本文将介绍一种结合 MCP 协议与数据库,以提升大模型对外部知识检索精度的新思路。通过一个学生管理系统的实战案例,我们将展示其效果如何超越传统的 RAG 技术。
我们先了解一下 RAG 技术目前存在的局限性。
一、背景:RAG 的局限性
RAG,即检索增强生成(Retrieval-Augmented Generation),是大模型领域的一个热门方向。它通过结合信息检索与生成式模型,旨在解决大模型在知识准确性、上下文理解以及对最新信息利用方面的难题。
然而,在实际应用中,RAG 的精准度可能并未达到预期。从其技术原理出发,主要存在以下问题:
- 检索精度不足:RAG 的核心流程是先将知识转换为向量存入向量数据库。当用户提问时,将问题也转换为向量,并在向量库中进行相似度匹配,最后让大模型总结检索到的内容。
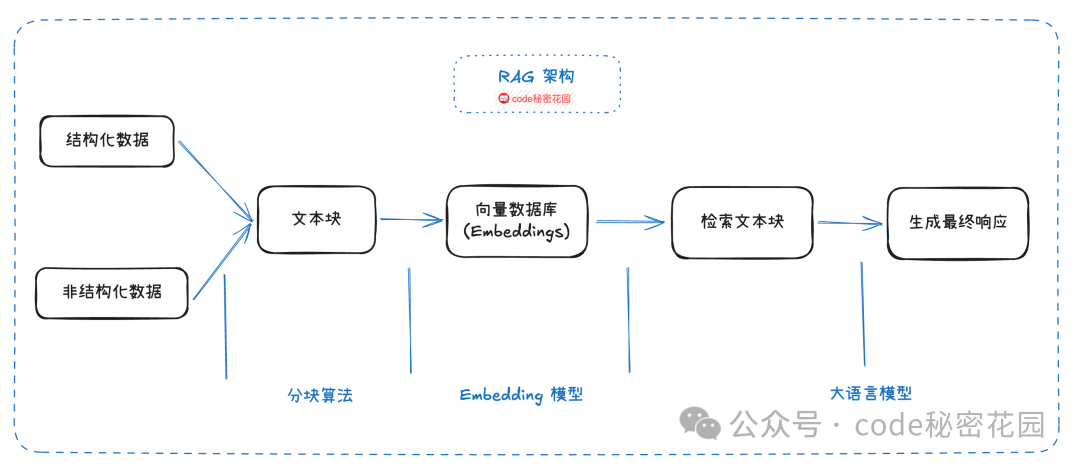
在这个过程中,大模型主要扮演总结者的角色。检索信息的精准度高度依赖于向量相似度匹配,这可能导致检索结果包含无关内容(低精确率)或遗漏关键信息(低召回率)。
- 生成内容不完整:RAG 处理的是文档切片,其局部性决定了它无法获取整篇文档的全貌。因此在回答“列举XXX”或“总结XXX”这类需要全局视野的问题时,答案往往是不完整的。
- 缺乏大局观:RAG 难以判断需要多少切片才能完整回答问题,也无法理解文档间的关联。例如,在法律条文中,新的解释可能覆盖旧的,但 RAG 无法有效判断哪个版本是最新的。
- 多轮检索能力弱:RAG 缺乏执行多轮、复杂查询检索的能力,而这对于许多推理任务而言是必不可少的。
尽管近期出现了如 GraphRAG、KAG 等新技术试图解决这些问题,但它们都还不成熟。目前的 RAG 技术效果,距离我们的理想目标仍有差距。
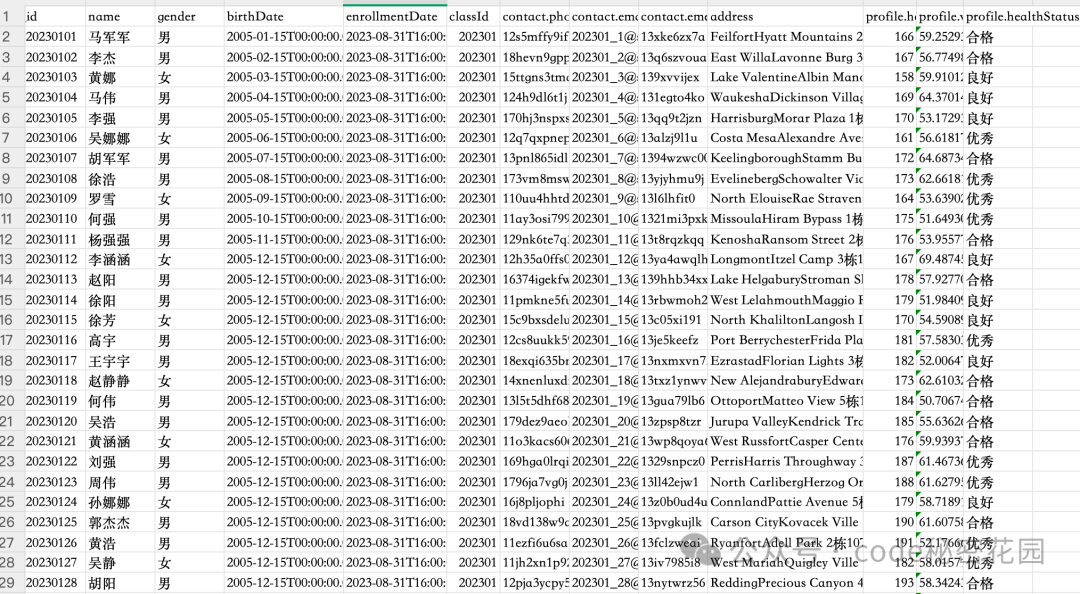
下面,我们将介绍一种新的方案:通过 MCP 协议连接数据库,来提升对结构化数据的检索精准度。它能基本实现“text to SQL”的效果,实测检索效果显著优于 RAG。例如,面对这样一份学生信息列表:
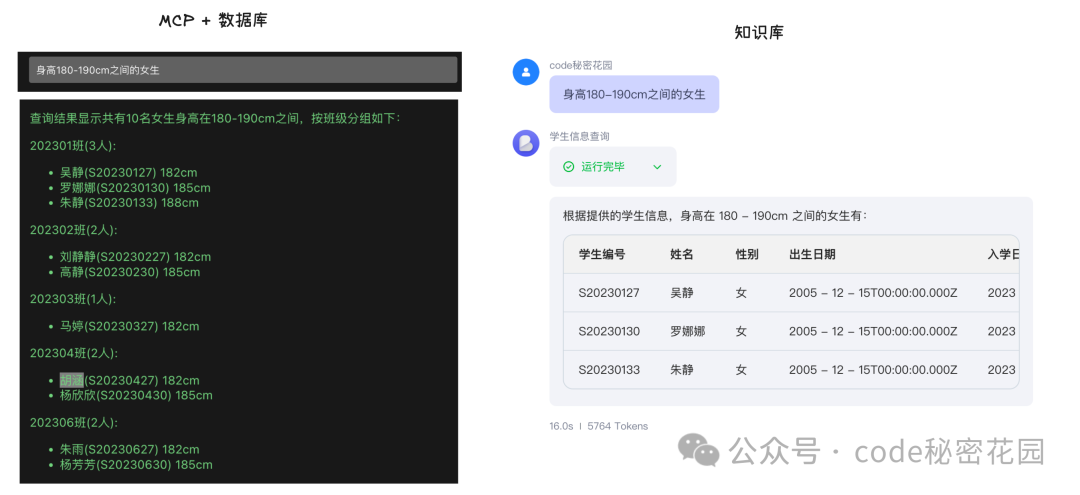
当我们提出一个稍复杂的问题——“身高 180-190cm 之间的女生有哪些?”时,两种方式的对比结果如下:
二、理论:了解 MCP 的基础知识
在深入学习 MCP 之前,必须先了解 Function Call 的概念。
2.1 Function Call
早期的 AI 大模型如同一个知识渊博但被禁锢在房间中的人,只能依赖内部知识回答问题,无法直接获取实时数据或与外部系统交互。
