一、Pacemaker介绍
1.1. Pacemaker介绍
Pacemaker 是 Linux 环境中使用最为广泛的开源集群资源管理器。它本身并不提供心跳,而是利用集群基础架构 (Corosync 或者 Heartbeat) 提供的消息和集群成员管理功能,来实现节点和资源级别的故障检测与恢复,从而最大限度地保证集群服务的高可用性。
从逻辑功能上看,Pacemaker 在管理员定义的资源规则驱动下,负责管理集群中软件服务的全生命周期,甚至可以管理整个软件系统及它们之间的交互。
Pacemaker 能够管理任何规模的集群,其强大的资源依赖模型允许管理员精确描述资源之间的顺序、位置等关系。同时,对于几乎任何形式的软件资源,通过为其编写自定义的资源启动与管理脚本(资源代理),都可以作为资源对象被 Pacemaker 管理。
这里需要强调的是,Pacemaker 只是一个资源管理器,心跳检测功能主要由 Corosync 或 Heartbeat 来实现,许多初学者容易混淆这一点。
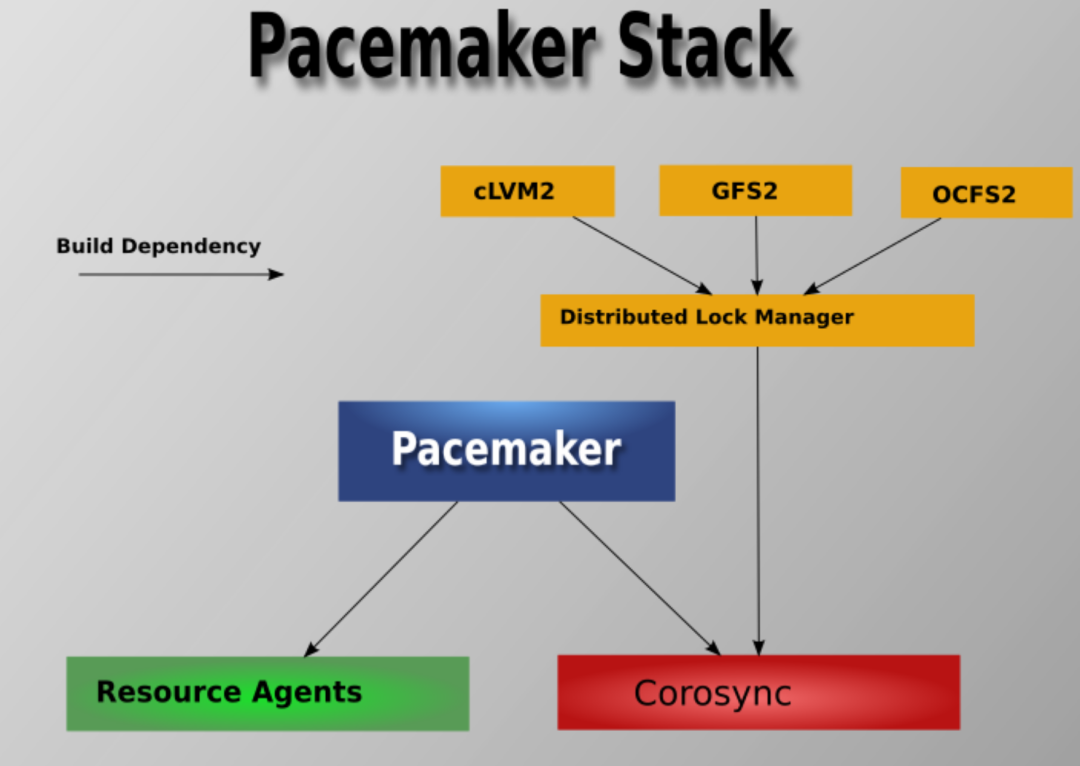
整体架构
在顶层,集群由三部分组成:
- 提供消息和集群成员管理功能的核心基础组件
- 与集群无关的组件
- 作为集群“大脑”的资源管理组件
下图清晰地展示了 Pacemaker 的架构层次与依赖关系:
1.2. 介质
| 软件 |
版本 |
| centos |
7.6 |
| python |
2.7.5 |
| pcs |
0.9.165 |
| PostgreSQL |
11.10 |
| pacemaker |
1.1.19 |
| corosync |
2.4.3 |
二、环境配置
2.1. 配置/etc/hosts
在3个节点(db1, db2, db3)上都执行:
su - root
vi /etc/hosts ,添加
192.168.0.31 db1
192.168.0.32 db2
192.168.0.33 db3
###vip###
192.168.0.28 vip-master
192.168.0.29 vip-slave
2.2. 关闭防火墙
在3个节点都执行:
su - root
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
2.3. 关闭selinux
在3个节点都执行:
su - root
修改配置文件,将 SELINUX 的值设置为 SELINUX=disabled:
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
此设置需要重启服务器才能生效。
2.4. 配置ntp
在3个节点都执行,安装 NTP 服务以同步时间:
su – root
yum -y install ntp
安装完成后,可以手动同步一次时间:
ntpdate ntp1.aliyun.com
三、安装集群相关软件包
3.1. 安装集群相关软件包
在3个节点都执行,安装 Pacemaker 高可用套件:
su - root
yum install -y pacemaker corosync pcs
安装 pacemaker 时,corosync 会被作为依赖一起安装。同时系统会自动创建 hacluster 操作系统用户。
3.2. 启动服务
在3个节点都执行,启动集群管理服务:
su - root
systemctl start pcsd
3.3. 设置服务开机自启
在3个节点都执行:
su - root
systemctl enable pcsd
systemctl enable corosync
systemctl enable pacemaker
systemctl is-enabled pcsd
systemctl is-enabled corosync
systemctl is-enabled pacemaker
四、启动集群
4.1. 设置hacluster用户密码
在3个节点都执行,为集群管理用户设置统一密码:
su - root
echo hacluster|passwd hacluster --stdin
4.2. 集群节点认证
在任何一个节点上执行,完成节点间的互信认证:
su - root
pcs cluster auth -u hacluster -p hacluster db1 db2 db3
4.3. 同步集群配置
在任何一个节点上执行,创建并同步集群配置:
su - root
pcs cluster setup --last_man_standing=1 --name pgcluster db1 db2 db3
4.4. 启动集群
在任何一个节点上执行,启动所有节点的集群服务:
su - root
pcs cluster start --all
五、部署PostgreSQL
5.1. 安装PostgreSQL依赖包
在3个节点都执行:
su - root
yum install -y readline readline-devel zlib zlib-devel gettext gettext-devel openssl openssl-devel pam pam-devel libxml2 libxml2-devel libxslt libxslt-devel perl perl-devel tcl-devel uuid-devel gcc gcc-c++ make flex bison perl-ExtUtils
5.2. 安装PostgreSQL软件
5.2.1. 创建组、用户、目录
在3个节点都执行:
su - root
groupadd dba -g 1000
useradd postgres -g 1000 -u 1000
passwd postgres # 输入密码
cd /opt/soft/pg11
tar -xzf postgresql-11.10.tar.gz
