当你使用千兆网卡传输一个10MB文件时,可能不知道有超过80%的CPU时间本应消耗在数据包的分片和校验上,而现在这些工作正悄悄地在网卡硬件中完成。
现代数据中心网络已经从10Gbps迈向100Gbps甚至更高,传统的软件网络协议栈处理方式已经无法满足高速网络的需求。网络卸载技术应运而生,将原本由CPU负责的网络协议处理任务转移到专用硬件,释放宝贵的CPU资源用于实际业务计算。
1. 网络卸载:为什么我们需要它?
1.1 传统网络处理的瓶颈
在经典网络模型中,每个通过系统的数据包都需要CPU的全程参与:从用户空间缓冲区拷贝到内核空间,经过TCP/IP协议栈的层层处理,加上各种头部信息,计算校验和,最后才交给网卡发送。
接收路径同样复杂,网卡每收到一个数据包就会产生一个中断,CPU需要响应中断,处理数据包,进行协议解析,再将数据传递到用户空间。
随着网络速度从100Mbps提升到100Gbps,数据包处理能力成为关键瓶颈。以1500字节的标准MTU (最大传输单元) 计算,10Gbps网络每秒需要处理约83万个数据包,这已经接近普通CPU的处理极限。
1.2 卸载技术的演进历程
网络卸载技术的发展经历了几个关键阶段:
第一阶段:基础卸载 - 将最简单的任务如校验和计算转移到网卡硬件。操作系统仍然需要将完整的数据包复制到内存并生成头部,但校验和的计算由硬件完成。
第二阶段:分散/聚集 (Scatter/Gather) - 操作系统不再需要将数据复制到连续内存中,而是将数据包的各个部分 (头部、数据) 的位置信息传递给驱动程序,由驱动程序或硬件负责“收集”这些分散的部分。
第三阶段:高级分段卸载 - 将大数据包的分片任务完全交给硬件。操作系统只需要提供头部模板和大块数据 (最大64KB) ,由硬件负责分割、添加头部和计算校验和。
第四阶段:完全协议卸载 - 将整个TCP协议栈甚至更高层的处理都卸载到智能网卡或DPU (数据处理单元) 上,CPU几乎不参与网络数据处理。
下面的表格展示了网络卸载技术的主要演进路径:
表:网络卸载技术演进阶段
| 阶段 |
技术特征 |
典型技术 |
性能提升 |
硬件要求 |
| 第一阶段 |
基础计算卸载 |
校验和卸载 |
10-15% CPU降低 |
基础卸载网卡 |
| 第二阶段 |
内存优化 |
分散/聚集DMA |
减少内存拷贝开销 |
支持SG的网卡 |
| 第三阶段 |
协议处理卸载 |
TSO/GSO, LRO/GRO |
大幅减少中断和CPU周期 |
智能网卡 |
| 第四阶段 |
完全协议栈卸载 |
TCP卸载引擎(TOE), RDMA |
CPU几乎零参与 |
DPU/智能网卡 |
1.3 关键术语解析
在深入技术细节前,我们先明确几个核心概念:
- MTU (最大传输单元): 网络中能够传输的最大数据帧大小,以太网标准为1500字节。
- MSS (最大分段大小): TCP连接中实际能够传输的最大数据量,通常是MTU减去TCP和IP头部大小 (约1460字节)。
- 分段 (Segmentation): 将大于MSS的TCP数据分割成适合网络传输的小段。
- 分片 (Fragmentation): 在IP层将大数据包分割成适合MTU的小包。
- 卸载 (Offload): 将原本由CPU执行的任务转移到专用硬件执行。
2. 发送路径:TSO与GSO的深度剖析
2.1 TSO:硬件分段卸载
TCP分段卸载 (TSO) 是最早出现的高级网络卸载技术之一。它的核心思想很简单:让网卡代替CPU执行TCP分段任务。
没有TSO时,当应用程序发送大量数据 (如32KB) 时,TCP协议栈需要将其分割成多个MSS大小 (如1460字节) 的数据段,为每个段添加TCP和IP头部,计算校验和,然后将这些小包交给网卡。
开启TSO后,整个过程发生了革命性变化:
// 简化的TSO处理流程概念代码
void tcp_send_with_tso(struct sock *sk, struct sk_buff *skb, size_t data_len)
{
// 1. 应用程序发送大数据 (如32KB)
// 2. 内核不立即分段,而是构建一个“超级数据包”
build_super_packet(skb, data_len);
// 3. 设置TSO描述符,告诉网卡如何分段
struct tso_desc desc = {
.mss = 1460, // 每个段的最大大小
.header_template = build_header_template(skb), // 头部模板
.data_len = data_len, // 总数据长度
};
// 4. 将超级数据包和描述符交给网卡
nic_transmit_with_tso(skb, &desc);
// 5. 网卡硬件负责:
// - 按MSS分割数据
// - 为每个段复制头部模板
// - 更新每个段的序列号、校验和等字段
}
TSO的工作流程可以用下面的图表示:
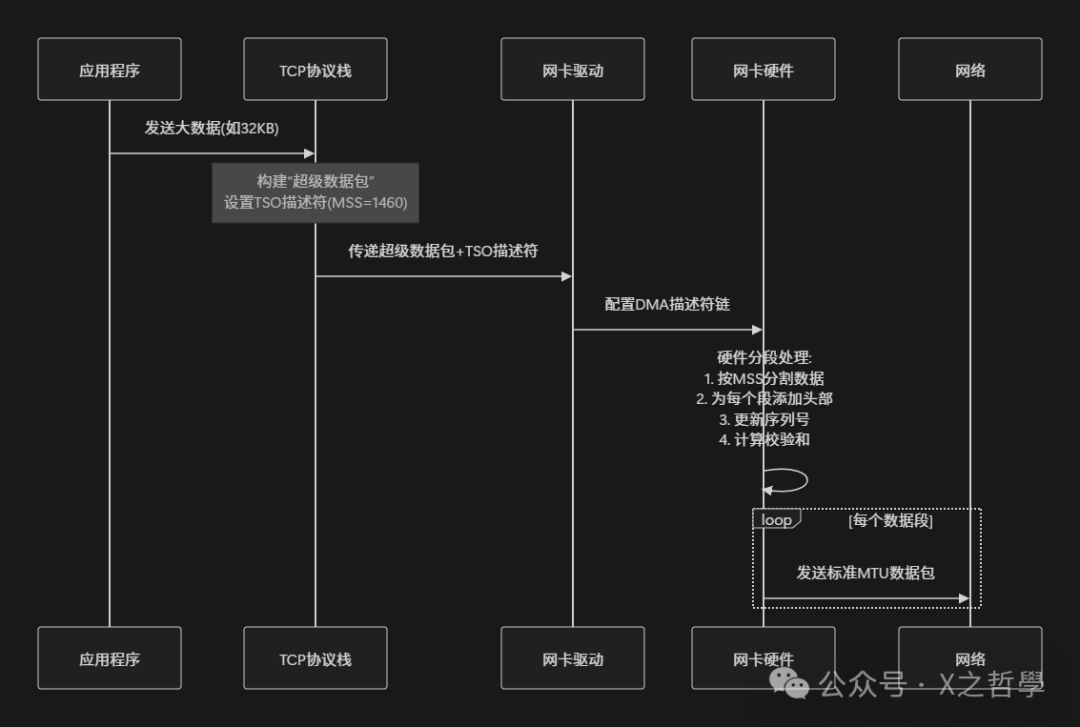
图1:TSO硬件分段卸载工作流程示意
TSO的优势是显而易见的:
- 减少CPU中断: 原本需要处理20多个数据包现在只需处理1个“超级数据包”。
- 降低内存带宽需求: 减少了多次头部复制和内存访问。
- 提高吞吐量: CPU可以更专注于应用程序逻辑而非网络处理。
但TSO也有局限性:它完全依赖硬件支持。如果网卡不支持TSO,这些优化就无法实现。正是这一限制催生了GSO的出现。
2.2 GSO:通用分段卸载
通用分段卸载 (GSO) 是Linux内核开发者Herbert Xu在2006年提出的创新解决方案。GSO的设计哲学是:尽可能推迟分段操作,直到最后一刻。
与TSO不同,GSO不要求硬件支持。它采用了一种巧妙的“延迟分段”策略:
- 在协议栈处理时,保持大数据包完整。
- 当数据包到达设备驱动时,检查硬件能力。
- 如果硬件支持TSO,则让硬件分段。
- 如果硬件不支持,则在驱动中进行软件分段。
// GSO的核心逻辑 (简化概念)
void dev_queue_xmit(struct sk_buff *skb)
{
// 检查是否启用了GSO
if (skb_is_gso(skb)) {
// 检查设备能力
if (dev->features & NETIF_F_TSO) {
// 硬件支持TSO,让硬件处理
device_driver_tso_transmit(dev, skb);
} else {
// 硬件不支持,在驱动中进行软件分段
segment_in_driver(dev, skb);
}
} else {
// 普通传输路径
normal_transmit(dev, skb);
}
}
GSO的精妙之处在于它的通用性和灵活性。它创建了一个抽象层,使得上层协议栈不需要关心底层硬件能力。无论硬件是否支持分段卸载,协议栈都可以使用相同的接口提交“超级数据包”。
这种设计带来了显著的性能提升。即使在不支持TSO的硬件上,GSO也能通过减少协议栈的遍历次数来提高性能。每个数据包只需经过一次完整的协议栈处理,而不是像传统方式那样每个小段都要独立处理。
2.3 TSO与GSO的对比与协同
TSO和GSO不是相互竞争的技术,而是互补的。在Linux内核中,它们通常协同工作,形成完整的分段卸载解决方案:
表:TSO与GSO对比
| 特性 |
TSO |
GSO |
| 实现位置 |
主要在网卡硬件 |
主要在Linux内核 |
| 硬件依赖 |
完全依赖硬件支持 |
不依赖硬件,但能利用硬件能力 |
| 分段时机 |
在网卡硬件中 |
尽可能推迟,在驱动中最后处理 |