Function Call(函数调用)是 OpenAI 在 2023 年推出的一个重要概念,它本质上是赋予大模型与外部系统交互的能力,就像为模型安装了一个“外挂工具箱”。
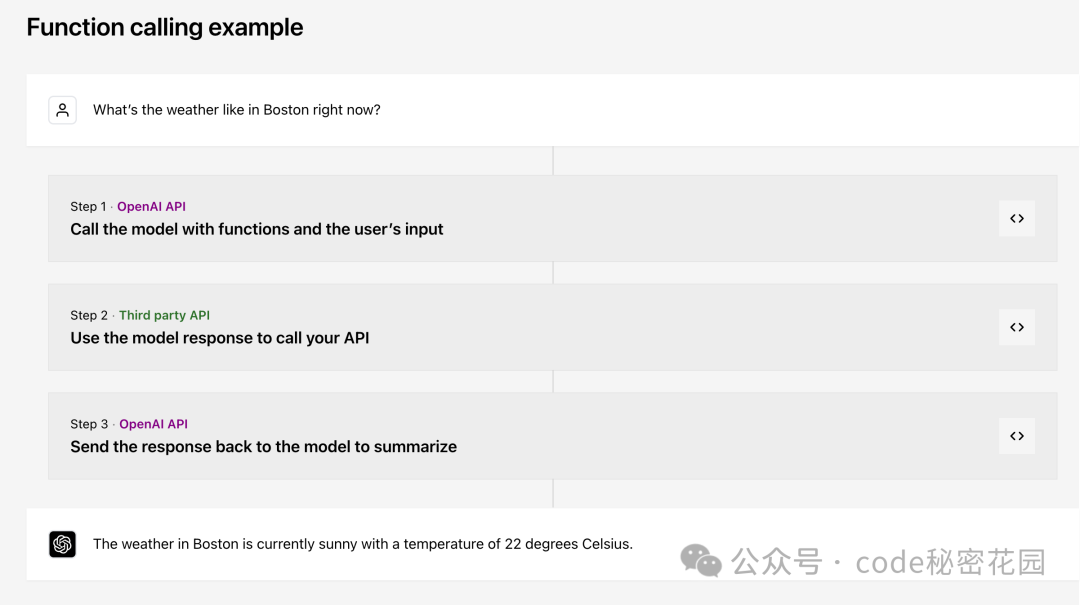
当大模型遇到无法直接回答的问题时,它可以主动调用预设的函数(如查询天气、访问数据库等),获取实时或精准信息后再生成回答。例如,在 Coze 这类零代码 Agent 搭建平台上看到的插件,其底层就是基于 Function Call 的思路封装的。
然而,这个能力有一个显著缺点:实现成本过高。在 MCP 出现之前,开发者要实现 Function Call 面临很高门槛。首先,模型本身需要稳定支持 Function Call 调用。例如在 Coze 中选择某些模型时,会提示不支持插件调用,本质就是不支持 Function Call。
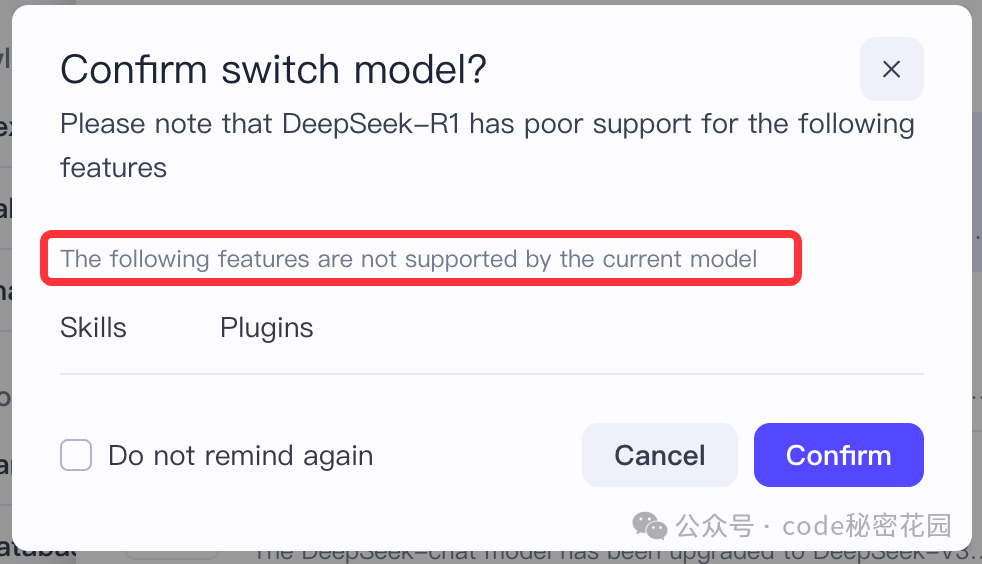
其次,更大的问题在于 协议不统一。OpenAI 最初提出这项技术时,并未将其定义为行业标准。因此,尽管后续许多模型都支持了 Function Call,但各自的实现方式(参数格式、触发逻辑、返回结构等)各不相同。
这意味着,如果我们要开发一个 Function Call 工具,需要对不同模型进行单独适配,成本极高。
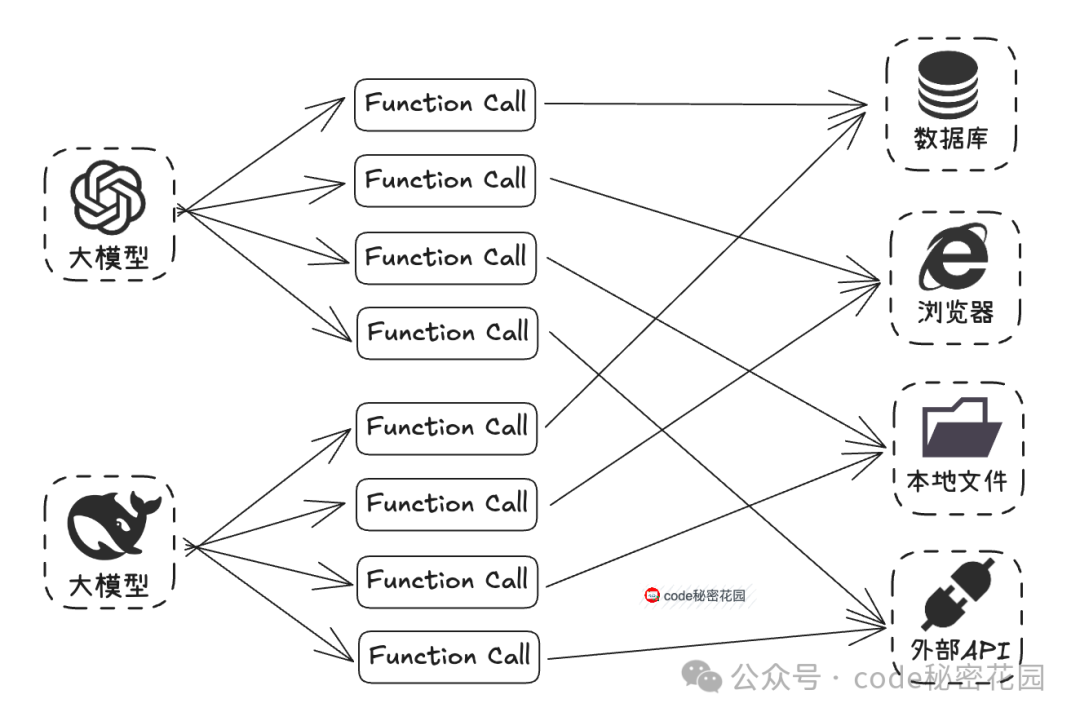
这也大大提高了 AI Agent 的开发门槛,使得在过去,开发者大多只能依赖 Dify、Coze 这类平台来构建 Agent。
核心特点与痛点
- 核心特点:
- 模型专属:不同模型(GPT/Claude/DeepSeek)的调用规则各异。
- 即时触发:模型解析用户意图后直接调用工具。
- 简单直接:适合单一功能调用场景。
- 痛点:
- 协议碎片化:需为每个模型单独开发适配层。
- 功能扩展难:新增工具需重新训练模型或调整接口。
2.2 MCP
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 公司推出的一个开放标准协议,旨在解决 AI 模型与外部数据源、工具交互的标准化难题。
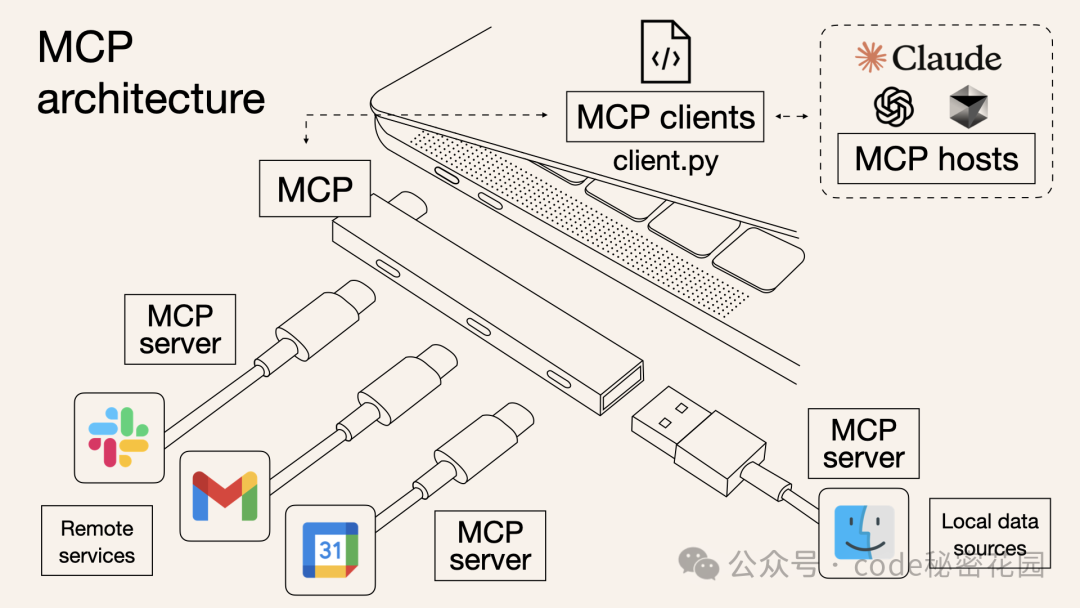
你可以把 MCP 理解为一个“通用插头”或“USB-C接口”。它制定了一套统一的规范,无论是连接数据库、第三方 API 还是本地文件,各种外部资源都可以通过这个“通用接口”与 AI 模型交互,让整个过程变得标准化、可复用。
