
神经网络并非遥不可及的“黑科技”,而是让计算机学会像人脑一样“举一反三”的核心工具。理解其基本原理,你便能洞悉当今绝大多数人工智能应用背后的底层逻辑。
一、神经网络如何模拟“思考”过程?
从手机的刷脸支付到短视频的精准推荐,再到随时应答的智能助手,这些能力的共同引擎都是神经网络。其核心思想非常直观:模仿人类大脑的学习方式。

灵感来源:从生物神经元到数学模型
人脑由近千亿个神经元通过突触连接构成复杂网络,使我们能识别、理解和学习。神经网络受此启发,用“人工神经元” 作为基础计算单元,相互连接形成网络,使计算机能够从数据中自行归纳规律,而非仅仅执行预设指令。
核心单元:人工神经元的运作机制
每个神经元可被视为一个微型的 “决策站” ,其工作流程是标准化的:
- 输入:接收来自其他神经元或原始数据的信息,如图像像素值或文本编码。
- 权重:为每条输入信息赋予一个“重要性”系数。例如,在识别猫时,“胡须特征”的权重可能远高于“背景颜色”。
- 偏置:一个内部调节参数,决定了神经元被激活的难易程度。
- 激活函数:对加权求和后的结果进行非线性变换,决定是否输出信号及信号强度。这是神经网络获得非线性决策能力的关键。
生活化示例:假设一个神经元负责判断“是否推荐这家餐厅”。其输入可能包括:你的个人口味偏好(高权重)、朋友评分(中权重)、餐厅距离(低权重)。经过计算,激活函数最终输出“强烈推荐”的信号。
核心学习过程:预测与修正的循环
单个神经元能力有限,但将它们分层连接(输入层→隐藏层→输出层)后,便形成了强大的网络。其学习本质是一个持续的 “预测-修正”循环:
- 前向传播:输入数据从网络首端流向末端,经过各层神经元的处理,最终在输出层产生一个预测结果。例如,输入一张图片,输出“90%概率是猫,10%概率是狗”。
- 反向传播:将预测结果与真实标签对比,计算出误差。然后,该误差从输出层开始,反向逐层传播,并据此调整网络中每一个神经元的权重和偏置参数,就像根据错题来修正解题思路。
通过海量数据反复进行这个循环,网络的预测能力会变得越来越精准。这个过程,即所谓的模型训练。
思考:如果让你设计一个判断“今日是否会下雨”的神经元,你会考虑哪些输入信号?其中哪个信号的“权重”应该最高?
二、三大主流架构:针对不同任务的“专业工具”
神经网络并非只有一种形态。针对不同的数据类型和任务目标,工程师们设计了各具特色的网络架构。理解以下三种主流架构,便能看懂绝大多数AI应用的核心。

