上一节我们粗略梳理了系统调用从用户态到内核态的流程及其关键概念。本节我们将深入剖析 glibc 内部如何封装系统调用,并回答几个核心问题。
- glibc 是如何实现多平台兼容的?
- glibc 内部系统调用的封装逻辑是怎样的?
- 如果不依赖 glibc 的接口,我们能否直接触发系统调用?
1. glibc 如何实现平台兼容?
系统调用通过特定的异常指令使 CPU 从用户态陷入内核态,但不同处理器架构的指令各不相同。例如,ARM64 使用 svc #0 指令,而 x86-64 则使用 syscall 指令。
那么,作为一套全平台兼容的 C 库,glibc 是如何处理这些差异的呢?
关键在于,glibc 并非在运行时通过大量 #ifdef 进行判断,而是在编译时就完成了平台适配。其核心机制依赖于一个名为 sysdeps 的目录,所有与架构相关的文件都存放在这里。通过 configure 脚本和 Makefile,在编译时选择对应的架构文件,最终生成目标平台的可执行库。
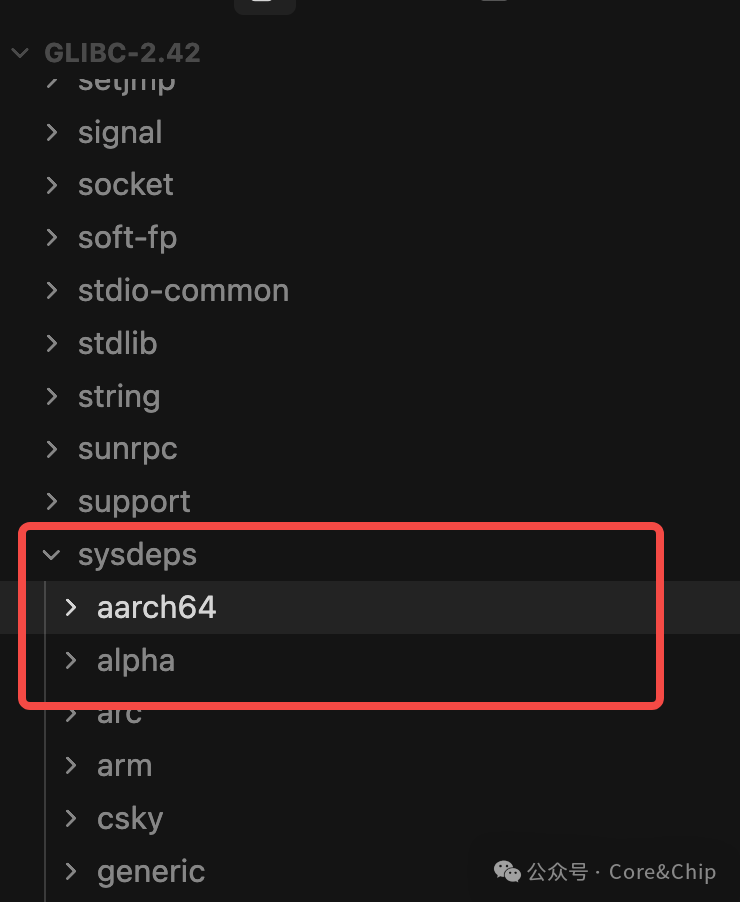
当我们交叉编译 glibc 时,通常会使用类似如下的命令:
./glibc-2.42/configure --host=aarch64-linux-gnu --build=x86_64-linux-gnu
configure 脚本会根据 --host 参数、编译器信息等计算出目标的规范三元组(如 aarch64-linux-gnu),并结合 sysdeps/ 目录下的 Implies 文件,生成一个有序的 sysdeps 目录链,并写入 config.make 文件。
顶层的 Makeconfig 会将此目录链转换为具体的搜索路径,例如:
+sysdep_dirs = glibc-2.42/sysdeps/unix/sysv/linux/aarch64 \
glibc-2.42/sysdeps/unix/sysv/linux \
glibc-2.42/sysdeps/unix \
glibc-2.42/sysdeps/aarch64 \
glibc-2.42/sysdeps/wordsize-64 \
glibc-2.42/sysdeps/generic
当 make 需要某个源文件(如 xxx.c 或 xxx.S)而当前目录不存在时,便会按照上述目录顺序依次查找,并使用第一个找到的文件。这种机制意味着:
- 如果
aarch64 架构在 sysdeps/unix/sysv/linux/aarch64/ 下有自己专用的 sysdep.h 或 syscall.S 实现,它将屏蔽掉更通用的版本。
- 如果某个架构没有实现特定文件,则会回退到上一级通用目录中的实现,直至
sysdeps/generic。
总结来说,glibc 通过 configure 脚本、sysdeps 目录分层机制以及 make 的搜索规则,在编译期实现了优雅的多平台兼容。了解这一整体框架后,我们进入更核心的实现部分。
2. glibc 内部系统调用封装详解
以 write 系统调用为例,其在 glibc 内部的调用链大致如下:
write(fd, buf, nbytes)
→ __libc_write()
→ SYSCALL_CANCEL(write, fd, buf, nbytes)
→ __SYSCALL_CANCEL_DISP
→ __syscall_cancel(..., __NR_write)
→ INTERNAL_SYSCALL(write, 3, fd, buf, nbytes)
→ INTERNAL_SYSCALL_RAW(__NR_write, 3, ...)