最初只有 Claude 客户端支持 MCP,并未引起广泛关注。但随着 Cursor 等工具的支持,以及各类插件和工具的跟进,MCP 逐渐进入大众视野。特别是近期,OpenAI 也宣布对 MCP 提供支持,这标志着 MCP 正成为 AI 工具调用的“行业标准”。
MCP 的工作原理:像 Claude Desktop、Cursor 这类工具作为 MCP Host,其内部实现了 MCP Client。MCP Client 通过标准的 MCP 协议与 MCP Server 交互。由第三方开发者提供的 MCP Server 负责实现与各种资源(数据库、浏览器、本地文件等)交互的具体逻辑,最后再将结果通过标准协议返回给 MCP Client 并展示。
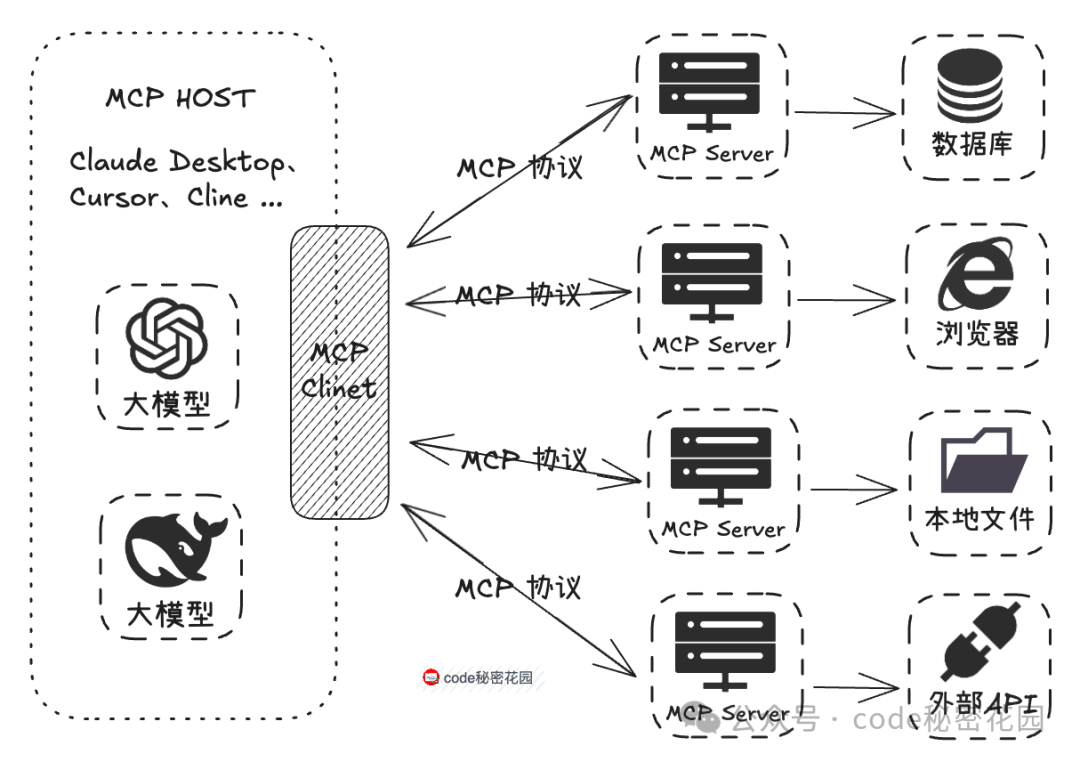
开发者只需按照 MCP 协议进行开发,无需为每个模型与不同资源的对接重复编写适配代码。同时,已开发出的 MCP Server 由于协议通用,可以直接开放给社区使用,极大地减少了重复劳动。例如,你开发的插件逻辑,可以同时应用于所有支持 MCP 的平台。
核心特点与价值
- 核心特点:
- 协议标准化:统一了工具调用的请求、响应及错误处理格式。
- 生态兼容性:一次开发即可对接所有兼容 MCP 的模型和客户端。
- 动态扩展:新增工具无需修改模型代码,实现即插即用。
- 核心价值(解决三大问题):
- 打破数据孤岛 → 打通本地/云端数据源。
- 避免重复开发 → 工具开发者只需适配 MCP 协议。
- 消除生态割裂 → 促进形成统一的工具市场。
2.3 MCP 对比 Function Call

注:上图中关于“调用方式”的描述可能有误,实际调用方式应以具体实现为准。
三、尝试:学会 MCP 的基本使用
从 MCP 的架构图可知,使用 MCP 技术首先需要一个支持该协议的客户端,然后找到符合需求的 MCP 服务器,并在客户端中进行配置和调用。
3.1 MCP 客户端(Host)
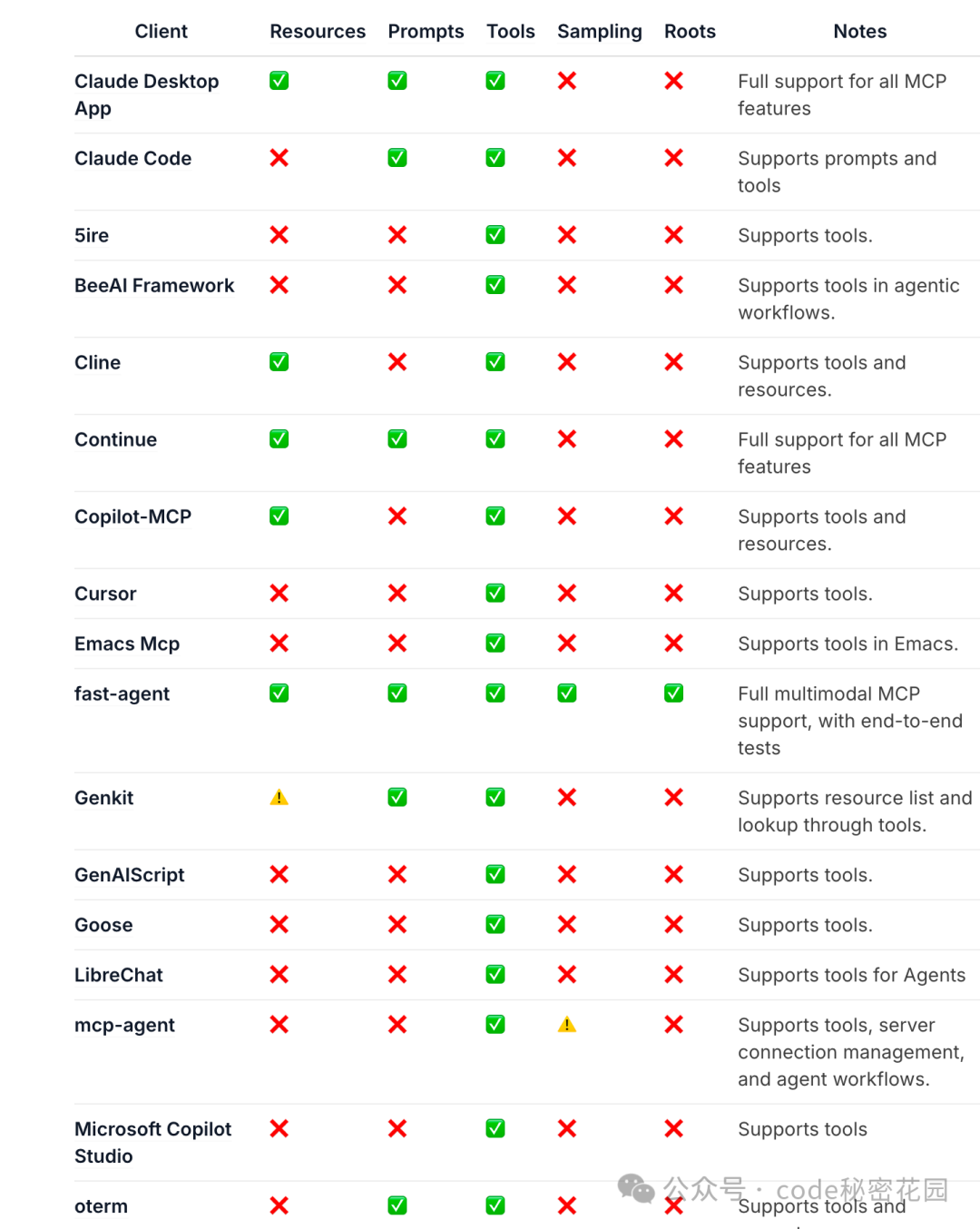
MCP 官方文档列出了已支持该协议的客户端列表。MCP 为客户端定义了五大能力,目前最常用且支持最广泛的是 Tools(工具调用)能力。
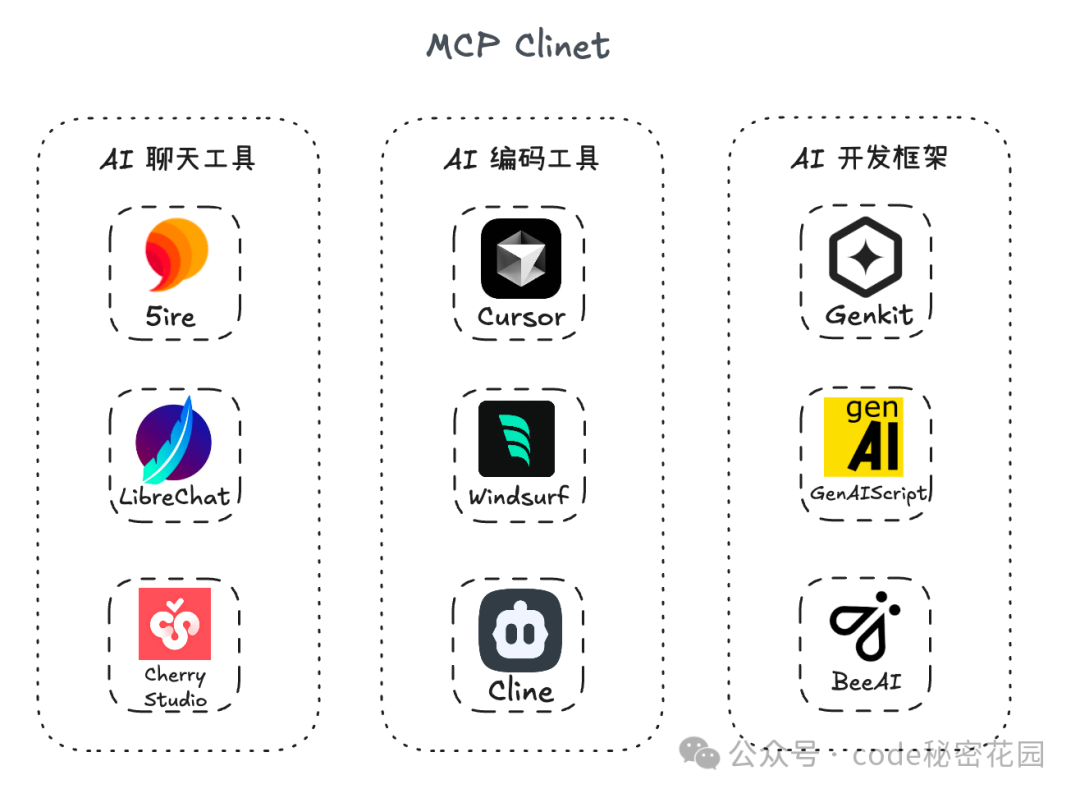
这些支持 MCP 的工具大致可分为三类:
- AI 聊天工具:如 5ire、LibreChat、Cherry Studio
- AI 编码工具:如 Cursor、Windsurf、Cline
