有段时间没有更新文章了,这并非没有想法,而是过去一个月几乎所有时间都投入到了一个项目上。
当时我正在学习泰语,想找一个好用的应用辅助复习。尝试了Anki和Quizlet(甚至购买了一年会员),但体验依然不尽如人意。首先,词库导入就是个麻烦事,尤其在发音方面。如果卡片中包含音标,由于是纯文本识别,发音往往不准。同时显示中英文也常出问题,实际体验并不理想。
市面上的一些主流应用对中文用户也并非特别友好。像Hello Talk和Ling这类应用,音标体系杂乱,且每天限制学习10个词,动不动就弹出会员订阅提醒。
更重要的是,这些应用的设计似乎并未完全从学习者角度出发。例如,一些软件的AI聊天功能无法关联你正在学习的单词和掌握程度,单词库的排序也像我们学英语时每次都从“abandon”开始,完全不考虑用户的实际水平。
后来我意识到,许多工具从一开始或许就不是为“真正学会”而设计的。你学得越认真,反而越容易被复杂的规则和付费墙劝退。
于是,我做了一个看似冲动的决定——自己动手做一个。
泰语本身为什么这么难
如果你看过泰文,会发现它没有逗号和句号。这导致一个问题:你看到的文本可能类似“iamhappyeveryday”这样一串连在一起的字符,其中包含几个单词、如何划分都难以确定,因为一个字母既可能属于前一个单词的结尾,也可能是后一个单词的开头。
泰语中存在大量不标准的规则,因此学习时需要练习音节切分(但实际体验中,我认为掌握单词本身比切分规则更重要,因为不规则情况太多)。基本上,只有掌握了音节划分才能正确读出单词。泰文有声调符号,但同一符号在不同单词中可能发不同的调,这对学习者来说非常困难。泰语共有5个声调,还有长短音之分,不像汉语拼音中声调符号直接决定了发音。
图:音节训练界面,用于练习泰文音节切分和声调选择。

发音与音标:最深的坑
这一部分,如果你只是想学泰语可以跳过;但如果你做过语言类产品,大概率会踩同样的坑。
学习语言通常需要音标辅助,如汉语拼音、英语音标。泰语也类似,但官方并未规定一套标准音标,导致市面上辅助发音的标注五花八门。例如“你好”,就有“sawadii”、“sawadee”等多种写法;“鸡”则有“gai”、“kai”、“khai”等,令人困惑。