→ inline asm: svc 0
Linux 系统调用的参数个数可变,最多支持 6 个参数。为了用 C 语言统一上层调用接口,glibc 定义了一组宏来适配不同参数数量的情况:
__SYSCALL_CANCEL0(name):0 个参数,如 getpid()__SYSCALL_CANCEL1(name, a1):1 个参数,如 close(fd)__SYSCALL_CANCEL2(name, a1, a2)- …
__SYSCALL_CANCEL6(name, a1, ..., a6)__SYSCALL_CANCEL7(...):为特殊用途保留,极少使用
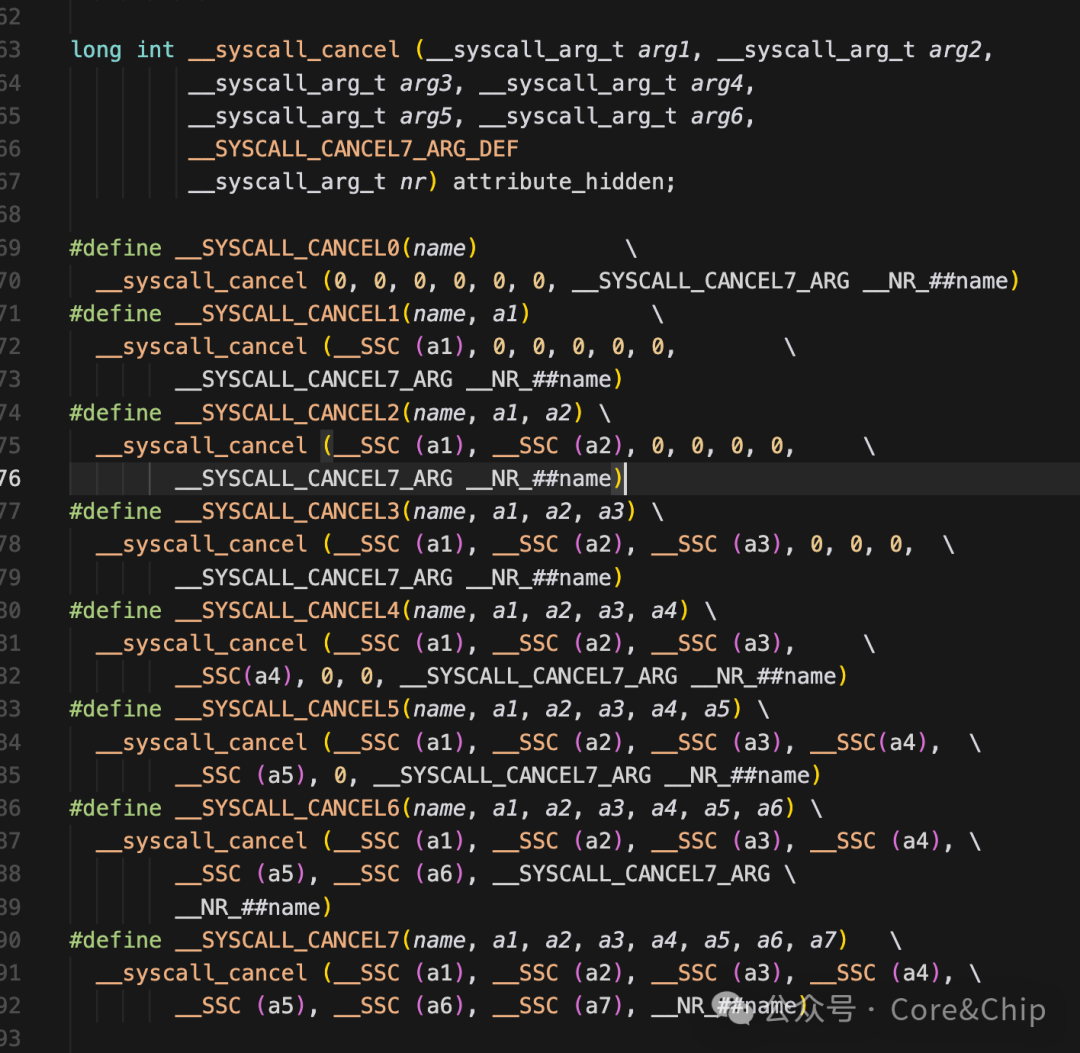
在上层,还有一个关键的分发宏 __SYSCALL_CANCEL_DISP,它根据 SYSCALL_CANCEL 宏传入的参数个数,自动选择正确的底层宏模板(__SYSCALL_CANCEL0 ~ __SYSCALL_CANCEL6)。这使得开发者可以用 SYSCALL_CANCEL(name, args...) 这种统一的形式调用任意参数数量的系统调用,而无需关心底层细节。