- AI 开发框架:如 Genkit、GenAIScript、BeeAI
3.2 MCP Server
MCP Server 的官方描述是:一个通过标准化模型上下文协议公开特定功能的轻量级程序。简单来说,它就是通过标准化协议与客户端交互,让模型能够调用特定数据源或工具的程序。常见的 MCP Server 包括:
- 文件和数据访问类:如 File System MCP Server。
- Web 自动化类:如 Puppeteer MCP Server。
- 三方工具集成类:如高德地图 MCP Server。
寻找所需 MCP Server 的途径:
- 官方 GitHub 仓库 (
https://github.com/modelcontextprotocol/servers):包含官方参考示例及社区开发的 Server。

- MCP.so (
https://mcp.so/):第三方聚合平台,收录了 5000+ 个 MCP Server,提供友好的展示和配置示例。
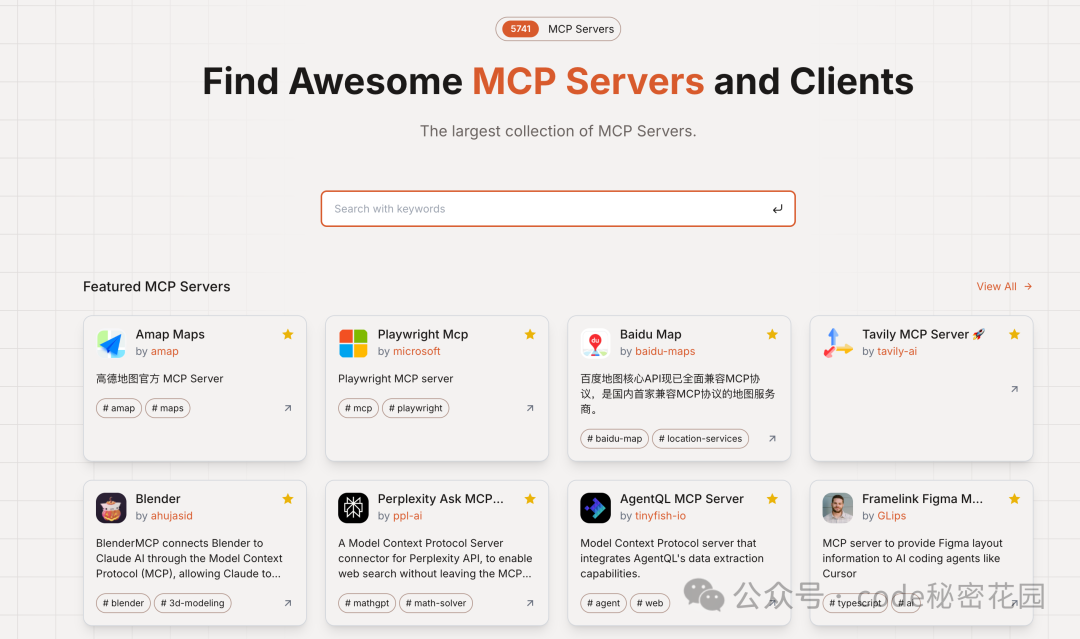
- MCP Market (
https://mcpmarket.cn/):访问速度不错,支持按工具类型筛选。
3.3 在 Cherry Studio 中尝试 MCP
我们以一个最简单的文件系统 MCP 接入为例,选择对新手友好的 Cherry Studio。它可以在客户端内一键安装必备环境(如 uv、bun),而其他一些工具可能需要用户手动安装。
打开 Cherry Studio 客户端,进入「设置 - MCP 服务器」并完成环境安装。
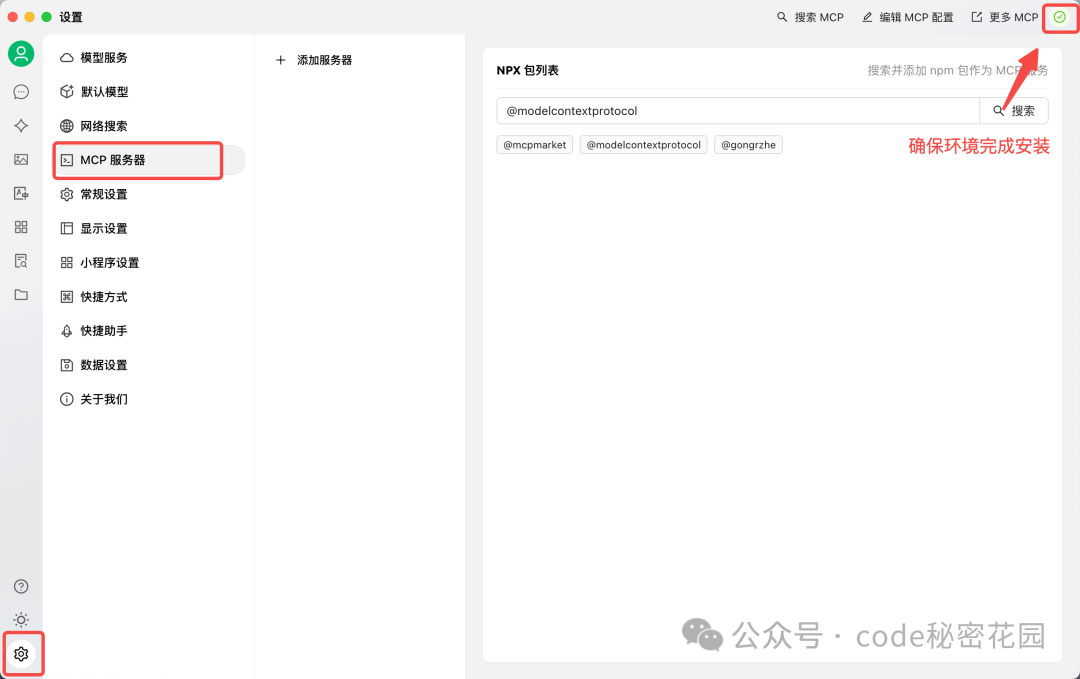
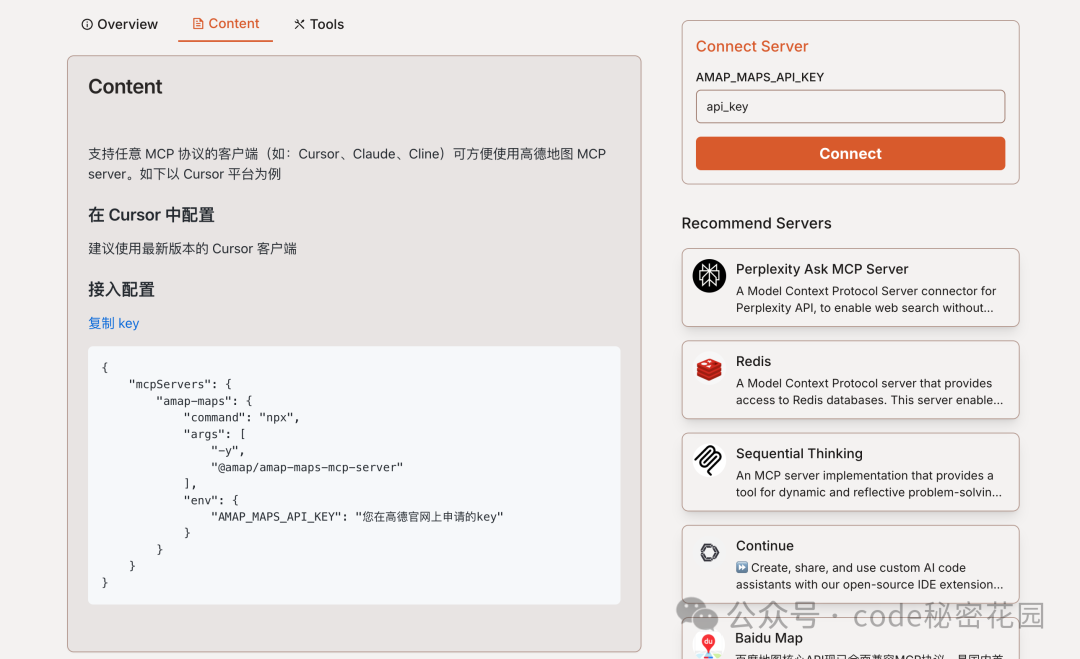
在搜索框中搜索 @modelcontextprotocol/server-filesystem,这是一个简单的文件系统 MCP Server。
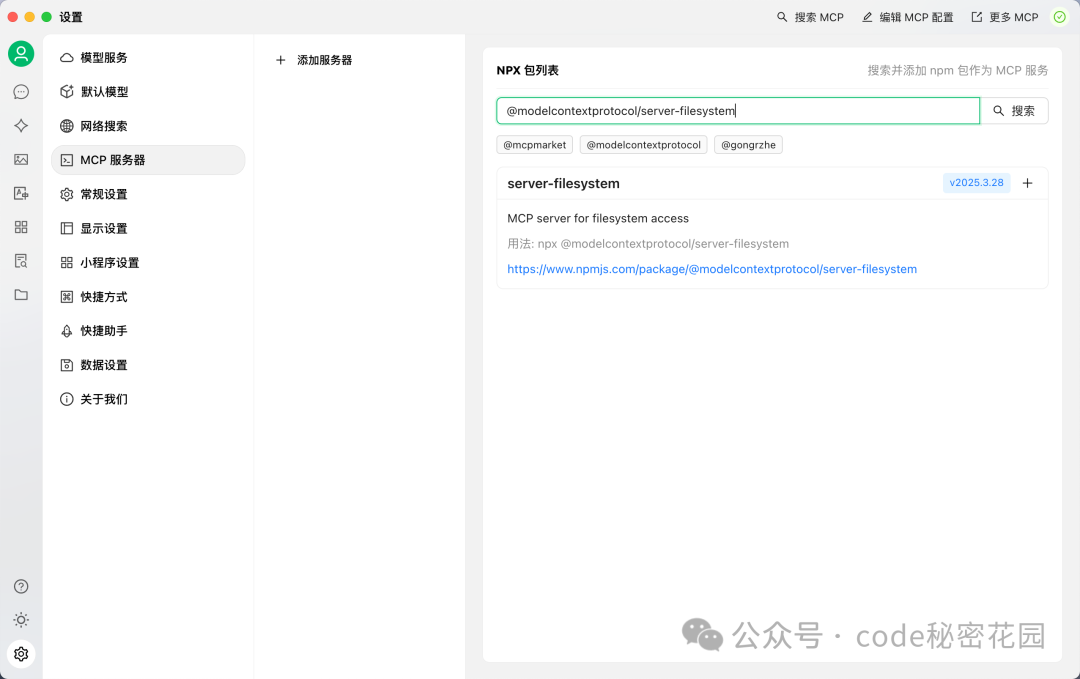
点击添加后,补充一个参数:允许访问的文件夹路径(例如 ~/Desktop)。
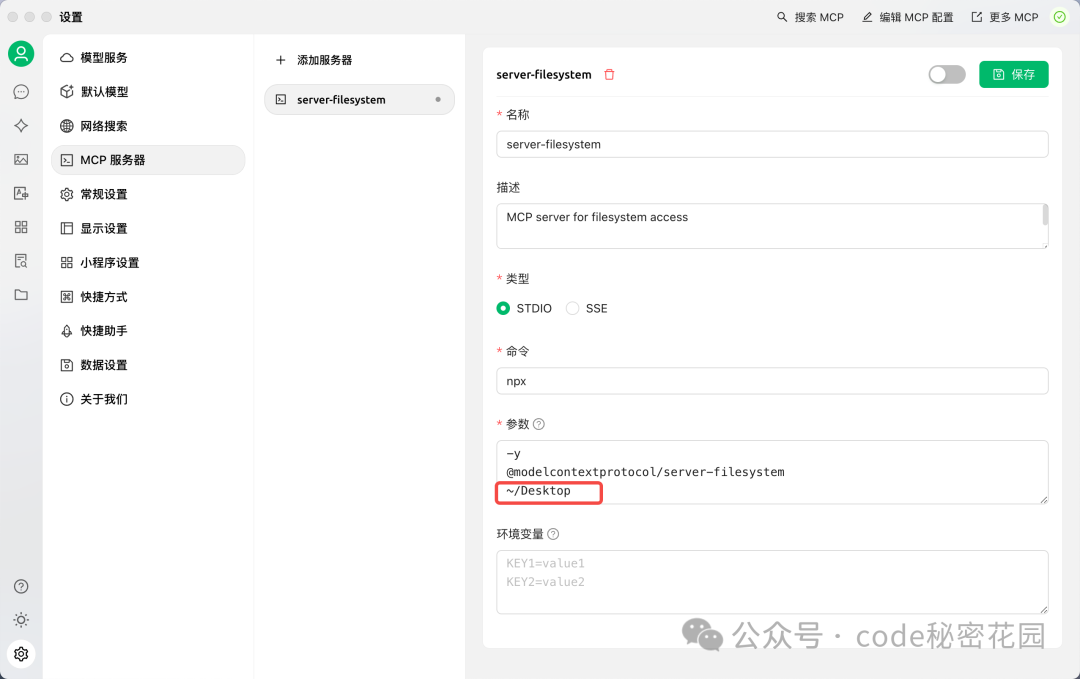
保存后,如果服务器状态显示为绿灯,则配置成功。
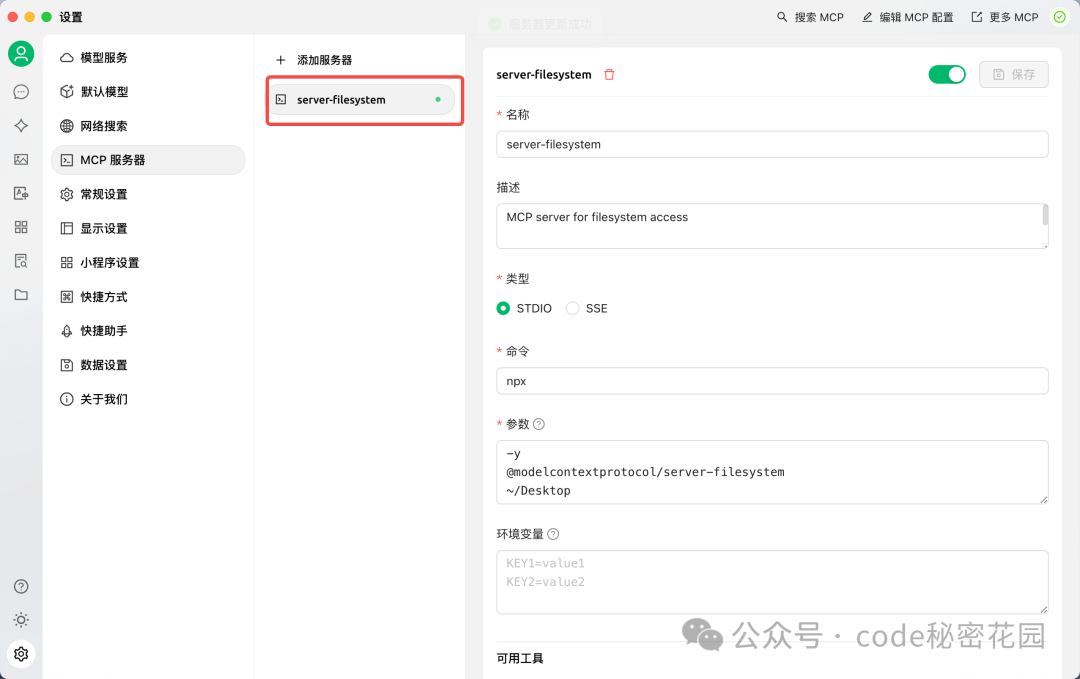
接下来,在聊天区域选择带有扳手🔧图标的模型(这表示该模型支持工具调用),并打开下方的 MCP 开关。
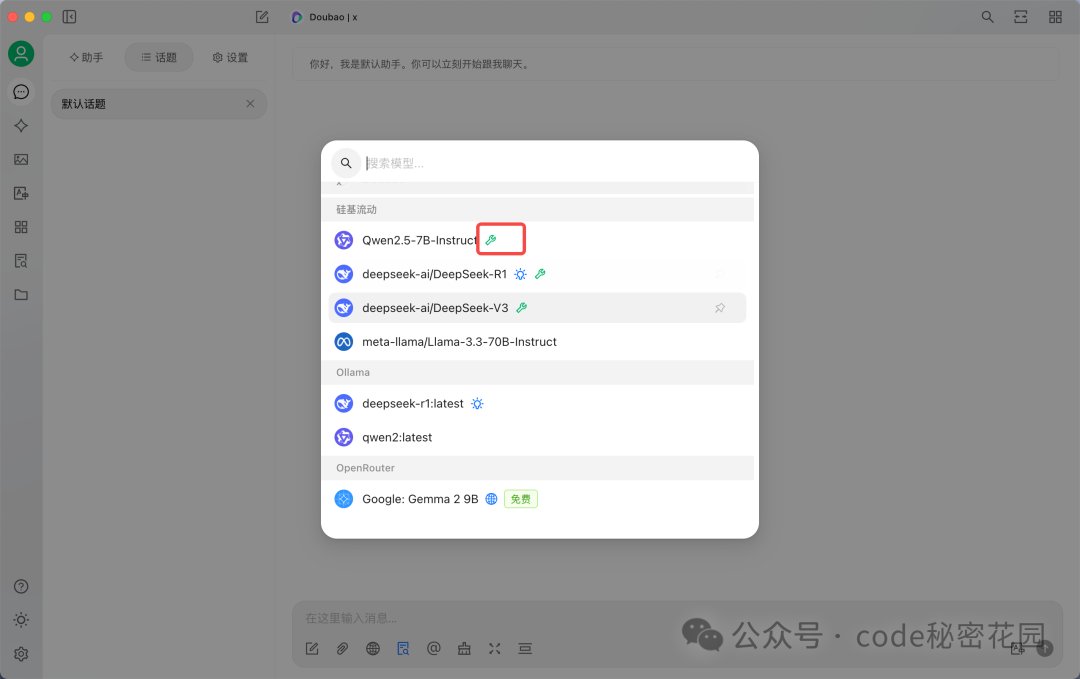