| 适用协议 |
主要是TCP |
TCP、UDP等多种协议 |
| 性能影响 |
显著减少CPU使用 |
减少协议栈处理开销 |
在实际系统中,GSO作为TSO的补充和后备。当硬件支持TSO时,GSO将分段任务完全交给硬件;当硬件不支持时,GSO在软件中完成分段,但仍能获得部分性能提升。
3. 接收路径:LRO与GRO的聚合魔法
3.1 LRO:大量接收卸载
如果说TSO/GSO是发送路径的加速器,那么大量接收卸载 (LRO) 就是接收路径的聚合器。
在网络传输中,发送方将大数据分割成小包发送,接收方则需要将这些小包重新组合成原始数据。传统方式中,每个到达的小包都会触发一次中断和完整的协议栈处理,当数据流量大时,这会消耗大量CPU资源。
LRO的基本思想是:在将数据包传递给协议栈之前,将属于同一个TCP流的多个小包合并成一个大包。
// LRO合并逻辑概念
void lro_receive_skb(struct net_device *dev, struct sk_buff *skb)
{
// 查找匹配的LRO会话
struct lro_session *session = find_lro_session(skb);
if (session) {
// 找到匹配会话,合并数据包
if (can_merge(skb, session)) {
merge_skb_into_session(skb, session);
// 检查是否应该提交会话 (超时或数据满)
if (should_flush_session(session)) {
struct sk_buff *big_skb = build_lro_skb(session);
netif_receive_skb(big_skb); // 提交大包给协议栈
free_lro_session(session);
}
return; // 合并完成,不进一步处理
}
}
// 无匹配会话或无法合并,正常处理
normal_receive_path(skb);
}
LRO的实现方式有两种:
- 驱动级LRO: 在网卡驱动中实现,合并操作在中断上下文中进行。
- 硬件LRO: 由智能网卡硬件完成合并,直接向系统提交大包。
LRO的合并条件相对宽松,主要检查:
- 相同源/目的IP和端口。
- 连续或重叠的TCP序列号。
- 相同的TCP控制标志。
3.2 GRO:通用接收卸载
虽然LRO能有效减少接收路径的CPU消耗,但它存在一个严重问题:合并条件过于宽松,可能导致数据错误。特别是当系统启用IP转发时,LRO可能合并不应该合并的数据包,导致校验和错误或其他问题。
通用接收卸载 (GRO) 是Linux内核中LRO的继任者,它解决了LRO的缺陷,提供了更严格、更安全的合并机制。
GRO的设计更加精细和智能:
// GRO的核心检查逻辑 (简化)
bool gro_can_merge(const struct sk_buff *skb, const struct sk_buff *prev)
{
// 1. 检查MAC头部必须完全匹配
if (!compare_mac_headers(skb, prev))
return false;
// 2. 检查IP头部:只有TTL、TOS等有限字段可以不同
if (!compare_ip_headers(skb, prev))
return false;
// 3. 对于TCP:序列号必须连续,时间戳必须匹配
if (is_tcp_packet(skb)) {
if (!compare_tcp_headers(skb, prev))
return false;
if (tcp_timestamp_mismatch(skb, prev))
return false;
}
// 4. 其他协议特定的检查...