在 __SYSCALL_CANCEL 宏中,通过 __NR_##name 的拼接,将函数名转换为对应的系统调用号。例如,write 在这里会被替换为 __NR_write。在 arch-syscall.h 头文件中,定义了 aarch64 架构下 write 的系统调用号为 64。
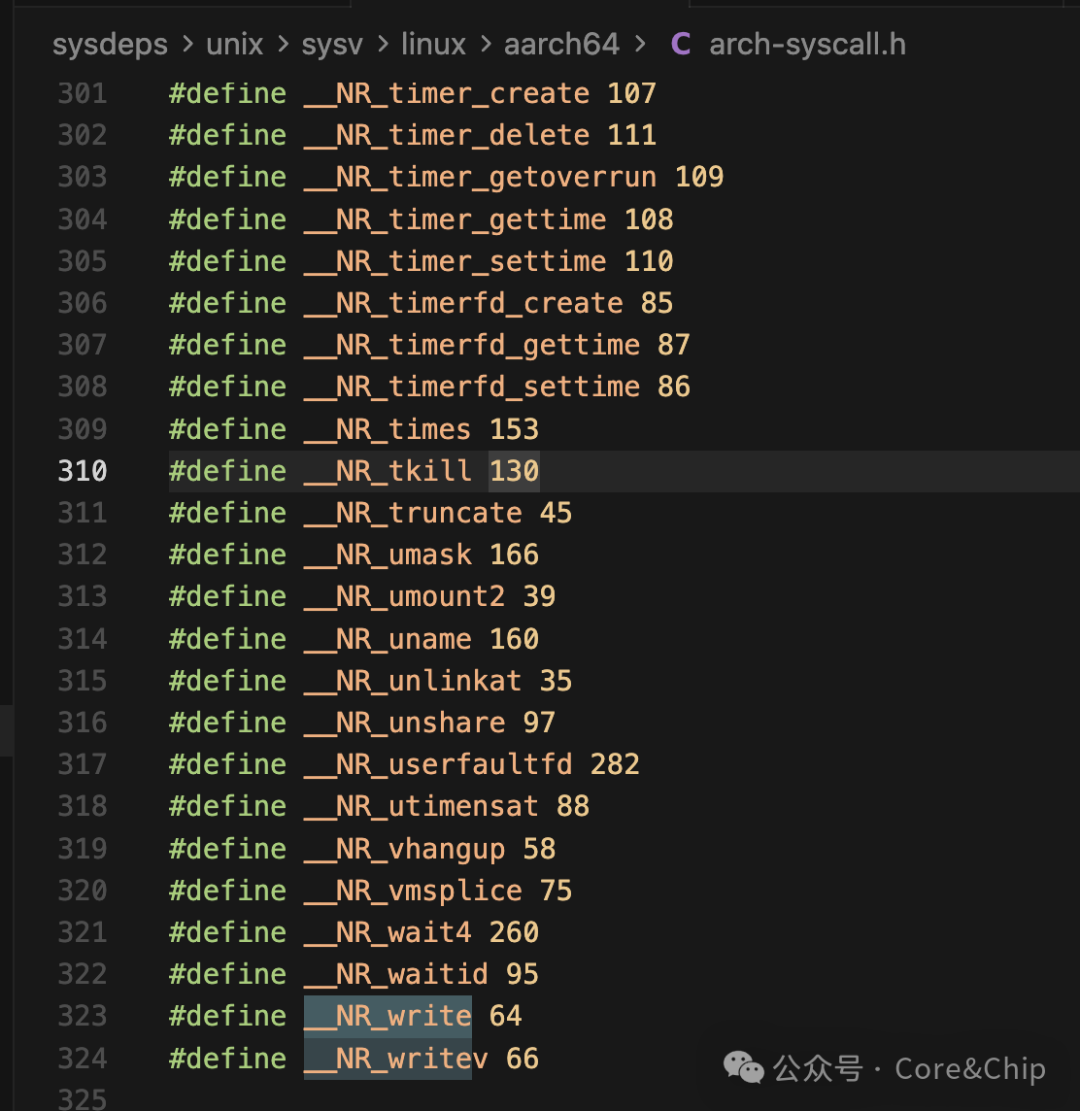
因此,对于 __SYSCALL_CANCEL3(write, ...),其最后一个展开参数就是 64(在 ARM64 上)。这个系统调用号会传递给 __syscall_cancel,进而传入 INTERNAL_SYSCALL,最终在汇编层被放入 x8 寄存器,并执行 svc 0 指令。
真正的汇编入口点(如 sysdeps/unix/sysv/linux/aarch64/syscall.S 中的 syscall)逻辑清晰:
/* syscall (int nr, ...)