这也使得我们无法直接依赖AI生成的内容来朗读单词。因此,我直接采用了语言学校教材中的发音规则,这套规则相对规范,对每个辅音、元音都有易于理解的标注。但其中仍有不少模糊之处,比如尾音规则:同一个字母有时转写为“i”,有时是“y”,教材并未详细说明特殊情况。
泰语不像拼音有固定的1234声,而是通过常用规则(看尾音、声母、元音等判断声调)加上特殊的音调系统来区分。音调系统本身也有例外,一个符号可能对应几种声调,不像中文一声永远是一声。此外还有静音、连读、隐音等种种规则。
我的实现路径颇为曲折。起初,我使用Google NotebookLM导入教材,梳理规则后让Claude Code按规则实现。但由于特殊案例太多(比如单词可能是两个独立词的合并),无论如何匹配都可能出错。这导致第一版转写引擎的准确率只有50%左右。
随后,我找到了一个五年前的开源库,其做法是用一个词库覆盖常用词来实现转写。问题是,词库未覆盖的单词就无法处理。于是,第二版我将这个词库与自研的转写引擎叠加,准确率有所提升,但错误依然不少。
继续探索后,我找到了一个业界维护的方案,其核心是通过NLP分析语义来判断前后词关系,再决定如何拆分音节。第三版我们前置了这项服务,先分析语义拆分音节,再将每个音节转写成国际音标(IPA)。这一版准确率显著提高,但在大量特殊规则词面前,语义分析会首先失效,导致后续转写全错。面对长词时(例如曼谷的全称),很难界定它是一个单词还是一个句子,也常导致拆分错误。
于是,我调整思路:先拆分成单词,再拆分成音节。幸运的是,我找到了一个包含单词简写规律(如a3e4这类模式)的词库。基于单词规律 + NLP语义分析 + 句子预拆分 + 音节拆分,我们折腾出了第四版音标引擎,准确率估计达到了80%。但新问题是,NLP服务在单词音节转写时存在较大的性能瓶颈。
目前正在设计第五版,尝试用Lexer(词法分析器)的方式重写转写引擎。因为当前引擎是按字符匹配的,它看不到单词全貌,只能像打补丁一样检索后转写,而不是整体处理。第五版是否最佳尚无定论,这方面若有专家,也欢迎交流。
