在分布式消息系统中,Kafka 作为核心组件,其消息的“精确一次”投递是保障业务数据一致性的关键挑战。消息重复消费不仅会增加下游系统负担,更可能引发严重的逻辑与数据错误。本文将深入剖析 Kafka 消息重复的四大根本原因,并提供从客户端配置到系统设计的架构级解决方案。
生产者端重试机制导致的重复
原因:当生产者发送消息失败时(例如遇到网络抖动或请求超时),其内置的重试机制会再次发送消息。但若 Kafka Broker 实际上已成功接收并写入消息,只是未能及时向生产者返回确认(ACK),那么这次重试就会产生一条内容完全相同的重复消息。
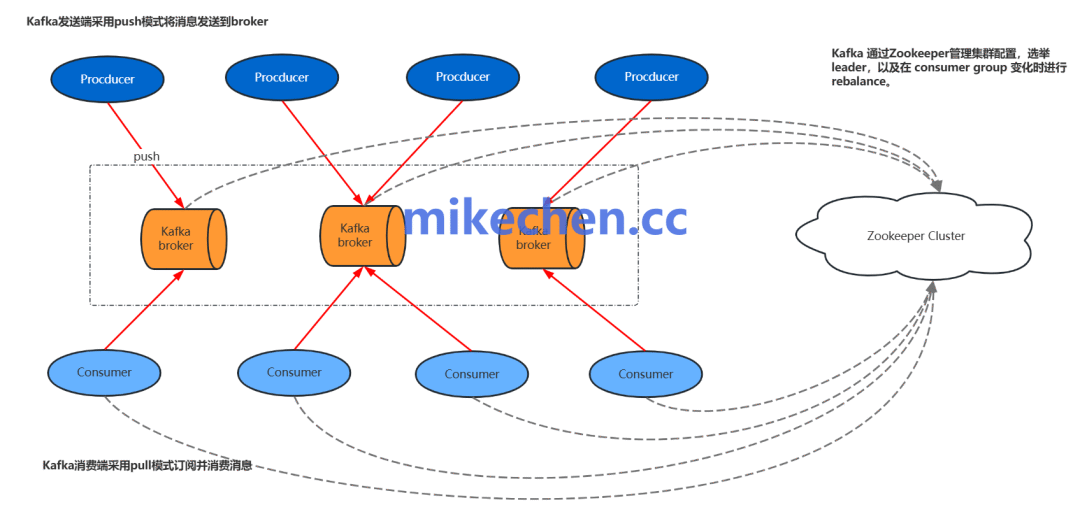
图1:Kafka 生产者推送消息至 Broker,消费者拉取消息的架构示意图
解决方案:
- 启用生产者幂等性:在生产者配置中设置
enable.idempotence=true。该机制会为每个生产者实例分配一个唯一的 producerId,并为发送到同一分区的每条消息附带一个递增序列号。Broker 端会据此检测并丢弃重复的序列号,从而确保单个分区内的“幂等发送”。
- 合理配置重试参数:结合
retries(重试次数)和 delivery.timeout.ms(总投递超时时间)进行精细控制。在启用幂等性的前提下,合理配置这些参数可以避免因无限重试或过长等待时间引发的新问题。
- 使用事务性生产者:对于需要跨多个分区或主题保证原子性写入的场景,应启用 Kafka 事务(设置
transactional.id),以实现更强的“端到端一次”语义。
消费者端处理失败与重复提交偏移量
原因:消费者在处理消息后、提交消费位移(Offset)之前发生崩溃(或进程重启),会导致位移未能更新。当消费者恢复后,它将从上次提交的位移处重新拉取消息,造成重复消费。反之,若采用“先提交位移,后处理消息”的模式,则可能在提交后、处理前崩溃,导致消息丢失。
图2:消费者组内多个消费者实例协同工作的简化模型
解决方案:
- 采用精确的手动提交位移:设置
enable.auto.commit=false,关闭自动提交。在业务逻辑确保处理成功后,再手动调用 commitSync() 或 commitAsync() 提交位移。这种“先消费,后提交”是更安全的模式。
- 实现处理与提交的原子性:将消息处理结果与消费位移的更新放在同一个数据库事务中完成,或使用支持事务的外部存储来记录处理状态。这样能确保两者要么同时成功,要么同时失败。
- 利用事务性消费者:与事务性生产者配合,通过消费者 API 的
isolation.level 配置(读已提交 read_committed),可以过滤掉未提交的事务消息,并确保位移提交与消息处理在事务边界内保持一致。
分区与副本机制引起的重复
原因:Kafka 的高可用依赖于副本机制。当分区 Leader 发生切换、ISR(In-Sync Replicas)列表因副本落后而缩容、或网络分区恢复时,未正确同步的复制状态可能导致数据不一致。例如,原 Leader 上已提交但未完全同步到所有 ISR 的消息,在新 Leader 选举后可能被视为未提交而丢失,随后生产者重试又会导致重复。
