在众多编程语言中,C/C++、Java 和 Python 因其各自的特点而占据着主导地位。这些语言的设计哲学、运行方式乃至应用场景都迥然不同。本文将对这三种主流语言的程序运行机制进行对比分析。
C/C++
C/C++ 作为经典的编译型语言,其程序在运行前需要经过完整的编译过程。编译器会将源代码直接转换为目标机器的机器码,生成的可执行文件能够直接在 CPU 上运行。正因为在编译阶段就已经确定了所有变量的类型,所以 C/C++ 也被归类为静态类型语言。这种追求极致性能的特性,使其成为开发操作系统、游戏引擎等底层或高性能系统的首选。如果你想深入探究其背后的指针、模板等高级特性,可以参考云栈社区的相关讨论。
假设一个 C 语言工程包含 a1.c、a2.c 和 a3.c 三个文件,分别定义了 main()、f1() 和 f2() 函数,且 main() 函数调用了 f1() 和 f2()。其典型的编译执行流程如下:
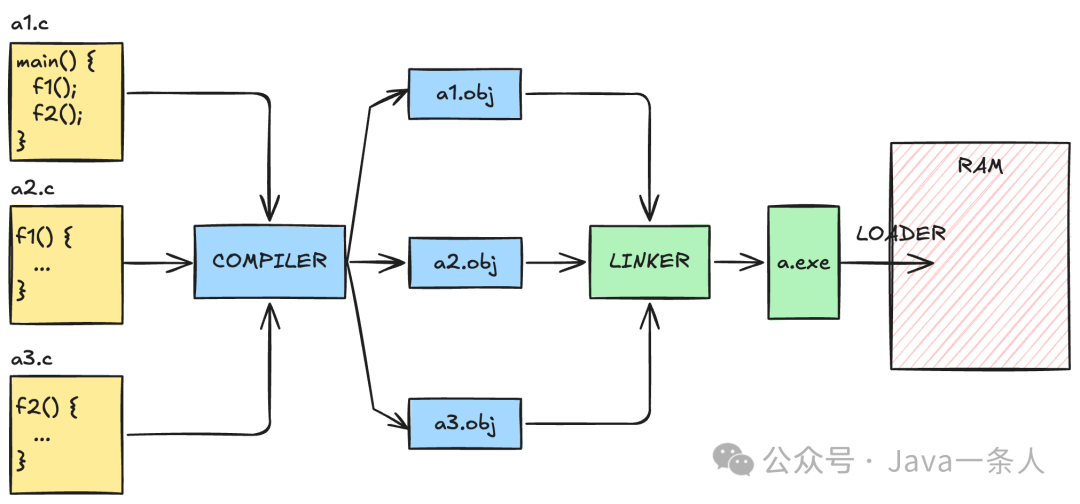
图1:C/C++编译链接流程示意图
首先,编译器(Compiler)将三个 .c 源文件分别编译成对应的目标文件(如 .obj 文件)。随后,链接器(Linker)将这些目标文件以及所需的库文件关联起来,解决函数和变量的地址引用,最终生成一个可执行的 .exe 文件。当用户运行程序时,操作系统的程序加载器(Loader)会将该可执行文件加载到内存(RAM)中,并由 CPU 开始执行。
Java
Java 通常被称作“半编译半解释”型语言。它在运行前需要编译器将源代码编译成一种中间格式——字节码(.class 文件),而非直接的机器码。字节码的运行依赖于 Java 虚拟机(JVM)。同样,Java 在编译期也确定了类型,属于静态类型语言。由于多了字节码和 JVM 这一层抽象,其性能通常略逊于 C/C++,但换来了“一次编写,到处运行”的强大跨平台能力,这使其成为企业级后端服务开发的基石。
我们同样假设有三个 Java 源文件:a1.java、a2.java 和 a3.java。它们的编译与执行过程如下图所示:
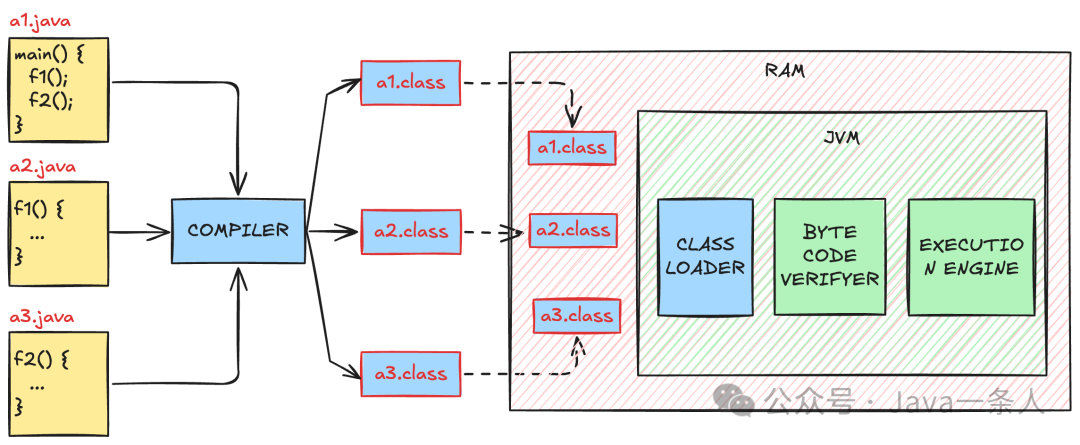