1. 卷积神经网络:计算机视觉的基石
- 擅长领域:专为处理具有网格结构的数据设计,尤其是图像和视频。是人脸识别、医学影像分析和自动驾驶视觉系统的核心。
- 核心原理:“局部感知”与“参数共享”。它使用卷积核(类似小扫帚)滑动扫描图像,先提取边缘、纹理等低级特征,再组合成高级语义特征(如识别出完整的物体)。这种方法极大提升了效率并降低了过拟合风险。
- 常见应用:手机相册自动分类、美颜滤镜、安防监控的人脸识别。
2. 循环神经网络:序列数据处理专家
- 擅长领域:处理具有时间或顺序依赖的数据,如语音、文本、股价序列。其特点是具有“记忆”能力。
- 核心原理:能够将上文信息传递到当前步骤的处理中。这使得它在分析句子时,能结合前文词汇来理解当前词义,因此在机器翻译、语音识别和文本生成任务上表现出色。
- 进阶形态:为了解决长序列依赖中的梯度消失问题,出现了LSTM、GRU等变体,成为现代智能语音助手和聊天机器人的重要基础。
3. Transformer:重塑格局的通用架构
- 擅长领域:最初为自然语言处理设计,现已统治该领域,并扩展至图像、音频等多模态任务。ChatGPT、文生图模型均基于此架构。
- 核心原理:“自注意力机制”。它能同时计算输入序列中所有元素之间的关联强度(例如一句话中每个词与其他词的相关性),并行计算效率极高,且擅长捕捉长距离依赖关系。
- 革命性影响:摒弃了RNN的顺序计算限制,训练速度大幅提升,直接推动了大模型(LLM)时代的到来。
选择题:当前热门的“文生视频”AI(如Sora),其核心架构最可能基于以下哪种技术的演进?
A. 卷积神经网络:因为视频由图像帧构成。
B. 循环神经网络:因为视频具有严格的时间序列。
C. Transformer架构:因为它能统一处理时空信息,且并行计算能力强。
D. 全新的未知架构:完全颠覆了现有技术。
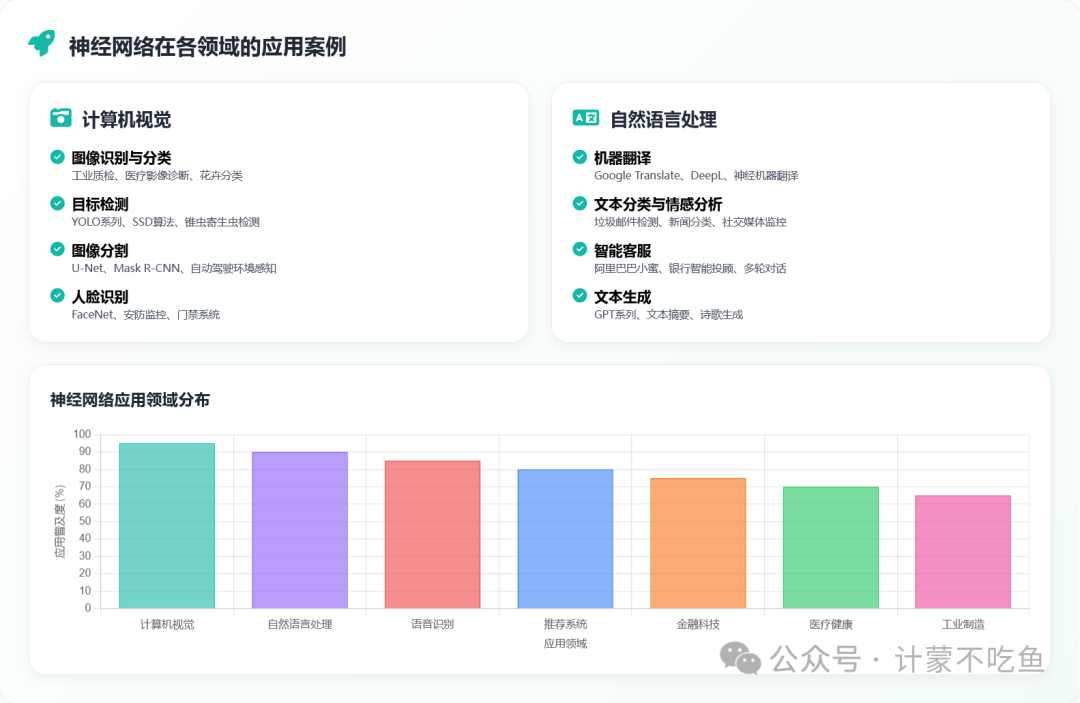
三、神经网络的应用:已深度融入日常生活
神经网络早已走出实验室,无声地重塑着我们的生活方式:
- 刷脸支付/解锁:CNN精准识别面部生物特征。
- 个性化推荐:神经网络分析用户历史行为,预测兴趣偏好。
- 智能客服:基于RNN或Transformer理解用户 query 并生成回复。
- 实时导航路况:分析海量车辆GPS数据,预测道路拥堵情况。
- AI修图与特效:CNN理解图像内容并进行像素级编辑。
- 医疗影像辅助诊断:帮助医生在CT、MRI等影像中更高效地识别病灶。
- 金融风控:实时分析交易模式,识别潜在的欺诈行为。
> 本质上,任何需要从复杂数据中寻找模式、进行预测或生成新内容的任务,都可能是神经网络的用武之地。
四、新手学习路径:从理论到实践的渐进地图
若你对神经网络产生兴趣,并希望从入门走向实践,遵循“理论-实践”交替的路径最为有效。
第一阶段:夯实基础(1-2个月)
- 目标:掌握必要的数学与编程基础。
- 行动:
- 数学:重点复习线性代数(向量/矩阵运算)、微积分(导数/梯度概念)、概率论基础。理解直观含义和应用场景优先,不必深究复杂证明。
- 编程:熟练掌握Python,并学会使用NumPy(数值计算)、Pandas(数据处理)和Matplotlib(数据可视化)这三大基础库。
第二阶段:初探机器学习(2-3个月)
- 目标:理解经典机器学习模型,为深度学习铺垫。
- 行动:学习使用scikit-learn库,动手实现线性回归、逻辑回归、决策树等经典算法。重点理解“过拟合”、“欠拟合”、“交叉验证”等核心概念。
第三阶段:深度学习入门(3-4个月)
- 目标:掌握神经网络基本原理,并用框架完成第一个实战项目。
- 行动:
- 理论:深入理解前向/反向传播、常用激活函数(如ReLU)、损失函数(如交叉熵)。
- 框架:从PyTorch(灵活,研究首选)或TensorFlow(生态成熟,工业常用)中二选一入手。初学者常从PyTorch开始,因其更符合编程直觉。
- 项目:在Kaggle或相关课程中,完成MNIST手写数字识别项目,这是深度学习的“Hello World”。
第四阶段:进阶与专精(持续投入)
- 目标:选择细分方向深入,积累实战经验。
- 行动:
- 定方向:根据兴趣选择计算机视觉、自然语言处理或强化学习等方向。
- 做项目:从复现经典模型(如ResNet, BERT)开始,逐步过渡到独立完成小型项目(如表情识别、新闻分类)。
- 读论文:从AlexNet、Transformer等奠基性论文读起,关注NeurIPS、CVPR、ACL等顶级会议的最新进展。
- 持续实战:在Kaggle、天池等平台参加竞赛,是快速提升工程能力的最佳途径之一。
精选学习资源:
- 课程:吴恩达《机器学习》(经典入门)、李沐《动手学深度学习》(实战导向强)。
- 书籍:《深度学习》(“花书”,权威参考书)、《动手学深度学习》(配套PyTorch,学练结合)。
- 社区:PyTorch官方论坛、知乎相关专栏、Reddit的r/MachineLearning板块。

结语
神经网络与人工智能的世界广阔而深邃,入门时的困惑是常态。关键在于保持耐心与好奇心,不必被复杂的数学形式所吓退,先从直观理解和高层概念入手,在不断的动手实践中巩固认知。
记住一个朴素的道理:一行可运行的代码,胜过十页抽象的推导。 从今天开始,尝试运行你的第一个神经网络程序,便是迈向这个领域最坚实的一步。
讨论:了解了神经网络的基础后,你对它在哪个具体领域的应用最感兴趣或最感到惊奇?是AIGC创作、辅助医疗诊断,还是其他方面? |  发表于 2025-12-25 19:41:42
|
查看: 286|
回复: 0
发表于 2025-12-25 19:41:42
|
查看: 286|
回复: 0
