数据(frontmatter)和Markdown正文。
Frontmatter 必需字段
---
name: skill-name
description: 描述技能功能和使用场景的文字,应包含帮助 Agent 识别相关任务的关键词
---
name 字段规则:
- 长度:1-64个字符。
- 字符:仅允许小写字母、数字和连字符 (a-z,
-)。
- 不能以连字符开头或结尾。
- 不能包含连续的连字符 (
--)。
- 必须与父目录名完全一致。
description 字段规则:
- 长度:1-1024个字符。
- 应清晰说明技能的功能和适用时机。
- 包含关键词以帮助Agent准确识别匹配场景。
可选字段
---
name: pdf-processing
description: Extract text from PDFs and merge multiple documents
license: MIT
compatibility: Requires Python 3.8+ and poppler-utils
metadata:
author: your-org
version: "1.0.0"
---
2.3 渐进式信息披露
为了优化大型语言模型(LLM)的Token使用效率,Agent Skills采用了渐进式加载策略:
- 元数据阶段 (~100 tokens):Agent启动时,仅加载所有Skills的
name和description。
- 指令阶段 (推荐<5000 tokens):当某个Skill被激活时,才加载其完整的
SKILL.md文件内容。
- 资源阶段 (按需):仅在需要执行具体操作时,加载
scripts/、references/、assets/等目录中的文件。
最佳实践建议:
- 尽量保持
SKILL.md文件内容在500行以内。
- 将详细的参考资料移至
references/目录。
- 避免在核心指令文件中进行深层次的嵌套文件引用。
三、使用 .NET File-Based Apps 编写 Agent Skills 脚本
在深入实战之前,我们有必要探讨为何.NET File-Based Apps是编写Agent Skills脚本的上佳之选。
3.0 .NET 作为脚本语言的独特优势
根据规范,scripts/目录下的代码应做到自包含、依赖明确、错误信息友好。常见的Python、Bash等脚本语言固然不错,但.NET File-Based Apps提供了极具竞争力的替代方案。
对比其他脚本语言方案
在为Agent Skills编写可执行脚本时,.NET方案与其他语言对比如下:
| 特性 |
.NET File-Based Apps |
Python 脚本 |
Node.js 脚本 |
| 单文件运行 |
✅ dotnet file.cs |
✅ python file.py |
✅ node file.js |
| 依赖声明 |
✅ 文件内直接声明 |
⚠️ 需要requirements.txt |
⚠️ 需要package.json |
| 类型安全 |
✅ 编译时检查 |
❌ 多为运行时错误 |
⚠️ 需配合TypeScript |
| 性能 |
✅ 支持Native AOT编译 |
⚠️ 解释执行 |
⚠️ JIT编译 |
| 跨平台部署 |
✅ 可发布为单个可执行文件 |
⚠️ 需Python运行时 |
⚠️ 需Node.js运行时 |
| 企业级库支持 |
✅ 丰富的NuGet生态 |
✅ PyPI生态 |
✅ npm生态 |
| AI Agent可读性 |
✅ 结构清晰、强类型自文档化 |
✅ 语法简洁 |
✅ 语法简洁 |
.NET 的核心优势
1. 真正的自包含
依赖声明直接写在代码文件头部,AI Agent或开发者一目了然,无需额外查找配置文件。
#:package PdfSharpCore@1.3.65
#:package Spectre.Console@0.49.1
2. 从开发到生产无缝过渡
开发时直接用dotnet run执行.cs文件;生产时可一键发布为小巧、毫秒级启动的Native AOT原生可执行文件。
3. AI友好的代码结构
.NET的强类型系统和清晰的语法,让人工智能更容易理解代码意图、发现潜在问题并生成准确的修改建议。
3.1 什么是 .NET File-Based Apps?
.NET 10 引入的 File-Based Apps 特性,允许开发者将单个.cs文件作为完整的应用程序来运行,无需传统的.csproj项目文件。其关键特性包括:
- 单文件即应用:一个
.cs 文件包含所有程序逻辑。
- 内联依赖声明:通过特殊的注释语法(如
#:package)声明所需的NuGet包。
- 直接运行:使用
dotnet file.cs 命令即可执行。
- 支持发布:可以发布为独立应用或进行Native AOT编译。
- 零配置:无需创建
csproj、sln等任何项目文件。
3.2 File-Based Apps 如何适配 Agent Skills 需求?
Agent Skills规范强调“简洁”、“自包含”和“可理解”,而.NET File-Based Apps的设计理念与之高度契合:
适配点 1:渐进式复杂度
// 阶段一:10行代码的简单原型
#!/usr/bin/env dotnet
if (args.Length == 0) { Console.WriteLine("Hello, Agent!"); return; }
Console.WriteLine($"Processing: {args[0]}");
// 阶段二:添加企业级依赖和健壮的错误处理
#:package Newtonsoft.Json@13.0.3
using Newtonsoft.Json;
try { /* 处理逻辑 */ }
catch (Exception ex) { Console.Error.WriteLine(ex.Message); return 1; }
// 阶段三:配置并发布为高性能原生应用
#:property PublishAot=true
// 发布命令:dotnet publish -r win-x64
从原型到生产环境部署,所有演进都在同一个文件中完成,避免了项目结构重构的麻烦。
适配点 2:降低AI Agent的理解成本
Python等传统方案:Agent需要读取并关联多个文件才能理解全貌。
my-skill/
├── tool.py # 主逻辑
├── requirements.txt # 依赖清单
└── README.md # 使用说明
.NET File-Based Apps方案:所有关键信息集中在一个文件内。
my-skill/
└── scripts/
└── tool.cs # 依赖、配置、逻辑、说明,一应俱全
Agent只需分析这一个文件,就能立刻获知:所需依赖(#:package)、运行方式(shebang行)、核心功能(代码逻辑)以及部署选项(#:property)。
适配点 3:企业级开发的可靠性
.NET的强类型系统在AI辅助开发中尤为宝贵,能在编译阶段拦截大量错误,而非运行时崩溃。
// .NET: 编译时即明确类型,AI生成代码更安全
string pdfPath = args[0]; // 明确为字符串
int pageCount = GetPageCount(pdfPath); // 明确返回整数
// 对比Python:类型信息模糊,潜在错误可能到运行时才暴露
# pdf_path = args[0] # 类型?可能是字符串,也可能是列表?
# page_count = get_page_count(pdf_path) # 返回值类型?整数?异常?
这意味着当AI Agent生成或修改代码时,.NET能提供更坚固的“安全护栏”。
适配点 4:卓越的性能与资源效率
AI Agent可能会频繁调用Skills,因此脚本的启动和执行速度至关重要。
# Python脚本启动(需加载解释器)
$ time python tool.py input.pdf
real 0m0.234s
# .NET File-Based App启动(JIT编译)
$ time dotnet tool.cs input.pdf
real 0m0.089s
# .NET Native AOT编译后(接近原生性能)
$ time ./tool input.pdf
real 0m0.012s
对于由Agent驱动、需要反复执行自动化任务的场景,这种性能优势将累积成显著的时间节省和成本降低。
3.3 实战案例:开发一个 PDF 拆分 Skill
下面我们通过一个完整的split-pdf Skill开发过程,演示如何应用上述规范和实践。
步骤 1:创建目录结构
mkdir -p split-pdf/scripts
cd split-pdf
步骤 2:编写核心的 SKILL.md 文件
SKILL.md是Skill的定义文件。创建内容如下:
---
name: split-pdf
description: Split PDF files into separate single-page documents or extract specific page ranges. Use when you need to divide a PDF into multiple files, extract particular pages, or process PDF pages individually. Works with multi-page PDF documents.
license: MIT
---
# Split PDF
将 PDF 文件拆分为多个单页文件或提取指定的页面范围。
## 使用场景
- 将多页合同、报告等PDF拆分为独立的单页文件。
- 从大型PDF文档中提取特定的章节或页面。
- 需要对PDF的每一页进行单独处理或分发时。
## 使用方法
使用 `scripts/split-pdf.cs` 脚本进行PDF拆分操作。
### 命令示例
```bash
# 拆分所有页面
dotnet scripts/split-pdf.cs input.pdf output-dir/
# 仅拆分第1到第5页
dotnet scripts/split-pdf.cs input.pdf output-dir/ 1-5
输出格式
拆分后的每个单页PDF将按以下格式命名:{原始文件名}_page_{三位数页码}.pdf
依赖项
- PdfSharpCore 1.3.65 - 用于PDF文档的读写操作。
- Spectre.Console 0.49.1 - 提供美观的控制台进度条和输出。
重要提示:
- 本Skill的
name (split-pdf) 必须与其所在的目录名完全一致。
description 中包含了 "split", "PDF", "pages" 等关键词,以帮助Agent准确识别该Skill的适用场景。
步骤 3:编写 .NET File-Based App 脚本
在scripts/目录下创建split-pdf.cs文件,这是技能的核心执行脚本。
#!/usr/bin/env dotnet
#:package PdfSharpCore@1.3.65