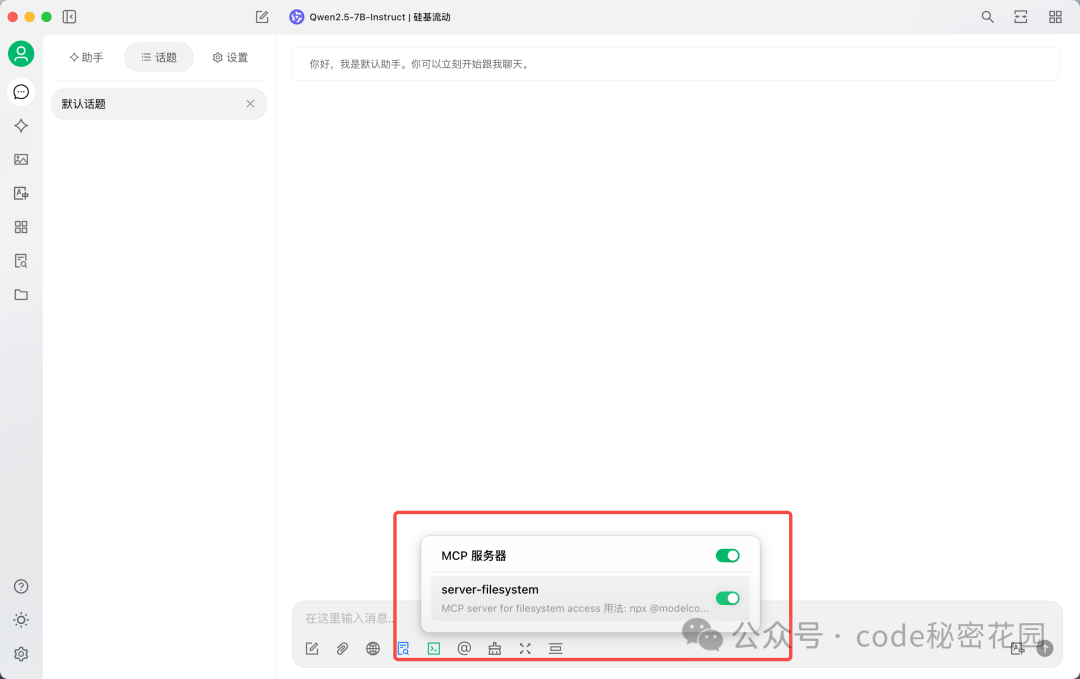
现在,可以尝试让模型访问桌面文件列表。
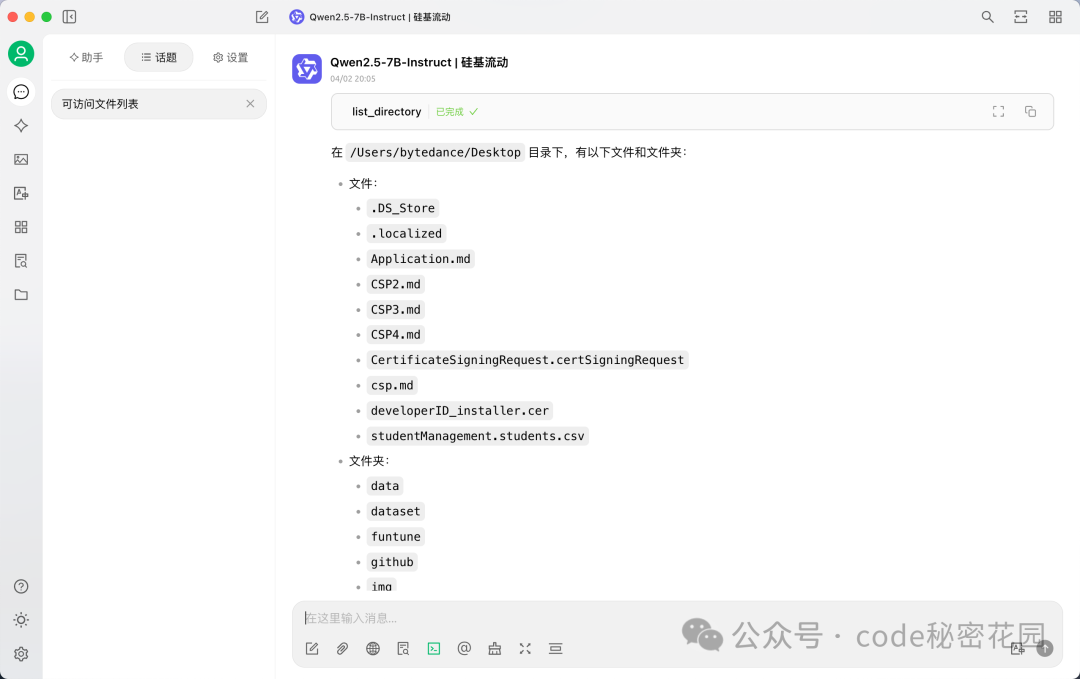
调用成功!这就是一个最简单的 MCP 调用示例。不过,由于 Cherry Studio 对 MCP 的支持尚新,在模型兼容性和调用稳定性上可能有所不足。因此,在接下来的实战章节,我们将使用 VsCode + Cline 这一组合进行演示。但请记住,核心是掌握 MCP 的使用思路,随着生态发展,各种工具都会越来越成熟。
四、实战:使用 MCP 调用数据库
首先,我们构建一个简单的数据库案例用于演示。
4.1 准备 MongoDB 数据库
我们选择 MongoDB 这款流行的开源文档型数据库。它以 JSON 格式存储数据,相比关系型数据库(如 SQLite),其文档模型允许在同一集合中存储结构不同的文档,可以灵活地添加或修改字段,无需事先定义严格的表结构。这对于构建一个需要持续补充的结构化知识库场景非常友好。

- 安装 MongoDB Community Server:从官网下载并安装免费开源版本。
- 安装 MongoDB Compass:这是 MongoDB 提供的 GUI 可视化工具,便于查看和管理数据。
- 连接数据库:通过 Compass 客户端连接到本地默认运行的 MongoDB 服务(通常监听 27017 端口)。
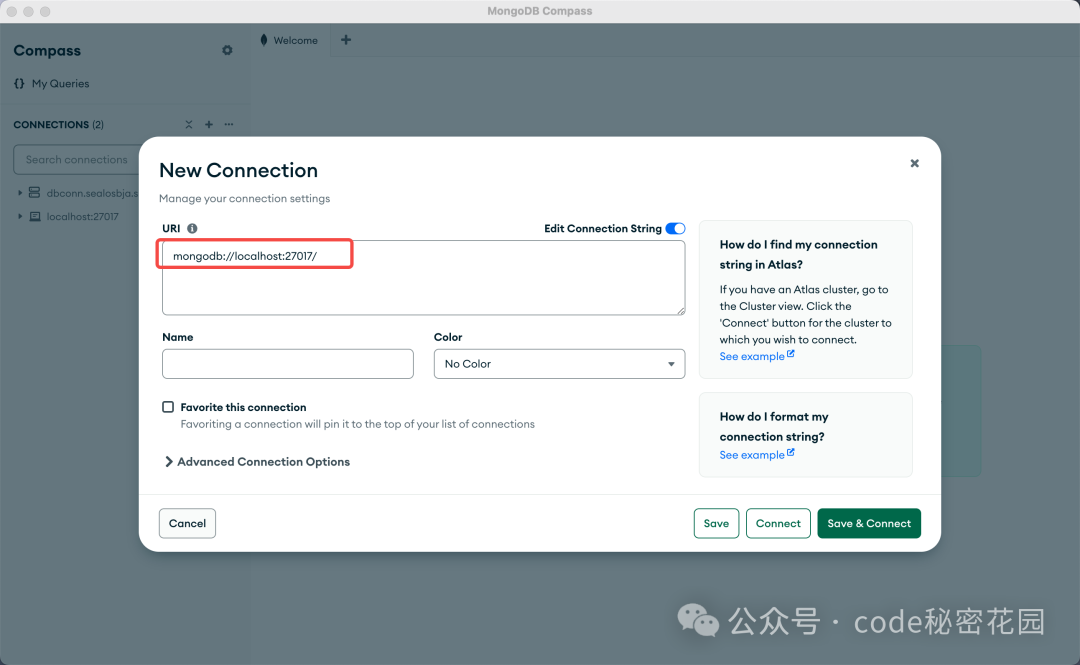
在本案例中,我们将使用一个学生信息数据集。数据表示范如下:
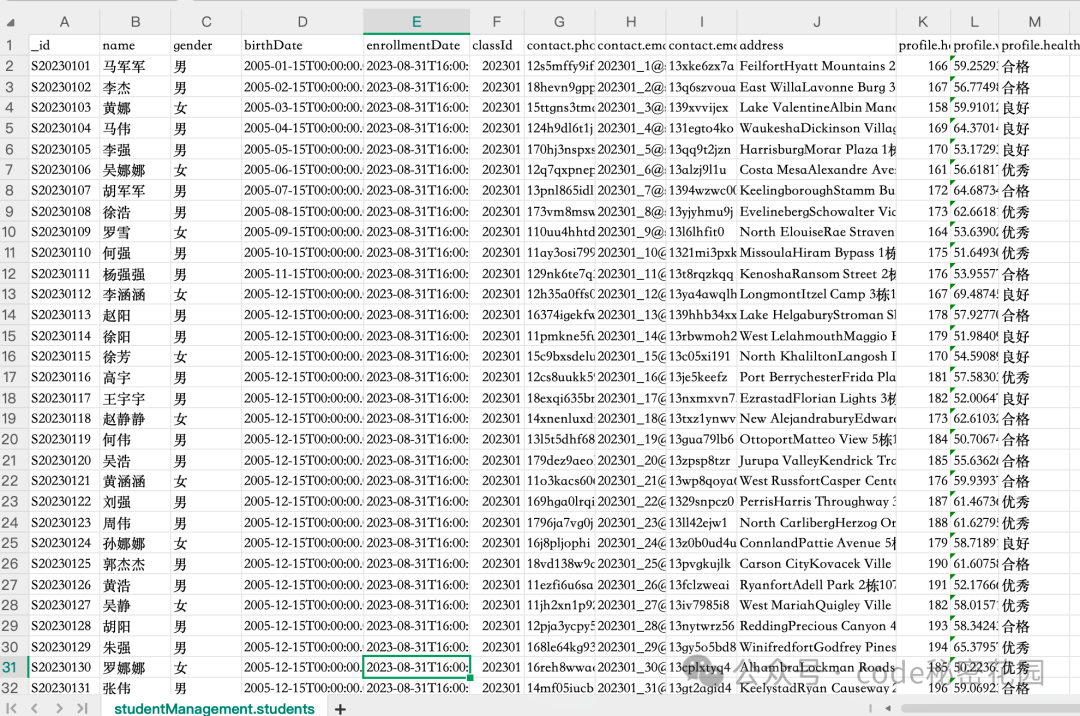
如果你不知道如何导入数据,可以借助 AI 生成导入脚本。提示词示例:帮我编写一个脚本,可以将当前表格中的数据导入我本地的 MongoDB 数据库,数据库的名称为 studentManagement。
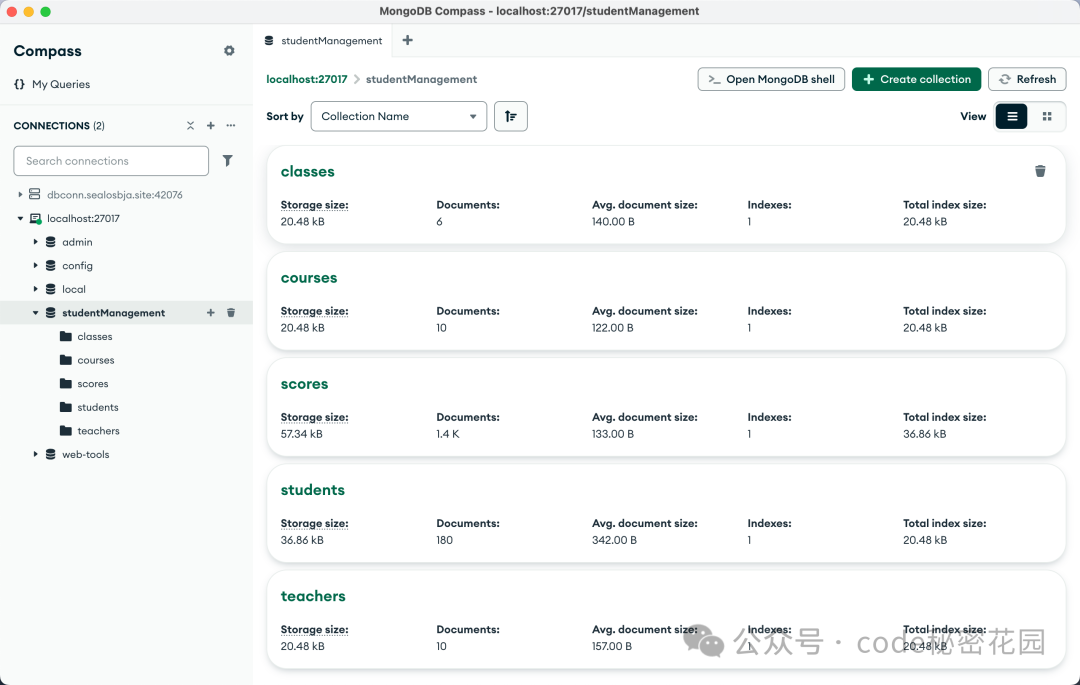
运行脚本成功导入后,可以在 Compass 中看到数据库及其集合。
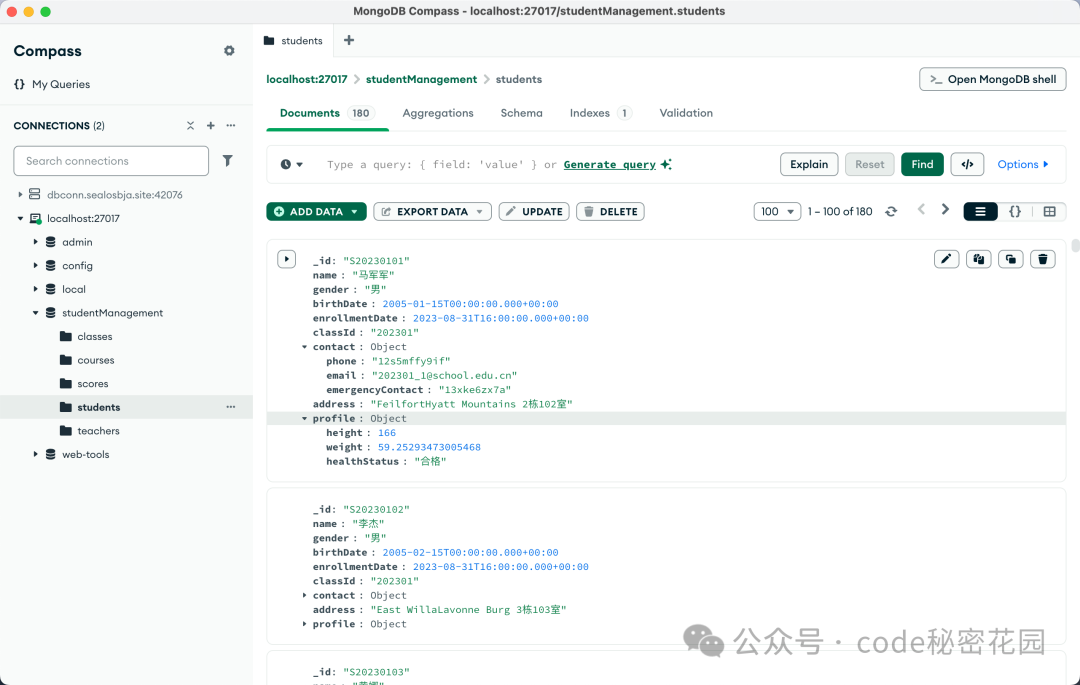
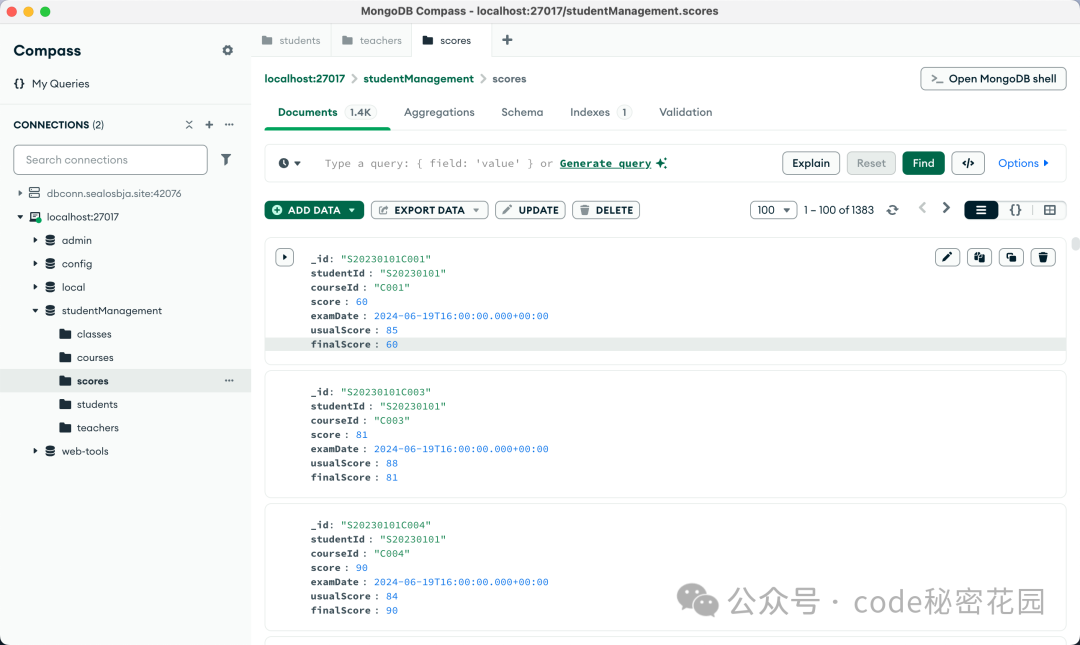
4.2 配置 VsCode 与 Cline 环境
在测试了多个支持 MCP 的客户端后,Cline 对 MCP 的兼容效果不错。它是一个开源、免费的 VSCode 插件,支持配置多种第三方 AI API,非常灵活。

