在两份表里找相同id的数据,很多同学的第一反应是写两个for循环嵌套。这个写法虽然直观,但在数据量稍大的场景下效率会比较低。今天我们就通过一个具体的案例,来看看如何对这种代码进行性能优化。
这个优化技巧其实比较常见,但在近期的几次代码评审中,我发现仍然有不少开发者会忽略它。所以,我觉得还是有必要拿出来详细说一说。
具体是什么场景呢?就是在 for 循环里面还有 for 循环,然后进行数据匹配和处理的场景。我们直接结合实例代码来看。
场景示例
假设我们现在拿到两个List数据:
- 一个是
User 的 List 集合。
- 另一个是
UserMemo 的 List 集合。
我们需要遍历 User List,然后根据每个用户的 userId,从 UserMemo List 里面取出对应的 content 值,并进行后续的数据处理。
以下是实体类的定义:
User.java
@Data
public class User {
private Long userId;
private String name;
}
UserMemo.java
@Data
public class UserMemo {
private Long userId;
private String content;
}
为了模拟真实场景,我们准备了两个测试数据集合:5万条 user 数据,3万条 userMemo 数据。
public static List<User> getUserTestList() {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 50000; i++) {
User user = new User();
user.setName(UUID.randomUUID().toString());
user.setUserId((long) i);
users.add(user);
}
return users;
}
public static List<UserMemo> getUserMemoTestList() {
List<UserMemo> userMemos = new ArrayList<>();
for (int i = 30000; i >= 1; i--) {
UserMemo userMemo = new UserMemo();
userMemo.setContent(UUID.randomUUID().toString());
userMemo.setUserId((long) i);
userMemos.add(userMemo);
}
return userMemos;
}
常见低效写法:双重循环
首先,我们看看在没注意性能时可能会写的代码:
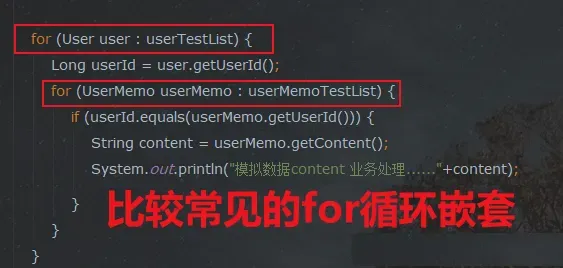
对应的代码逻辑如下:
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......" + content);
}
}
}
如果数据量很小,这种写法的性能差别确实不大。但我们仍然需要了解其中的性能瓶颈。让我们看看这种写法的耗时情况。
这相当于迭代了 5W * 3W = 15亿 次。运行后的耗时结果如下:

耗时高达 26857毫秒(约26.8秒)。
初级优化:适时使用 break
在继续深入之前,我们插入一个题外但有用的优化点。观察上面的代码,如果我们能确定每个 userId 在 UserMemo List 中只有一条对应数据,或者我们只需要找到第一个匹配项,那么在内层循环找到目标后,应该立即使用 break 跳出,避免无意义的后续遍历。
优化后的代码片段:
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......" + content);
break; // 找到后立即跳出内层循环
}
}
}