chown -R postgres:dba postgresql-11.10
mkdir /opt/pg1110 /opt/pgdata1110 /opt/backup /opt/pgarchive
chown -R postgres:dba /opt/pg1110 /opt/pgdata1110 /opt/backup /opt/pgarchive
chmod 755 /opt/pg1110
chmod 700 /opt/pgdata1110
chmod 777 /opt
5.2.2. 设置postgres用户的环境变量
在3个节点都执行:
su - postgres
vi ~/.bash_profile ,添加:
export PGPORT=5432
export PG_HOME=/opt/pg1110
export PATH=$PG_HOME/bin:$PATH
export PGDATA=/opt/pgdata1110
export LD_LIBRARY_PATH=$PG_HOME/lib
export LANG=en_US.utf8
执行以下命令使环境变量生效:
source ~/.bash_profile
5.2.3. 编译安装PostgreSQL软件
在3个节点都执行:
su - postgres
cd /opt/soft/pg11/postgresql-11.10
./configure --prefix=/opt/pg1110 --with-openssl --with-includes=/usr/include/openssl
gmake world && gmake install-world
5.3. 初始化数据库
仅在 db1 节点(主库)初始化数据库,备库将通过流复制创建。
su - postgres
initdb --pgdata=/opt/pgdata1110 --data-checksums -W
# 输入密码
5.4. 编辑postgresql.conf配置文件
在 db1 节点执行:
su - postgres
vi /opt/pgdata1110/postgresql.conf , 添加或修改以下参数:
listen_addresses = '*'
wal_level = logical
wal_log_hints = on
checkpoint_completion_target = 0.9
archive_mode = on
archive_command = 'cp %p /opt/pgarchive/%f'
wal_keep_segments = 100
synchronous_standby_names = ''
hot_standby_feedback = on
logging_collector = on
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_size = 0
log_min_duration_statement = 0
log_checkpoints = on
log_connections = on
log_disconnections = on
log_line_prefix = '%t [%p]: db=%d,user=%u,app=%a,client=%h '
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
lc_messages = 'en_US.UTF-8'
port = 5432
max_wal_senders = 10
max_replication_slots = 10
max_worker_processes = 8
5.5. 编辑pg_hba.conf文件
在 db1 节点执行,允许本地网络连接和流复制:
su - postgres
vi /opt/pgdata1110/pg_hba.conf , 添加:
host all all 192.168.0.0/24 md5
host replication all 192.168.0.0/24 md5
5.6. 启动主库pg实例
在 db1 节点上启动数据库实例:
su - postgres
pg_ctl -D /opt/pgdata1110 start
注意:这里使用 pg_ctl 命令在前台启动服务,以便后续由 Pacemaker 接管。
5.7. 创建复制用户
在 db1 主节点,创建用于流复制的用户:
su - postgres
create user repluser with replication password 'repluser';
5.8. 创建备库
在 db2、db3 备节点,使用 pg_basebackup 从主库克隆数据目录:
su - postgres
pg_basebackup -h192.168.0.31 -Urepluser -R -Fp -P --verbose -c fast -D /opt/pgdata1110
# 输入密码: repluser
执行该命令后,备库会自动生成 recovery.conf 文件(PostgreSQL 11),无需手动编辑。
5.9. 启动备库
在 db2、db3 备节点,启动数据库实例:
su - postgres
pg_ctl -D /opt/pgdata1110 start
同样,这里使用命令行前台启动。
5.10. 在主库查看集群复制状态
在 db1 主节点执行,验证流复制是否建立:
su - postgres
postgres=# select usename,application_name,client_addr,state,sync_state from pg_stat_replication;
usename | application_name | client_addr | state | sync_state