安装与配置:
- 在 VSCode 插件市场中搜索并安装
Cline(选择下载量最大的官方版本)。
- 打开 Cline 侧边栏,进入设置,配置你的 AI 模型提供商和 API 密钥。
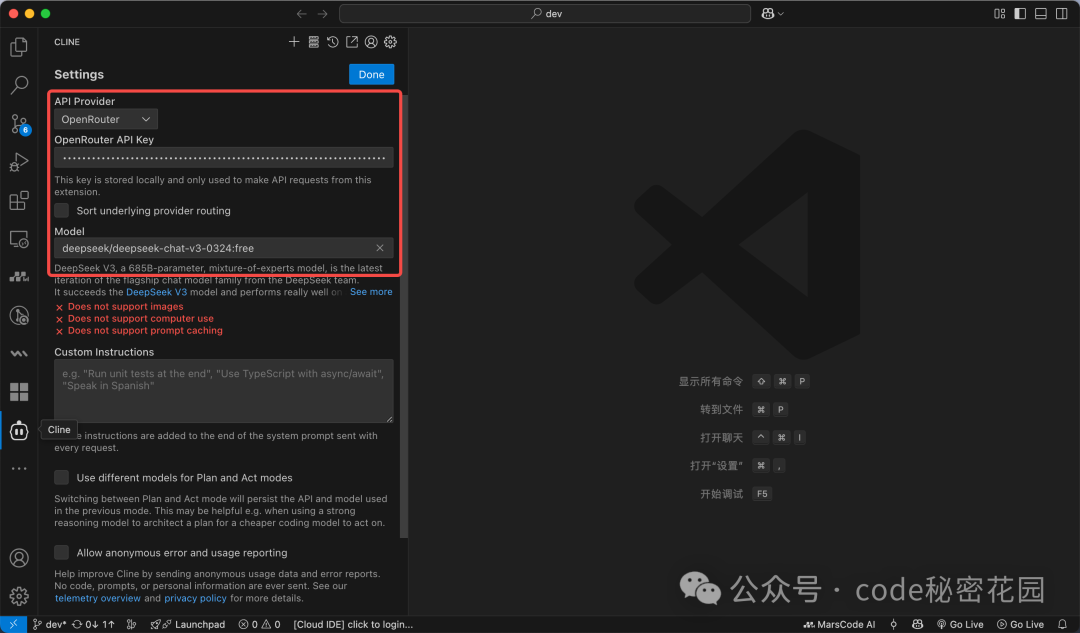
- 配置完成后,在聊天窗口进行测试,确保模型能正常响应。
4.3 在 Cline 中配置 mcp-mongo-server
接下来,我们需要一个支持 MongoDB 的 MCP Server。社区已有现成的选择,例如 mcp-mongo-server。
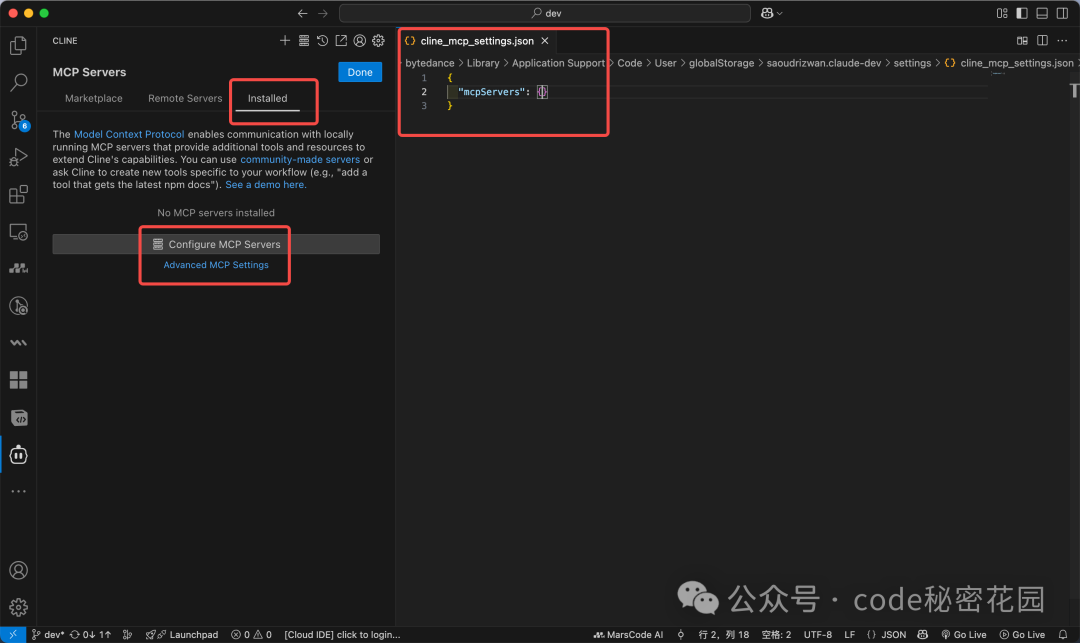
在 Cline 中配置 MCP Server:
- 点击上方工具栏的
MCP Servers 图标。
- 如果所需 Server 不在内置市场列表,则切换到
Installed 标签页,点击 Configure MCP Servers。
- 这会打开一个 JSON 配置文件 (
cline_mcp_settings.json)。
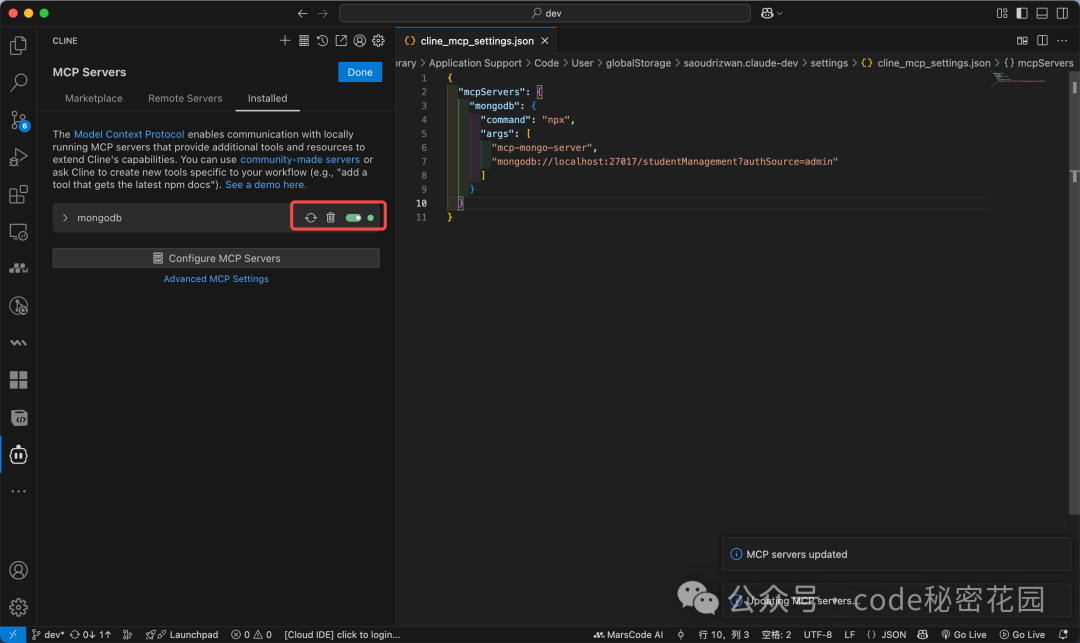
根据 mcp-mongo-server 提供的配置示例,我们进行简化配置。关键参数是:
command: 执行命令(这里用 npx,需提前安装 Node.js 环境)。args: 传递给命令的参数。
例如,连接本地无认证的 studentManagement 数据库:
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"mcp-mongo-server",
"mongodb://localhost:27017/studentManagement"
]
}
}
}
将配置粘贴到 Cline 的配置文件中,如果左侧对应的服务器指示灯变为绿色,说明配置成功。
注意:使用 npx 命令需要你的电脑上已安装 Node.js 环境。安装后,可在终端通过 node -v 和 npx -v 验证。
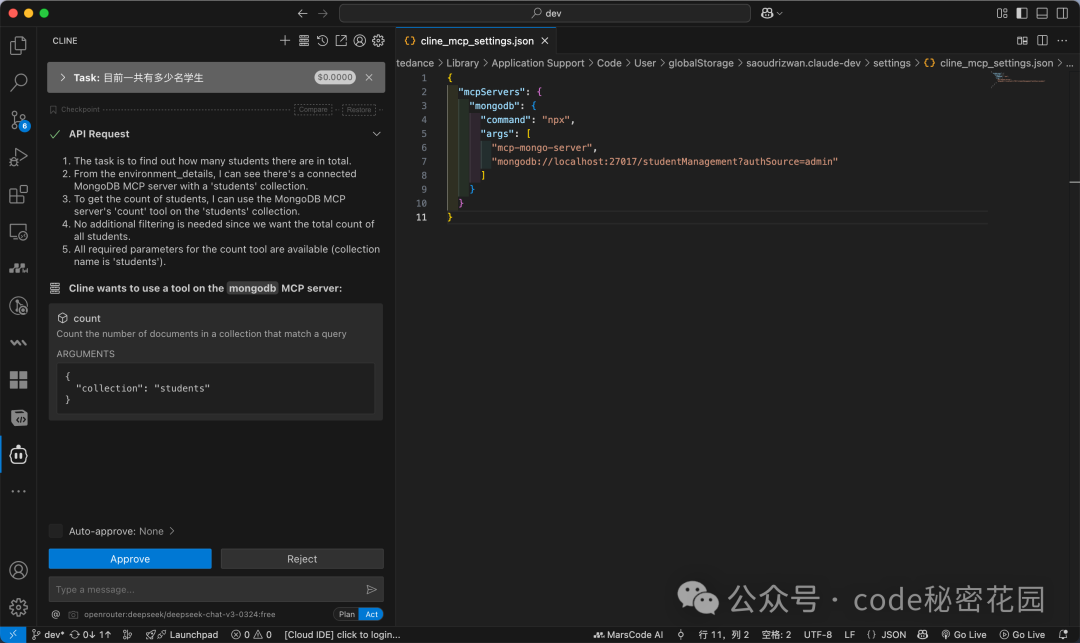
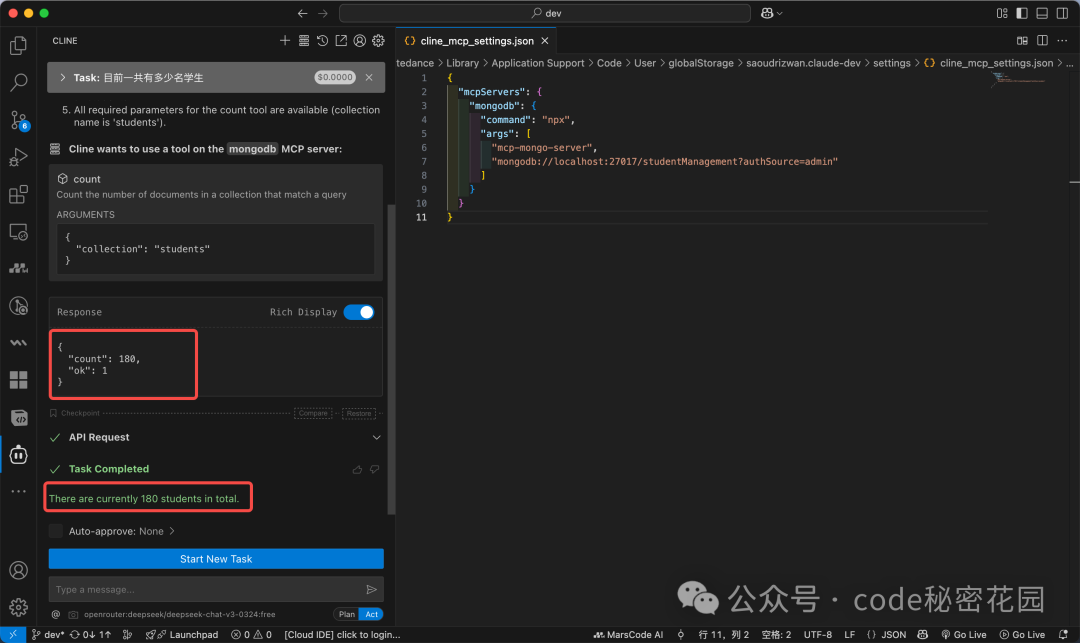
现在进行测试。提问:“目前一共有多少名学生?”
Cline 会自动识别问题需要调用 MCP,并请求权限。允许后,MCP Server 会执行查询并返回准确结果。
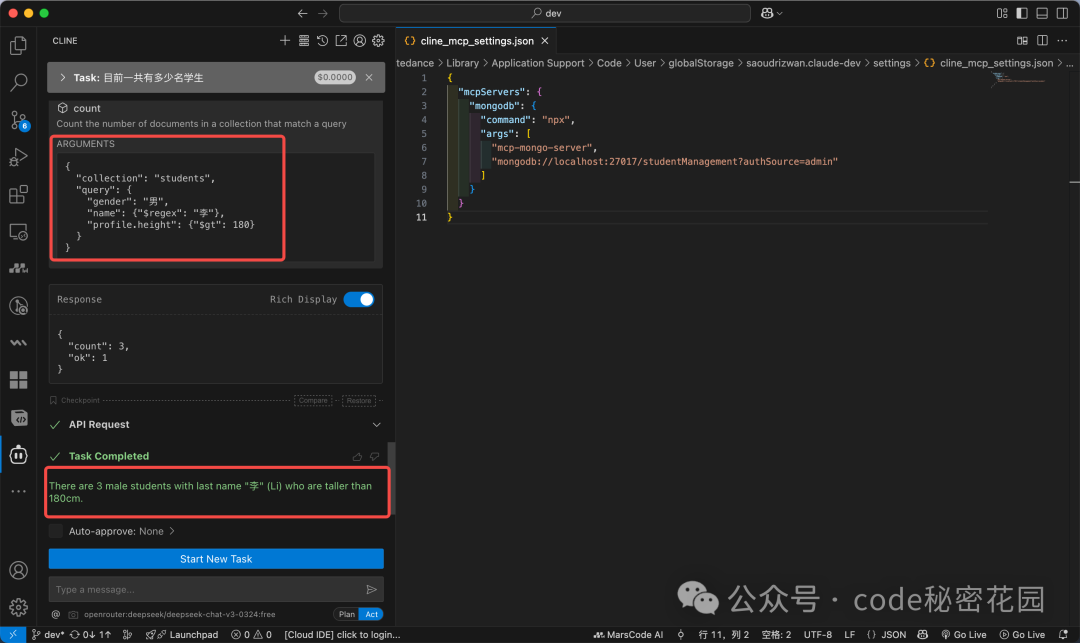
再尝试一个复杂查询:“有多少身高大于 180、姓李的男同学?”