return true;
}
GRO与LRO的关键区别:
- 合并位置: GRO在内核网络协议栈的通用层实现,而不只是在驱动中。
- 合并粒度: GRO可以针对不同协议 (TCP、UDP、甚至其他协议) 实现特定的合并逻辑。
- 安全性: GRO有更严格的检查,避免错误合并。
- 灵活性: GRO可以根据系统配置动态调整合并策略。
3.3 GRO与LRO的对比
表:LRO与GRO对比
| 特性 |
LRO |
GRO |
| 实现位置 |
主要在驱动或硬件 |
Linux内核通用层 |
| 合并条件 |
相对宽松,可能出错 |
严格检查,更安全 |
| 协议支持 |
主要是TCP |
TCP、UDP等多种协议 |
| 与IP转发兼容性 |
通常不兼容 |
完全兼容 |
| 可配置性 |
有限 |
高度可配置 |
在现代Linux系统中,GRO已经基本取代了LRO。除非有特殊需求,否则建议使用GRO而不是LRO。
4. 硬件卸载的软件架构
4.1 Linux网络协议栈与卸载集成
要理解硬件卸载如何在Linux中工作,我们需要先了解Linux网络协议栈的基本架构,以及卸载技术如何集成到这一架构中。
Linux网络协议栈是一个复杂的分层系统,从应用程序到物理网卡,数据包需要经过多个处理层。硬件卸载技术通过在每个层次提供“快捷路径”来优化这一流程。
下面的图展示了Linux网络协议栈与硬件卸载的集成架构:
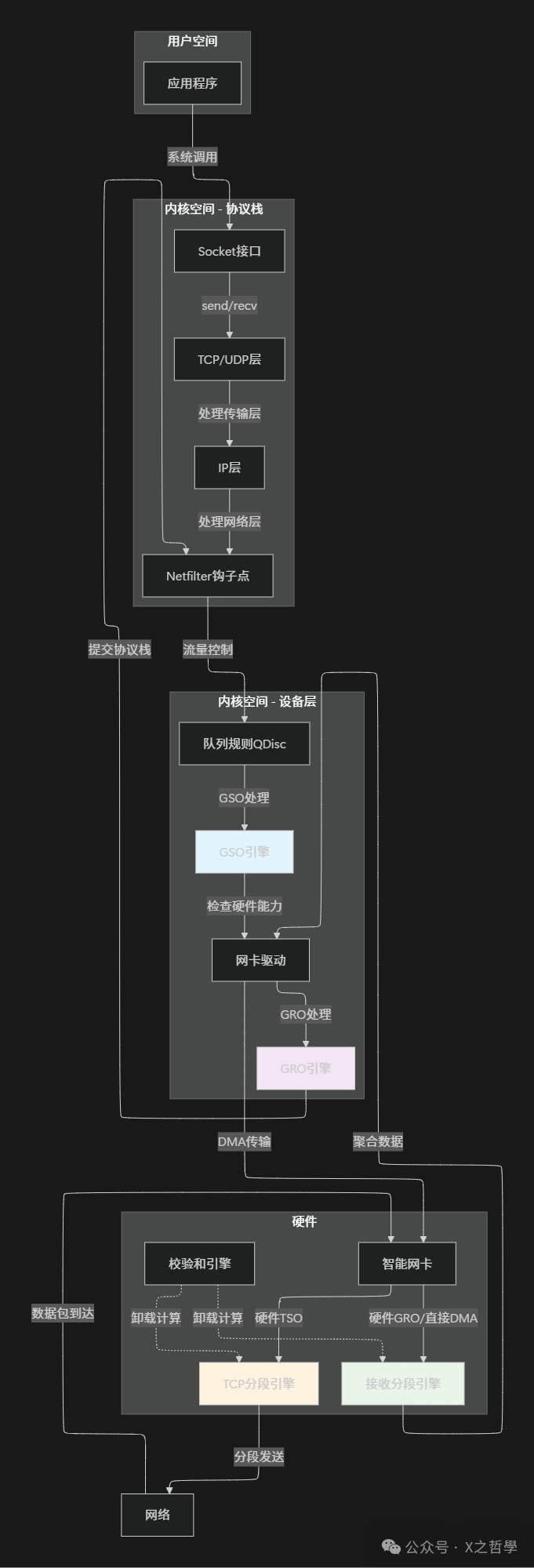
图2:Linux网络协议栈与硬件卸载集成架构示意
4.2 核心数据结构
硬件卸载在Linux内核中的实现依赖于几个关键数据结构。了解这些结构有助于深入理解卸载技术的工作原理。
sk_buff (套接字缓冲区)
这是Linux网络子系统中最核心的数据结构,代表一个网络数据包:
// sk_buff的简化版本,突出卸载相关字段
struct sk_buff {
// 数据包头部指针
unsigned char *head; // 头部开始
unsigned char *data; // 数据开始
unsigned char *tail; // 数据结束
unsigned char *end; // 缓冲区结束
// 长度信息
unsigned int len; // 数据长度
unsigned int data_len; // 分片数据长度
unsigned int truesize; // 实际缓冲区大小
// 卸载相关标志
__u16 gso_size; // GSO分段大小 (MSS)
__u16 gso_segs; // 分段数量
__u16 gso_type; // GSO类型 (TSO、UFO等)
// 校验和相关信息
__wsum csum; // 校验和
__u16 csum_start; // 校验和起始偏移
__u16 csum_offset; // 校验和存储偏移
// 协议信息
__be16 protocol; // 协议类型
__u8 ip_summed:2; // IP校验和状态
// 设备信息
struct net_device *dev; // 相关网络设备
// 链接信息
struct sk_buff *next;
struct sk_buff *prev;
};
net_device (网络设备)
代表一个网络接口,包含设备的卸载能力信息:
// net_device的卸载相关字段 (简化)
struct net_device {
// 设备名称
char name[IFNAMSIZ];
// 卸载能力标志
unsigned long features; // 设备支持的特性
#define NETIF_F_TSO (1UL << 7) // 支持TSO
#define NETIF_F_GSO (1UL << 15) // 支持GSO
#define NETIF_F_GRO (1UL << 19) // 支持GRO
#define NETIF_F_LRO (1UL << 21) // 支持LRO
#define NETIF_F_HW_CSUM (1UL << 1) // 支持硬件校验和
// 设备操作
const struct net_device_ops *netdev_ops;
// 统计信息
struct net_device_stats stats;
};
netdev_features_t (网络设备特性)
这是一个位图类型,表示设备支持的卸载特性:
typedef u64 netdev_features_t;
// 常见的卸载特性标志
enum {
NETIF_F_SG_BIT, // 分散/聚集IO
NETIF_F_IP_CSUM_BIT, // IPv4校验和
NETIF_F_TSO_BIT, // TCP分段卸载
NETIF_F_GSO_BIT, // 通用分段卸载
NETIF_F_GRO_BIT, // 通用接收卸载
NETIF_F_LRO_BIT, // 大量接收卸载
// ... 更多标志
};
4.3 卸载决策流程
当数据包通过网络协议栈时,系统需要决定是否以及如何使用卸载技术。这个决策流程是动态的,基于多种因素:
// 简化的卸载决策流程
static int decide_offload_strategy(struct sk_buff *skb,
struct net_device *dev)
{
// 检查设备能力
if (!(dev->features & NETIF_F_GSO)) {
// 设备不支持GSO,禁用所有分段卸载
skb->gso_type = 0;
return NO_OFFLOAD;
}
// 检查数据包类型和大小
if (skb->len <= dev->mtu) {
// 数据包小于MTU,不需要分段
return NO_SEGMENTATION_NEEDED;
}
// 检查协议类型
if (skb->protocol == htons(ETH_P_IP)) {
if (ip_hdr(skb)->protocol == IPPROTO_TCP) {
// TCP over IPv4
if (dev->features & NETIF_F_TSO) {
// 设备支持TSO,使用硬件分段
skb->gso_type = SKB_GSO_TCPV4;
skb->gso_size = dev->gso_max_size;
return HARDWARE_TSO;
} else {
// 设备不支持TSO,使用GSO软件分段
skb->gso_type = SKB_GSO_TCPV4;
skb->gso_size = dev->gso_max_size;
return SOFTWARE_GSO;
}
}
// 其他协议处理...
