Lux 是一个专门用于计算机操作的基础模型。与仅能生成文本的传统 AI 不同,Lux 能够理解屏幕上的视觉信息,解析自然语言描述的任务目标,并实时操控计算机来完成具体工作。
例如,你可以对电脑说“打开浏览器,访问某个网站”,Lux 便能像真人一样执行一系列操作:移动鼠标、点击图标、输入网址、滚动页面。整个过程流畅自然,几乎与人类操作无异。
Lux 的技术实现
Lux 的优势在于它不依赖于任何特定的应用程序接口(API),因此能够在几乎任何桌面应用中工作,无论是浏览器、代码编辑器、邮件客户端还是电子表格软件。它的核心技术融合了计算机视觉与动作预测:
- 捕获屏幕截图:实时获取当前桌面状态。
- 解析 UI 组件:识别窗口、按钮、输入框等界面元素。
- 预测下一步操作:判断需要执行的点击、输入、滚动等动作。
- 循环执行:持续执行“观察-行动”循环,直至任务结束。
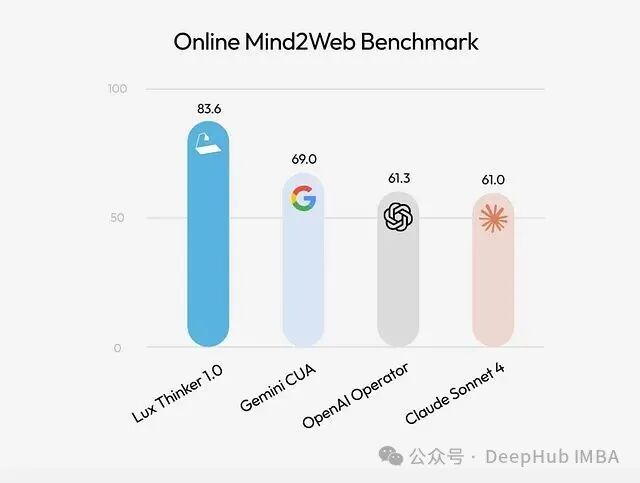
在涉及 300 个实际网络操作场景的基准测试中,Lux 的表现超越了 Google Gemini CUA、OpenAI Operator 以及 Anthropic Claude 等同类方案。
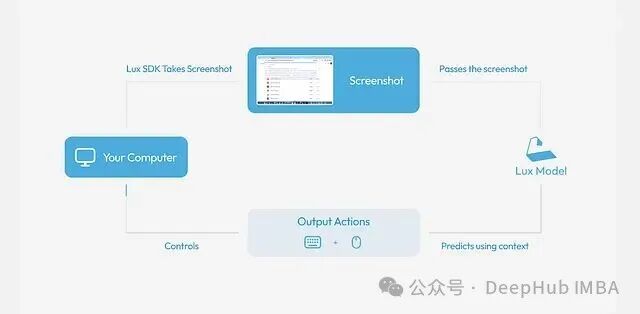
工作机制
Lux 运行在一个持续的动作-观察循环之中:
目标 → 视觉分析 → 执行动作 → 获取反馈 → 循环
用户使用自然语言下达指令,例如:“打开浏览器并搜索最新新闻”。随后,Lux 会截取当前屏幕画面,并基于截图内容智能决策下一步操作,可能包括:
- 点击某个特定按钮
- 在输入框中键入文字
- 移动光标至目标位置
- 滚动页面以查看更多内容
- 触发系统或应用的快捷键
执行动作后,Lux 会再次捕获新的屏幕状态作为反馈,并进入下一轮循环。这个过程会一直持续,直到预设任务被完成为止。你可以将它想象成一个坐在你电脑前,替你处理琐碎工作的 AI 助手。
环境配置
在开始使用 Lux 之前,需要完成必要的安装和系统权限设置。
步骤 1:权限授予
Lux 需要与常规自动化工具相同的系统权限:屏幕录制权限和辅助功能权限。
在终端中执行以下命令来触发权限申请:
oagi agent permission
在 macOS 系统中,执行上述命令后系统会弹出权限请求窗口,主要涉及:
你需要进入 系统设置 — 隐私与安全,在相应的权限列表中批准这些请求。权限设置完成后,请务必重启终端应用以使更改生效。
步骤 2:API 认证
访问 agiopen 官方网站以生成新的 API 密钥。新注册用户通常会获得一定额度的免费试用(例如 $10),这足以运行数十次代理任务。
获取密钥后,需要在终端中配置环境变量:
export OAGI_API_KEY=sk-...
