2025年12月20日,摩尔线程首届MUSA开发者大会在北京召开。作为聚焦全功能GPU的技术盛会,大会系统展示了以自主MUSA统一架构为核心的全栈技术成果与前瞻布局。
本次发布的核心成果包括:

1、新架构“花港”亮相:发布全功能GPU架构“花港”,支持FP4到FP64的全精度计算,算力密度提升50%,效能提升10倍。未来将基于该架构推出高性能AI训推一体“华山”芯片与专攻高性能图形渲染的“庐山”芯片。

2、“夸娥万卡”高效训练:发布夸娥万卡智算集群,展示了其支撑万亿参数模型训练的工程化能力与可靠性,在多项关键精度指标上达到国际主流水平。

3、推理性能实现跨越:摩尔线程联合硅基流动,在DeepSeek R1 671B全量模型上实现性能突破,MTT S5000单卡Prefill吞吐突破4000 tokens/s、Decode吞吐突破1000 tokens/s,树立国产推理性能新标杆。

4、超节点架构前瞻:分享面向下一代超大规模智算中心的MTT C256超节点架构,着眼高密硬件设计,旨在实现极致智算性能。

5、全新个人智算平台:正式发布搭载智能SoC芯片“长江”的AI算力本MTT AIBOOK,旨在赋能“摩尔学院”的广大开发者与学习者。
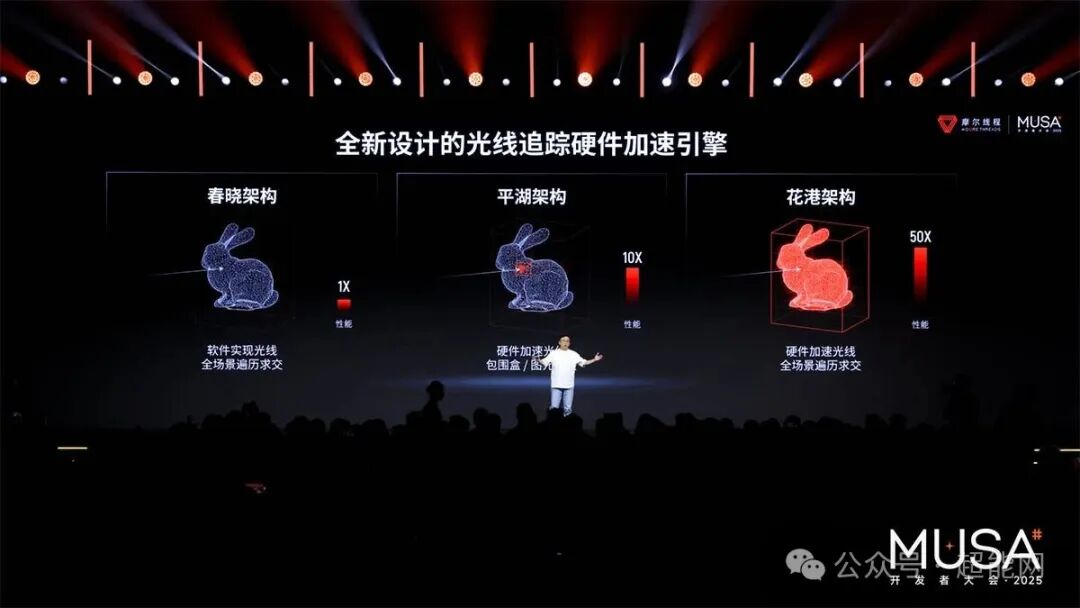
6、图形进化与前沿探索:揭晓硬件级光线追踪加速与自研AI生成式渲染技术,并展示了在具身智能、科学智能(AI4S)、AI for 6G等前沿领域的深度布局。
这一系列成果标志着摩尔线程已构建起一套以自主统一架构为根基、贯穿“芯-边-端-云”的完整技术栈,为国产智能计算生态的持续演进提供了坚实、开放的平台级支撑。
战略基石:MUSA统一架构的进化与开放
MUSA(元计算统一系统架构)是摩尔线程自主研发的全栈技术体系,覆盖从芯片架构、指令集、编程模型到软件运行库的全链条。
MUSA为全功能GPU奠定了技术根基,可高效支持AI计算、图形渲染、物理仿真和科学计算、超高清视频编解码等全场景高性能计算需求。