模型通过 MCP 生成并执行了对应的 MongoDB 查询条件,准确返回了结果。
对于一个模糊问题:“求张老师的联系方式”,模型也能通过查询教师表并匹配姓氏来找到答案。
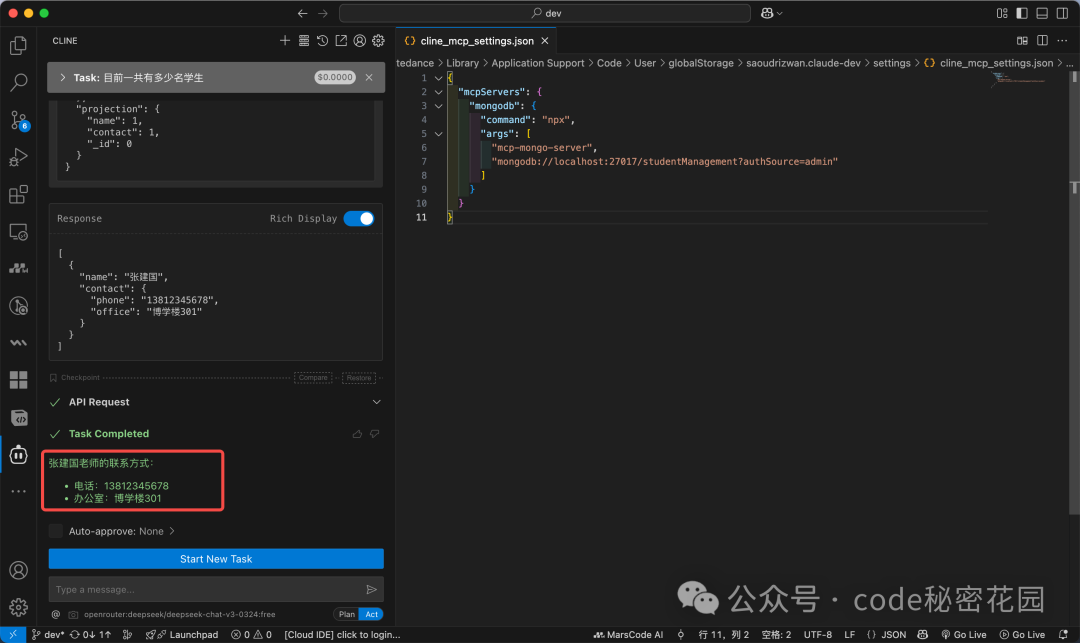
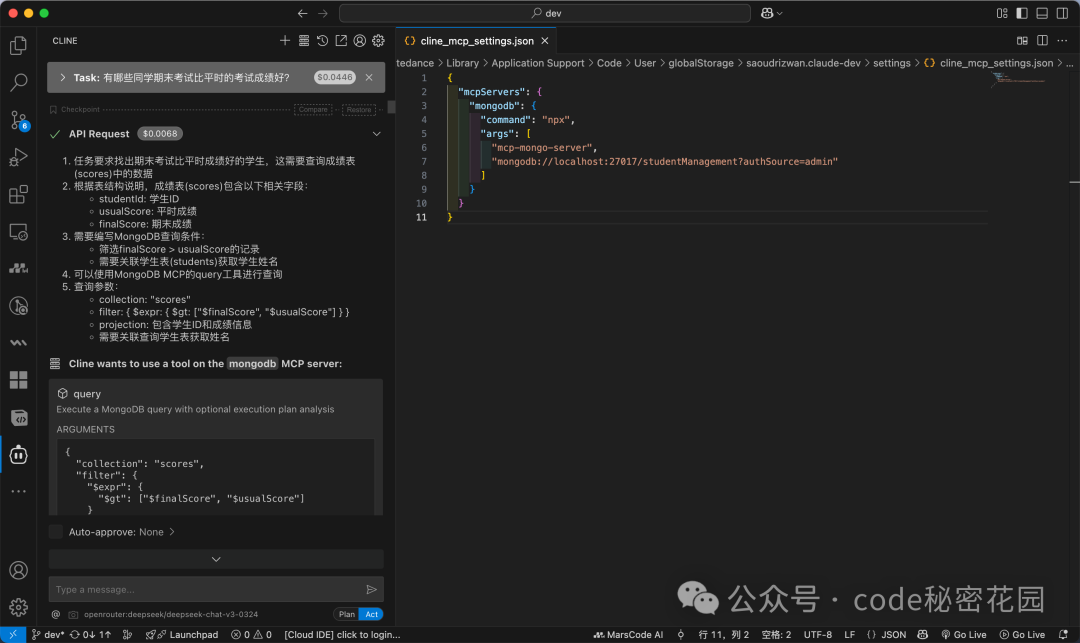
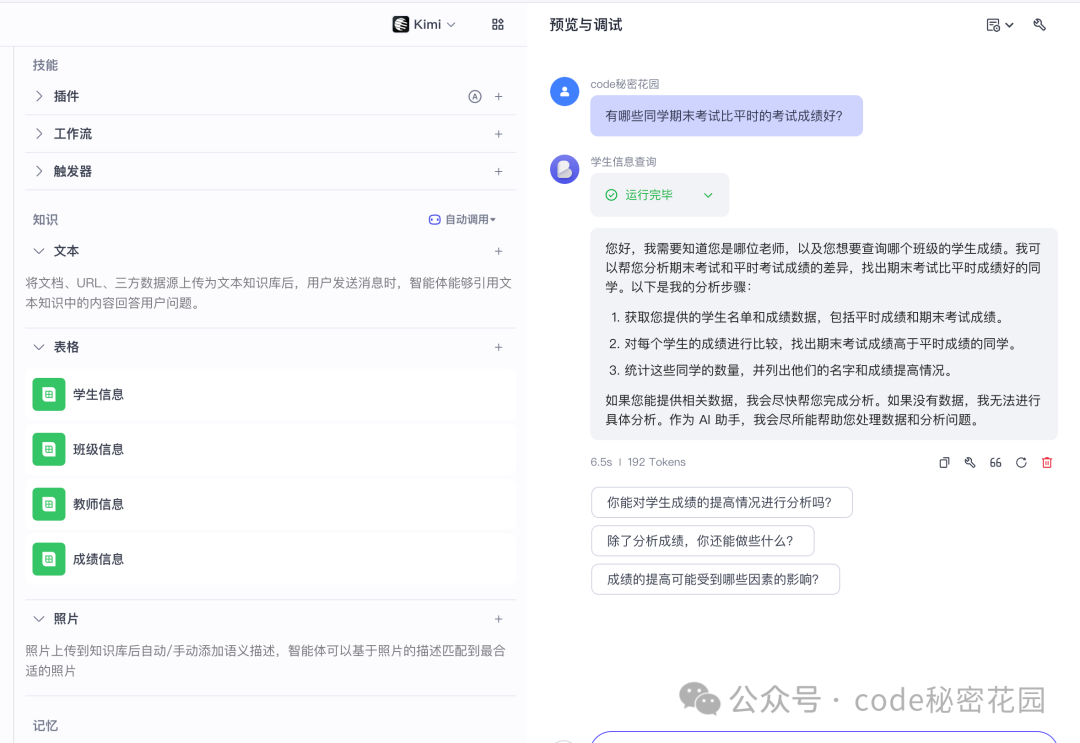
接下来挑战一个需要多表关联和推理的问题:“有哪些同学期末考试比平时的考试成绩好?”
模型首先会探索数据库结构(例如查看 scores 表的一个样本),以了解字段名。
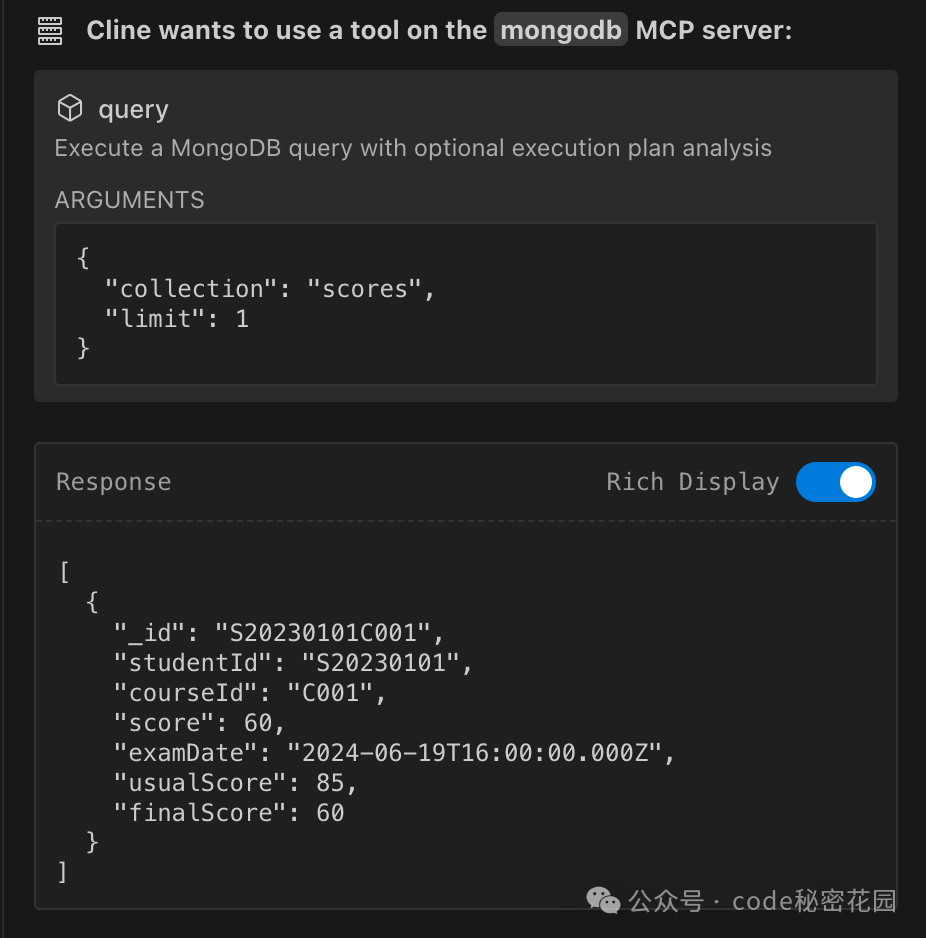
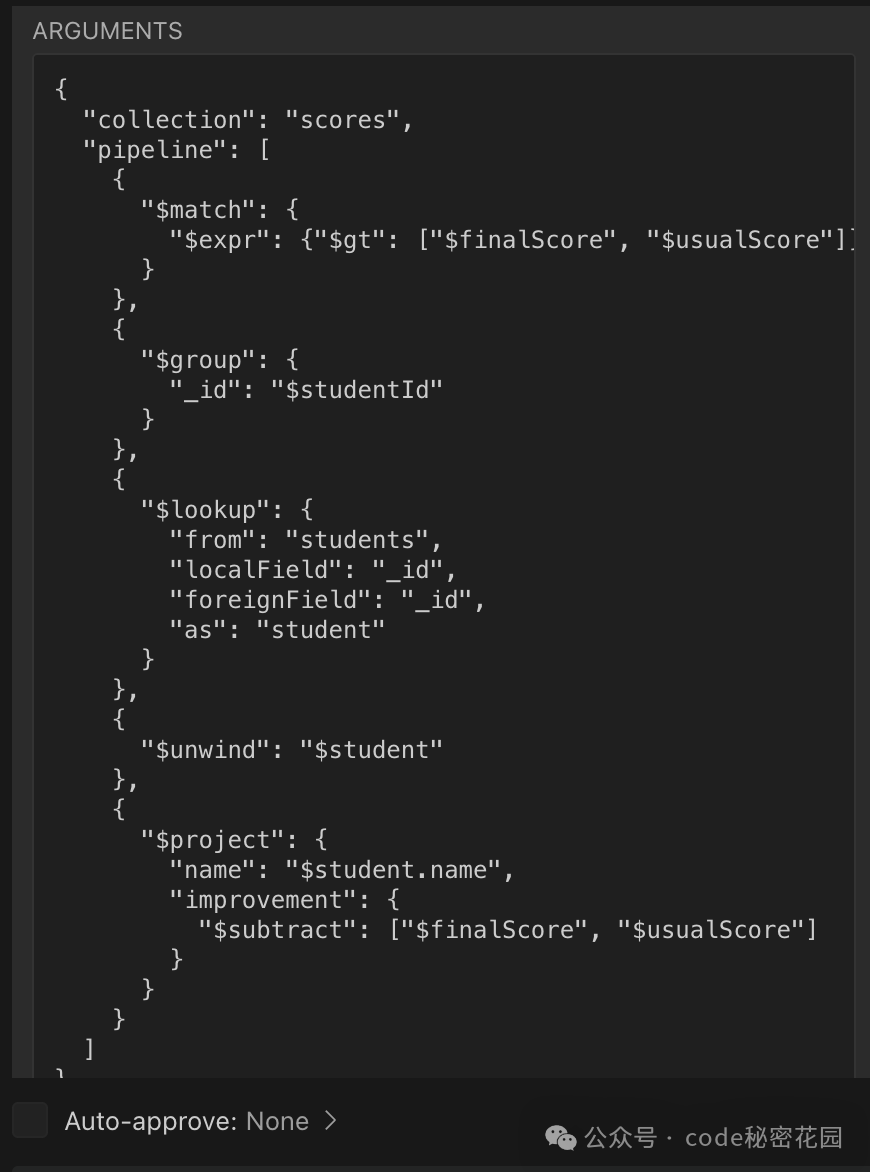
然后,它会构建一个复杂的聚合查询管道(使用 $match, $lookup, $project 等阶段),来关联学生表并筛选出期末成绩高于平时成绩的记录。
最终,模型能够给出准确的答案列表。
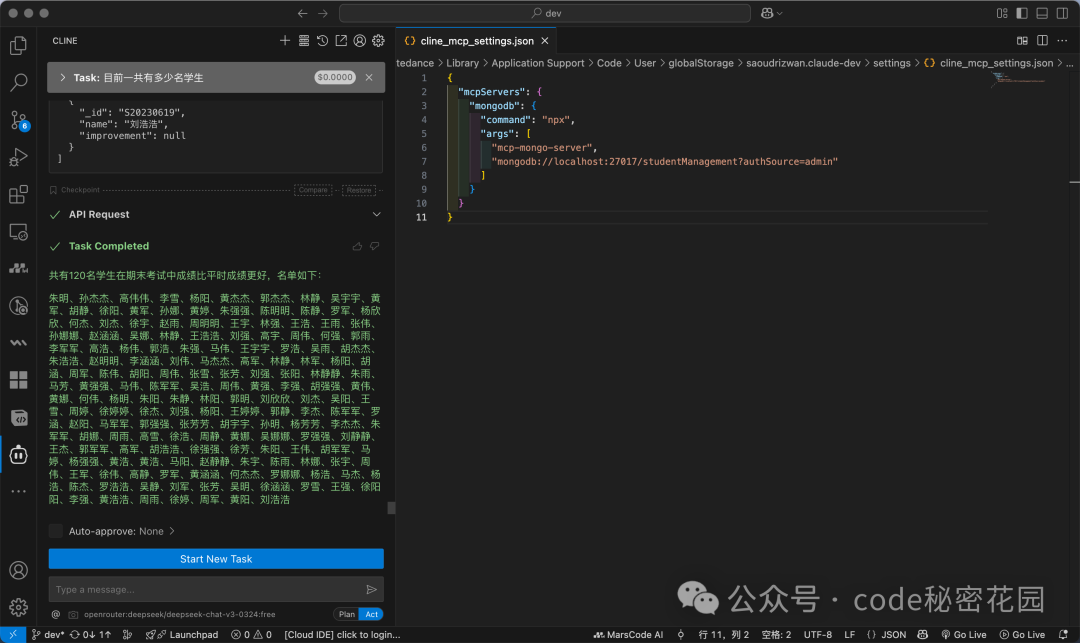
4.4 通过 Prompt 优化查询效果
MCP Server 为模型提供了访问数据库的能力,但数据库的表结构对模型而言起初是黑盒。这可能导致模型需要“猜测”字段名或先探查结构,影响效率和准确性。
一个有效的优化技巧是:在系统提示词(Custom Instructions)中明确告知模型表结构信息和要求。你可以用 AI 生成一份清晰的表结构说明。
然后,在 Cline 的设置中找到 Custom Instructions,将这段提示词粘贴进去。
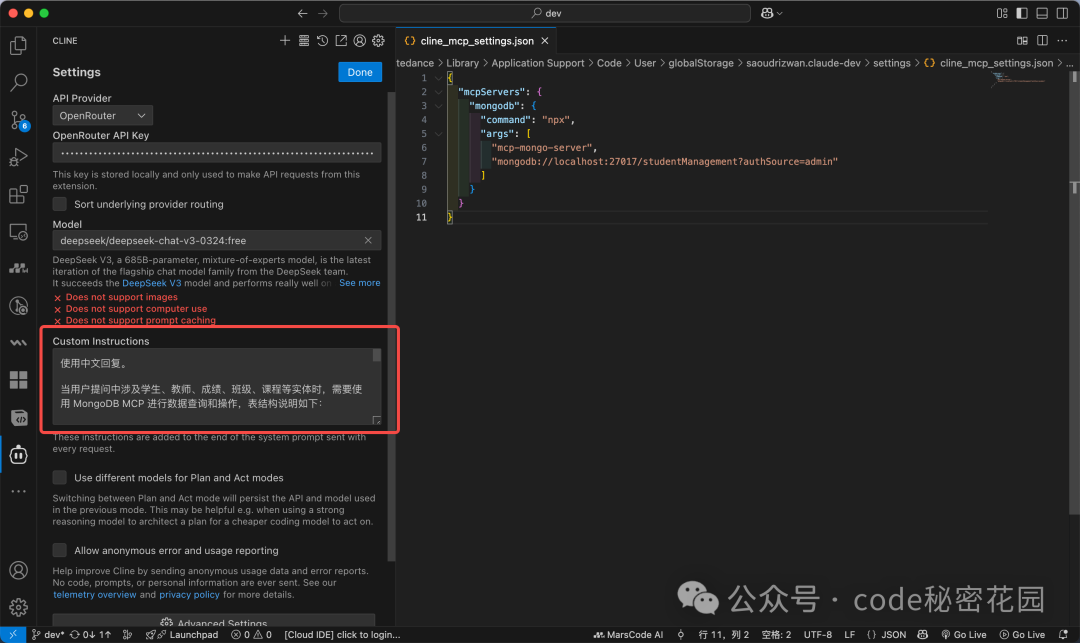
添加提示词后,重新提问:“有哪些同学期末考试比平时的考试成绩好?”