图2:Java程序编译与JVM执行流程图
Java 编译器先将 .java 文件编译成 .class 字节码文件。运行程序时,JVM 的类加载器(ClassLoader)负责将这些字节码文件加载到内存中。紧接着,字节码验证器(Byte-Code-Verifier)会执行安全检查,确保代码符合规范且没有危害虚拟机的操作。验证通过后,执行引擎(Execution Engine,如 HotSpot 的 JIT 编译器)会将字节码即时编译(JIT)为当前宿主机的本地机器码并执行。这个加载、验证、解释/编译的过程,也是 Java 程序启动往往较慢的主要原因。
Python
Python 是一种典型的解释型语言。它在运行前无需显式的编译步骤,解释器会直接读取源代码,边解释边执行。变量类型在运行时才能确定,因此 Python 是动态类型语言。这种灵活、简洁的特性,使其在数据科学、机器学习、自动化脚本等领域大放异彩,当前主流的大模型开源框架也大多基于 Python 构建。
假设有三个 Python 脚本:a1.py、a2.py 和 a3.py,其中 a1.py 作为主程序入口(包含 __main__),并导入了 a2.py 和 a3.py 模块。其运行流程可通过下图理解:
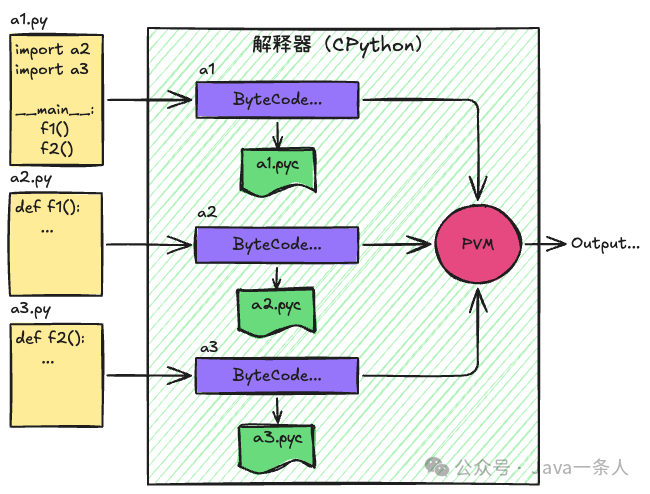
图3:Python解释器执行与字节码生成流程
Python 代码的执行完全依赖于Python 解释器,其官方实现是 CPython。与编译型语言不同,Python 没有独立的编译和链接阶段。然而,解释器内部会进行隐式编译:当执行 a1.py 时,解释器会先将其编译为字节码,为了提高后续执行效率,通常还会将字节码缓存为 .pyc 文件。如果在编译 a1.py 时发现它导入了 a2.py,则会暂停当前编译,转而去处理 a2.py 的编译。待所有依赖模块都处理完毕,内存中的字节码会被交给 Python 虚拟机(PVM,即解释器的核心执行引擎)逐行解释执行,最终输出结果。 |  发表于 2025-12-30 21:24:32
|
查看: 232|
回复: 0
发表于 2025-12-30 21:24:32
|
查看: 232|
回复: 0