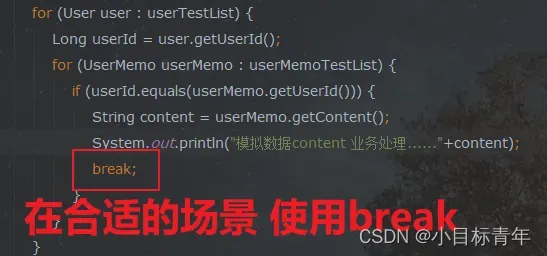
加上 break 之后,我们再来看耗时:
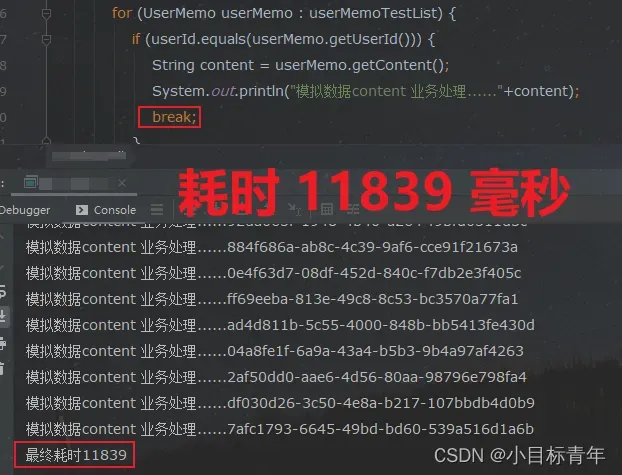
耗时从 2.6万毫秒 降到了 1.1万毫秒。这个简单的 break 带来的优化效果非常显著。
核心优化:利用 Map 数据结构
回到最初的问题,即便使用了 break,双重循环的耗时依然有1万多毫秒。如果场景更复杂,比如多层嵌套,那代码耗时将变得非常恐怖。
接下来的技巧是使用 Map(哈希表) 来进行优化,这是解决此类问题的核心思路。
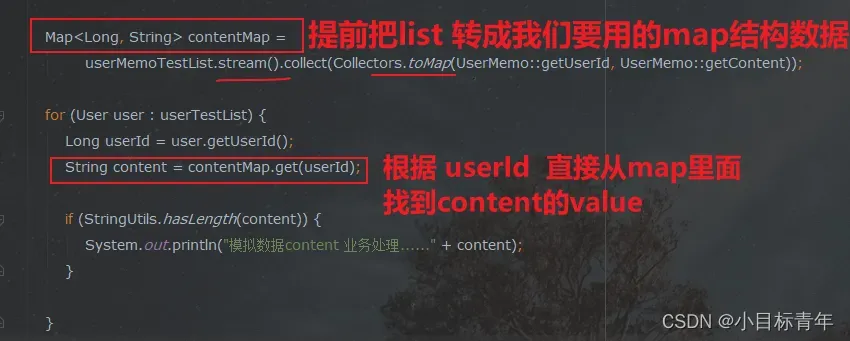
优化后的完整代码如下:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 关键步骤:提前将 List 转换为 Map。使用stream()时务必注意空指针,此处示例省略判空。
Map<Long, String> contentMap =
userMemoTestList.stream().collect(Collectors.toMap(UserMemo::getUserId, UserMemo::getContent));
for (User user : userTestList) {
Long userId = user.getUserId();
// 根据 userId 直接从 map 中获取,时间复杂度接近 O(1)
String content = contentMap.get(userId);
if (StringUtils.hasLength(content)) {
System.out.println("模拟数据content 业务处理......" + content);
}
}
stopWatch.stop();
System.out.println("最终耗时" + stopWatch.getTotalTimeMillis());
}
让我们看看使用 Map 优化后的耗时:
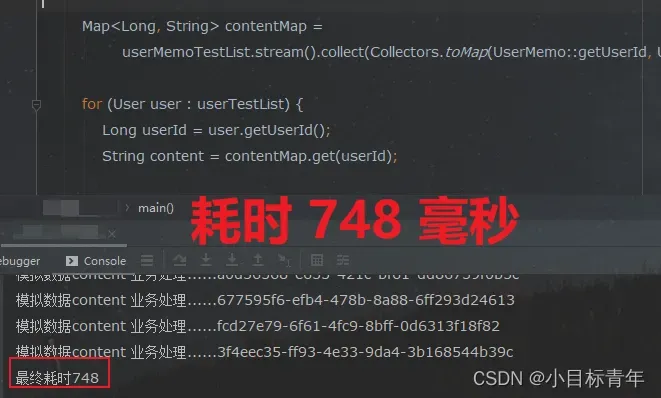
最终耗时仅为 748毫秒!相比最初的 26857 毫秒,性能提升了超过 35倍。
为什么效果如此显著?
这本质上是时间复杂度的优化。
- 双重
for 循环:其时间复杂度是 O(n * m)。就好比循环每一个 user,取出 userId 后,需要在内层循环中从 userMemo 列表里“开盲盒”式地顺序匹配,直到找到对应的项。当 n 和 m 都很大时,计算量呈乘积级增长。
Map (如 HashMap) 查询:其平均时间复杂度接近 O(1)。我们提前对 userMemo 列表进行一次遍历(O(m)),将其转换并存储到 Map 中。之后,每次根据 userId 查询时,HashMap 通过 hash(key) 计算能直接定位到数组的大致索引位置,从而快速获取值。

以 JDK 8 的 HashMap 实现为例,其采用了数组+链表/红黑树的结构。在良好的哈希函数下,发生哈希冲突的概率很低,绝大多数情况下都能实现接近常数的查询时间。即使在最坏情况下(所有 key 哈希冲突,退化为链表),时间复杂度也才是 O(n),但这在实际应用中极少见,通常无需考虑。
总结
面对需要在两个集合间进行数据匹配的场景,应避免直接使用嵌套循环。优先考虑使用 Map 数据结构来建立索引,将查找操作的时间复杂度从 O(n*m) 降为 O(m + n),这在数据量较大时能带来数量级的性能提升。
这是一个非常实用的Java性能优化技巧,其背后的核心思想——用空间换时间,利用高效的数据结构降低时间复杂度——在解决各类算法优化问题时都值得借鉴。希望这个案例能对你有所启发。欢迎在云栈社区分享你的性能优化实践与心得。
 发表于 2026-1-3 07:54:45
|
查看: 277|
回复: 0
发表于 2026-1-3 07:54:45
|
查看: 277|
回复: 0