}
// 默认:无卸载
return NO_OFFLOAD;
}
5. 现代智能网卡与高级卸载
5.1 从基础网卡到智能网卡
现代数据中心网络的发展推动了网卡技术的革命。传统的简单网卡只能执行最基本的数据传输任务,而智能网卡 (SmartNIC) 集成了强大的处理能力,可以执行复杂的网络和存储协议处理。
智能网卡通常包含:
- 多核处理器: 专用网络处理器或通用ARM核心。
- 大容量内存: 用于缓存数据包和连接状态。
- 可编程流水线: 硬件加速的数据包处理流水线。
- 多种卸载引擎: TSO、GRO、加密、压缩等。
5.2 RDMA与完全卸载
远程直接内存访问 (RDMA) 代表了网络卸载技术的终极形态。在RDMA模型中,数据直接从应用程序内存传输到远程应用程序内存,完全绕过操作系统内核和CPU。
RDMA的关键特点:
- 零拷贝: 数据不需要在内核和用户空间之间复制。
- 内核旁路: 数据传输不需要内核参与。
- CPU卸载: 远程内存访问由网卡硬件完成。
// RDMA操作的概念示例 (非真实API)
// 发送方
void rdma_send(struct rdma_context *ctx, void *data, size_t len)
{
// 1. 注册内存区域 (一次性的)
struct rdma_mr *mr = rdma_reg_mr(ctx, data, len);
// 2. 发布发送工作请求
struct ibv_send_wr wr = {
.opcode = IBV_WR_RDMA_WRITE,
.wr.rdma.remote_addr = remote_addr,
.wr.rdma.rkey = remote_key,
.sg_list = {{
.addr = (uintptr_t)data,
.length = len,
.lkey = mr->lkey,
}},
.num_sge = 1,
};
// 3. 提交请求后立即返回,传输由硬件完成
ibv_post_send(ctx->qp, &wr, NULL);
// CPU可以继续其他工作,不需要等待传输完成
}
// 接收方甚至不需要明确接收操作
// 数据直接出现在应用程序内存中
5.3 eBPF与可编程数据路径
现代智能网卡的另一个趋势是支持可编程数据路径。通过eBPF (扩展的伯克利包过滤器) 等技术,用户可以在网卡上运行自定义的数据包处理程序。
// 网卡eBPF程序的简化概念
SEC("xdp")
int xdp_offload_program(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// 解析数据包
struct ethhdr *eth = data;
if (eth + 1 > data_end)
return XDP_DROP;
// 检查是否为TCP流量
if (eth->h_proto == htons(ETH_P_IP)) {
struct iphdr *ip = data + sizeof(*eth);
if (ip + 1 > data_end)
return XDP_DROP;
if (ip->protocol == IPPROTO_TCP) {
// TCP流量,执行智能卸载决策
return handle_tcp_offload(ctx, ip);
}
}
// 其他协议,正常处理
return XDP_PASS;
}
eBPF卸载的优势:
- 灵活性: 可以根据实际需求定制卸载逻辑。
- 安全性: 在受限虚拟机中运行,不会破坏系统。
- 高性能: 在网卡上直接处理,延迟极低。
6. 配置、监控与调试
6.1 配置卸载功能
在Linux系统中,可以使用 ethtool 工具查看和配置网卡的卸载功能。
查看当前卸载设置:
# 查看所有卸载功能状态
ethtool -k eth0
# 查看特定功能
ethtool --show-offload eth0
# 示例输出:
# Features for eth0:
# rx-checksumming: on
# tx-checksumming: on
# scatter-gather: on
# tcp-segmentation-offload: on
# tx-tcp-segmentation: on
# generic-segmentation-offload: on
# generic-receive-offload: on
# large-receive-offload: off [fixed]
修改卸载设置:
# 启用GRO
ethtool -K eth0 gro on
# 禁用TSO
ethtool -K eth0 tso off
# 同时启用多个功能
ethtool -K eth0 gro on gso on tso on
# 注意:某些功能可能标记为[fixed],表示不可更改
6.2 监控卸载效果
了解卸载功能是否真正发挥作用很重要。Linux提供了多种监控工具:
使用 /proc 文件系统:
# 查看网络统计
cat /proc/net/dev
# 查看软中断统计,网络软中断是NET_RX和NET_TX
cat /proc/softirqs
# 查看详细的协议统计
cat /proc/net/snmp
使用专用监控工具:
# 使用nstat查看网络统计
nstat -a
# 使用dropwatch监控丢包
dropwatch -l kas
# 使用ethtool查看详细统计
ethtool -S eth0
6.3 调试常见问题
卸载功能虽然能提升性能,但有时也会导致问题。以下是一些常见问题及调试方法:
问题1:性能不升反降
问题2:校验和错误
问题3:高延迟
问题4:虚拟化环境中的卸载问题
6.4 性能调优建议
根据不同的应用场景,卸载功能的优化配置也不同:
表:不同场景下的卸载配置建议
| 应用场景 |
推荐配置 |
调优说明 |
| 大数据传输 |
TSO:ON, GSO:ON, GRO:ON |
最大化吞吐量,减少CPU使用 |
| 低延迟交易 |
TSO:OFF, GSO:OFF, GRO:OFF |
减少排队延迟,快速处理小包 |
| 虚拟化环境 |
TSO:ON(宿主机), TSO:OFF(虚拟机) |
避免双重分段,提高效率 |
| 网络设备 (路由器) |
GSO:ON, GRO:ON, TSO:OFF |
优化转发性能,减少处理开销 |
| 高并发Web服务 |
GRO:ON, GSO:ON, TSO:视情况 |
平衡连接处理与数据传输 |
7. 实战案例:实现简单的硬件卸载感知应用
7.1 检测系统卸载能力
在开发网络应用时,了解运行环境的卸载能力可以帮助优化应用程序行为:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ioctl.h>
#include <net/if.h>
#include <linux/ethtool.h>
#include <linux/sockios.h>
int check_offload_capability(const char *ifname) {
int fd;
struct ifreq ifr;
struct ethtool_value eval;
// 创建套接字
fd = socket(AF_INET, SOCK_DGRAM, 0);
if (fd < 0) {
perror("socket");
return -1;
}
// 准备ifreq结构
memset(&ifr, 0, sizeof(ifr));
strncpy(ifr.ifr_name, ifname, IFNAMSIZ - 1);
// 检查TSO能力
eval.cmd = ETHTOOL_GET_TSO;
ifr.ifr_data = (caddr_t)&eval;
if (ioctl(fd, SIOCETHTOOL, &ifr) == 0) {
printf("TSO capability: %s\n", eval.data ? "Enabled" : "Disabled");
}
// 检查GSO能力
eval.cmd = ETHTOOL_GET_GSO;
ifr.ifr_data = (caddr_t)&eval;
if (ioctl(fd, SIOCETHTOOL, &ifr) == 0) {
printf("GSO capability: %s\n", eval.data ? "Enabled" : "Disabled");
}
// 检查GRO能力
eval.cmd = ETHTOOL_GET_GRO;
ifr.ifr_data = (caddr_t)&eval;
if (ioctl(fd, SIOCETHTOOL, &ifr) == 0) {
printf("GRO capability: %s\n", eval.data ? "Enabled" : "Disabled");
}
close(fd);
return 0;
}
int main() {
printf("Checking system offload capabilities:\n");
check_offload_capability("eth0");
return 0;
}
7.2 优化应用发送缓冲区
基于系统卸载能力优化应用程序发送策略:
// 根据系统卸载能力优化发送缓冲区大小
size_t get_optimal_send_size(const char *ifname) {
size_t default_mss = 1460; // 标准MSS
// 检测TSO/GSO能力
if (check_tso_capability(ifname)) {
// 系统支持TSO,可以使用大缓冲区
return 65536; // 64KB,最大TSO大小
} else if (check_gso_capability(ifname)) {
// 系统支持GSO,可以使用较大缓冲区