----------+------------------+--------------+-----------+------------
repluser | walreceiver | 192.168.0.32 | streaming | async
repluser | walreceiver | 192.168.0.33 | streaming | async
(2 rows)
5.11. 在备库查看状态
在 db2、db3 备节点执行,确认处于恢复模式:
su - postgres
select pg_is_in_recovery();
5.12. 停止所有节点pg实例
为后续由集群管理,需要手动停止所有数据库实例。注意顺序:先停止备库,后停止主库。
su - postgres
pg_ctl stop
六、配置集群资源
6.1. 配置cluster_setup.sh脚本
在 db1 节点上创建并编辑集群资源配置脚本。这个脚本定义了VIP、PostgreSQL资源及其复杂的依赖和约束关系,是实现自动故障切换的核心。
su - root
vi /var/lib/pacemaker/cib/cluster_setup.sh , 添加以下内容:
pcs cluster cib pgsql_cfg
pcs -f pgsql_cfg property set no-quorum-policy="ignore"
pcs -f pgsql_cfg property set stonith-enabled="false"
pcs -f pgsql_cfg resource defaults resource-stickiness="INFINITY"
pcs -f pgsql_cfg resource defaults migration-threshold="1"
pcs -f pgsql_cfg resource create vip-master IPaddr2 \
ip="192.168.0.28" \
nic="ens33" \
cidr_netmask="24" \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="block"
pcs -f pgsql_cfg resource create vip-slave IPaddr2 \
ip="192.168.0.29" \
nic="ens33" \
cidr_netmask="24" \
meta migration-threshold="0" \
op start timeout="60s" interval="0s" on-fail="stop" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="ignore"
pcs -f pgsql_cfg resource create pgsql pgsql \
pgctl="/opt/pg1110/bin/pg_ctl" \
psql="/opt/pg1110/bin/psql" \
pgdata="/opt/pgdata1110" \
config="/opt/pgdata1110/postgresql.conf" \
rep_mode="async" \
node_list="db1 db2 db3" \
master_ip="192.168.0.28" \
repuser="repluser" \
primary_conninfo_opt="password=repluser keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
restart_on_promote='true' \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="4s" on-fail="restart" \
op monitor timeout="60s" interval="3s" on-fail="restart" role="Master" \
op promote timeout="60s" interval="0s" on-fail="restart" \
op demote timeout="60s" interval="0s" on-fail="stop" \
op stop timeout="60s" interval="0s" on-fail="block" \
op notify timeout="60s" interval="0s"
pcs -f pgsql_cfg resource master msPostgresql pgsql \
master-max=1 master-node-max=1 clone-max=5 clone-node-max=1 notify=true
pcs -f pgsql_cfg resource group add master-group vip-master
pcs -f pgsql_cfg resource group add slave-group vip-slave
pcs -f pgsql_cfg constraint colocation add master-group with master msPostgresql INFINITY
pcs -f pgsql_cfg constraint order promote msPostgresql then start master-group symmetrical=false score=INFINITY
pcs -f pgsql_cfg constraint order demote msPostgresql then stop master-group symmetrical=false score=0
pcs -f pgsql_cfg constraint colocation add slave-group with slave msPostgresql INFINITY