如何将“学泰语”拆解为可执行的任务
这里聊聊如何制作一个学习工具。最初的构思是做一个类似Anki或Quizlet的工具,方便背单词。后来发现很多人有类似需求,就决定做成网站发布。
泰文是表音文字,所见即所得,看着文字就能直接发音,因此需要学习其辅音和元音。相同的发音可能由不同的辅音、元音组合构成,所以必须记住每个辅音、元音的发音规则。
为此,我设计了几个专项训练。因为辅音在单词首尾位置可能有不同读音,所以专门拆分成两个训练模块。
图:学习进度概览与辅音字母熟练度统计界面。
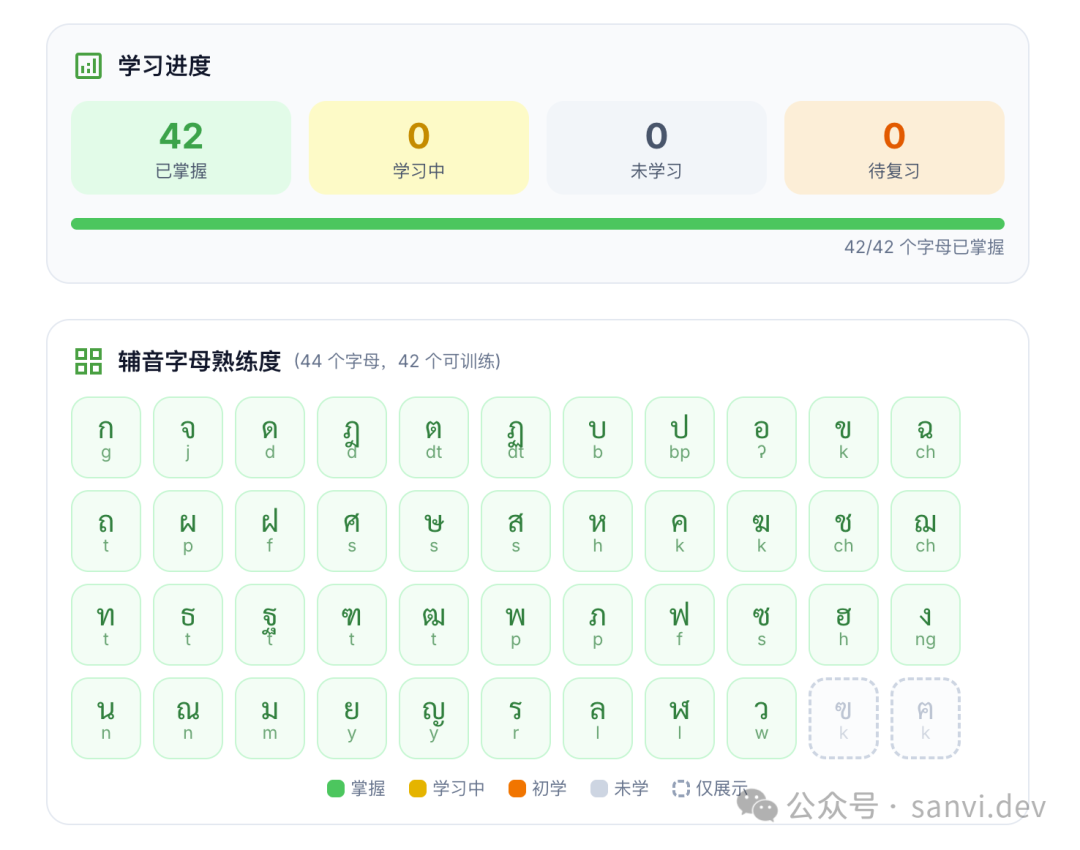
发现:仅6%的用户能坚持学习7天
背单词的困境
解决了词库问题,核心仍回归到学习本身。背单词模块采用了艾宾浩斯间隔重复算法,简单说就是学完后,在即将遗忘的时间点(如10分钟后、1天、2-3天、7天、15天)安排复习,以强化记忆。
但这样做有个明显问题:一旦中断打卡,累积的待复习单词会越来越多,用户看到大量任务容易产生畏难情绪而放弃。背单词本身是枯燥的,数据也证实了这一点:仅6%的用户能在7天内进行第二次学习。
在训练方式上,我们参考多邻国,设计了看中文选泰文、看泰文选中文字、音节组装、听音选词、看汉字写泰文等多种模式。虽然形式上没那么单调,但对学习动力提升有限。作为“学渣”,我反思:平时我们是如何把一些“没用”的知识塞进脑子的?
比如,“羊羊羊”这个重复,会让你联想到什么?这就是通过大量重复强行植入记忆。我观察了Quizlet和多邻国里的游戏模块,但感觉无聊且记不住。
游戏化改造
于是,我开始思考有哪些轻量、无需动脑的小游戏适合用来打发时间?消消乐、2048这类游戏似乎很合适。但要让人更想玩,积分和排行榜是有效的驱动力。
设计核心是将小游戏与单词学习结合,创造新玩法:
- 单词消消乐:通过组合正确音节来消除方块。
- 记忆翻牌:匹配中文与泰文对应的卡片。
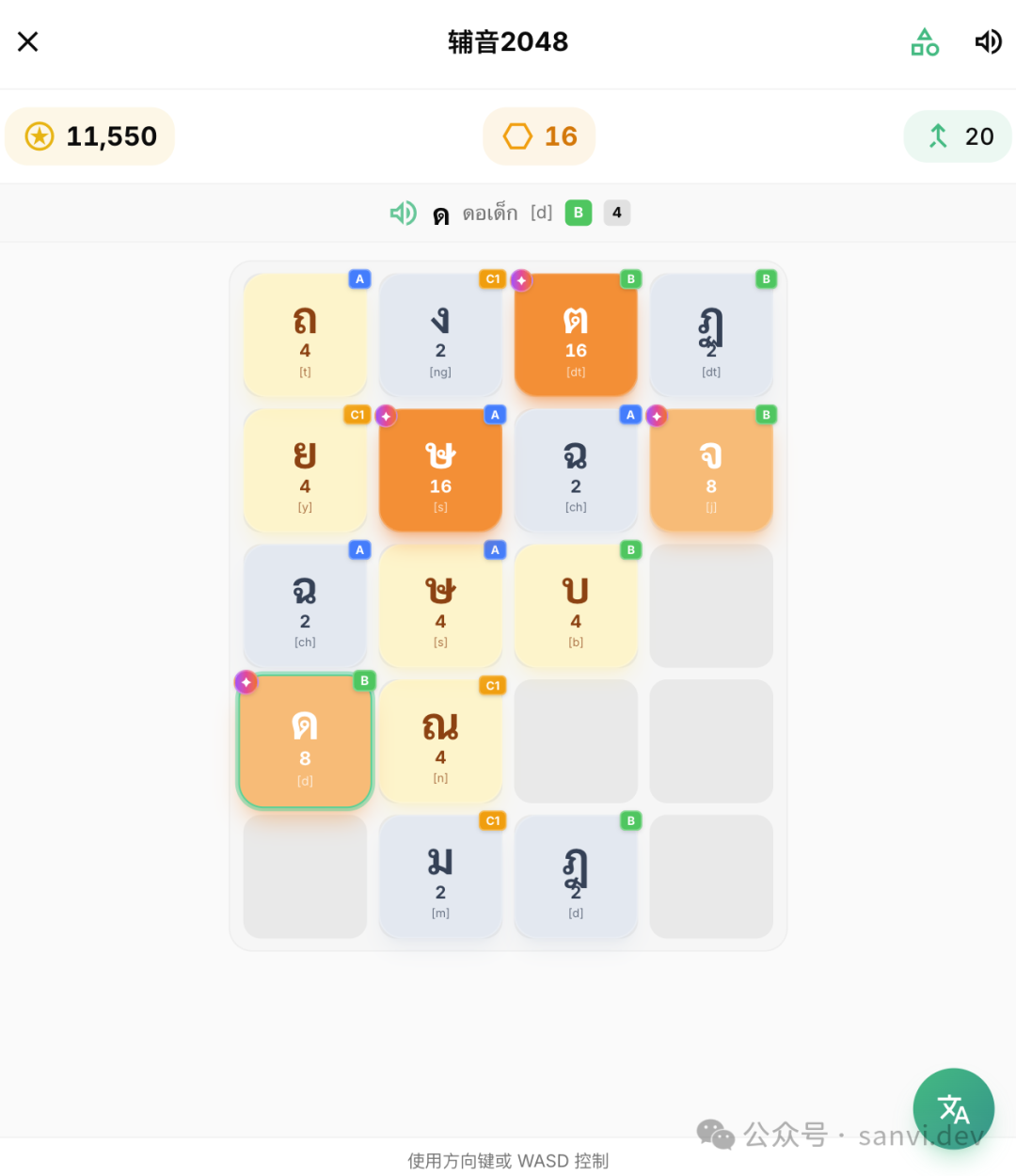