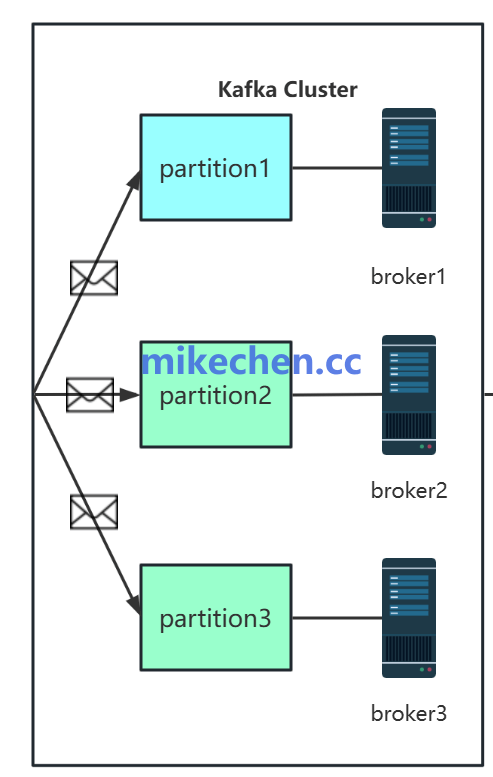
图3:Kafka 集群中,Topic 分区分布在不同的 Broker 上以实现负载均衡与高可用
解决方案:
- 强化生产端确认机制:设置
acks=all(或 acks=-1)。这意味着生产者需要等待所有 ISR 副本都成功写入消息后才收到确认,从根本上避免了因副本未同步导致的数据丢失风险,但会轻微增加延迟。
- 优化副本与可靠性配置:设置合适的
replication.factor(通常 >=3)和 min.insync.replicas(例如 2)。这确保了即使个别 Broker 宕机,写入操作依然能满足最低同步副本数要求,维持可用性与一致性。
- 监控与运维保障:密切监控集群的 ISR 变化、网络延迟及 Broker 健康状况。通过优化硬件、网络和 JVM 配置,减少非必要的 Leader 切换,为副本同步创造稳定环境。
系统层面幂等性与去重策略不足
原因:前述机制主要解决 Kafka 内部的消息重复,但在复杂的业务流中(如跨系统调用、批量重试、数据回补),缺乏端到端的幂等设计和全局唯一标识,使得业务层不得不承担复杂的去重逻辑,增加系统复杂度和出错概率。
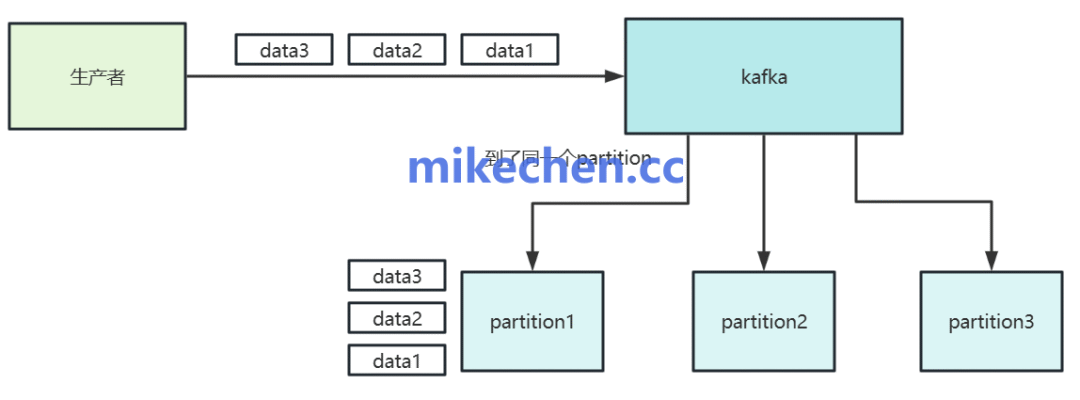
图4:生产者产生的数据流被路由到 Topic 的各个分区中
解决方案:
- 设计带唯一标识的消息:在消息体(或 Header)中携带全局唯一 ID,例如 UUID、由“业务主键+时间戳/场景”生成的组合键。这是实现去重的基石。
- 消费端实现幂等检查:在消费者侧,利用 Redis 或数据库等外部存储,以上述唯一 ID 为键建立去重表或缓存。在处理前先查询该 ID 是否已存在,实现“至少一次”到“精确一次”的转换。对于海量数据场景,可考虑布隆过滤器进行前置过滤。
- 设计幂等的业务操作:这是最根本的解决方案。尽可能将业务逻辑设计为幂等操作,例如使用“INSERT ... ON DUPLICATE KEY UPDATE”的数据库语句,或提供支持幂等调用的业务 API。这样即使消息重复,最终状态也是正确的。
消息重复问题贯穿于 Kafka 使用的各个环节,从客户端配置到集群运维,再到业务架构设计,都需要通盘考虑。理解其根本原因,并组合运用生产者幂等、消费者手动提交、acks=all 以及业务级去重策略,才能构建起健壮的、具备“精确一次”或“有效一次”处理能力的数据管道。
本文深入探讨了 Kafka 消息重复的常见场景与解决方案,更多关于分布式系统、高并发架构及 消息中间件 的深度解析,欢迎访问云栈社区进行交流学习。 |  发表于 2025-12-30 22:03:12
|
查看: 265|
回复: 0
发表于 2025-12-30 22:03:12
|
查看: 265|
回复: 0
