你是否正在面临以下困境?
- 业务决策受制于T+1延迟的数仓数据?
- 维护包含Kafka、Flink、ClickHouse的复杂数据链路让你头疼不已?
- 希望找到一套简洁的架构,能够实现MySQL数据变更的秒级分析?
本文将提供一个明确的解决方案。我们将手把手指导你,使用Apache Paimon 0.8与StarRocks 4.0这一经过生产验证的最新组合,通过五个核心步骤,搭建端到端延迟小于1秒的实时数仓。这套方案能够省去中间消息队列,预计可降低50%的运维复杂度。
一、传统痛点与Paimon+StarRocks的解法
下表清晰地对比了传统方案的痛点与新架构的优势:
| 传统痛点 |
Paimon + StarRocks 解法 |
| T+1 数据延迟 |
基于CDC实时入湖,实现秒级数据可见性 |
| 数据处理链路过长 |
简化为 Flink → Paimon → StarRocks 直连,无需Kafka |
| 更新(UPDATE/DELETE)难处理 |
Paimon自动合并变更日志(Changelog),支持基于主键的Upsert |
这套方案的核心价值在于:用最简洁的架构,实现最强的实时数据处理能力。
二、为什么选择 Paimon 0.8 + StarRocks 4.0?
截至2025年,Paimon与StarRocks的组合已成为构建实时湖仓一体平台的事实标准。
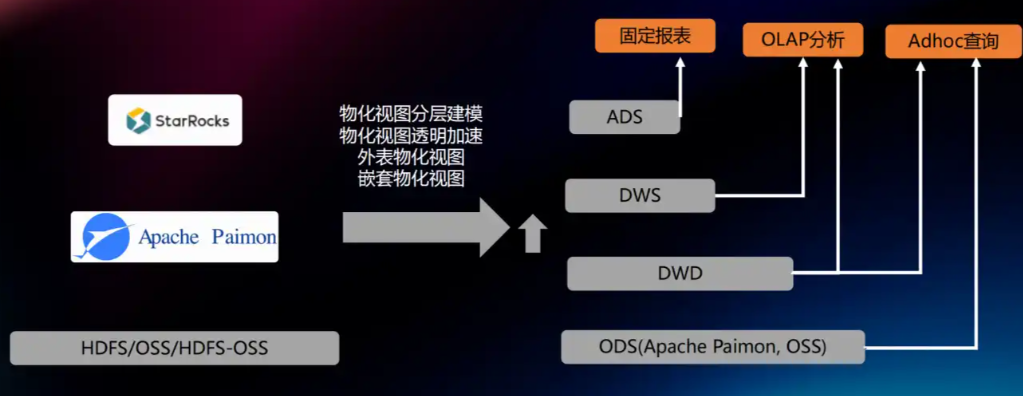
- Apache Paimon 0.8:原生支持CDC数据合并,可自动处理来自上游的INSERT、UPDATE、DELETE事件。
- StarRocks 4.0:通过原生External Catalog功能直接查询Paimon数据湖,查询性能相比之前版本有显著提升。
- 架构极简:Flink可以直接将数据写入Paimon,无需引入Kafka等中间件,极大降低了系统的运维成本。
三、实战:5步搭建实时数据管道
环境准备
需要提前部署以下组件:
- MySQL 8.0+(业务表必须有主键)
- Flink 1.18+
- Apache Paimon 0.8
- StarRocks 4.0
步骤 1:在MySQL中开启Binlog并创建用户
首先,确保MySQL配置文件中已启用Binlog,并设置为ROW模式。
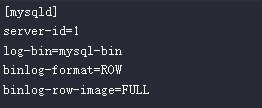
随后,创建一个专用于Flink CDC连接的用户,并授予必要的权限。
CREATE USER 'flinkuser'@'%' IDENTIFIED BY 'password';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flinkuser';
关键点:业务源表必须拥有唯一主键,否则Paimon将无法正确合并数据变更。
步骤 2:使用Flink SQL创建CDC源表与Paimon目标表
在Flink SQL中,首先创建指向MySQL的CDC源表。
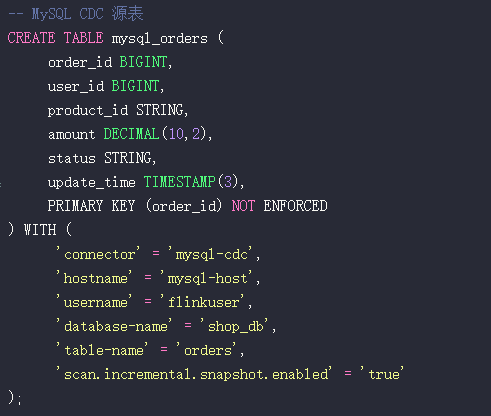
-- MySQL CDC 源表
CREATE TABLE mysql_orders (
order_id BIGINT,
user_id BIGINT,
product_id STRING,
amount DECIMAL(10,2),
status STRING,
update_time TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql-host',
'username' = 'flinkuser',
'database-name' = 'shop_db',
'table-name' = 'orders',
'scan.incremental.snapshot.enabled' = 'true'
);
接着,创建Paimon Catalog和目标表。目标表需配置merge-engine为deduplicate以支持数据更新。
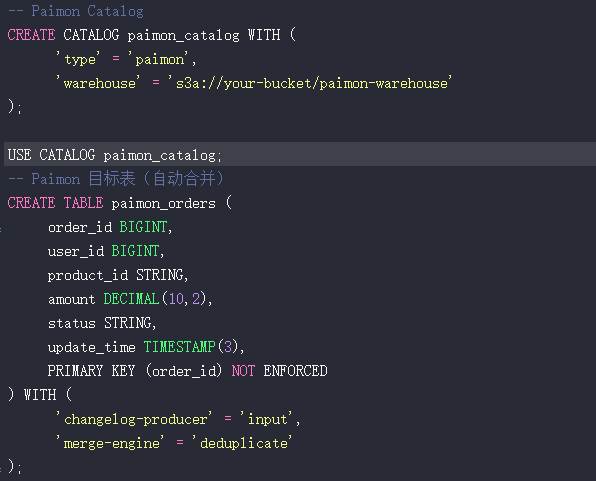
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 's3a://your-bucket/paimon-warehouse'
);
USE CATALOG paimon_catalog;
-- Paimon 目标表(自动合并)
CREATE TABLE paimon_orders (