- 辅音2048:将2048玩法融入,相同分类的辅音可以合并升级。
无论哪种游戏,配对成功后都会显示单词的泰文、中文及发音,以此加强记忆。
图:单词消消乐游戏界面。
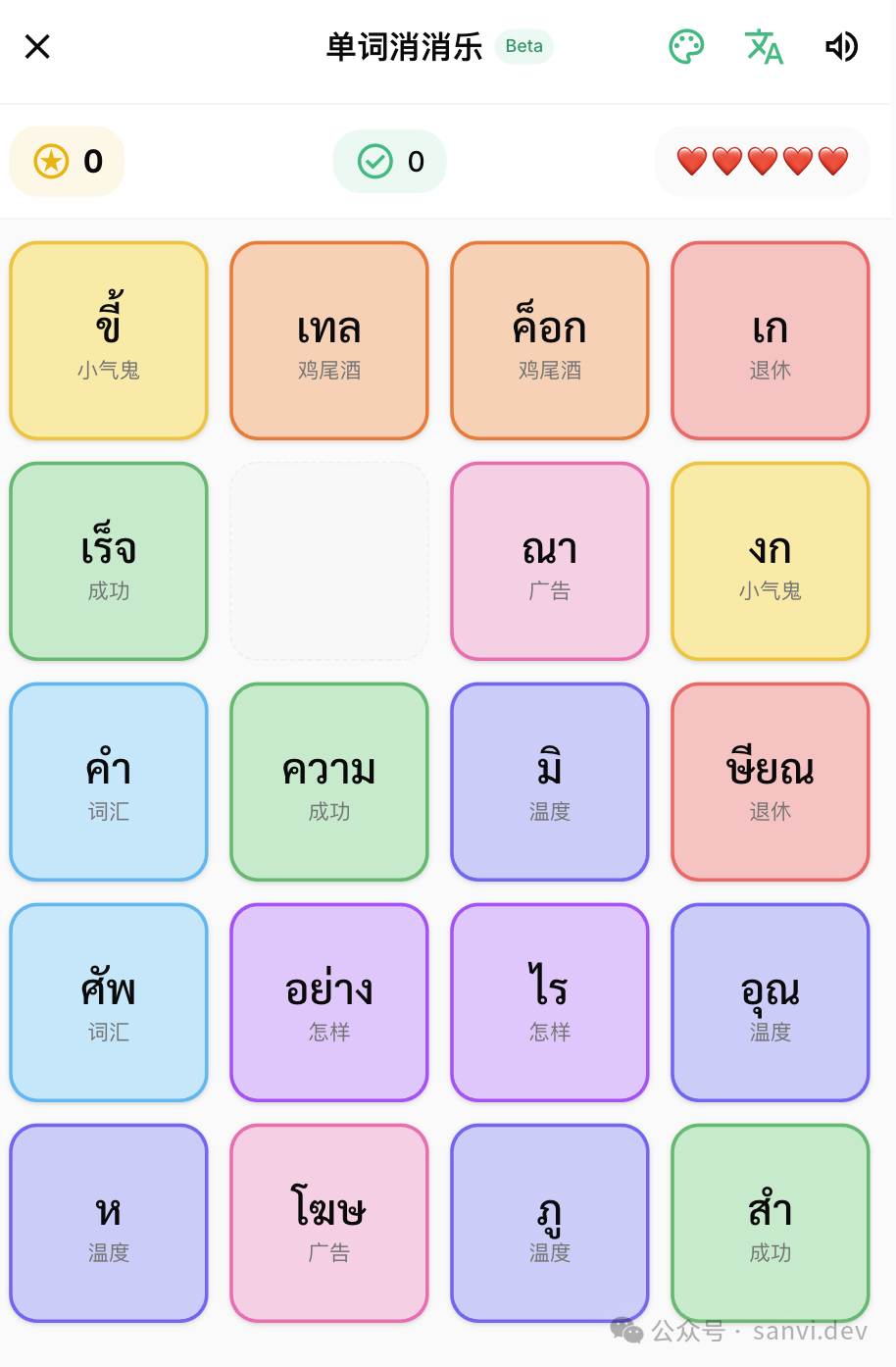
图:记忆翻牌游戏界面。
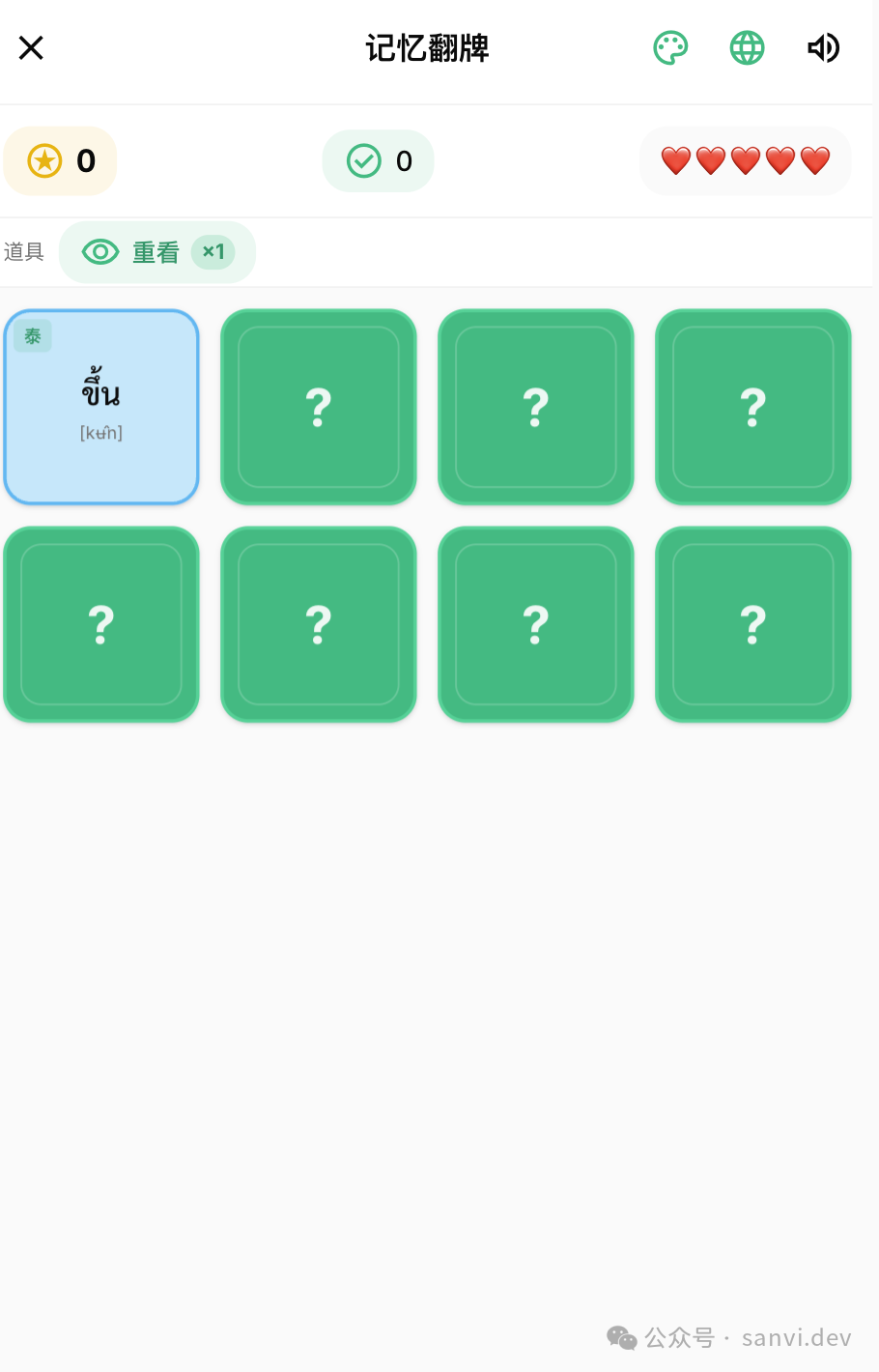
图:辅音2048游戏界面与排行榜。
翻译难题
起初想找现成的汉泰或英泰词典服务,但资料稀少。最终只找到一个公开的1000个常用泰语单词列表。上线后有用反馈翻译不准,我尝试本地部署Qwen的8B模型跑了一遍翻译,效果也不理想。
最后无奈选择氪金调用线上大模型进行翻译,但这仍非百分百准确。单词含义会随语境变化,且泰语有书写体、礼貌用语等区分,不过基本能满足使用需求。
音频/TTS与移动端的连环坑
最初因为只有1000个单词,我专门预录了所有音频。但许多手机浏览器用户反馈听不到声音。原因是他们使用了自定义词库,而这些词库没有预录音频。
自定义词库功能的设计初衷也很无奈。我本身不是专业教育者,初衷只是做一个方便自己记忆的工具,其中音频、翻译、IPA显示都可能存在错误,因此被批评“用错误内容误人子弟”。说实话,除了Anki这类需要用户自行制作专业词库的应用,我还没见过哪个好用的背单词应用能完全免费且无限制。当时差点因此关闭网站。
今年做独立产品以来“抗压能力”有所提升,于是设计了自定义词库功能,本意是让大家像用Anki一样自行导入词库,并可以共享订阅。但我高估了用户DIY的积极性,创建词库的人很少,大部分用户不喜欢折腾。如果我喜欢折腾,可能一开始就不会做这个项目了。
然而,这种突发奇想加入的功能,往往考虑不周,音频问题就是一例。于是转向TTS(文本转语音)播放,但用户反馈时好时坏。我发现浏览器的TTS非常不稳定,尤其在手机端更不可控。
接着转向商业TTS服务,以确保跨浏览器、跨终端体验一致。但新问题又来了:手机播放仍有各种问题。通过日志排查,发现是手机权限问题。有幸在社交平台结识一位做法语学习工具的前辈,讨论后得到的方案是:将TTS音频缓存到本地,然后以播放本地音效的方式绕过移动端浏览器的限制。此外,iOS会限制自动播放,因此在交互上默认静音,需用户点击授权后才能自动播放音频。