export OAGI_BASE_URL=https://api.agiopen.org
步骤 3:桌面环境准备
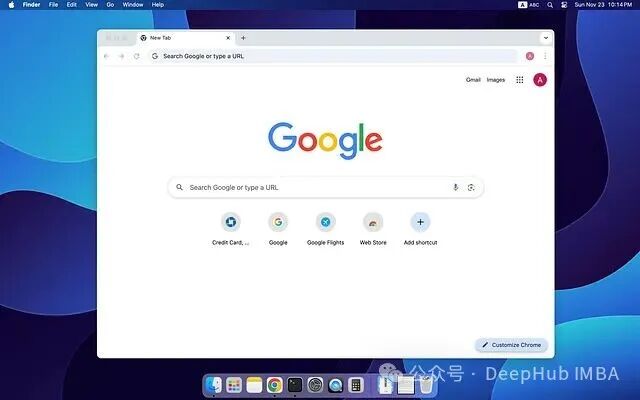
由于 Lux 直接读取并分析屏幕内容,一个干净、整洁的桌面环境有助于提高 UI 元素识别的准确性。
推荐的工作区配置如下:
- 浏览器以单个最大化窗口运行。
- 使用空白页或简洁的起始页。
- 保持桌面图标整洁,尽量减少无关窗口。
- 使用颜色单一或简洁的桌面壁纸。
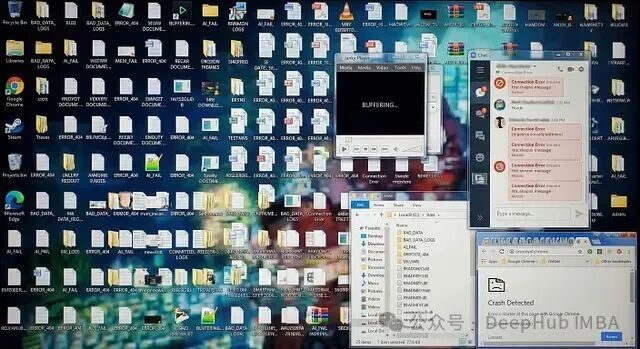
不推荐的配置包括:
- 多个小窗口杂乱排列。
- 不同程序的窗口互相重叠遮挡。
- 使用元素复杂、色彩斑斓的桌面壁纸。
混乱的桌面环境可能导致 Lux 在识别元素时出错,从而需要多次重试或执行错误点击。
步骤 4:第一次运行
完成上述配置后,就可以尝试运行你的第一个 Lux 指令了:
oagi agent run "Go to https://agiopen.org" --model "lux-actor-1"
执行命令后,你将看到鼠标开始自动移动,键盘自动输入,整个网页访问过程完全由 AI 自动化完成。
实际案例
假设我们需要 Lux 完成一个更复杂的任务:启动浏览器,搜索“OpenAGI Lux model documentation”,并滚动浏览搜索结果。
对应的命令如下:
oagi agent run "Open a browser, search for OpenAGI Lux model documentation, and scroll through the results." --model "lux-actor-1"
Lux 会按逻辑顺序执行以下步骤:
- 识别并定位到浏览器图标或Dock栏中的浏览器。
- 点击以启动浏览器应用程序。
- 在浏览器界面中定位地址栏或搜索框。
- 输入指定的搜索关键词。
- 模拟按下回车键进行搜索。
- 加载搜索结果页面后,识别页面的可滚动区域。
- 自动执行向下滚动操作,以浏览更多结果。
整个流程完全依赖于 Lux 的视觉理解与动作预测能力,无需任何预设脚本或规则。
总结
Lux 不仅是一个先进的AI模型,更代表了一个重要的技术发展方向:让计算机能够直接理解并执行人类的高层意图,而非依赖于人类一步步的点击和输入。这种基础模型的能力,正在将“让电脑替你把事情做了”这个想法变为触手可及的现实。如果你对AI如何通过计算机视觉理解世界并与之交互感兴趣,可以到 云栈社区 的 人工智能 板块查看更多深度讨论和技术分享。

 发表于 2026-1-4 01:13:36
|
查看: 275|
回复: 0
发表于 2026-1-4 01:13:36
|
查看: 275|
回复: 0