AArch64 system calls take between 0 and 7 arguments. On entry here nr
is in w0 and any other system call arguments are in register x1..x7.
For kernel entry we need to move the system call nr to x8 then
load the remaining arguments to register. */
ENTRY (syscall)
uxtw x8, w0 // 系统调用号从 w0 移至 x8
mov x0, x1 // 参数1 -> x0
mov x1, x2 // 参数2 -> x1
mov x2, x3 // 参数3 -> x2
mov x3, x4 // 参数4 -> x3
mov x4, x5 // 参数5 -> x4
mov x5, x6 // 参数6 -> x5
mov x6, x7 // 参数7 -> x6
svc 0x0 // 触发系统调用
cmn x0, #4095 // 检查返回值是否表示错误
b.cs 1f
RET
1:
b SYSCALL_ERROR
其工作步骤非常直接:
- 将系统调用号从
w0 寄存器移动到 x8 寄存器(ARM64 架构约定)。
- 将传入的参数从
x1-x7 寄存器依次移动到 x0-x6 寄存器(Linux ARM64 ABI 约定系统调用参数使用 x0-x5)。
- 执行
svc 0 指令陷入内核。
以 write(fd, buf, count) 为例,调用 syscall(64, fd, buf, count) 时,寄存器初始状态为:w0=64, x1=fd, x2=buf, x3=count。经过上述汇编代码调整后,进入内核前的寄存器状态变为:x8=64, x0=fd, x1=buf, x2=count,完全符合 Linux 内核的调用约定。
3. 脱离glibc:手写汇编触发系统调用
理解了 glibc 对 write 的封装原理后,我们可以尝试抛开 glibc,直接使用汇编指令 svc 来实现一个简单的打印功能,以加深理解。
以下是一个完整的 ARM64 汇编程序,它直接通过系统调用向标准输出写入字符串,然后退出:
// syscall.s (ARM64)
// 使用系统调用实现类似printf的输出功能
.text
.global _start
.align 2
_start:
// 准备字符串地址 (Linux ARM64方式)
adrp x1, msg // 获取msg所在页的基地址
add x1, x1, :lo12:msg // 添加页内偏移
// 调用 write(fd=1, buf=msg, count=msg_len)
mov x0, #1 // fd = 1 (stdout)
mov x2, #msg_len // count = 字符串长度
mov x8, #64 // __NR_write = 64
svc #0 // 执行系统调用
// 调用 exit(0)
mov x0, #0 // status = 0
mov x8, #93 // __NR_exit = 93
svc #0 // 执行系统调用
.section .rodata
.align 2
msg:
.ascii "hello from corechip svc #0 syscall\n"
msg_len = . - msg
使用交叉编译工具链编译并运行该程序后,效果如下:

4. 总结
本节我们深入解析了 glibc 实现系统调用的内部机制,包括其通过 sysdeps 目录实现的编译时跨平台兼容策略,以及通过宏展开和汇编封装将用户态调用转换为 svc 指令的完整链条。最后,我们通过手写汇编程序验证了系统调用的本质。
理解这些底层细节,对于操作系统和计算机体系结构的深入学习至关重要。在云栈社区,你可以找到更多关于系统编程和底层开发的深度讨论与资源。下一节,我们将进入 Linux 内核,探究内核在接收到 svc 指令及参数后的一系列处理流程。
 发表于 2026-1-3 07:31:39
|
查看: 241|
回复: 0
发表于 2026-1-3 07:31:39
|
查看: 241|
回复: 0