你看,这就是AI无法替代的经验。我觉得现在Vibe Coding这么火,这类实战咨询服务或许会有市场,当然前提是能接到客户。
当功能开始产生真实成本
转向商业TTS后,成本就不再是固定值了。此前的成本(开发、服务器、域名、预生成内容)是可预估的。但商业TTS服务费会随用户使用量增长而攀升,虽然目前体量小,但不得不未雨绸缪。
因此我们接入了支付,主要使用Stripe,为后续拓展多语言做准备。支付宝订阅需单独联系客服开通。如何开通Stripe本文不展开。
支付接入相对简单,下载llms.txt规范文件后,让Claude Code按规范接入即可,之前有项目经验,基本顺利。
唯一尴尬的是:上线两周无人支付,却有用户创建了客户信息。起初没在意,后来才发现是上线时忘记配置支付回调链接。毕竟线上测试要花真金白银,当时疏忽了。
预期与现实:AI阅读功能并未达到预期
AI阅读
随着词汇量增长,阅读理解是自然需求。但教材中的文章内容(如“张三买了几只鸡”)往往让人提不起兴趣。因此我们构思了这个功能:根据用户近期要复习的单词,按兴趣场景生成文章。我设计了30多种场景和几大分类,用户可根据兴趣生成文章,甚至能基于现有文章的提示词进行二创。
根据在语言学校的观察,很多用户是因泰国明星而开始学泰语的。因此我加入了“泰式纯爱”场景,结果该场景迅速霸榜。
但数据显示,文章的题目回答率只有22%,即五篇文章中仅有一篇被认真完成答题。我尚未想好如何提高该功能的转化率,不确定用户是出于好奇生成文章,还是真的想通过阅读学习。
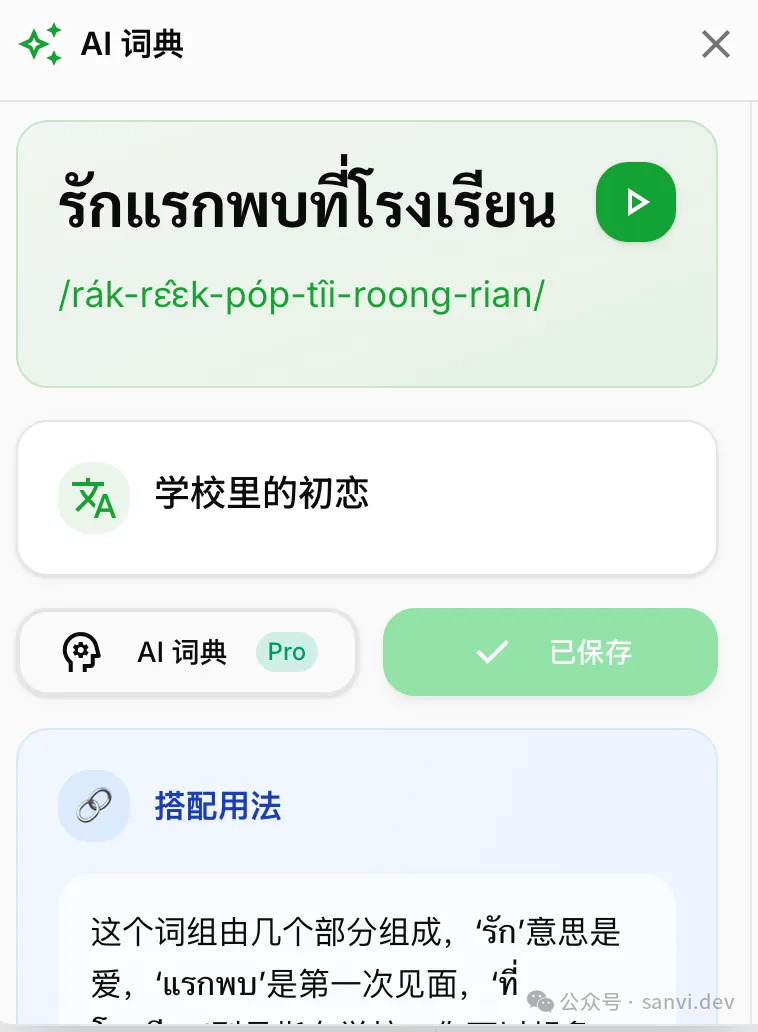
AI词典
这个功能旨在解决日常使用Google翻译与深度学习之间的矛盾。我常用Google翻译听单词发音,但有时其准确性不如AI。AI能提供IPA读音(若不准确,我可凭借泰语知识手动修正),更重要的是能给出多义解释、例句等辅助理解,最好还能直接加入生词本。