pcs -f pgsql_cfg constraint order promote msPostgresql then start slave-group symmetrical=false score=INFINITY
pcs -f pgsql_cfg constraint order demote msPostgresql then stop slave-group symmetrical=false score=0
pcs cluster cib-push pgsql_cfg
6.2. 赋予脚本执行权限
在 db1 节点执行:
su - root
chmod +x /var/lib/pacemaker/cib/cluster_setup.sh
6.3. 执行cluster_setup.sh脚本
在 db1 节点执行,将资源配置应用到集群:
su - root
sh /var/lib/pacemaker/cib/cluster_setup.sh
七、启动Corosync服务
启动所有节点的 Corosync 服务,它为 Pacemaker 提供底层的消息和成员管理功能,是构建分布式系统高可用的通信基石。
在3个节点都执行:
su - root
systemctl start corosync.service
说明:在实际部署中,安装 Corosync RPM 包后,通常使用默认配置启动即可,无需编辑 corosync.conf 配置文件。
八、启动Pacemaker服务并验证
8.1. 启动 Pacemaker服务
启动所有节点的 Pacemaker 服务,它作为集群的“大脑”开始工作。
在3个节点都执行:
su - root
systemctl start pacemaker.service
8.2. 检查集群状态
使用 root 用户执行以下命令,全面检查集群和资源的状态。
在 db1 节点执行 crm_mon -Afr -1,查看集群详细状态:
[root@db1 ~]# crm_mon -Afr -1
Stack: corosync
Current DC: db1 (version 1.1.19-8.el7-c3c624ea3d) - partition with quorum
Last updated: Mon Sep 8 22:46:15 2025
Last change: Mon Sep 8 22:45:09 2025 by root via crm_attribute on db1
3 nodes configured
7 resources configured
Online: [ db1 db2 db3 ]
Full list of resources:
Master/Slave Set: msPostgresql [pgsql]
Masters: [ db1 ]
Slaves: [ db2 db3 ]
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started db1
Resource Group: slave-group
vip-slave (ocf::heartbeat:IPaddr2): Started db3
...
执行 pcs status 查看集群概览:
[root@db1 ~]# pcs status
Cluster name: pgcluster
Stack: corosync
Current DC: db1 (version 1.1.19-8.el7-c3c624ea3d) - partition with quorum
Last updated: Mon Sep 8 22:50:26 2025
Last change: Mon Sep 8 22:45:09 2025 by root via crm_attribute on db1
3 nodes configured
7 resources configured
Online: [ db1 db2 db3 ]
Full list of resources:
...
执行 ip addr 验证 VIP 是否已正确绑定。在 db1 节点应看到 vip-master (192.168.0.28),在某个备节点(如db3)应看到 vip-slave (192.168.0.29)。
8.3. 查看流复制状态
在 db1 主节点切换至 postgres 用户,再次查看流复制状态,确认 Pacemaker 管理的数据库复制正常:
su - postgres
postgres=# select usename,application_name,client_addr,state,sync_state from pg_stat_replication;
usename | application_name | client_addr | state | sync_state
----------+------------------+--------------+-----------+------------
repluser | db3 | 192.168.0.33 | streaming | async
repluser | db2 | 192.168.0.32 | streaming | async
(2 rows)
至此,一个基于 Pacemaker + Corosync 的 PostgreSQL 高可用集群已经部署完成。该集群能够自动管理数据库主备切换、VIP 漂移,为上层应用提供持续可用的数据库服务。如果你想了解更多关于高可用架构或 Linux 集群的实践,欢迎访问 云栈社区 进行交流探讨。
 发表于 2026-1-3 11:10:25
|
查看: 191|
回复: 0
发表于 2026-1-3 11:10:25
|
查看: 191|
回复: 0