#:package Spectre.Console@0.49.1
#:property PublishAot=true
using PdfSharpCore.Pdf;
using PdfSharpCore.Pdf.IO;
using Spectre.Console;
using System;
using System.IO;
using System.Threading.Tasks;
// ==================== 参数校验与初始化 ====================
if (args.Length < 2)
{
AnsiConsole.MarkupLine("[red]错误: 参数不足[/]");
AnsiConsole.MarkupLine("[yellow]用法: dotnet split-pdf.cs <PDF文件路径> <输出目录路径> [起始页-结束页][/]");
AnsiConsole.MarkupLine("[grey]示例: dotnet split-pdf.cs document.pdf ./pages/ 1-3[/]");
return 1;
}
var pdfPath = args[0];
var outputDir = args[1];
var pageRange = args.Length >= 3 ? args[2] : null;
// 验证输入文件是否存在
if (!File.Exists(pdfPath))
{
AnsiConsole.MarkupLine($"[red]错误: 指定的PDF文件不存在: {pdfPath}[/]");
return 1;
}
// 确保输出目录存在
Directory.CreateDirectory(outputDir);
// ==================== 核心PDF拆分逻辑 ====================
try
{
using var inputDocument = PdfReader.Open(pdfPath, PdfDocumentOpenMode.Import);
var totalPages = inputDocument.PageCount;
var baseName = Path.GetFileNameWithoutExtension(pdfPath);
// 解析页面范围参数,默认为全部页面
int startPage = 1, endPage = totalPages;
if (!string.IsNullOrEmpty(pageRange))
{
var rangeParts = pageRange.Split('-');
if (rangeParts.Length == 2 &&
int.TryParse(rangeParts[0], out startPage) &&
int.TryParse(rangeParts[1], out endPage))
{
// 确保页码范围有效
startPage = Math.Max(1, Math.Min(startPage, totalPages));
endPage = Math.Max(startPage, Math.Min(endPage, totalPages));
}
else
{
AnsiConsole.MarkupLine($"[red]错误: 无效的页面范围格式 '{pageRange}'。请使用 '起始页-结束页' 格式,例如 '1-5'。[/]");
return 1;
}
}
AnsiConsole.MarkupLine($"[green]准备拆分: {Path.GetFileName(pdfPath)} (共{totalPages}页)[/]");
AnsiConsole.MarkupLine($"[grey]输出范围: 第 {startPage} 页 至 第 {endPage} 页[/]");
// 使用进度条提升用户体验
await AnsiConsole.Progress()
.StartAsync(async ctx =>
{
var progressTask = ctx.AddTask("正在拆分页面", maxValue: endPage - startPage + 1);
for (int currentPage = startPage; currentPage <= endPage; currentPage++)
{
// 创建新PDF文档并加入当前页
using var outputDocument = new PdfDocument();
outputDocument.AddPage(inputDocument.Pages[currentPage - 1]);
// 生成输出文件名,页码补零至3位
var outputFileName = $"{baseName}_page_{currentPage:D3}.pdf";
var outputPath = Path.Combine(outputDir, outputFileName);
outputDocument.Save(outputPath);
// 更新进度
progressTask.Increment(1);
await Task.Delay(10); // 小幅延迟,让进度条更平滑(实际生产可移除)
}
});
AnsiConsole.MarkupLine($"[bold green]✅ 拆分完成!共生成 {endPage - startPage + 1} 个文件,已保存至: {outputDir}[/]");
return 0;
}
catch (Exception ex)
{
AnsiConsole.MarkupLine($"[bold red]❌ 处理过程中发生错误:[/]");
AnsiConsole.WriteException(ex, ExceptionFormats.ShortenEverything);
return 1;
}
代码关键点解析:
- Shebang行:
#!/usr/bin/env dotnet 使得在Unix/Linux系统上可以直接执行此脚本。
- 依赖声明:通过
#:package 指令内联声明了所有NuGet包及其版本。
- AOT配置:
#:property PublishAot=true 表示此脚本支持发布为Native AOT应用。
- 顶层语句:无需定义
Main方法,代码从文件顶部开始顺序执行,更符合脚本的简洁性。
- 友好的交互:利用Spectre.Console库提供了彩色输出、进度条和清晰的异常信息,这对后端架构中工具链的开发者体验至关重要。
- 返回值:使用