因此设计了这个功能,但作为网页内的悬浮球,体验并不完美。例如,重新打开页面会被刷新。不过,我发现有用户很喜欢用它来翻译,尽管查看详细解释的使用率没那么高。
图:AI词典界面,展示单词详情与用法。
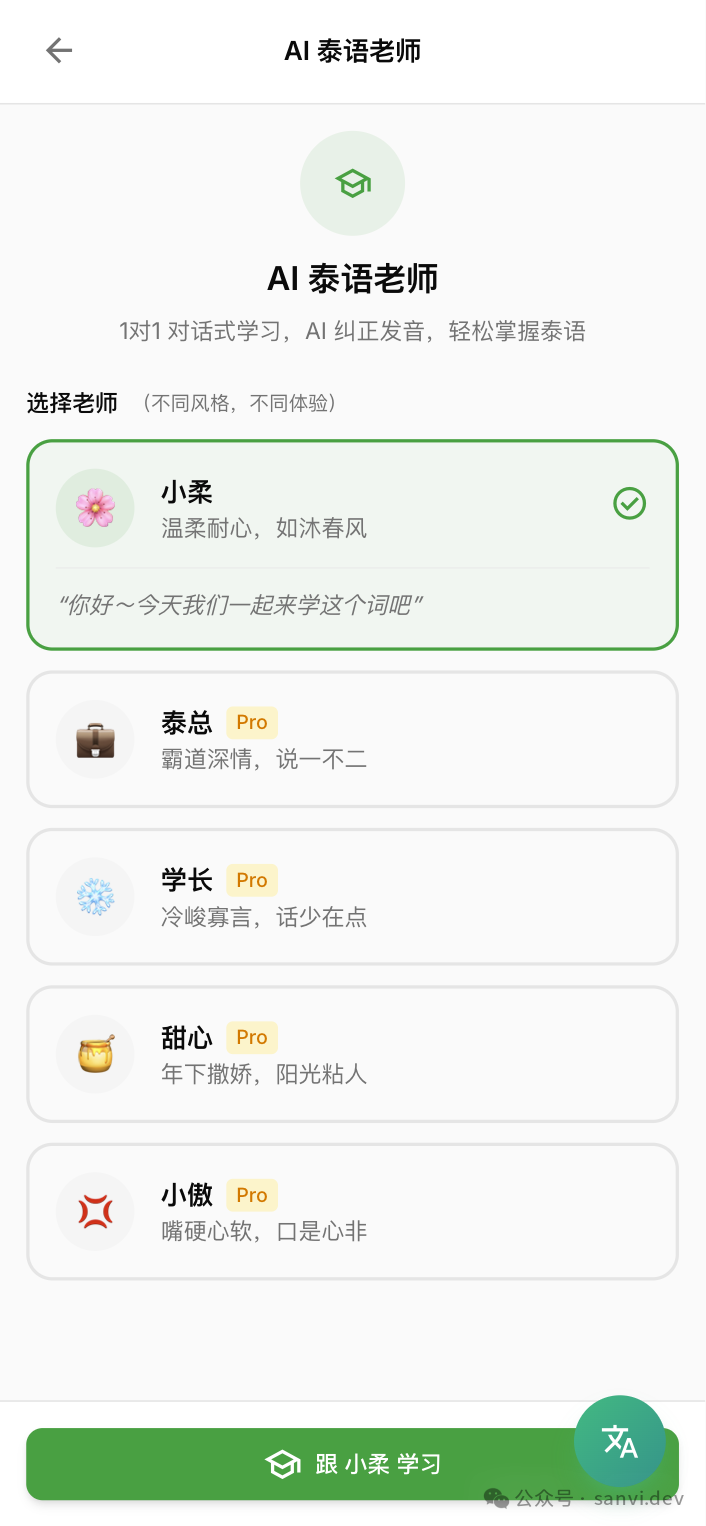
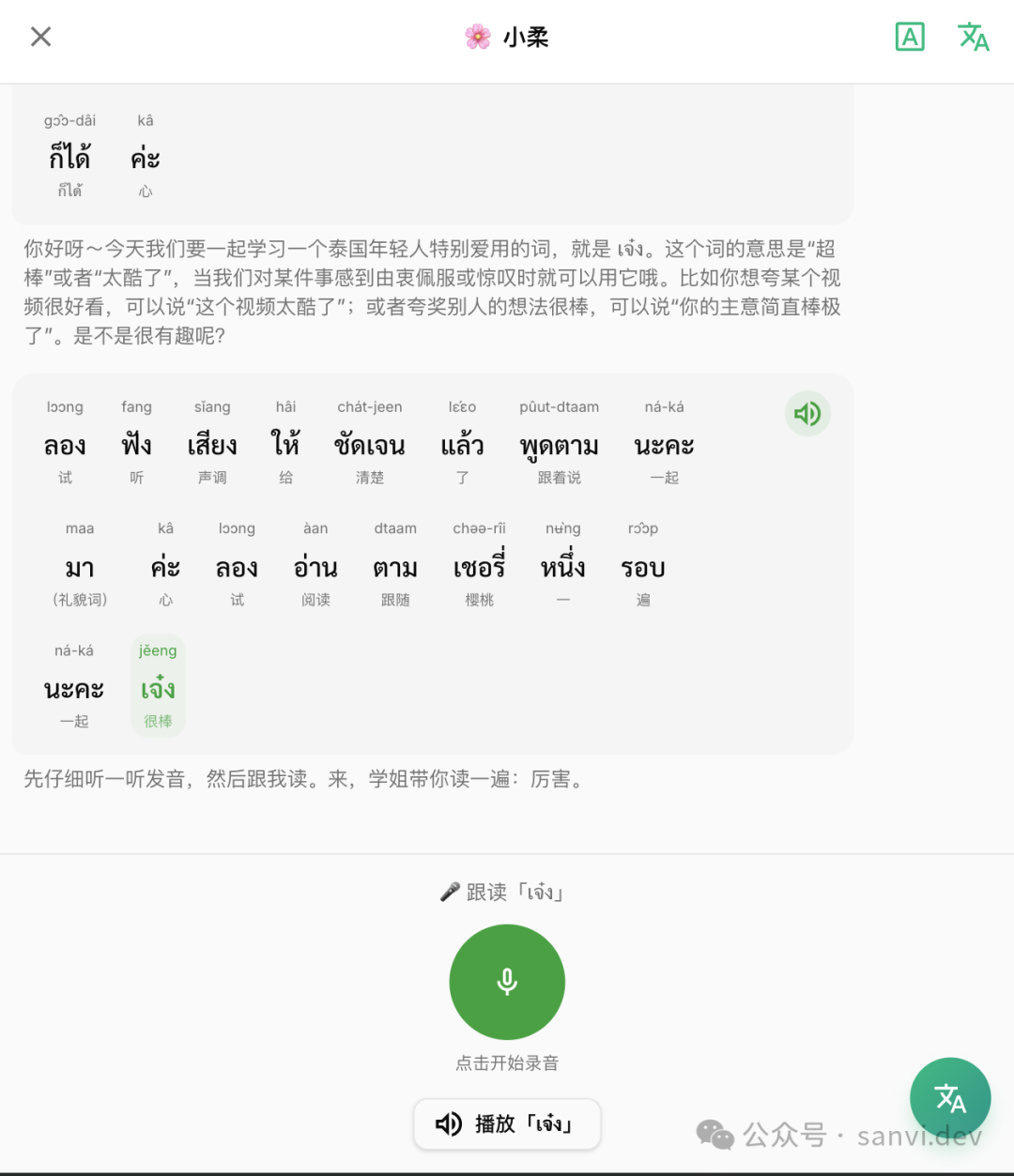
让AI真正“执教”:AI老师功能
之前的许多功能仍停留在工具层面,解决“听”和“读”,但未解决“说”的问题。有用户反馈希望有AI纠音功能。恰逢Gemini Flash 3发布,据称功能强大,且支持音频输入,这让AI纠音成为可能。
实施中遇到几个问题:
- 流程控制:初期尝试开放对话,结果容易跑偏。这与直接问GPT有何区别?因此,我结合真实上课流程:泰文解释单词 -> 跟读 -> 提问 -> 拓展问题,让学生用所学单词回答,并纠正其发音和语法。
- 流程执行:将整个流程交给AI控制,发现AI并不按阶段执行。于是改为由系统控制流程,AI仅判断学生当前回答/跟读结果是否达标,以进入下一阶段。
- 技术整合:句子的拆分、转写、翻译、音频均可复用前序方案。最后找到一个支持在手机网页端录制MP3的库,解决了录音问题。
仅这样仍显枯燥,我让AI从网上搜集泰剧中比较流行的人设(我本人不太看泰剧),整理出几种性格并融入到AI老师中。至于是否符合角色性格,我无法亲自验证。
图:AI泰语老师角色选择与教学界面。
其他零散的改动和设计不再赘述,光是记录功能点的文档就有30个,更多的惊喜(或惊吓)留待大家自行探索。
关于Vibe Coding的真实体验
目前核心功能已基本完善,但仍有一堆问题待解决。在此复盘一下,这也是我目前用Vibe Coding最顺利的一个项目,一个完全由AI编写的中小型商业项目。
我们看到很多“10分钟Vibe出一个XX”的项目,但很少有人展示相对复杂的项目。当然,网上也有各种“神技”和“神模型”,但往往热一阵就过了。以下是我的一些实践经验。
原型与UI
虽然我的界面称不上极致精美,但也不像常见的AI生成的Demo那样粗糙。我的方法是:
- 在Google Stitch中编写需求,让其产出原型图。将原型图丢给Claude Code,让其基于此创建一套设计规范(记得保存为MD文件)。
- 如果基于特定组件库(如shadcn),可去其官网找到
llms.txt并保存到本地。提示Claude Code时引入该文件,AI便能按照该组件库规范创建界面。
图:项目早期的仪表盘与词汇学习卡片设计。
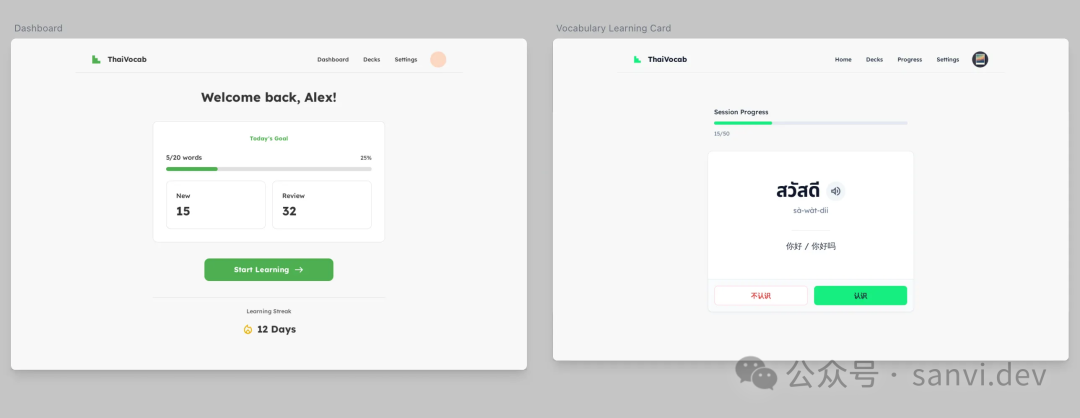
另一个方法是使用Google AI Studio中的Gemini Pro 3模型(免费额度足够使用),选择“Build”功能。你可以找一些喜欢的网站设计截图丢给它,生成风格类似的网页框架,然后将资源拉取到本地交给Claude Code处理。
图:使用AI工具生成UI设计风格的参考过程。

文档管理
这是最重要的一环,成败关键在此。文档质量直接影响Vibe Coding能否顺利进行。我的做法是在docs目录下建立几个部分:
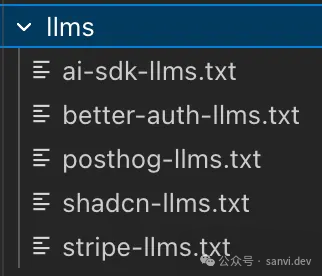
- llms目录:存放常用集成的说明文件,如AI SDK、Stripe、Better-Auth等。想接入某项服务时,先查看其是否有
llms.txt,有则下载到本地。这能帮助Claude Code更好地检索和理解如何集成。但需注意文件可能过时。
图:存放各类服务集成说明文件的目录。
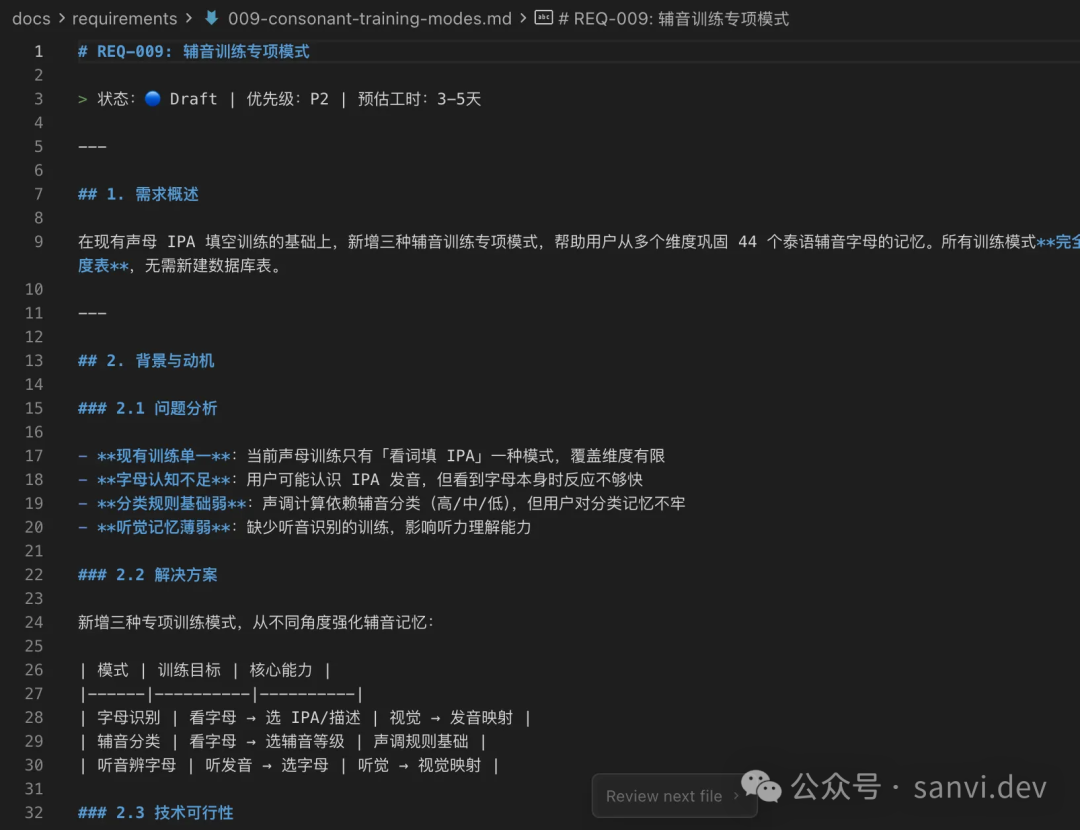
- requirements(需求池):对于复杂需求,需将细节(产品逻辑、技术架构)讨论清楚。每个需求文档按序号编号。可以让Claude Code搜索网络上的最佳实践来编写模板。务必维护一个
README.md索引文档,方便AI检索。在实现时,也可让AI基于需求文档制定开发计划。
图:需求文档示例与需求状态看板。

- features(功能列表):这是最重要的部分。每个功能单独维护一份文档,内部可链接到其他相关文档,实现功能自治。同样需要