历经五年深度研发,全新升级的MUSA 5.0在统一性、效能与开放性上取得关键突破:
- 编程生态升级:原生支持MUSA C,深度兼容 TileLang、Triton 等编程语言。
- 计算效能优化:核心计算库muDNN的GEMM/FlashAttention效率超98%,编译器性能提升3倍。
- 开源生态扩大:计划逐步开源计算加速库、通信库及系统管理框架等核心组件。
- 前沿特性拓展:即将推出兼容跨代GPU的中间语言MTX、融合计算语言muLang、量子计算框架MUSA-Q及计算光刻库muLitho。
硬件核心:“花港”新架构与技术路线图

基于MUSA体系,新一代全功能GPU架构“花港”在计算密度、能效及图形技术等方面实现全面突破:
- 计算性能提升:算力密度提升50%,支持从FP4到FP64的全精度计算,新增MTFP6/MTFP4支持。
- 超大规模互联:通过自研MTLink高速互联技术,支持十万卡以上规模智算集群扩展。
- 图形与AI融合:内置AI生成式渲染架构,增强硬件光追加速,完整支持DirectX 12 Ultimate。
- 全栈自研安全:基于全栈自主研发,通过四层硬件安全架构提供可验证的安全守护。
基于“花港”架构,摩尔线程公布了两款未来芯片的技术路线:

- “华山”:专注AI训推一体与超大规模智能计算,支持全精度计算,为构建下一代“AI工厂”的坚实底座。
- “庐山”:专攻高性能图形渲染,AI计算性能提升64倍,光线追踪性能提升50倍,集成AI生成式渲染与全新硬件光追引擎。
基础设施:夸娥万卡集群,树立国产智算效率标杆
本次大会正式发布了具备全精度、全功能通用计算能力的夸娥万卡智算集群。其在万卡规模下实现高效稳定的AI训练与推理,训练线性扩展效率达95%,并与国际主流生态高度兼容。

- 训练侧:基于原生FP8能力完整复现顶尖大模型训练流程,Flash Attention算力利用率超95%。
- 推理侧:联合硅基流动,在DeepSeek R1 671B模型上实现突破,MTT S5000单卡推理性能树立新标杆。
- 面向未来:发布MTT C256超节点架构规划,采用计算与交换一体化高密设计,旨在为下一代超大规模智算中心构建硬件基石。
迈向物理AI:图形技术持续进化,前瞻布局未来计算
在图形计算领域,其产品已全面支持DirectX 12、Vulkan 1.3等主流API,并即将完整支持DirectX 12 Ultimate。

在核心渲染技术上实现两项关键突破:
- 迈入实时光追时代:基于“花港”架构的硬件光线追踪加速引擎,支持DirectX Raytracing (DXR)。
- 定义AI生成式渲染(AGR):推出全自研MTAGR 1.0技术,推动渲染技术范式从“计算”走向“生成”。
在前沿计算场景的布局包括:
- 具身智能全栈赋能:发布MT Lambda仿真训练平台与MT Robot解决方案,并宣布将于2026年开源关键仿真加速组件。
- 前沿融合计算探索:MUSA生态已在科学智能、量子科技、AI for 6G等交叉领域展开探索,拓展通用算力底座的应用价值。
生态加速:全面赋能开发者,发布个人AI算力平台
生态建设是GPU行业的核心。摩尔线程构建了从硬件工具、算力支撑到人才培养的赋能体系。

- 深化人才培养:以摩尔学院为平台,汇聚近20万开发者,并通过共建行动覆盖全国200多所高校。本次宣布建设MUSA生态中心并发布开发者计划。
- 发布AI算力本:MTT AIBOOK搭载自研“长江”智能SoC,提供50TOPS端侧AI算力,实现从芯片到开发环境的全栈整合,为开发者提供“开箱即用”的体验。

大会同时预告了基于“长江”SoC打造的迷你型计算设备MTT AICube。
结语:构筑自主基座,共赴智能未来
MDC 2025系统呈现了从统一架构、核心芯片到超大规模基础设施与开发者终端的技术全景。展望未来,摩尔线程将以MUSA为核心,坚持开放生态,与全球开发者携手,共同构建下一代智能计算体系。


 发表于 2025-12-25 17:17:59
|
查看: 274|
回复: 0
发表于 2025-12-25 17:17:59
|
查看: 274|
回复: 0