return 返回退出码(0成功,非0失败),符合命令行工具规范。
四、测试与验证
4.1 本地测试
功能测试
# 进入Skill目录
cd split-pdf
# 测试1:拆分PDF的所有页面
dotnet scripts/split-pdf.cs sample.pdf ./output-all/
# 测试2:拆分PDF的指定页面范围(第2至第4页)
dotnet scripts/split-pdf.cs sample.pdf ./output-range/ 2-4
错误处理测试
# 测试文件不存在的情况
dotnet scripts/split-pdf.cs missing.pdf ./output/
# 测试缺少必要参数的情况
dotnet scripts/split-pdf.cs
# 测试无效的页面范围格式
dotnet scripts/split-pdf.cs sample.pdf ./output/ abc-xyz
4.2 Agent 集成测试
在支持Agent Skills的环境(如配置了相应插件的IDE)中进行测试:
- 将整个
split-pdf文件夹放置到Agent指定的Skills目录下(例如.github/skills/)。
- 重启或刷新你的AI Agent(如Copilot Chat)。
- 尝试提出相关需求,观察Agent是否能自动识别并调用该Skill。
模拟对话:
用户: “我有一个report.pdf文件,请帮我把前3页单独拆分出来。”
Agent行为:
- 理解任务为“拆分PDF前3页”。
- 在已加载的Skill元数据中,匹配到
name为split-pdf、description含相关关键词的Skill。
- 激活该Skill,读取
SKILL.md获取具体用法。
- 构造并执行命令:
dotnet scripts/split-pdf.cs report.pdf ./split_result/ 1-3
- 将执行结果(成功或失败信息)反馈给用户。
五、最佳实践
5.1 脚本设计原则
- 清晰的参数设计:使用有意义的参数顺序和名称,并在帮助信息中明确说明。
- 友好的交互反馈:对于耗时操作,务必提供进度提示;对于错误,给出可操作的解决建议。
- 完善的错误处理:使用
try-catch捕获异常,并以非零退出码和清晰消息告知失败原因。
5.2 依赖管理
- 锁定版本:始终在
#:package指令中指定依赖包的确切版本号,避免因依赖更新导致的不兼容。
- 最小化依赖:仅引入完成功能所必需的包,以减少最终应用体积和潜在冲突。
5.3 文档编写
- 关键词策略:在
SKILL.md的description中,务必包含动作动词(split, merge, analyze)、操作对象(PDF, JSON, database)和场景关键词。
- 提供丰富示例:在Markdown正文中,提供涵盖常见和边界情况的命令行示例。
5.4 跨平台兼容性
- 使用Path类处理路径:始终使用
System.IO.Path.Combine()来拼接路径,避免硬编码\或/。
- 注意控制台编码:如果需要输出非ASCII字符,可设置
Console.OutputEncoding = System.Text.Encoding.UTF8。
六、进阶话题
6.1 构建工具集Skill
一个Skill内可以包含多个相关脚本,形成一个工具集。
pdf-toolkit/
├── SKILL.md # 介绍整个PDF工具箱
└── scripts/
├── split.cs # 拆分
├── merge.cs # 合并
└── extract-text.cs # 提取文本
6.2 利用References目录
对于复杂的Skill,可以将详细的API文档、算法原理等内容移到references/目录下,保持SKILL.md的简洁。
data-analysis/
├── SKILL.md # 快速入门和核心用法
├── scripts/
│ └── analyze.cs
└── references/ # 深入资料
├── api-reference.md
├── advanced-examples.md
└── algorithm-details.md
6.3 Native AOT 深度优化
对于性能极度敏感或要求极小部署体积的场景,可以进一步优化AOT发布:
#:property PublishAot=true
#:property InvariantGlobalization=true // 移除区域化数据,减小体积
#:property StripSymbols=true // 剥离调试符号
发布命令:
dotnet publish scripts/split-pdf.cs -r linux-x64 -c Release --property:PublishAot=true
这将生成一个极速启动、不依赖任何.NET运行时的单一可执行文件,非常适合集成到云原生或边缘计算场景的自动化流水线中。
6.4 团队协作与知识沉淀
将Skills纳入团队代码仓库进行版本管理,是沉淀组织知识资产的有效方式。
.your-repo/
├── .github/
│ └── skills/ # 团队共享的Agent Skills库
│ ├── split-pdf/
│ ├── data-analyzer/
│ └── code-reviewer/
└── README.md # 说明如何安装和使用这些Skills
七、总结与展望
通过本文的探讨,我们可以看到.NET File-Based Apps凭借其单文件自包含、编译时类型安全、支持高性能Native AOT编译等特性,与Agent Skills对脚本“简洁、可靠、高效”的要求完美契合。它不仅为.NET开发者打开了参与AI Agent生态的新大门,其强类型和丰富的基础库也为AI生成和操作代码提供了更可靠的“护栏”。
行动起来
- 对于.NET开发者:立即尝试用你熟悉的C#,将你的专业知识封装成Agent Skill,在AI协作的浪潮中发挥独特价值。
- 对于所有开发者:.NET File-Based Apps的入门门槛已极大降低。如果你需要一个兼具脚本灵活性与应用性能的解决方案,它绝对值得一试。
未来,随着Agent Skills生态的成熟,我们或许会看到专门的Skill市场、更强大的IDE集成工具,以及更广泛的企业级应用。.NET File-Based Apps有望在其中扮演高性能、高可靠性脚本运行时的重要角色。
参考资源
 发表于 2025-12-25 08:46:13
|
查看: 308|
回复: 0
发表于 2025-12-25 08:46:13
|
查看: 308|
回复: 0