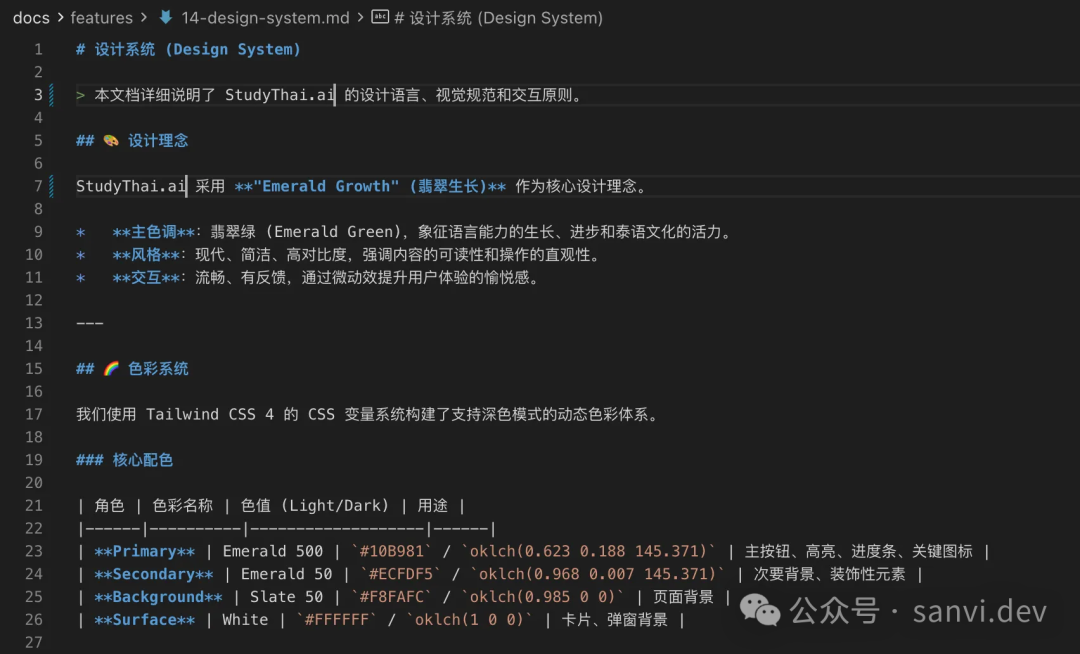
README.md索引文档,以及系统的更新日志。例如,我将设计系统也单独维护为一份功能文档。
图:项目设计系统文档片段,说明设计理念与色彩系统。
工具链
- 主力开发:Claude Code。
- 复杂需求讨论:Gemini Pro 3(之前购买的订阅在Warp、Cursor中基本够用)。
- 辅助:部分需求使用GPT-4o。
Cursor主要在Claude Code额度用尽时顶替,但同样模型下能力差距明显。我猜测是因为Claude Code使用了多智能体进行规划,而Cursor仍停留在文档规划层面。
Antigravity是一个亮眼的IDE,主要可白嫖部分额度的Gemini Pro 3。其智能体内置了浏览器,能打开Chrome进行操作。这对不熟悉前端调试的我非常有用,无需再口头描述问题,AI会自行运行、截图、录屏分析。如果你让它做些设计,它甚至会用nano banana生成图片并添加到网页中。
GPT-4o近期更新并未扳回太多优势,我觉得ChatGPT急需上线真正的多智能体规划模式。
最后是Warp终端,很多环境依赖和数据问题可以在终端里解决,这在Cursor IDE中可能运行困难。
开发经验
很多时候,你需要人为干预AI的实施。例如,可以将Claude Code的规划方案拿去问Gemini Pro 3或ChatGPT,获取建议后再反馈给Claude Code,这能有效提高实施质量。
如果你发现某个需求需要多轮复杂对话才能厘清,那就应该先进入规划讨论阶段,形成详细方案后再让AI执行。不要过度依赖单一工具的“检查点”功能,因为你是多工具、多模型协作,尽量以Git提交为准。一个功能完成就提交,管理好分支这些基础就不赘述了。
如果你正在学习泰语,或者正在开发AI产品、教育产品、独立项目,这篇文章记录的经历与踩过的坑,或许能为你提供一些参考。
 发表于 2025-12-31 00:30:18
|
查看: 227|
回复: 0
发表于 2025-12-31 00:30:18
|
查看: 227|
回复: 0