order_id BIGINT,
user_id BIGINT,
product_id STRING,
amount DECIMAL(10,2),
status STRING,
update_time TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'changelog-producer' = 'input',
'merge-engine' = 'deduplicate'
);
步骤 3:启动Flink同步作业
通过一个INSERT INTO语句启动实时同步任务。

INSERT INTO paimon_orders SELECT * FROM mysql_orders;
此后,MySQL中发生的任何数据插入、更新或删除,都将在Paimon表中自动合并,最终只保留每条记录的最新状态。
步骤 4:在StarRocks中创建外部目录并直连查询
在StarRocks中,创建一个指向Paimon数据湖的外部目录(External Catalog)。

-- 创建 External Catalog
CREATE EXTERNAL CATALOG paimon_ext
PROPERTIES (
"type" = "paimon",
"paimon.warehouse" = "s3a://your-bucket/paimon-warehouse"
);
-- 秒级查询
SELECT product_id, SUM(amount) AS gmv
FROM paimon_ext.default.paimon_orders
WHERE status = 'paid'
GROUP BY product_id
ORDER BY gmv DESC
LIMIT 10;
实测延迟:在优化环境(SSD存储、千兆网络、Flink Checkpoint间隔≤10秒)下,从MySQL变更到StarRocks可查询的端到端延迟可控制在1秒以内。
步骤 5:接入BI工具与数据大屏
- StarRocks完全兼容MySQL协议。
- 主流BI工具如Superset、QuickBI等可直接连接,无需改造。只需将仪表板刷新频率设置为5-10秒,即可实现准实时的数据可视化。
四、深度优化与关键避坑指南
性能调优建议
- Paimon写入优化:调整
'write-buffer-size' = '512MB',提升写入吞吐。
- 小文件治理:定期执行
CALL sys.compact('default', 'paimon_orders')命令合并小文件,避免查询性能下降。
- 排序键:根据高频查询条件(如
product_id)为Paimon表设置排序键,可大幅提升StarRocks查询时的谓词下推效率。
关键问题与解决方案
| 问题 |
解决方案 |
| 源表无主键 |
必须为表添加逻辑主键,否则CDC合并机制将失效。 |
| StarRocks查询Paimon表速度慢 |
检查S3/HDFS客户端版本,并在StarRocks中启用Manifest缓存。 |
| 查询结果时区不一致 |
确保Flink作业与StarRocks集群的时区设置统一(如'Asia/Shanghai')。 |
重要限制:在StarRocks 4.0中,对Paimon外部表不支持创建倒排索引或物化视图。若需极致查询性能,可考虑将Paimon数据异步导入StarRocks内部表后再进行加速。
五、生产环境实测价值(某电商案例)
- 数据规模:日均处理订单变更约2亿条。
- 处理能力:Paimon实时写入吞吐达12万条/秒。
- 查询性能:基于百亿级数据,StarRocks的查询P99延迟小于1.2秒。
- 运维收益:相比旧架构,运维人力成本降低50%以上。
六、未来展望
- Native Reader:未来StarRocks有望推出原生Paimon Reader,绕过JNI调用,预计读取性能可再提升30%。
- 向量化分析:结合Paimon存储Embedding向量,通过StarRocks实现实时的推荐与相似度计算。
- Serverless化:向按查询付费的Serverless实时数仓演进,彻底简化资源规划与管理。
希望这篇结合了最新技术栈的实践指南能为你构建实时数据平台提供清晰的路径。更多关于数据架构、数据库和前沿技术的深度讨论,欢迎关注云栈社区的技术分享。
 发表于 2026-1-3 02:37:07
|
查看: 267|
回复: 0
发表于 2026-1-3 02:37:07
|
查看: 267|
回复: 0