return 32768; // 32KB
} else {
// 无卸载支持,使用标准MSS
return default_mss;
}
}
// 优化发送循环
void optimized_send(int sockfd, const void *data, size_t total_len) {
size_t optimal_size = get_optimal_send_size("eth0");
size_t sent = 0;
while (sent < total_len) {
size_t to_send = total_len - sent;
if (to_send > optimal_size) {
to_send = optimal_size;
}
ssize_t n = send(sockfd, (char*)data + sent, to_send, 0);
if (n < 0) {
// 错误处理
break;
}
sent += n;
}
}
7.3 监控卸载统计信息
实时监控卸载统计,动态调整应用行为:
// 监控卸载统计的简单实现
struct offload_stats {
unsigned long tso_segments;
unsigned long gso_segments;
unsigned long gro_merged;
unsigned long tx_packets;
unsigned long rx_packets;
};
void monitor_offload_stats(const char *ifname,
struct offload_stats *stats) {
FILE *fp;
char path[256];
char line[512];
// 读取网络设备统计
snprintf(path, sizeof(path),
"/sys/class/net/%s/statistics/", ifname);
// 读取TX数据包统计 (简化示例)
snprintf(path, sizeof(path),
"/sys/class/net/%s/statistics/tx_packets", ifname);
fp = fopen(path, "r");
if (fp) {
fgets(line, sizeof(line), fp);
stats->tx_packets = atol(line);
fclose(fp);
}
// 在实际实现中,可以读取更多统计信息
// 如:/sys/class/net/eth0/queues/tx-0/byte_queue_limits/
}
8. 未来展望与趋势
8.1 卸载技术的演进方向
网络卸载技术仍在快速发展,主要趋势包括:
- 更智能的卸载决策 - 基于机器学习预测流量模式,动态调整卸载策略。
- 协议无关的卸载 - 开发更通用的卸载框架,支持各种现有和未来协议。
- 安全与卸载的融合 - 将加密、认证等安全功能集成到卸载引擎中。
- 跨层优化 - 联合优化网络、存储和应用层的卸载策略。
8.2 DPU与基础设施处理单元
数据处理单元 (DPU) 代表了卸载技术的集大成者。DPU不仅仅是智能网卡,更是完整的基础设施处理单元,可以卸载网络、存储、安全、虚拟化等多种功能。
DPU的关键特性:
- 强大的多核处理器: 通常包含数十个ARM或专用核心。
- 丰富的硬件加速器: 加解密、压缩、正则表达式匹配等。
- 灵活的可编程性: 支持P4、eBPF、专用ISA等多种编程模型。
- 高速互连: PCIe Gen4/5、CXL等新一代互连技术。
8.3 云原生与卸载
在云原生环境中,卸载技术面临新的挑战和机遇:
- 微服务间通信优化 - 针对微服务间的大量小包通信优化卸载策略。
- 服务网格集成 - 将服务网格代理 (如Envoy) 卸载到智能网卡。
- 多租户隔离 - 在硬件层面确保不同租户的卸载资源隔离。
- 弹性卸载 - 根据负载动态调整卸载程度,平衡性能与能耗。
结论:卸载技术的本质与价值
通过本文的深入分析,我们可以看到Linux分段/聚合与硬件卸载技术背后的核心设计思想:将通用任务从通用处理器转移到专用硬件,实现性能与效率的平衡。
从TSO到GSO,从LRO到GRO,从智能网卡到DPU,网络卸载技术的发展历程体现了计算机系统设计的经典智慧:
- 推迟决策: 像GSO一样,尽可能推迟分段决策,保持灵活性。
- 分层抽象: 像GRO一样,创建通用层隔离硬件差异。
- 专用化加速: 像TSO一样,为常见任务设计专用硬件。
- 软硬协同: 像现代智能网卡一样,软件与硬件紧密协作。
理解这些底层机制,不仅有助于我们优化系统性能,更能启发我们在设计复杂分布式系统时的架构思考。探索这些前沿技术,并加入 云栈社区 与更多开发者交流,是持续提升技术视野的有效途径。
 发表于 2025-12-31 05:41:54
|
查看: 297|
回复: 0
发表于 2025-12-31 05:41:54
|
查看: 297|
回复: 0