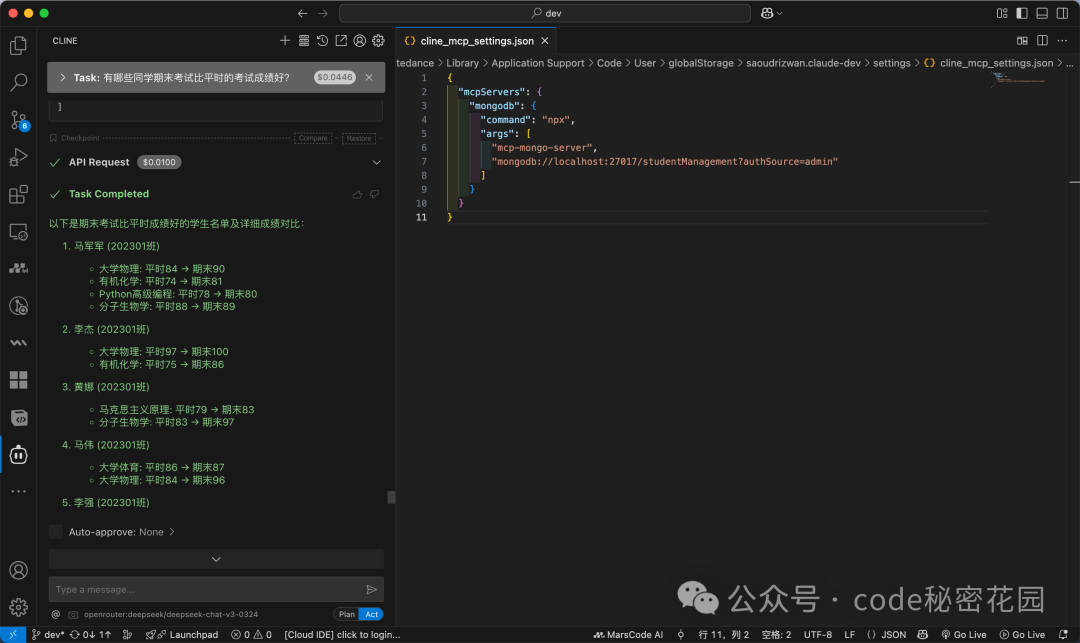
此时,模型会直接根据已知的表结构生成精准的查询思路,并按科目给出详细的对比结果,效率显著提升。
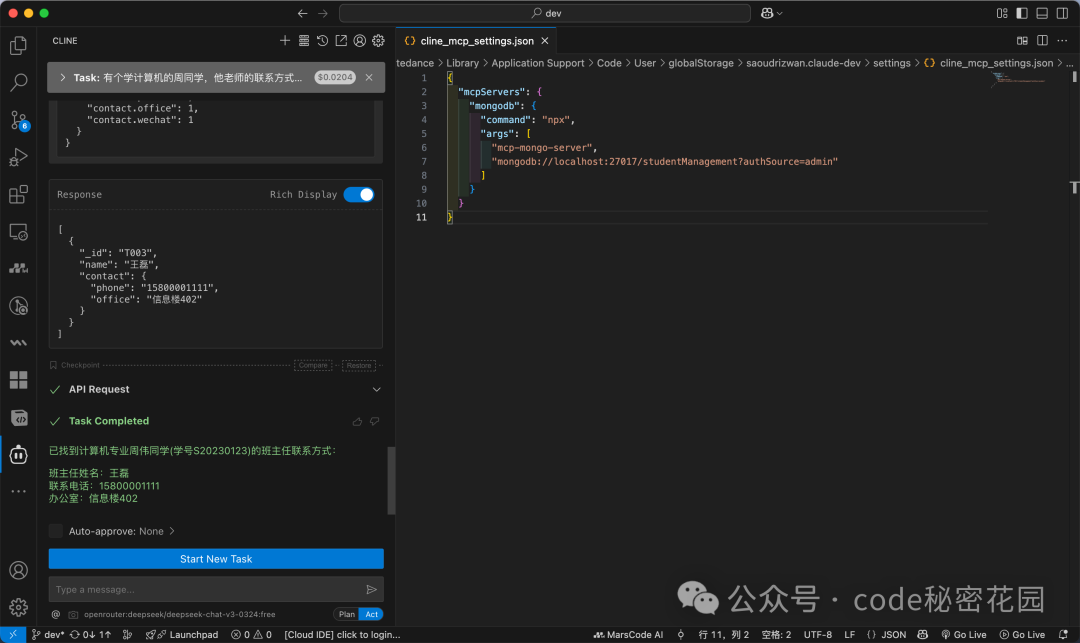
再测试一个更复杂的多步关联查询:“有个学计算机的周同学,他老师的联系方式给我一下”。
模型成功执行了“找姓周学生 -> 确定其所在班级 -> 通过班级找到班主任ID -> 查询教师信息”这一系列操作。
4.5 对比知识库效果
为了对比,我们将同样的学生数据表导入 Coze 平台的知识库中。
对于简单问题“目前一共有多少名学生?”,知识库能正确回答。
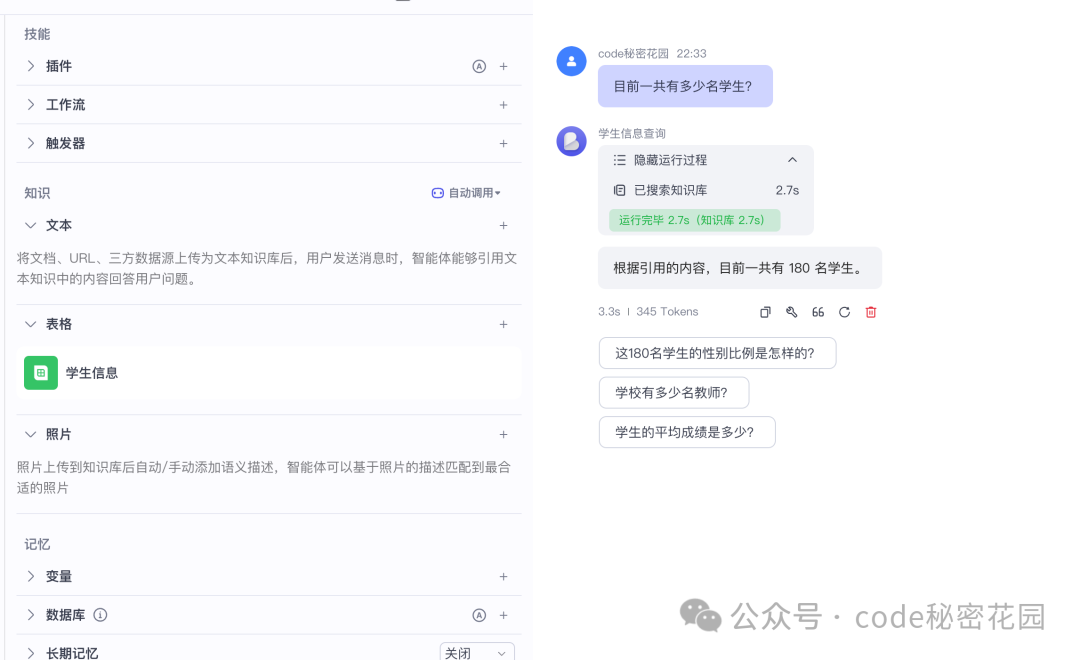
但对于“有个学计算机的周同学,他老师的联系方式给我一下”这个问题,出于隐私考虑,知识库模型可能拒绝回答。
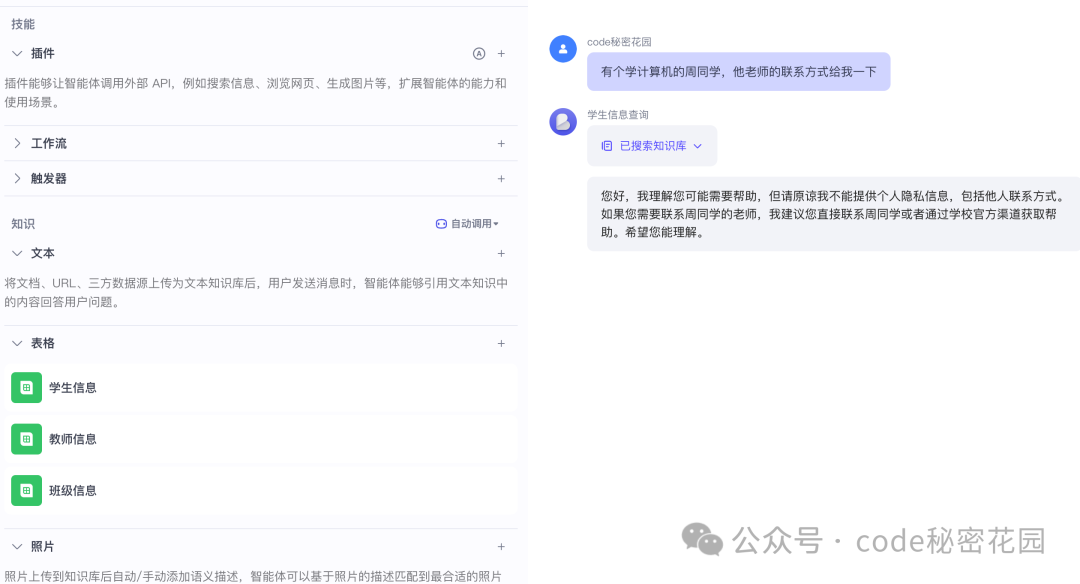
换成“有哪些同学期末考试比平时的考试成绩好?”,知识库模型也表示无法分析,需要额外数据。
对比非常明显:在结构化数据的精准查询和复杂分析场景下,MCP + 数据库的方式显著优于传统的 RAG 知识库。
4.6 目前的局限性
由于 MCP 技术正处于爆发初期,当前方案也存在一些局限性:
- 避免大数据量检索:与 RAG 仅检索最相关的切片不同,MCP 会执行真实的数据库查询。如果一次查询请求过大的数据量,会消耗大量 Token,甚至可能导致客户端卡顿。
- Token 消耗增加:许多 MCP 客户端依赖系统提示词来实现与工具的通信,启用 MCP 功能通常会伴随 Token 消耗量的增长。
尽管如此,未来依然可期。过去虽有基于 Function Call + Text2SQL 的类似尝试,但因开发成本和准确性难以普及。而今天我们探讨的 MCP + 数据库 的方式,极大地降低了开发门槛(甚至可以是零代码),且查询准确性高。相信它将在智能客服、仓储管理、信息管理等结构化数据检索场景中,成为一种非常有潜力的技术方案,并可能逐步替代传统的 RAG 方式。
希望这篇在 云栈社区 分享的实战教程,能帮助你理解并上手 MCP 这项强大的技术。
 发表于 2026-1-4 16:01:47
|
查看: 278|
回复: 0
发表于 2026-1-4 16:01:47
|
查看: 278|
回复: 0
